 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Accent Normalization via Discrete Diffusion
Mar 15, 2026Existing accent normalization methods do not typically offer control over accent strength, yet many applications-such as language learning and dubbing-require tunable accent retention. We propose DLM-AN, a controllable accent normalization system built on masked discrete diffusion over self-supervised speech tokens. A Common Token Predictor identifies source tokens that likely encode native pronunciation; these tokens are selectively reused to initialize the reverse diffusion process. This provides a simple yet effective mechanism for controlling accent strength: reusing more tokens preserves more of the original accent. DLM-AN further incorporates a flow-matching Duration Ratio Predictor that automatically adjusts the total duration to better match the native rhythm. Experiments on multi-accent English data show that DLM-AN achieves the lowest word error rate among all compared systems while delivering competitive accent reduction and smooth, interpretable accent strength control.
Towards Achieving Human Parity on End-to-end Simultaneous Speech Translation via LLM Agent
Jul 31, 2024



In this paper, we present Cross Language Agent -- Simultaneous Interpretation, CLASI, a high-quality and human-like Simultaneous Speech Translation (SiST) System. Inspired by professional human interpreters, we utilize a novel data-driven read-write strategy to balance the translation quality and latency. To address the challenge of translating in-domain terminologies, CLASI employs a multi-modal retrieving module to obtain relevant information to augment the translation. Supported by LLMs, our approach can generate error-tolerated translation by considering the input audio, historical context, and retrieved information. Experimental results show that our system outperforms other systems by significant margins. Aligned with professional human interpreters, we evaluate CLASI with a better human evaluation metric, valid information proportion (VIP), which measures the amount of information that can be successfully conveyed to the listeners. In the real-world scenarios, where the speeches are often disfluent, informal, and unclear, CLASI achieves VIP of 81.3% and 78.0% for Chinese-to-English and English-to-Chinese translation directions, respectively. In contrast, state-of-the-art commercial or open-source systems only achieve 35.4% and 41.6%. On the extremely hard dataset, where other systems achieve under 13% VIP, CLASI can still achieve 70% VIP.
Learning Retrieval Augmentation for Personalized Dialogue Generation
Jun 27, 2024Personalized dialogue generation, focusing on generating highly tailored responses by leveraging persona profiles and dialogue context, has gained significant attention in conversational AI applications. However, persona profiles, a prevalent setting in current personalized dialogue datasets, typically composed of merely four to five sentences, may not offer comprehensive descriptions of the persona about the agent, posing a challenge to generate truly personalized dialogues. To handle this problem, we propose $\textbf{L}$earning Retrieval $\textbf{A}$ugmentation for $\textbf{P}$ersonalized $\textbf{D}$ial$\textbf{O}$gue $\textbf{G}$eneration ($\textbf{LAPDOG}$), which studies the potential of leveraging external knowledge for persona dialogue generation. Specifically, the proposed LAPDOG model consists of a story retriever and a dialogue generator. The story retriever uses a given persona profile as queries to retrieve