 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake Some Noise: Towards LLM audio reasoning and generation using sound tokens
Mar 28, 2025



Integrating audio comprehension and generation into large language models (LLMs) remains challenging due to the continuous nature of audio and the resulting high sampling rates. Here, we introduce a novel approach that combines Variational Quantization with Conditional Flow Matching to convert audio into ultra-low bitrate discrete tokens of 0.23kpbs, allowing for seamless integration with text tokens in LLMs. We fine-tuned a pretrained text-based LLM using Low-Rank Adaptation (LoRA) to assess its effectiveness in achieving true multimodal capabilities, i.e., audio comprehension and generation. Our tokenizer outperforms a traditional VQ-VAE across various datasets with diverse acoustic events. Despite the substantial loss of fine-grained details through audio tokenization, our multimodal LLM trained with discrete tokens achieves competitive results in audio comprehension with state-of-the-art methods, though audio generation is poor. Our results highlight the need for larger, more diverse datasets and improved evaluation metrics to advance multimodal LLM performance.
Quality Over Quantity? LLM-Based Curation for a Data-Efficient Audio-Video Foundation Model
Mar 12, 2025Integrating audio and visual data for training multimodal foundational models remains challenging. We present Audio-Video Vector Alignment (AVVA), which aligns audiovisual (AV) scene content beyond mere temporal synchronization via a Large Language Model (LLM)-based data curation pipeline. Specifically, AVVA scores and selects high-quality training clips using Whisper (speech-based audio foundation model) for audio and DINOv2 for video within a dual-encoder contrastive learning framework. Evaluations on AudioCaps, VALOR, and VGGSound demonstrate that this approach can achieve significant accuracy gains with substantially less curated data. For instance, AVVA yields a 7.6% improvement in top-1 accuracy for audio-to-video retrieval on VGGSound compared to ImageBind, despite training on only 192 hours of carefully filtered data (vs. 5800+ hours). Moreover, an ablation study highlights that trading data quantity for data quality improves performance, yielding respective top-3 accuracy increases of 47.8, 48.4, and 58.0 percentage points on AudioCaps, VALOR, and VGGSound over uncurated baselines. While these results underscore AVVA's data efficiency, we also discuss the overhead of LLM-driven curation and how it may be scaled or approximated in larger domains. Overall, AVVA provides a viable path toward more robust, text-free audiovisual learning with improved retrieval accuracy.
Distillation and Pruning for Scalable Self-Supervised Representation-Based Speech Quality Assessment
Feb 07, 2025


In this paper, we investigate distillation and pruning methods to reduce model size for non-intrusive speech quality assessment based on self-supervised representations. Our experiments build on XLS-R-SQA, a speech quality assessment model using wav2vec 2.0 XLS-R embeddings. We retrain this model on a large compilation of mean opinion score datasets, encompassing over 100,000 labeled clips. For distillation, using this model as a teacher, we generate pseudo-labels on unlabeled degraded speech signals and train student models of varying sizes. For pruning, we use a data-driven strategy. While data-driven pruning performs better at larger model sizes, distillation on unlabeled data is more effective for smaller model sizes. Distillation can halve the gap between the baseline's correlation with ground-truth MOS labels and that of the XLS-R-based teacher model, while reducing model size by two orders of magnitude compared to the teacher model.
Audio Entailment: Assessing Deductive Reasoning for Audio Understanding
Jul 25, 2024Recent literature uses language to build foundation models for audio. These Audio-Language Models (ALMs) are trained on a vast number of audio-text pairs and show remarkable performance in tasks including Text-to-Audio Retrieval, Captioning, and Question Answering. However, their ability to engage in more complex open-ended tasks, like Interactive Question-Answering, requires proficiency in logical reasoning -- a skill not yet benchmarked. We introduce the novel task of Audio Entailment to evaluate an ALM's deductive reasoning ability. This task assesses whether a text description (hypothesis) of audio content can be deduced from an audio recording (premise), with potential conclusions being entailment, neutral, or contradiction, depending on the sufficiency of the evidence. We create two datasets for this task with audio recordings sourced from two audio captioning datasets -- AudioCaps and Clotho -- and hypotheses generated using Large Language Models (LLMs). We benchmark state-of-the-art ALMs and find deficiencies in logical reasoning with both zero-shot and linear probe evaluations. Finally, we propose "caption-before-reason", an intermediate step of captioning that improves the zero-shot and linear-probe performance of ALMs by an absolute 6% and 3%, respectively.
Multi-label audio classification with a noisy zero-shot teacher
Jul 20, 2024



