 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSViT: Dynamic Mixed-Scale Tokenization for Vision Transformers
Jul 05, 2023



The input tokens to Vision Transformers carry little semantic meaning as they are defined as regular equal-sized patches of the input image, regardless of its content. However, processing uniform background areas of an image should not necessitate as much compute as dense, cluttered areas. To address this issue, we propose a dynamic mixed-scale tokenization scheme for ViT, MSViT. Our method introduces a conditional gating mechanism that selects the optimal token scale for every image region, such that the number of tokens is dynamically determined per input. The proposed gating module is lightweight, agnostic to the choice of transformer backbone, and trained within a few epochs (e.g., 20 epochs on ImageNet) with little training overhead. In addition, to enhance the conditional behavior of the gate during training, we introduce a novel generalization of the batch-shaping loss. We show that our gating module is able to learn meaningful semantics despite operating locally at the coarse patch-level. We validate MSViT on the tasks of classification and segmentation where it leads to improved accuracy-complexity trade-off.
A Brief Overview of Unsupervised Neural Speech Representation Learning
Mar 01, 2022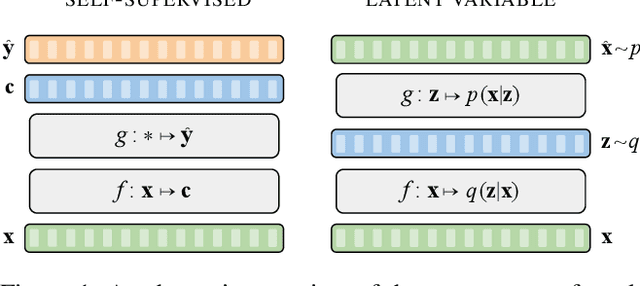
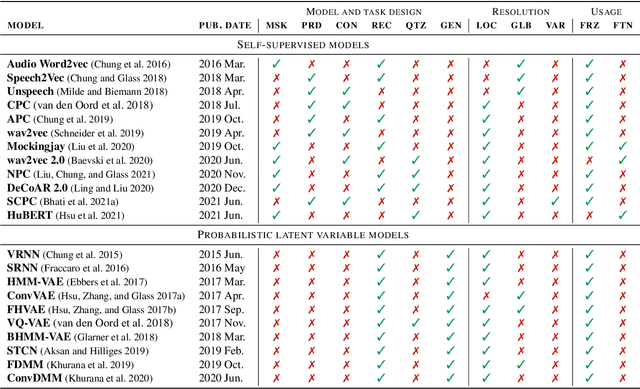
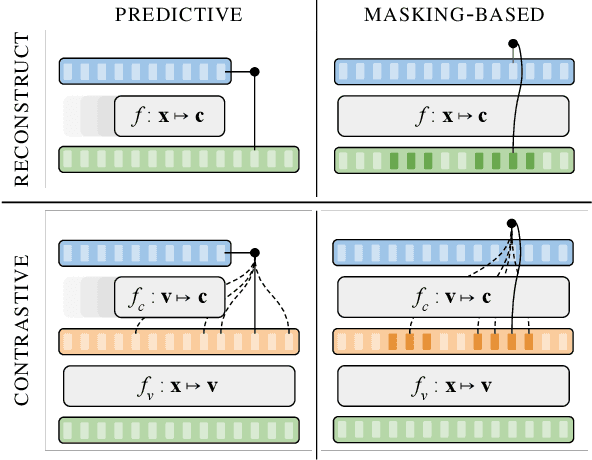
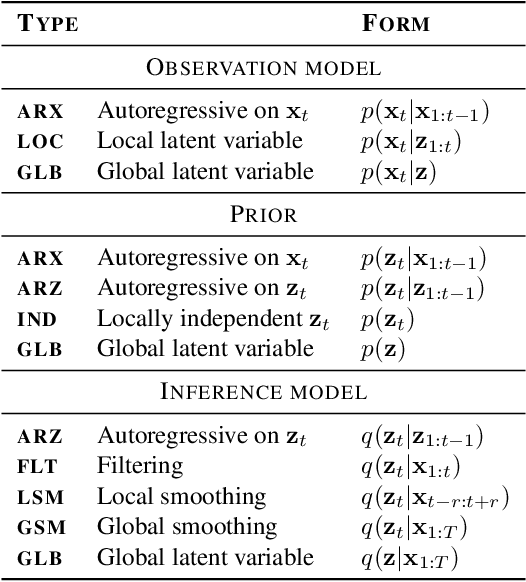
Unsupervised representation learning for speech processing has matured greatly in the last few years. Work in computer vision and natural language processing has paved the way, but speech data offers unique challenges. As a result, methods from other domains rarely translate directly. We review the development of unsupervised representation learning for speech over the last decade. We identify two primary model categories: self-supervised methods and probabilistic latent variable models. We describe the models and develop a comprehensive taxonomy. Finally, we discuss and compare models from the two categories.
