 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALAS: Measuring Latent Speech-Text Alignment For Spoken Language Understanding In Multimodal LLMs
May 26, 2025Large Language Models (LLMs) are widely used in Spoken Language Understanding (SLU). Recent SLU models process audio directly by adapting speech input into LLMs for better multimodal learning. A key consideration for these models is the cross-modal alignment between text and audio modalities, which is a telltale sign as to whether or not LLM is able to associate semantic meaning to audio segments. While various methods exist for fusing these modalities, there is no standard metric to evaluate alignment quality in LLMs. In this work, we propose a new metric, ALAS (Automatic Latent Alignment Score). Our study examines the correlation between audio and text representations across transformer layers, for two different tasks (Spoken Question Answering and Emotion Recognition). We showcase that our metric behaves as expected across different layers and different tasks.
Calm-Whisper: Reduce Whisper Hallucination On Non-Speech By Calming Crazy Heads Down
May 19, 2025OpenAI's Whisper has achieved significant success in Automatic Speech Recognition. However, it has consistently been found to exhibit hallucination issues, particularly in non-speech segments, which limits its broader application in complex industrial settings. In this paper, we introduce a novel method to reduce Whisper's hallucination on non-speech segments without using any pre- or post-possessing techniques. Specifically, we benchmark the contribution of each self-attentional head in the Whisper-large-v3 decoder to the hallucination problem by performing a head-wise mask. Our findings reveal that only 3 of the 20 heads account for over 75% of the hallucinations on the UrbanSound dataset. We then fine-tune these three crazy heads using a collection of non-speech data. The results show that our best fine-tuned model, namely Calm-Whisper, achieves over 80% reduction in non-speech hallucination with only less than 0.1% WER degradation on LibriSpeech test-clean and test-other.
Open Universal Arabic ASR Leaderboard
Dec 18, 2024In recent years, the enhanced capabilities of ASR models and the emergence of multi-dialect datasets have increasingly pushed Arabic ASR model development toward an all-dialect-in-one direction. This trend highlights the need for benchmarking studies that evaluate model performance on multiple dialects, providing the community with insights into models' generalization capabilities. In this paper, we introduce Open Universal Arabic ASR Leaderboard, a continuous benchmark project for open-source general Arabic ASR models across various multi-dialect datasets. We also provide a comprehensive analysis of the model's robustness, speaker adaptation, inference efficiency, and memory consumption. This work aims to offer the Arabic ASR community a reference for models' general performance and also establish a common evaluation framework for multi-dialectal Arabic ASR models.
What Are They Doing? Joint Audio-Speech Co-Reasoning
Sep 22, 2024


In audio and speech processing, tasks usually focus on either the audio or speech modality, even when both sounds and human speech are present in the same audio clip. Recent Auditory Large Language Models (ALLMs) have made it possible to process audio and speech simultaneously within a single model, leading to further considerations of joint audio-speech tasks. In this paper, we investigate how well ALLMs can perform joint audio-speech processing. Specifically, we introduce Joint Audio-Speech Co-Reasoning (JASCO), a novel task that unifies audio and speech processing, strictly requiring co-reasoning across both modalities. We release a scene-reasoning dataset called "What Are They Doing" and establish a joint audio-speech benchmark to evaluate the joint reasoning capability of popular ALLMs. Additionally, we provide deeper insights into the models' behaviors by analyzing their dependence on each modality.
Open-Source Conversational AI with SpeechBrain 1.0
Jul 02, 2024

SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech recognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks
Speech Emotion Diarization: Which Emotion Appears When?
Jun 22, 2023Speech Emotion Recognition (SER) typically relies on utterance-level solutions. However, emotions conveyed through speech should be considered as discrete speech events with definite temporal boundaries, rather than attributes of the entire utterance. To reflect the fine-grained nature of speech emotions, we propose a new task: Speech Emotion Diarization (SED). Just as Speaker Diarization answers the question of "Who speaks when?", Speech Emotion Diarization answers the question of "Which emotion appears when?". To facilitate the evaluation of the performance and establish a common benchmark for researchers, we introduce the Zaion Emotion Dataset (ZED), an openly accessible speech emotion dataset that includes non-acted emotions recorded in real-life conditions, along with manually-annotated boundaries of emotion segments within the utterance. We provide competitive baselines and open-source the code and the pre-trained models.
