 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
A Fine-tuned Wav2vec 2.0/HuBERT Benchmark For Speech Emotion Recognition, Speaker Verification and Spoken Language Understanding
Nov 04, 2021
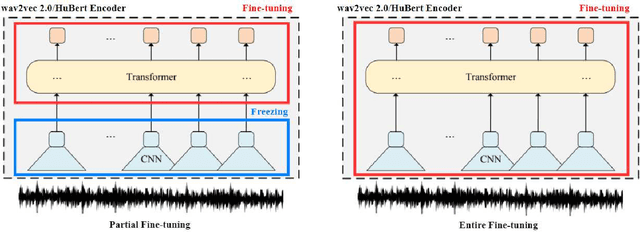
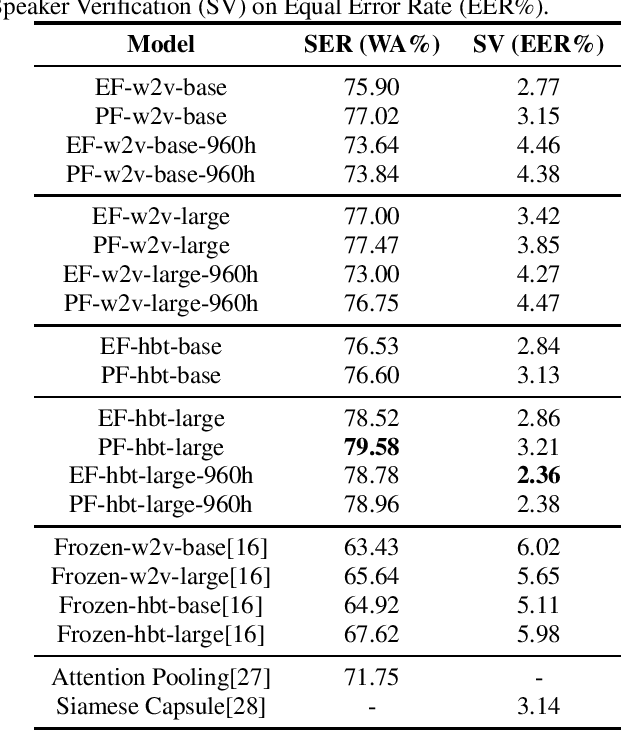
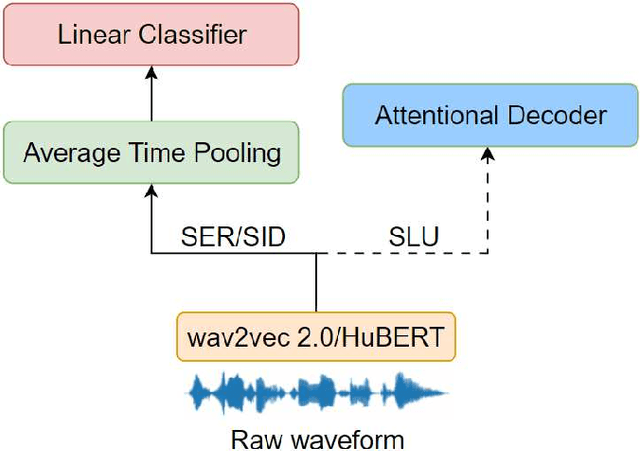
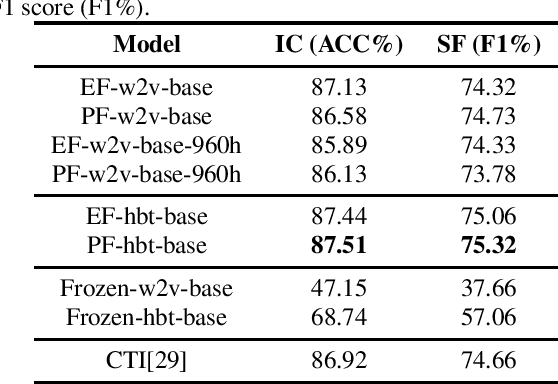
Self-supervised speech representations such as wav2vec 2.0 and HuBERT are making revolutionary progress in Automatic Speech Recognition (ASR). However, self-supervised models have not been totally proved to produce better performance on tasks other than ASR. In this work, we explore partial fine-tuning and entire fine-tuning on wav2vec 2.0 and HuBERT pre-trained models for three non-ASR speech tasks : Speech Emotion Recognition, Speaker Verification and Spoken Language Understanding. We also compare pre-trained models with/without ASR fine-tuning. With simple down-stream frameworks, the best scores reach 79.58% weighted accuracy for Speech Emotion Recognition on IEMOCAP, 2.36% equal error rate for Speaker Verification on VoxCeleb1, 87.51% accuracy for Intent Classification and 75.32% F1 for Slot Filling on SLURP, thus setting a new state-of-the-art for these three benchmarks, proving that fine-tuned wav2vec 2.0 and HuBERT models can better learn prosodic, voice-print and semantic representations.