Do We Still Need Automatic Speech Recognition for Spoken Language Understanding?
Nov 29, 2021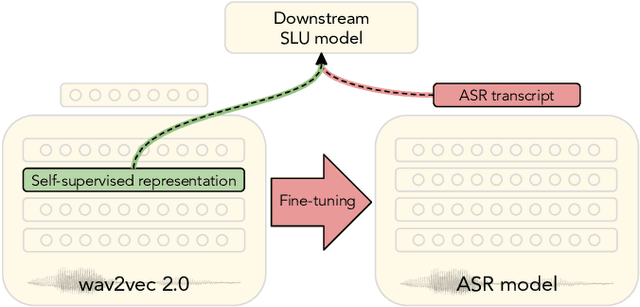

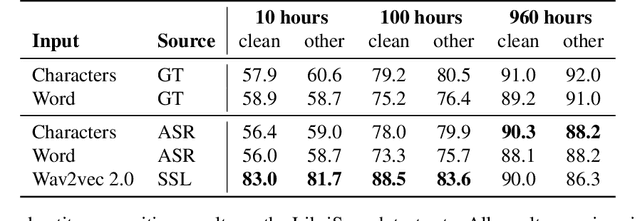

Spoken language understanding (SLU) tasks are usually solved by first transcribing an utterance with automatic speech recognition (ASR) and then feeding the output to a text-based model. Recent advances in self-supervised representation learning for speech data have focused on improving the ASR component. We investigate whether representation learning for speech has matured enough to replace ASR in SLU. We compare learned speech features from wav2vec 2.0, state-of-the-art ASR transcripts, and the ground truth text as input for a novel speech-based named entity recognition task, a cardiac arrest detection task on real-world emergency calls and two existing SLU benchmarks. We show that learned speech features are superior to ASR transcripts on three classification tasks. For machine translation, ASR transcripts are still the better choice. We highlight the intrinsic robustness of wav2vec 2.0 representations to out-of-vocabulary words as key to better performance.
Do End-to-End Speech Recognition Models Care About Context?
Feb 17, 2021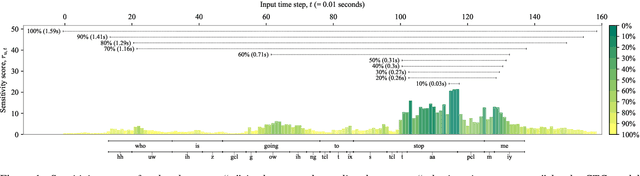
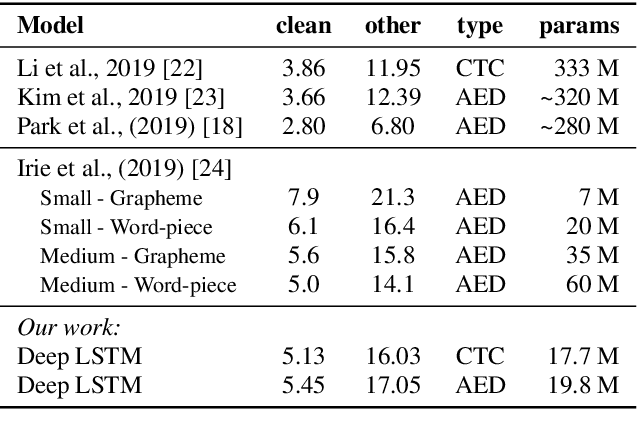
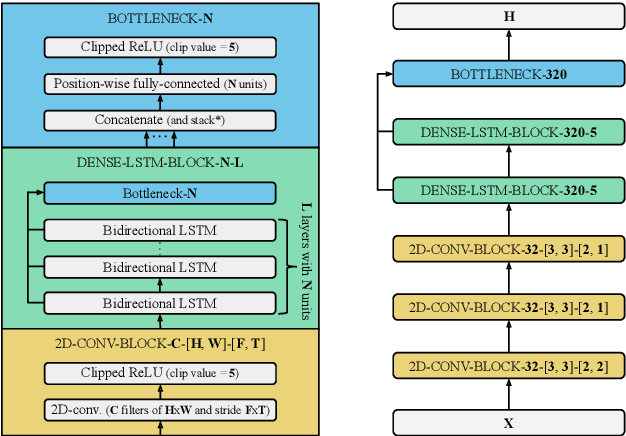
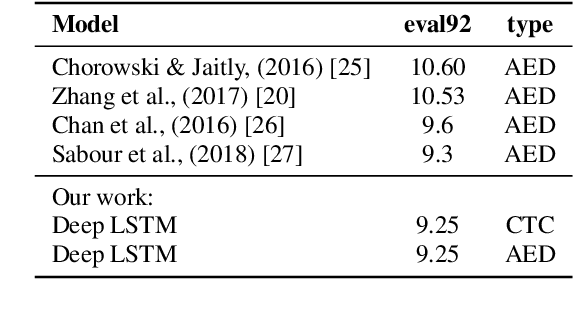
The two most common paradigms for end-to-end speech recognition are connectionist temporal classification (CTC) and attention-based encoder-decoder (AED) models. It has been argued that the latter is better suited for learning an implicit language model. We test this hypothesis by measuring temporal context sensitivity and evaluate how the models perform when we constrain the amount of contextual information in the audio input. We find that the AED model is indeed more context sensitive, but that the gap can be closed by adding self-attention to the CTC model. Furthermore, the two models perform similarly when contextual information is constrained. Finally, in contrast to previous research, our results show that the CTC model is highly competitive on WSJ and LibriSpeech without the help of an external language model.