relevant information from the story document, which serves as a supplementary context to augment the persona profile. The dialogue generator utilizes both the dialogue history and the augmented persona profile to generate personalized responses. For optimization, we adopt a joint training framework that collaboratively learns the story retriever and dialogue generator, where the story retriever is optimized towards desired ultimate metrics (e.g., BLEU) to retrieve content for the dialogue generator to generate personalized responses. Experiments conducted on the CONVAI2 dataset with ROCStory as a supplementary data source show that the proposed LAPDOG method substantially outperforms the baselines, indicating the effectiveness of the proposed method. The LAPDOG model code is publicly available for further exploration. https://github.com/hqsiswiliam/LAPDOG
Selective Prompting Tuning for Personalized Conversations with LLMs
Jun 26, 2024In conversational AI, personalizing dialogues with persona profiles and contextual understanding is essential. Despite large language models' (LLMs) improved response coherence, effective persona integration remains a challenge. In this work, we first study two common approaches for personalizing LLMs: textual prompting and direct fine-tuning. We observed that textual prompting often struggles to yield responses that are similar to the ground truths in datasets, while direct fine-tuning tends to produce repetitive or overly generic replies. To alleviate those issues, we propose \textbf{S}elective \textbf{P}rompt \textbf{T}uning (SPT), which softly prompts LLMs for personalized conversations in a selective way. Concretely, SPT initializes a set of soft prompts and uses a trainable dense retriever to adaptively select suitable soft prompts for LLMs according to different input contexts, where the prompt retriever is dynamically updated through feedback from the LLMs. Additionally, we propose context-prompt contrastive learning and prompt fusion learning to encourage the SPT to enhance the diversity of personalized conversations. Experiments on the CONVAI2 dataset demonstrate that SPT significantly enhances response diversity by up to 90\%, along with improvements in other critical performance indicators. Those results highlight the efficacy of SPT in fostering engaging and personalized dialogue generation. The SPT model code (https://github.com/hqsiswiliam/SPT) is publicly available for further exploration.
Speech Translation with Large Language Models: An Industrial Practice
Dec 21, 2023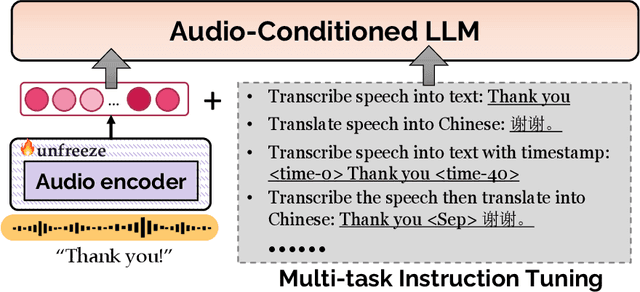
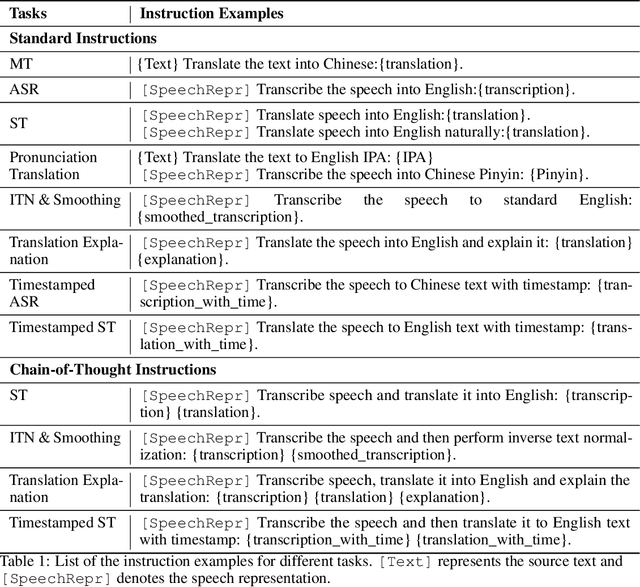
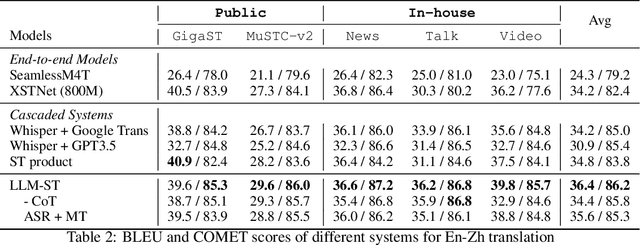
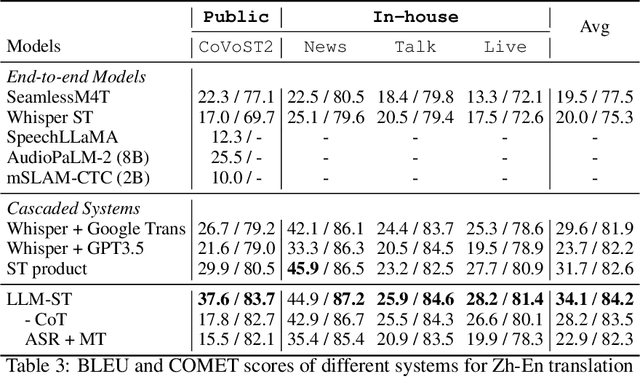
Given the great success of large language models (LLMs) across various tasks, in this paper, we introduce LLM-ST, a novel and effective speech translation model constructed upon a pre-trained LLM. By integrating the large language model (LLM) with a speech encoder and employing multi-task instruction tuning, LLM-ST can produce accurate timestamped transcriptions and translations, even from long audio inputs. Furthermore, our findings indicate that the implementation of Chain-of-Thought (CoT) prompting can yield advantages in the context of LLM-ST. Through rigorous experimentation on English and Chinese datasets, we showcase the exceptional performance of LLM-ST, establishing a new benchmark in the field of speech translation. Demo: https://speechtranslation.github.io/llm-st/.
RepCodec: A Speech Representation Codec for Speech Tokenization
Aug 31, 2023