Language model fusion for streaming end to end speech recognition
Apr 09, 2021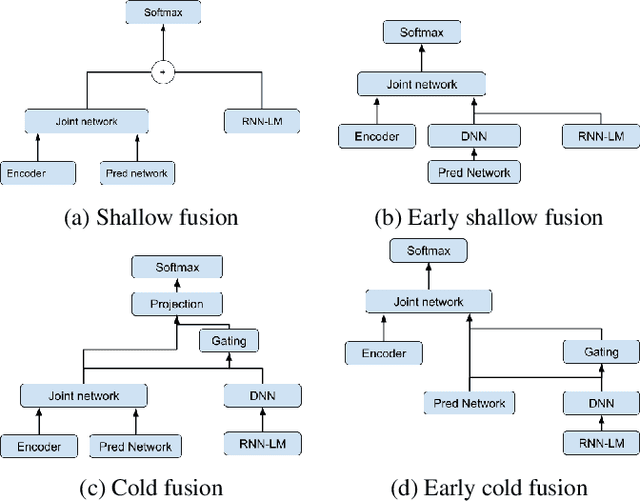
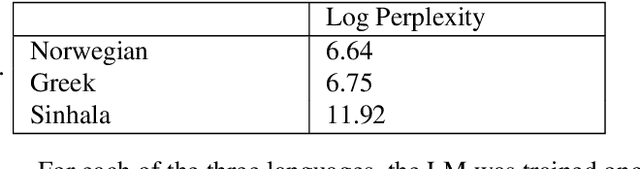
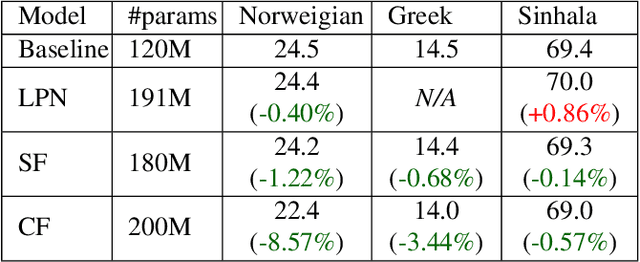
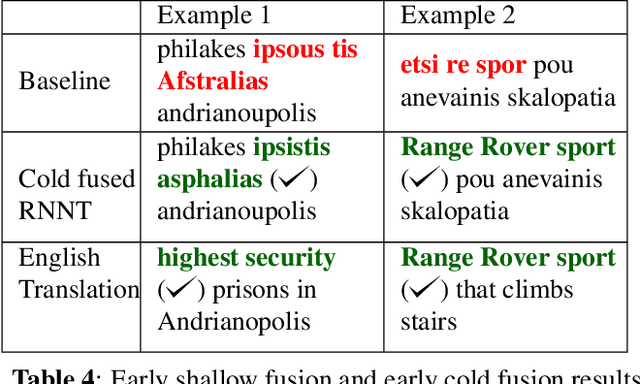
Streaming processing of speech audio is required for many contemporary practical speech recognition tasks. Even with the large corpora of manually transcribed speech data available today, it is impossible for such corpora to cover adequately the long tail of linguistic content that's important for tasks such as open-ended dictation and voice search. We seek to address both the streaming and the tail recognition challenges by using a language model (LM) trained on unpaired text data to enhance the end-to-end (E2E) model. We extend shallow fusion and cold fusion approaches to streaming Recurrent Neural Network Transducer (RNNT), and also propose two new competitive fusion approaches that further enhance the RNNT architecture. Our results on multiple languages with varying training set sizes show that these fusion methods improve streaming RNNT performance through introducing extra linguistic features. Cold fusion works consistently better on streaming RNNT with up to a 8.5% WER improvement.