On Scaling Contrastive Representations for Low-Resource Speech Recognition
Feb 01, 2021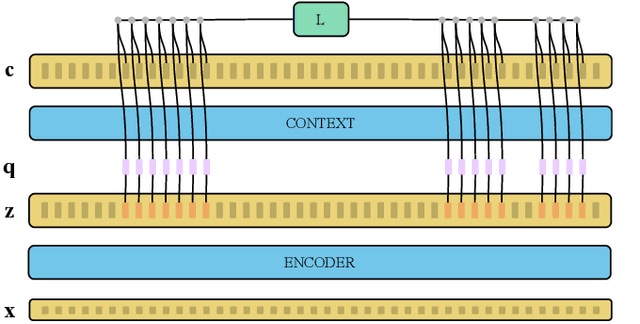
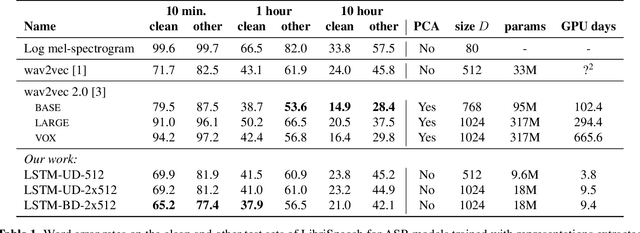
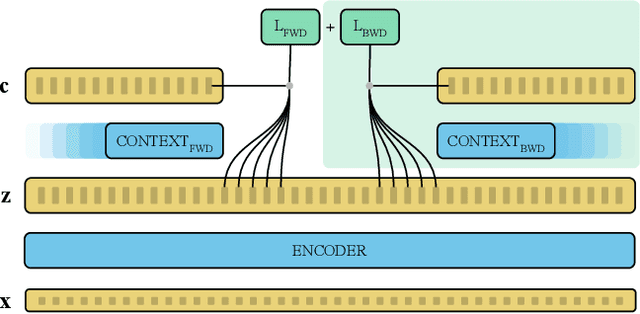
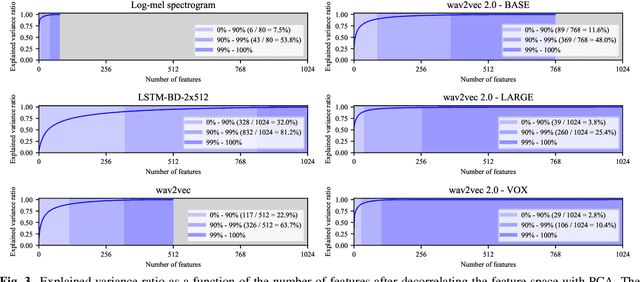
Recent advances in self-supervised learning through contrastive training have shown that it is possible to learn a competitive speech recognition system with as little as 10 minutes of labeled data. However, these systems are computationally expensive since they require pre-training followed by fine-tuning in a large parameter space. We explore the performance of such systems without fine-tuning by training a state-of-the-art speech recognizer on the fixed representations from the computationally demanding wav2vec 2.0 framework. We find performance to decrease without fine-tuning and, in the extreme low-resource setting, wav2vec 2.0 is inferior to its predecessor. In addition, we find that wav2vec 2.0 representations live in a low dimensional subspace and that decorrelating the features of the representations can stabilize training of the automatic speech recognizer. Finally, we propose a bidirectional extension to the original wav2vec framework that consistently improves performance.