We propose a novel training scheme using self-label correction and data augmentation methods designed to deal with noisy labels and improve real-world accuracy on a polyphonic audio content detection task. The augmentation method reduces label noise by mixing multiple audio clips and joining their labels, while being compatible with multiple active labels. We additionally show that performance can be improved by a self-label correction method using the same pretrained model. Finally, we show that it is feasible to use a strong zero-shot model such as CLAP to generate labels for unlabeled data and improve the results using the proposed training and label enhancement methods. The resulting model performs similar to CLAP while being an efficient mobile device friendly architecture and can be quickly adapted to unlabeled sound classes.
Gaussian Flow Bridges for Audio Domain Transfer with Unpaired Data
May 29, 2024



Audio domain transfer is the process of modifying audio signals to match characteristics of a different domain, while retaining the original content. This paper investigates the potential of Gaussian Flow Bridges, an emerging approach in generative modeling, for this problem. The presented framework addresses the transport problem across different distributions of audio signals through the implementation of a series of two deterministic probability flows. The proposed framework facilitates manipulation of the target distribution properties through a continuous control variable, which defines a certain aspect of the target domain. Notably, this approach does not rely on paired examples for training. To address identified challenges on maintaining the speech content consistent, we recommend a training strategy that incorporates chunk-based minibatch Optimal Transport couplings of data samples and noise. Comparing our unsupervised method with established baselines, we find competitive performance in tasks of reverberation and distortion manipulation. Despite encoutering limitations, the intriguing results obtained in this study underscore potential for further exploration.
PAM: Prompting Audio-Language Models for Audio Quality Assessment
Feb 01, 2024