On Scaling Contrastive Representations for Low-Resource Speech Recognition
Feb 01, 2021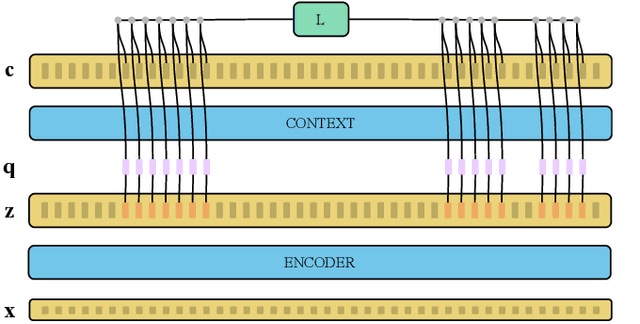
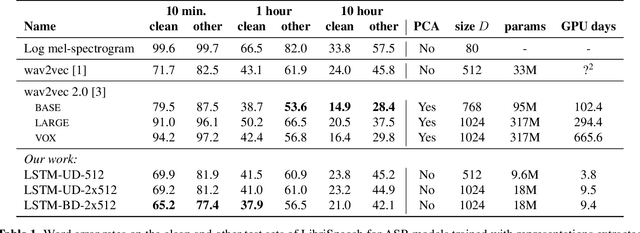
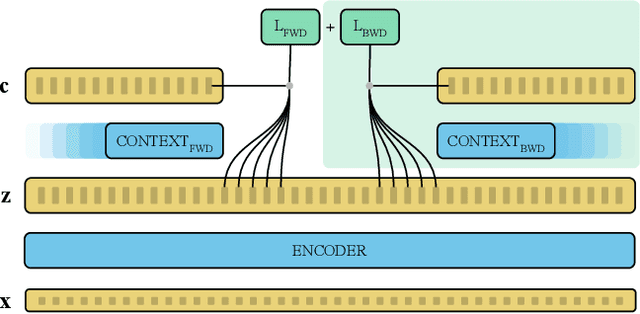
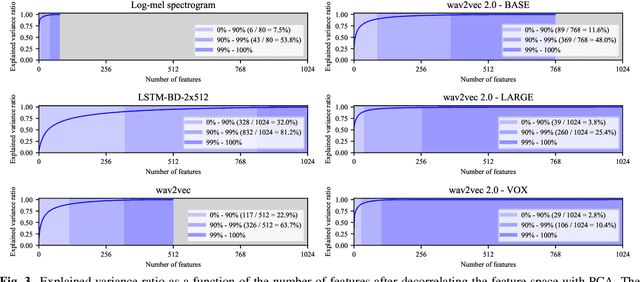
Recent advances in self-supervised learning through contrastive training have shown that it is possible to learn a competitive speech recognition system with as little as 10 minutes of labeled data. However, these systems are computationally expensive since they require pre-training followed by fine-tuning in a large parameter space. We explore the performance of such systems without fine-tuning by training a state-of-the-art speech recognizer on the fixed representations from the computationally demanding wav2vec 2.0 framework. We find performance to decrease without fine-tuning and, in the extreme low-resource setting, wav2vec 2.0 is inferior to its predecessor. In addition, we find that wav2vec 2.0 representations live in a low dimensional subspace and that decorrelating the features of the representations can stabilize training of the automatic speech recognizer. Finally, we propose a bidirectional extension to the original wav2vec framework that consistently improves performance.
