 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTidyVoice 2026 Challenge Evaluation Plan
Jan 29, 2026The performance of speaker verification systems degrades significantly under language mismatch, a critical challenge exacerbated by the field's reliance on English-centric data. To address this, we propose the TidyVoice Challenge for cross-lingual speaker verification. The challenge leverages the TidyVoiceX dataset from the novel TidyVoice benchmark, a large-scale, multilingual corpus derived from Mozilla Common Voice, and specifically curated to isolate the effect of language switching across approximately 40 languages. Participants will be tasked with building systems robust to this mismatch, with performance primarily evaluated using the Equal Error Rate on cross-language trials. By providing standardized data, open-source baselines, and a rigorous evaluation protocol, this challenge aims to drive research towards fairer, more inclusive, and language-independent speaker recognition technologies, directly aligning with the Interspeech 2026 theme, "Speaking Together."
OmniLingo: Listening- and speaking-based language learning
Oct 10, 2023In this demo paper we present OmniLingo, an architecture for distributing data for listening- and speaking-based language learning applications and a demonstration client built using the architecture. The architecture is based on the Interplanetary Filesystem (IPFS) and puts at the forefront user sovereignty over data.
Yet Another Format of Universal Dependencies for Korean
Sep 20, 2022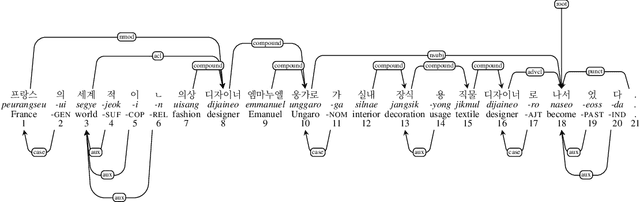

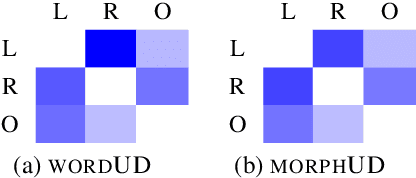
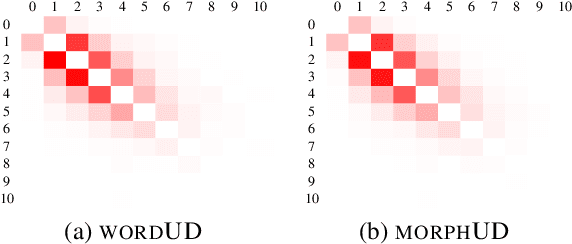
In this study, we propose a morpheme-based scheme for Korean dependency parsing and adopt the proposed scheme to Universal Dependencies. We present the linguistic rationale that illustrates the motivation and the necessity of adopting the morpheme-based format, and develop scripts that convert between the original format used by Universal Dependencies and the proposed morpheme-based format automatically. The effectiveness of the proposed format for Korean dependency parsing is then testified by both statistical and neural models, including UDPipe and Stanza, with our carefully constructed morpheme-based word embedding for Korean. morphUD outperforms parsing results for all Korean UD treebanks, and we also present detailed error analyses.