While audio quality is a key performance metric for various audio processing tasks, including generative modeling, its objective measurement remains a challenge. Audio-Language Models (ALMs) are pre-trained on audio-text pairs that may contain information about audio quality, the presence of artifacts, or noise. Given an audio input and a text prompt related to quality, an ALM can be used to calculate a similarity score between the two. Here, we exploit this capability and introduce PAM, a no-reference metric for assessing audio quality for different audio processing tasks. Contrary to other "reference-free" metrics, PAM does not require computing embeddings on a reference dataset nor training a task-specific model on a costly set of human listening scores. We extensively evaluate the reliability of PAM against established metrics and human listening scores on four tasks: text-to-audio (TTA), text-to-music generation (TTM), text-to-speech (TTS), and deep noise suppression (DNS). We perform multiple ablation studies with controlled distortions, in-the-wild setups, and prompt choices. Our evaluation shows that PAM correlates well with existing metrics and human listening scores. These results demonstrate the potential of ALMs for computing a general-purpose audio quality metric.
CMMD: Contrastive Multi-Modal Diffusion for Video-Audio Conditional Modeling
Dec 08, 2023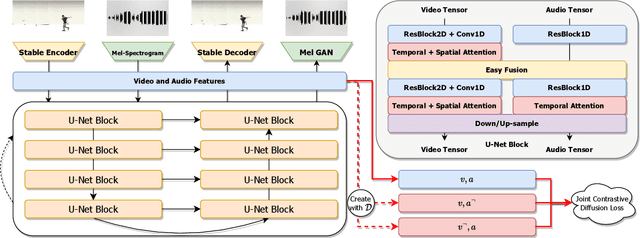
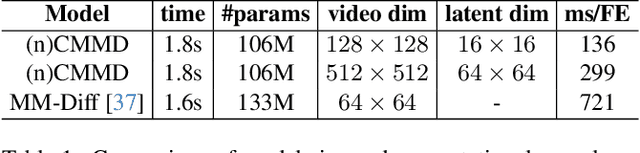
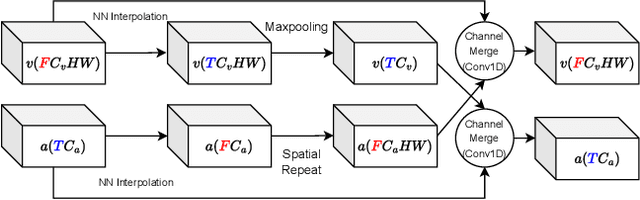
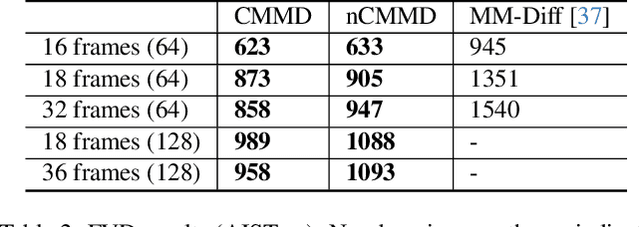
We introduce a multi-modal diffusion model tailored for the bi-directional conditional generation of video and audio. Recognizing the importance of accurate alignment between video and audio events in multi-modal generation tasks, we propose a joint contrastive training loss to enhance the synchronization between visual and auditory occurrences. Our research methodology involves conducting comprehensive experiments on multiple datasets to thoroughly evaluate the efficacy of our proposed model. The assessment of generation quality and alignment performance is carried out from various angles, encompassing both objective and subjective metrics. Our findings demonstrate that the proposed model outperforms the baseline, substantiating its effectiveness and efficiency. Notably, the incorporation of the contrastive loss results in improvements in audio-visual alignment, particularly in the high-correlation video-to-audio generation task. These results indicate the potential of our proposed model as a robust solution for improving the quality and alignment of multi-modal generation, thereby contributing to the advancement of video and audio conditional generation systems.
Adapting Frechet Audio Distance for Generative Music Evaluation
Nov 02, 2023



The growing popularity of generative music models underlines the need for perceptually relevant, objective music quality metrics. The Frechet Audio Distance (FAD) is commonly used for this purpose even though its correlation with perceptual quality is understudied. We show that FAD performance may be hampered by sample size bias, poor choice of audio embeddings, or the use of biased or low-quality reference sets. We propose reducing sample size bias by extrapolating scores towards an infinite sample size. Through comparisons with MusicCaps labels and a listening test we identify audio embeddings and music reference sets that yield FAD scores well-correlated with acoustic and musical quality. Our results suggest that per-song FAD can be useful to identify outlier samples and predict perceptual quality for a range of music sets and generative models. Finally, we release a toolkit that allows adapting FAD for generative music evaluation.
ICASSP 2023 Acoustic Echo Cancellation Challenge
Sep 22, 2023



The ICASSP 2023 Acoustic Echo Cancellation Challenge is intended to stimulate research in acoustic echo cancellation (AEC), which is an important area of speech enhancement and is still a top issue in audio communication. This is the fourth AEC challenge and it is enhanced by adding a second track for personalized acoustic echo cancellation, reducing the algorithmic + buffering latency to 20ms, as well as including a full-band version of AECMOS. We open source two large datasets to train AEC models under both single talk and double talk scenarios. These datasets consist of recordings from more than 10,000 real audio devices and human speakers in real environments, as well as a synthetic dataset. We open source an online subjective test framework and provide an objective metric for researchers to quickly test their results. The winners of this challenge were selected based on the average mean opinion score (MOS) achieved across all scenarios and the word accuracy (WAcc) rate.