Two-Pass End-to-End Speech Recognition
Aug 29, 2019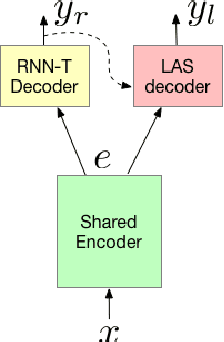

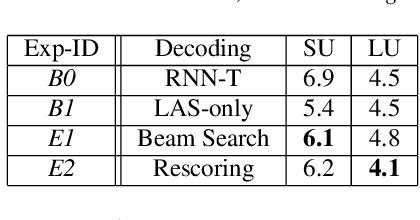
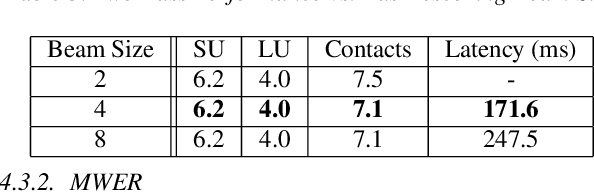
The requirements for many applications of state-of-the-art speech recognition systems include not only low word error rate (WER) but also low latency. Specifically, for many use-cases, the system must be able to decode utterances in a streaming fashion and faster than real-time. Recently, a streaming recurrent neural network transducer (RNN-T) end-to-end (E2E) model has shown to be a good candidate for on-device speech recognition, with improved WER and latency metrics compared to conventional on-device models [1]. However, this model still lags behind a large state-of-the-art conventional model in quality [2]. On the other hand, a non-streaming E2E Listen, Attend and Spell (LAS) model has shown comparable quality to large conventional models [3]. This work aims to bring the quality of an E2E streaming model closer to that of a conventional system by incorporating a LAS network as a second-pass component, while still abiding by latency constraints. Our proposed two-pass model achieves a 17%-22% relative reduction in WER compared to RNN-T alone and increases latency by a small fraction over RNN-T.
Have best of both worlds: two-pass hybrid and E2E cascading framework for speech recognition
Oct 10, 2021
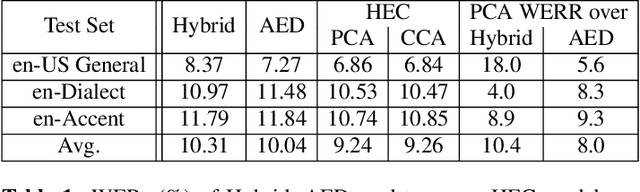
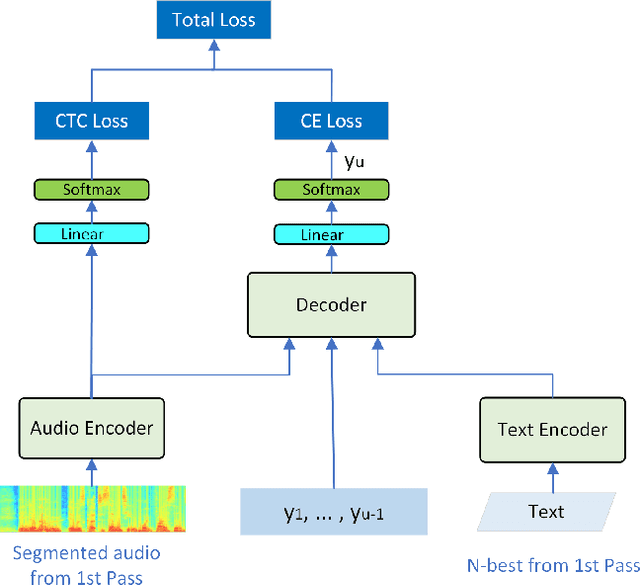
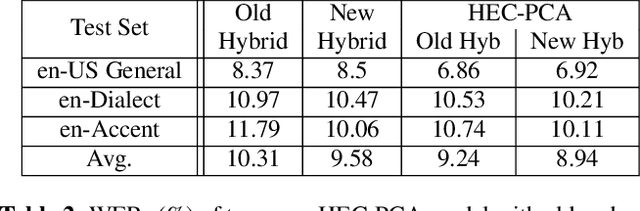
Hybrid and end-to-end (E2E) systems have their individual advantages, with different error patterns in the speech recognition results. By jointly modeling audio and text, the E2E model performs better in matched scenarios and scales well with a large amount of paired audio-text training data. The modularized hybrid model is easier for customization, and better to make use of a massive amount of unpaired text data. This paper proposes a two-pass hybrid and E2E cascading (HEC) framework to combine the hybrid and E2E model in order to take advantage of both sides, with hybrid in the first pass and E2E in the second pass. We show that the proposed system achieves 8-10% relative word error rate reduction with respect to each individual system. More importantly, compared with the pure E2E system, we show the proposed system has the potential to keep the advantages of hybrid system, e.g., customization and segmentation capabilities. We also show the second pass E2E model in HEC is robust with respect to the change in the first pass hybrid model.