A Fine-tuned Wav2vec 2.0/HuBERT Benchmark For Speech Emotion Recognition, Speaker Verification and Spoken Language Understanding
Nov 04, 2021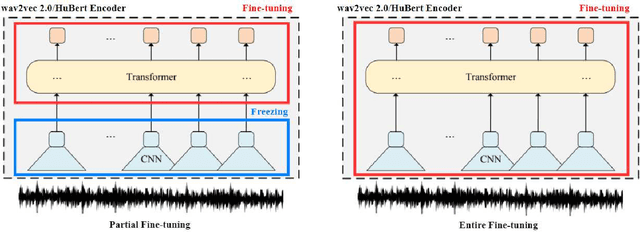
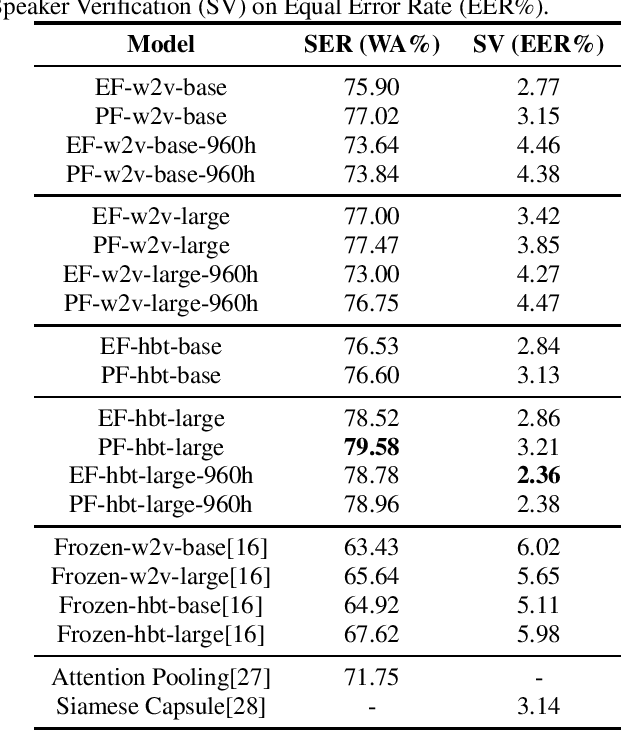
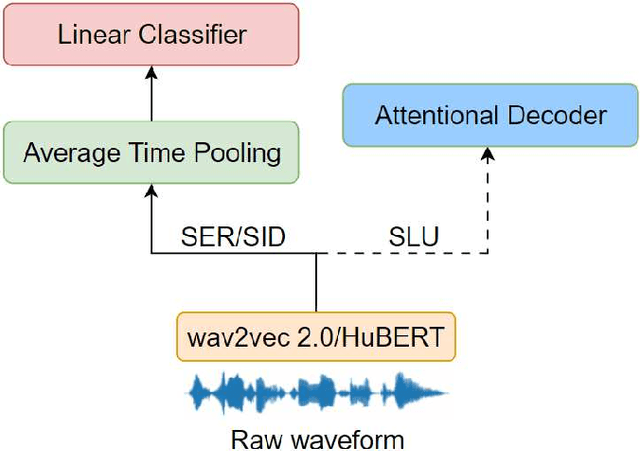
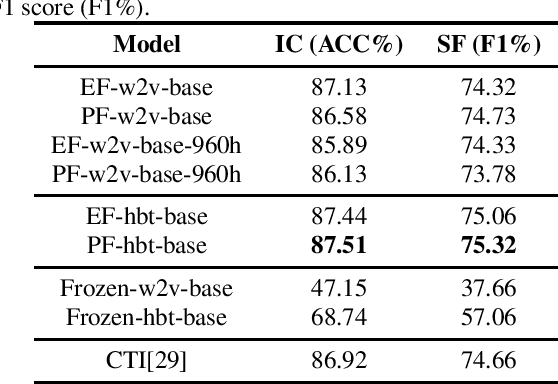
Self-supervised speech representations such as wav2vec 2.0 and HuBERT are making revolutionary progress in Automatic Speech Recognition (ASR). However, self-supervised models have not been totally proved to produce better performance on tasks other than ASR. In this work, we explore partial fine-tuning and entire fine-tuning on wav2vec 2.0 and HuBERT pre-trained models for three non-ASR speech tasks : Speech Emotion Recognition, Speaker Verification and Spoken Language Understanding. We also compare pre-trained models with/without ASR fine-tuning. With simple down-stream frameworks, the best scores reach 79.58% weighted accuracy for Speech Emotion Recognition on IEMOCAP, 2.36% equal error rate for Speaker Verification on VoxCeleb1, 87.51% accuracy for Intent Classification and 75.32% F1 for Slot Filling on SLURP, thus setting a new state-of-the-art for these three benchmarks, proving that fine-tuned wav2vec 2.0 and HuBERT models can better learn prosodic, voice-print and semantic representations.