 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cookbook for Community-driven Data Collection of Impaired Speech in LowResource Languages
Jul 03, 2025This study presents an approach for collecting speech samples to build Automatic Speech Recognition (ASR) models for impaired speech, particularly, low-resource languages. It aims to democratize ASR technology and data collection by developing a "cookbook" of best practices and training for community-driven data collection and ASR model building. As a proof-of-concept, this study curated the first open-source dataset of impaired speech in Akan: a widely spoken indigenous language in Ghana. The study involved participants from diverse backgrounds with speech impairments. The resulting dataset, along with the cookbook and open-source tools, are publicly available to enable researchers and practitioners to create inclusive ASR technologies tailored to the unique needs of speech impaired individuals. In addition, this study presents the initial results of fine-tuning open-source ASR models to better recognize impaired speech in Akan.
Learnings from curating a trustworthy, well-annotated, and useful dataset of disordered English speech
Sep 13, 2024

Project Euphonia, a Google initiative, is dedicated to improving automatic speech recognition (ASR) of disordered speech. A central objective of the project is to create a large, high-quality, and diverse speech corpus. This report describes the project's latest advancements in data collection and annotation methodologies, such as expanding speaker diversity in the database, adding human-reviewed transcript corrections and audio quality tags to 350K (of the 1.2M total) audio recordings, and amassing a comprehensive set of metadata (including more than 40 speech characteristic labels) for over 75\% of the speakers in the database. We report on the impact of transcript corrections on our machine-learning (ML) research, inter-rater variability of assessments of disordered speech patterns, and our rationale for gathering speech metadata. We also consider the limitations of using automated off-the-shelf annotation methods for assessing disordered speech.
An analysis of degenerating speech due to progressive dysarthria on ASR performance
Oct 31, 2022



Although personalized automatic speech recognition (ASR) models have recently been designed to recognize even severely impaired speech, model performance may degrade over time for persons with degenerating speech. The aims of this study were to (1) analyze the change of performance of ASR over time in individuals with degrading speech, and (2) explore mitigation strategies to optimize recognition throughout disease progression. Speech was recorded by four individuals with degrading speech due to amyotrophic lateral sclerosis (ALS). Word error rates (WER) across recording sessions were computed for three ASR models: Unadapted Speaker Independent (U-SI), Adapted Speaker Independent (A-SI), and Adapted Speaker Dependent (A-SD or personalized). The performance of all three models degraded significantly over time as speech became more impaired, but the performance of the A-SD model improved markedly when it was updated with recordings from the severe stages of speech progression. Recording additional utterances early in the disease before speech degraded significantly did not improve the performance of A-SD models. Overall, our findings emphasize the importance of continuous recording (and model retraining) when providing personalized models for individuals with progressive speech impairments.
Assessing ASR Model Quality on Disordered Speech using BERTScore
Sep 21, 2022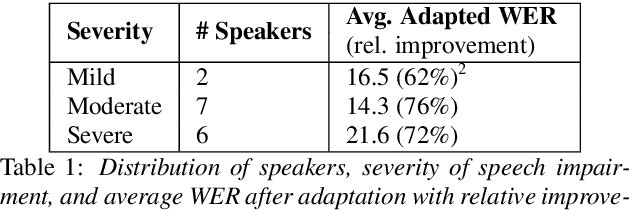
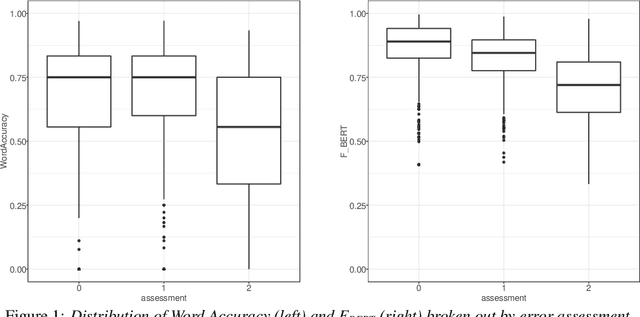
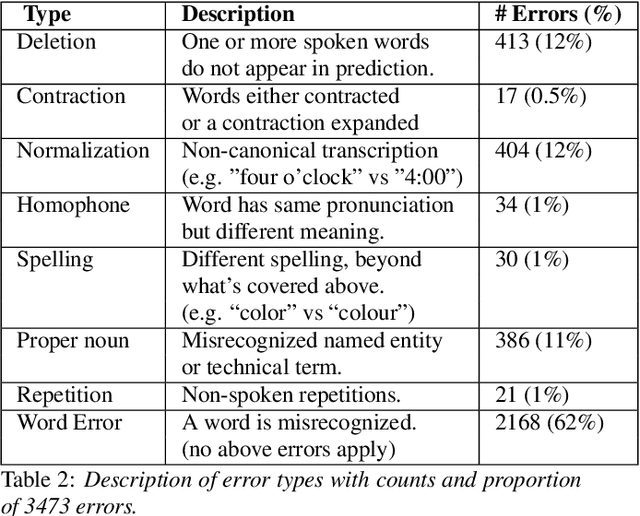
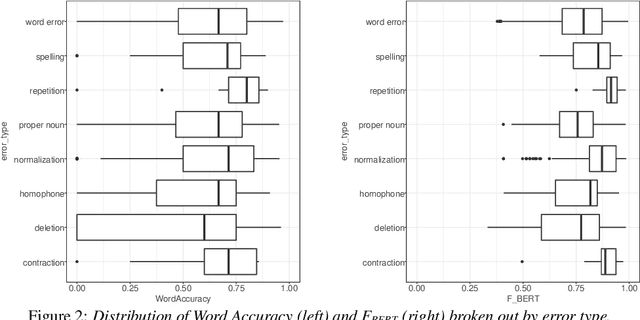
Word Error Rate (WER) is the primary metric used to assess automatic speech recognition (ASR) model quality. It has been shown that ASR models tend to have much higher WER on speakers with speech impairments than typical English speakers. It is hard to determine if models can be be useful at such high error rates. This study investigates the use of BERTScore, an evaluation metric for text generation, to provide a more informative measure of ASR model quality and usefulness. Both BERTScore and WER were compared to prediction errors manually annotated by Speech Language Pathologists for error type and assessment. BERTScore was found to be more correlated with human assessment of error type and assessment. BERTScore was specifically more robust to orthographic changes (contraction and normalization errors) where meaning was preserved. Furthermore, BERTScore was a better fit of error assessment than WER, as measured using an ordinal logistic regression and the Akaike's Information Criterion (AIC). Overall, our findings suggest that BERTScore can complement WER when assessing ASR model performance from a practical perspective, especially for accessibility applications where models are useful even at lower accuracy than for typical speech.