An analysis of degenerating speech due to progressive dysarthria on ASR performance
Oct 31, 2022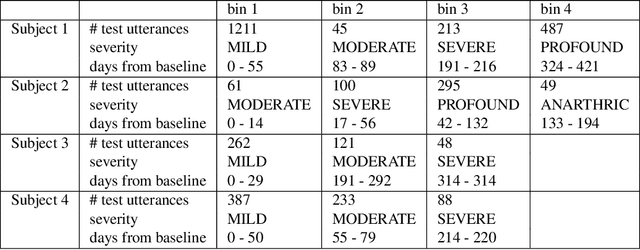
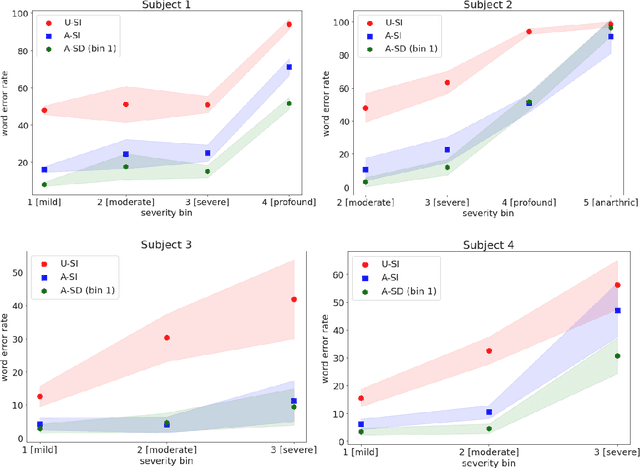

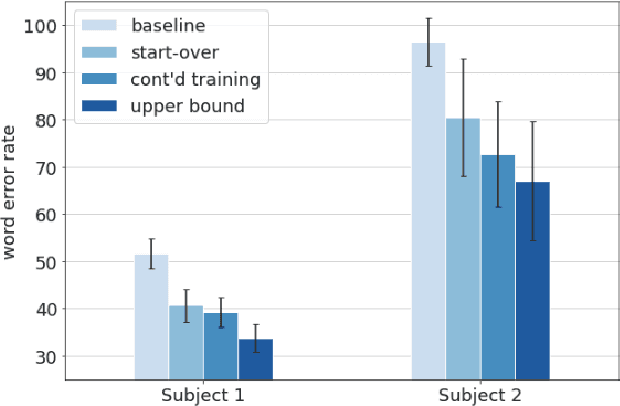
Although personalized automatic speech recognition (ASR) models have recently been designed to recognize even severely impaired speech, model performance may degrade over time for persons with degenerating speech. The aims of this study were to (1) analyze the change of performance of ASR over time in individuals with degrading speech, and (2) explore mitigation strategies to optimize recognition throughout disease progression. Speech was recorded by four individuals with degrading speech due to amyotrophic lateral sclerosis (ALS). Word error rates (WER) across recording sessions were computed for three ASR models: Unadapted Speaker Independent (U-SI), Adapted Speaker Independent (A-SI), and Adapted Speaker Dependent (A-SD or personalized). The performance of all three models degraded significantly over time as speech became more impaired, but the performance of the A-SD model improved markedly when it was updated with recordings from the severe stages of speech progression. Recording additional utterances early in the disease before speech degraded significantly did not improve the performance of A-SD models. Overall, our findings emphasize the importance of continuous recording (and model retraining) when providing personalized models for individuals with progressive speech impairments.