UniMorph 4.0: Universal Morphology
May 10, 2022



The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
What shall we do with an hour of data? Speech recognition for the un- and under-served languages of Common Voice
May 10, 2021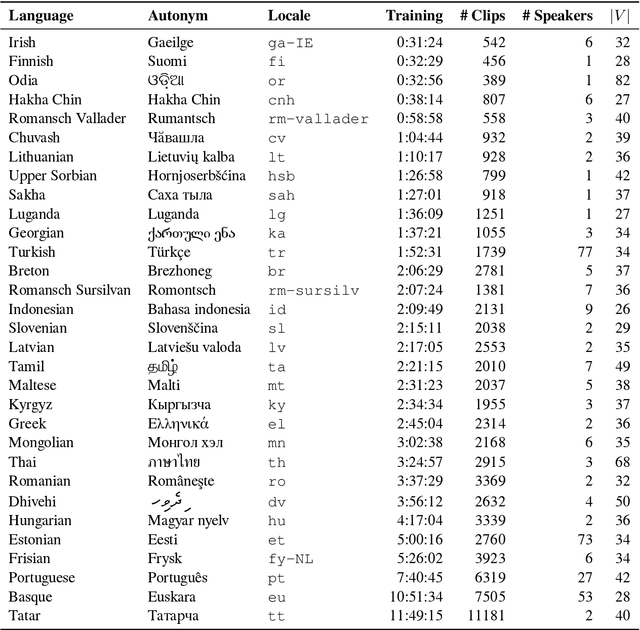
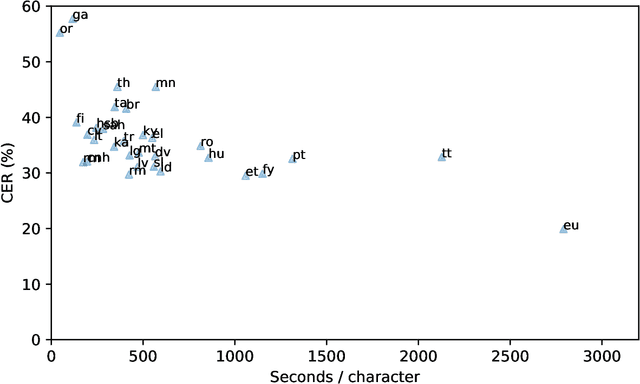
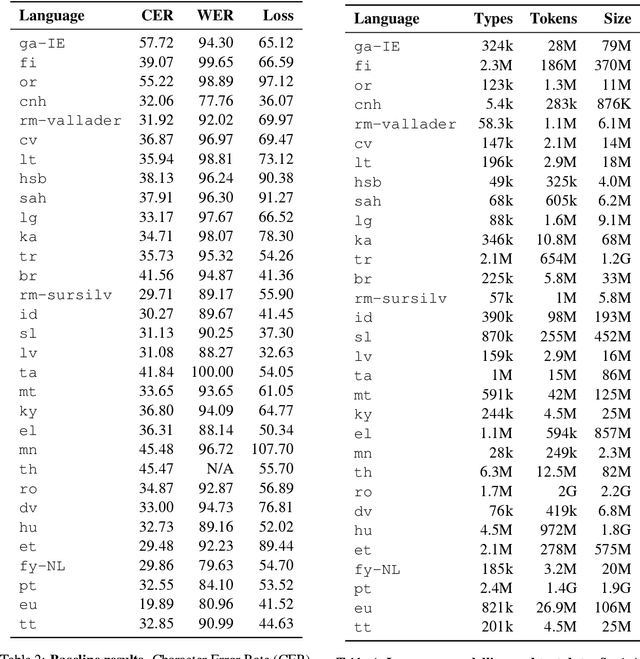
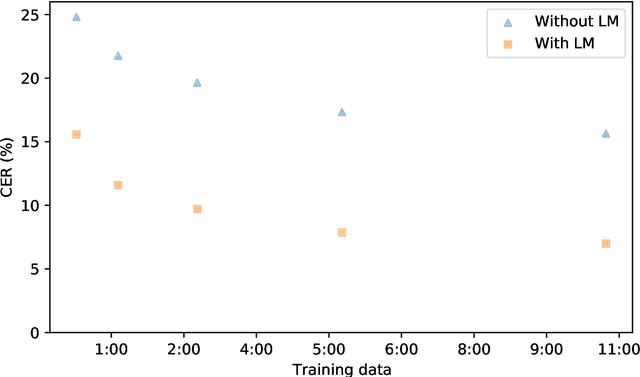
This technical report describes the methods and results of a three-week sprint to produce deployable speech recognition models for 31 under-served languages of the Common Voice project. We outline the preprocessing steps, hyperparameter selection, and resulting accuracy on official testing sets. In addition to this we evaluate the models on multiple tasks: closed-vocabulary speech recognition, pre-transcription, forced alignment, and key-word spotting. The following experiments use Coqui STT, a toolkit for training and deployment of neural Speech-to-Text models.