With recent rapid growth of large language models (LLMs), discrete speech tokenization has played an important role for injecting speech into LLMs. However, this discretization gives rise to a loss of information, consequently impairing overall performance. To improve the performance of these discrete speech tokens, we present RepCodec, a novel speech representation codec for semantic speech tokenization. In contrast to audio codecs which reconstruct the raw audio, RepCodec learns a vector quantization codebook through reconstructing speech representations from speech encoders like HuBERT or data2vec. Together, the speech encoder, the codec encoder and the vector quantization codebook form a pipeline for converting speech waveforms into semantic tokens. The extensive experiments illustrate that RepCodec, by virtue of its enhanced information retention capacity, significantly outperforms the widely used k-means clustering approach in both speech understanding and generation. Furthermore, this superiority extends across various speech encoders and languages, affirming the robustness of RepCodec. We believe our method can facilitate large language modeling research on speech processing.
Recent Advances in Direct Speech-to-text Translation
Jun 20, 2023

Recently, speech-to-text translation has attracted more and more attention and many studies have emerged rapidly. In this paper, we present a comprehensive survey on direct speech translation aiming to summarize the current state-of-the-art techniques. First, we categorize the existing research work into three directions based on the main challenges -- modeling burden, data scarcity, and application issues. To tackle the problem of modeling burden, two main structures have been proposed, encoder-decoder framework (Transformer and the variants) and multitask frameworks. For the challenge of data scarcity, recent work resorts to many sophisticated techniques, such as data augmentation, pre-training, knowledge distillation, and multilingual modeling. We analyze and summarize the application issues, which include real-time, segmentation, named entity, gender bias, and code-switching. Finally, we discuss some promising directions for future work.
MOSPC: MOS Prediction Based on Pairwise Comparison
Jun 18, 2023



As a subjective metric to evaluate the quality of synthesized speech, Mean opinion score~(MOS) usually requires multiple annotators to score the same speech. Such an annotation approach requires a lot of manpower and is also time-consuming. MOS prediction model for automatic evaluation can significantly reduce labor cost. In previous works, it is difficult to accurately rank the quality of speech when the MOS scores are close. However, in practical applications, it is more important to correctly rank the quality of synthesis systems or sentences than simply predicting MOS scores. Meanwhile, as each annotator scores multiple audios during annotation, the score is probably a relative value based on the first or the first few speech scores given by the annotator. Motivated by the above two points, we propose a general framework for MOS prediction based on pair comparison (MOSPC), and we utilize C-Mixup algorithm to enhance the generalization performance of MOSPC. The experiments on BVCC and VCC2018 show that our framework outperforms the baselines on most of the correlation coefficient metrics, especially on the metric KTAU related to quality ranking. And our framework also surpasses the strong baseline in ranking accuracy on each fine-grained segment. These results indicate that our framework contributes to improving the ranking accuracy of speech quality.
PolyVoice: Language Models for Speech to Speech Translation
Jun 13, 2023



We propose PolyVoice, a language model-based framework for speech-to-speech translation (S2ST) system. Our framework consists of two language models: a translation language model and a speech synthesis language model. We use discretized speech units, which are generated in a fully unsupervised way, and thus our framework can be used for unwritten languages. For the speech synthesis part, we adopt the existing VALL-E X approach and build a unit-based audio language model. This grants our framework the ability to preserve the voice characteristics and the speaking style of the original speech. We examine our system on Chinese $\rightarrow$ English and English $\rightarrow$ Spanish pairs. Experimental results show that our system can generate speech with high translation quality and audio quality. Speech samples are available at https://speechtranslation.github.io/polyvoice.
CTC-based Non-autoregressive Speech Translation
May 27, 2023



Combining end-to-end speech translation (ST) and non-autoregressive (NAR) generation is promising in language and speech processing for their advantages of less error propagation and low latency. In this paper, we investigate the potential of connectionist temporal classification (CTC) for non-autoregressive speech translation (NAST). In particular, we develop a model consisting of two encoders that are guided by CTC to predict the source and target texts, respectively. Introducing CTC into NAST on both language sides has obvious challenges: 1) the conditional independent generation somewhat breaks the interdependency among tokens, and 2) the monotonic alignment assumption in standard CTC does not hold in translation tasks. In response, we develop a prediction-aware encoding approach and a cross-layer attention approach to address these issues. We also use curriculum learning to improve convergence of training. Experiments on the MuST-C ST benchmarks show that our NAST model achieves an average BLEU score of 29.5 with a speed-up of 5.67$\times$, which is comparable to the autoregressive counterpart and even outperforms the previous best result of 0.9 BLEU points.