Rationalizing Predictions by Adversarial Information Calibration
Jan 15, 2023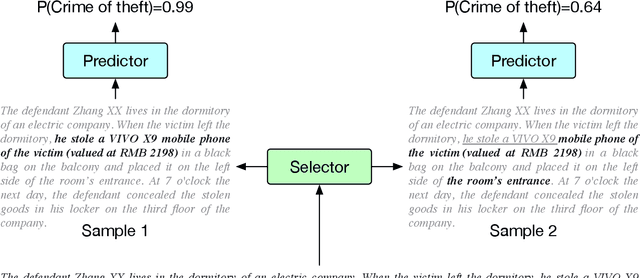
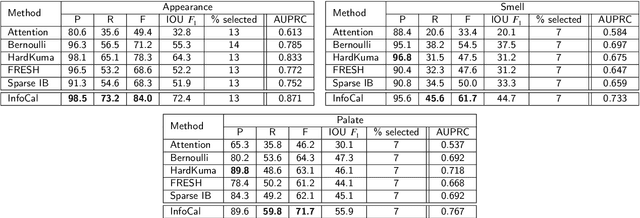
Explaining the predictions of AI models is paramount in safety-critical applications, such as in legal or medical domains. One form of explanation for a prediction is an extractive rationale, i.e., a subset of features of an instance that lead the model to give its prediction on that instance. For example, the subphrase ``he stole the mobile phone'' can be an extractive rationale for the prediction of ``Theft''. Previous works on generating extractive rationales usually employ a two-phase model: a selector that selects the most important features (i.e., the rationale) followed by a predictor that makes the prediction based exclusively on the selected features. One disadvantage of these works is that the main signal for learning to select features comes from the comparison of the answers given by the predictor to the ground-truth answers. In this work, we propose to squeeze more information from the predictor via an information calibration method. More precisely, we train two models jointly: one is a typical neural model that solves the task at hand in an accurate but black-box manner, and the other is a selector-predictor model that additionally produces a rationale for its prediction. The first model is used as a guide for the second model. We use an adversarial technique to calibrate the information extracted by the two models such that the difference between them is an indicator of the missed or over-selected features. In addition, for natural language tasks, we propose a language-model-based regularizer to encourage the extraction of fluent rationales. Experimental results on a sentiment analysis task, a hate speech recognition task as well as on three tasks from the legal domain show the effectiveness of our approach to rationale extraction.