A bandit approach to curriculum generation for automatic speech recognition
Feb 06, 2021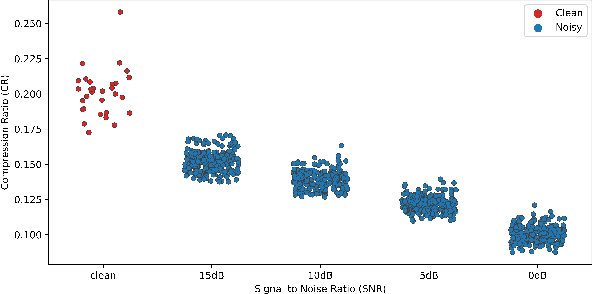
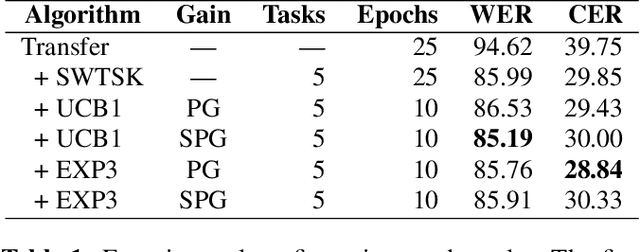
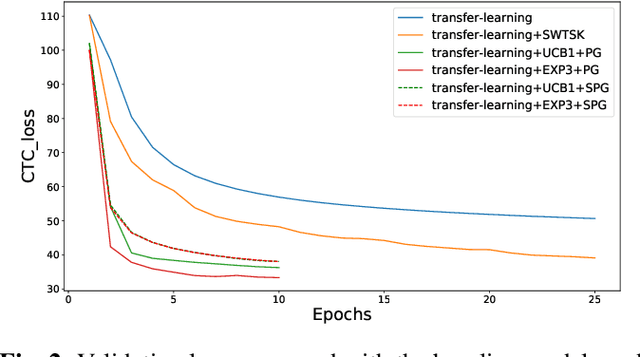
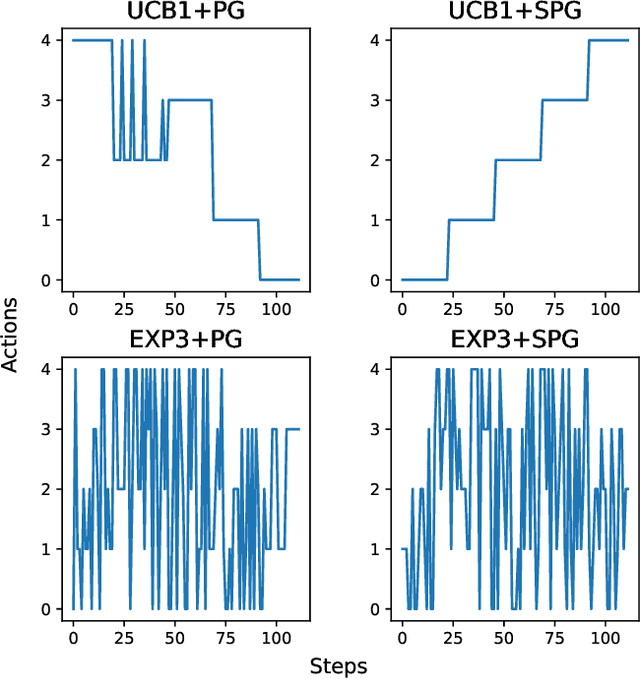
The Automated Speech Recognition (ASR) task has been a challenging domain especially for low data scenarios with few audio examples. This is the main problem in training ASR systems on the data from low-resource or marginalized languages. In this paper we present an approach to mitigate the lack of training data by employing Automated Curriculum Learning in combination with an adversarial bandit approach inspired by Reinforcement learning. The goal of the approach is to optimize the training sequence of mini-batches ranked by the level of difficulty and compare the ASR performance metrics against the random training sequence and discrete curriculum. We test our approach on a truly low-resource language and show that the bandit framework has a good improvement over the baseline transfer-learning model.
Common Voice: A Massively-Multilingual Speech Corpus
Dec 13, 2019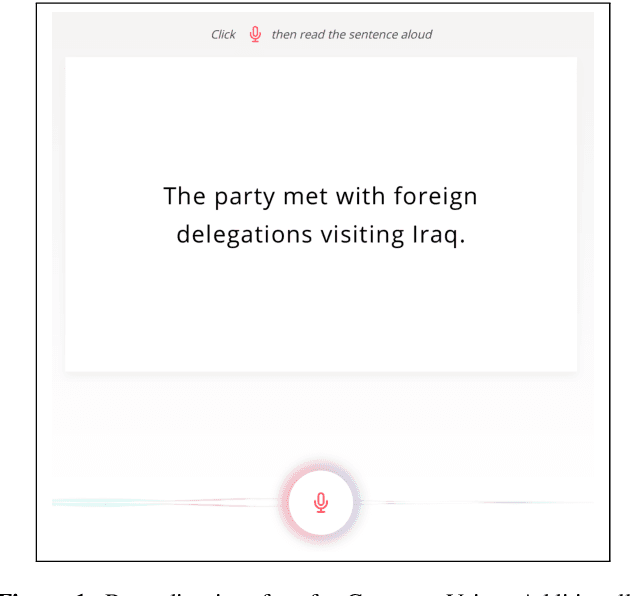
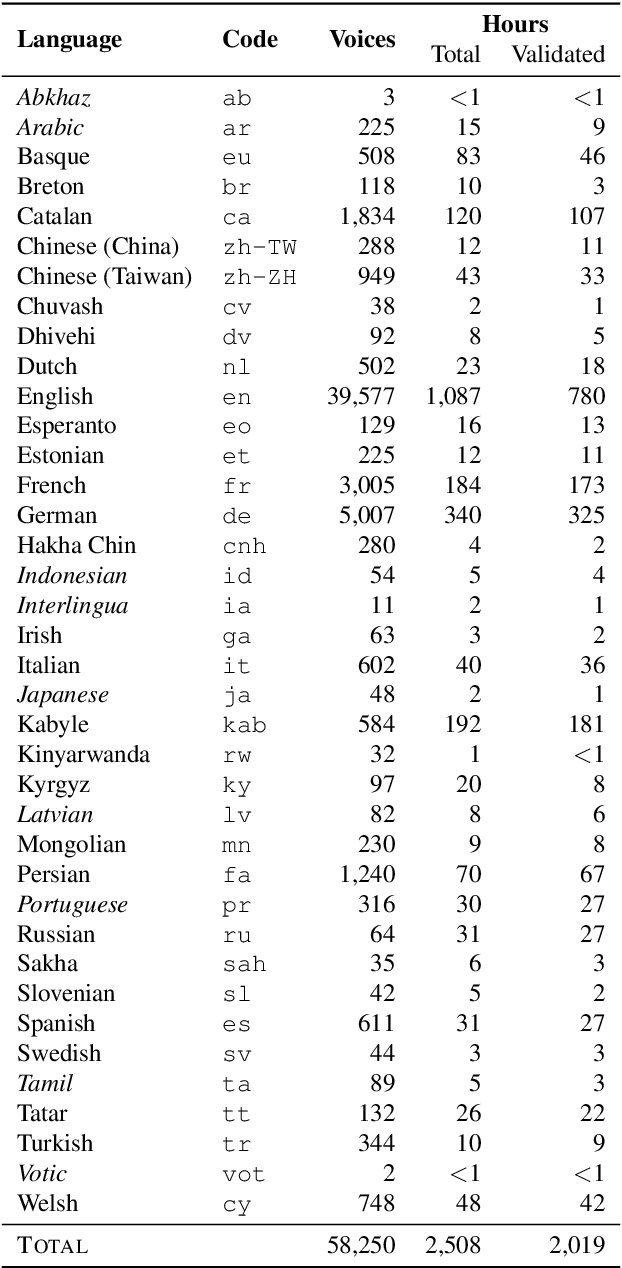
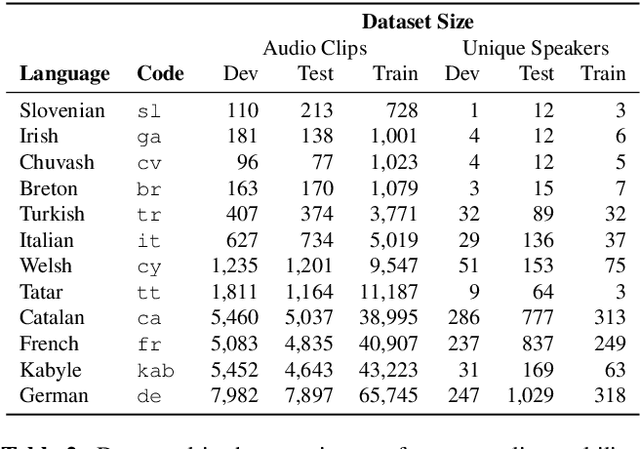
The Common Voice corpus is a massively-multilingual collection of transcribed speech intended for speech technology research and development. Common Voice is designed for Automatic Speech Recognition purposes but can be useful in other domains (e.g. language identification). To achieve scale and sustainability, the Common Voice project employs crowdsourcing for both data collection and data validation. The most recent release includes 29 languages, and as of November 2019 there are a total of 38 languages collecting data. Over 50,000 individuals have participated so far, resulting in 2,500 hours of collected audio. To our knowledge this is the largest audio corpus in the public domain for speech recognition, both in terms of number of hours and number of languages. As an example use case for Common Voice, we present speech recognition experiments using Mozilla's DeepSpeech Speech-to-Text toolkit. By applying transfer learning from a source English model, we find an average Character Error Rate improvement of 5.99 +/- 5.48 for twelve target languages (German, French, Italian, Turkish, Catalan, Slovenian, Welsh, Irish, Breton, Tatar, Chuvash, and Kabyle). For most of these languages, these are the first ever published results on end-to-end Automatic Speech Recognition.