* arXiv admin note: substantial text overlap with arXiv:2012.08884
A bandit approach to curriculum generation for automatic speech recognition
Feb 06, 2021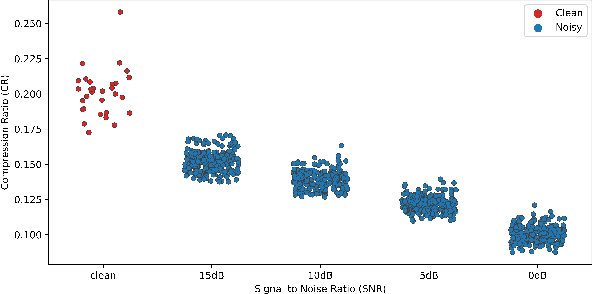
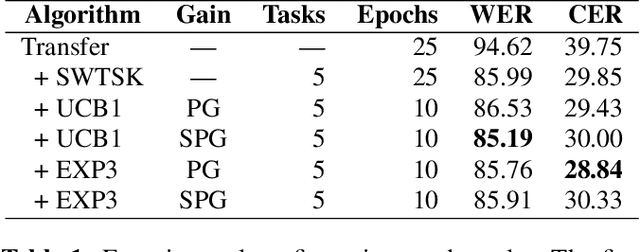
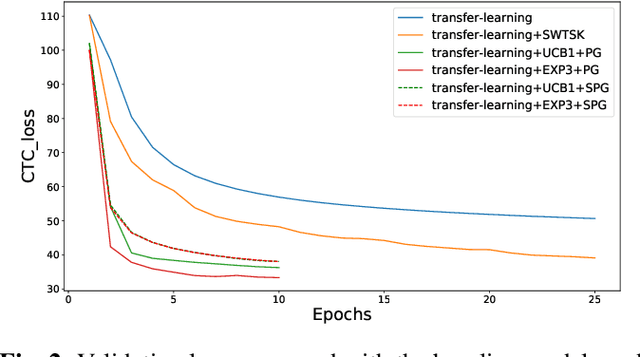
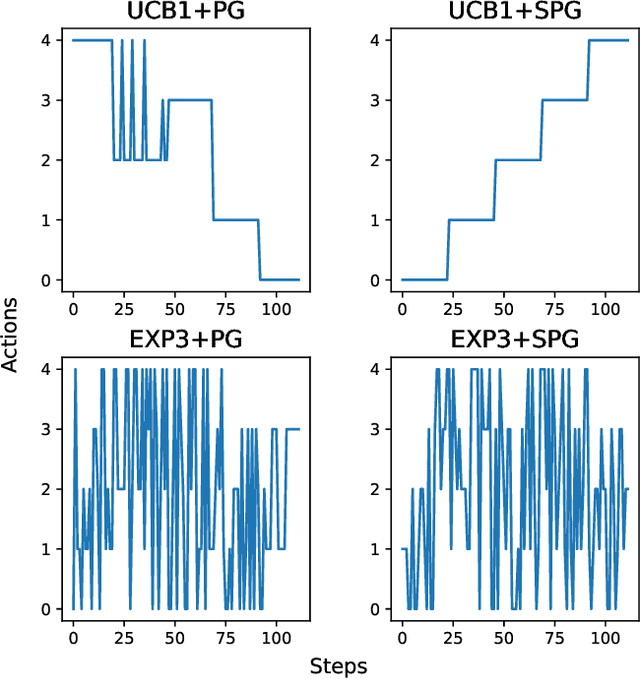
The Automated Speech Recognition (ASR) task has been a challenging domain especially for low data scenarios with few audio examples. This is the main problem in training ASR systems on the data from low-resource or marginalized languages. In this paper we present an approach to mitigate the lack of training data by employing Automated Curriculum Learning in combination with an adversarial bandit approach inspired by Reinforcement learning. The goal of the approach is to optimize the training sequence of mini-batches ranked by the level of difficulty and compare the ASR performance metrics against the random training sequence and discrete curriculum. We test our approach on a truly low-resource language and show that the bandit framework has a good improvement over the baseline transfer-learning model.
A Study on the Integration of Pre-trained SSL, ASR, LM and SLU Models for Spoken Language Understanding
Nov 10, 2022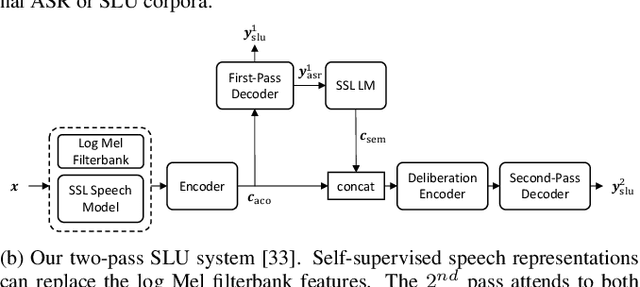
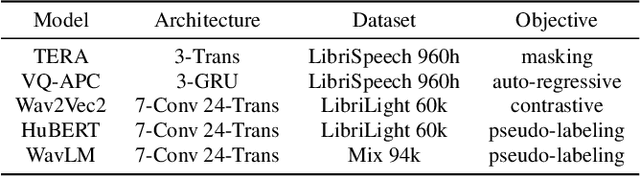
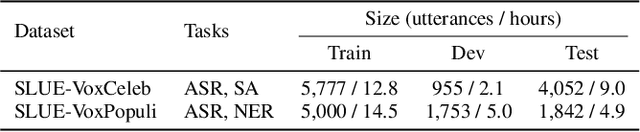
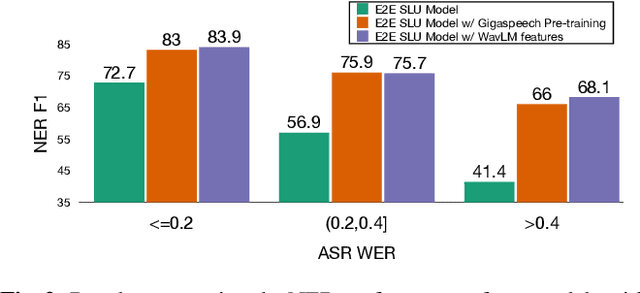
Collecting sufficient labeled data for spoken language understanding (SLU) is expensive and time-consuming. Recent studies achieved promising results by using pre-trained models in low-resource scenarios. Inspired by this, we aim to ask: which (if any) pre-training strategies can improve performance across SLU benchmarks? To answer this question, we employ four types of pre-trained models and their combinations for SLU. We leverage self-supervised speech and language models (LM) pre-trained on large quantities of unpaired data to extract strong speech and text representations. We also explore using supervised models pre-trained on larger external automatic speech recognition (ASR) or SLU corpora. We conduct extensive experiments on the SLU Evaluation (SLUE) benchmark and observe self-supervised pre-trained models to be more powerful, with pre-trained LM and speech models being most beneficial for the Sentiment Analysis and Named Entity Recognition task, respectively.
A Weakly-Supervised Streaming Multilingual Speech Model with Truly Zero-Shot Capability
Nov 04, 2022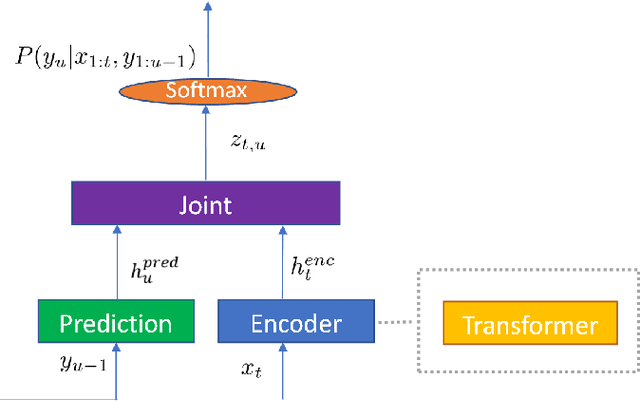

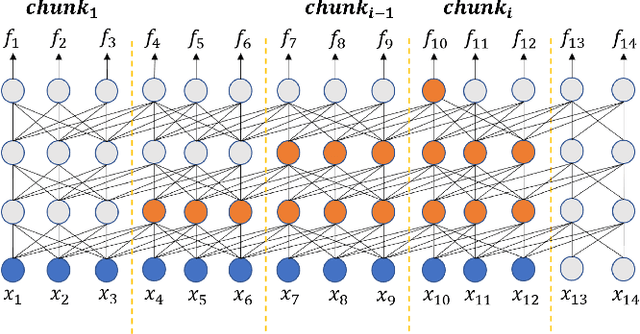

In this paper, we introduce our work of building a Streaming Multilingual Speech Model (SM2), which can transcribe or translate multiple spoken languages into texts of the target language. The backbone of SM2 is Transformer Transducer, which has high streaming capability. Instead of human labeled speech translation (ST) data, SM2 models are trained using weakly supervised data generated by converting the transcriptions in speech recognition corpora with a machine translation service. With 351 thousand hours of anonymized speech training data from 25 languages, SM2 models achieve comparable or even better ST quality than some recent popular large-scale non-streaming speech models. More importantly, we show that SM2 has the truly zero-shot capability when expanding to new target languages, yielding high quality ST results for {source-speech, target-text} pairs that are not seen during training.