Can LSTM Learn to Capture Agreement? The Case of Basque
Sep 21, 2018
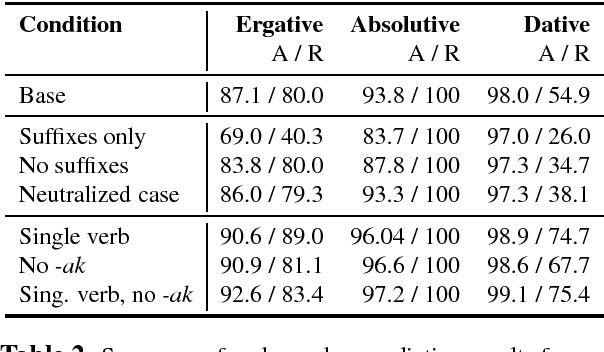

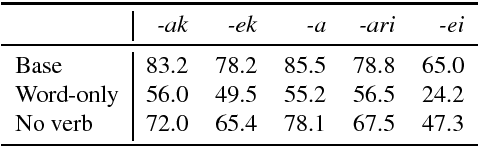
Sequential neural networks models are powerful tools in a variety of Natural Language Processing (NLP) tasks. The sequential nature of these models raises the questions: to what extent can these models implicitly learn hierarchical structures typical to human language, and what kind of grammatical phenomena can they acquire? We focus on the task of agreement prediction in Basque, as a case study for a task that requires implicit understanding of sentence structure and the acquisition of a complex but consistent morphological system. Analyzing experimental results from two syntactic prediction tasks - verb number prediction and suffix recovery - we find that sequential models perform worse on agreement prediction in Basque than one might expect on the basis of a previous agreement prediction work in English. Tentative findings based on diagnostic classifiers suggest the network makes use of local heuristics as a proxy for the hierarchical structure of the sentence. We propose the Basque agreement prediction task as challenging benchmark for models that attempt to learn regularities in human language.