 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgephoto style transfer
Papers and Code
AdaCM: Adaptive ColorMLP for Real-Time Universal Photo-realistic Style Transfer
Dec 03, 2022Photo-realistic style transfer aims at migrating the artistic style from an exemplar style image to a content image, producing a result image without spatial distortions or unrealistic artifacts. Impressive results have been achieved by recent deep models. However, deep neural network based methods are too expensive to run in real-time. Meanwhile, bilateral grid based methods are much faster but still contain artifacts like overexposure. In this work, we propose the \textbf{Adaptive ColorMLP (AdaCM)}, an effective and efficient framework for universal photo-realistic style transfer. First, we find the complex non-linear color mapping between input and target domain can be efficiently modeled by a small multi-layer perceptron (ColorMLP) model. Then, in \textbf{AdaCM}, we adopt a CNN encoder to adaptively predict all parameters for the ColorMLP conditioned on each input content and style image pair. Experimental results demonstrate that AdaCM can generate vivid and high-quality stylization results. Meanwhile, our AdaCM is ultrafast and can process a 4K resolution image in 6ms on one V100 GPU.
Using Decoupled Features for Photo-realistic Style Transfer
Dec 05, 2022In this work we propose a photorealistic style transfer method for image and video that is based on vision science principles and on a recent mathematical formulation for the deterministic decoupling of sample statistics. The novel aspects of our approach include matching decoupled moments of higher order than in common style transfer approaches, and matching a descriptor of the power spectrum so as to characterize and transfer diffusion effects between source and target, which is something that has not been considered before in the literature. The results are of high visual quality, without spatio-temporal artifacts, and validation tests in the form of observer preference experiments show that our method compares very well with the state-of-the-art. The computational complexity of the algorithm is low, and we propose a numerical implementation that is amenable for real-time video application. Finally, another contribution of our work is to point out that current deep learning approaches for photorealistic style transfer don't really achieve photorealistic quality outside of limited examples, because the results too often show unacceptable visual artifacts.
One-Shot Stylization for Full-Body Human Images
Apr 14, 2023



The goal of human stylization is to transfer full-body human photos to a style specified by a single art character reference image. Although previous work has succeeded in example-based stylization of faces and generic scenes, full-body human stylization is a more complex domain. This work addresses several unique challenges of stylizing full-body human images. We propose a method for one-shot fine-tuning of a pose-guided human generator to preserve the "content" (garments, face, hair, pose) of the input photo and the "style" of the artistic reference. Since body shape deformation is an essential component of an art character's style, we incorporate a novel skeleton deformation module to reshape the pose of the input person and modify the DiOr pose-guided person generator to be more robust to the rescaled poses falling outside the distribution of the realistic poses that the generator is originally trained on. Several human studies verify the effectiveness of our approach.
Style Transfer for 2D Talking Head Animation
Mar 22, 2023



Audio-driven talking head animation is a challenging research topic with many real-world applications. Recent works have focused on creating photo-realistic 2D animation, while learning different talking or singing styles remains an open problem. In this paper, we present a new method to generate talking head animation with learnable style references. Given a set of style reference frames, our framework can reconstruct 2D talking head animation based on a single input image and an audio stream. Our method first produces facial landmarks motion from the audio stream and constructs the intermediate style patterns from the style reference images. We then feed both outputs into a style-aware image generator to generate the photo-realistic and fidelity 2D animation. In practice, our framework can extract the style information of a specific character and transfer it to any new static image for talking head animation. The intensive experimental results show that our method achieves better results than recent state-of-the-art approaches qualitatively and quantitatively.
One-shot Unsupervised Domain Adaptation with Personalized Diffusion Models
Mar 31, 2023



Adapting a segmentation model from a labeled source domain to a target domain, where a single unlabeled datum is available, is one the most challenging problems in domain adaptation and is otherwise known as one-shot unsupervised domain adaptation (OSUDA). Most of the prior works have addressed the problem by relying on style transfer techniques, where the source images are stylized to have the appearance of the target domain. Departing from the common notion of transferring only the target ``texture'' information, we leverage text-to-image diffusion models (e.g., Stable Diffusion) to generate a synthetic target dataset with photo-realistic images that not only faithfully depict the style of the target domain, but are also characterized by novel scenes in diverse contexts. The text interface in our method Data AugmenTation with diffUsion Models (DATUM) endows us with the possibility of guiding the generation of images towards desired semantic concepts while respecting the original spatial context of a single training image, which is not possible in existing OSUDA methods. Extensive experiments on standard benchmarks show that our DATUM surpasses the state-of-the-art OSUDA methods by up to +7.1%. The implementation is available at https://github.com/yasserben/DATUM
Few-shots Portrait Generation with Style Enhancement and Identity Preservation
Mar 01, 2023



Nowadays, the wide application of virtual digital human promotes the comprehensive prosperity and development of digital culture supported by digital economy. The personalized portrait automatically generated by AI technology needs both the natural artistic style and human sentiment. In this paper, we propose a novel StyleIdentityGAN model, which can ensure the identity and artistry of the generated portrait at the same time. Specifically, the style-enhanced module focuses on artistic style features decoupling and transferring to improve the artistry of generated virtual face images. Meanwhile, the identity-enhanced module preserves the significant features extracted from the input photo. Furthermore, the proposed method requires a small number of reference style data. Experiments demonstrate the superiority of StyleIdentityGAN over state-of-art methods in artistry and identity effects, with comparisons done qualitatively, quantitatively and through a perceptual user study. Code has been released on Github3.
AgileGAN3D: Few-Shot 3D Portrait Stylization by Augmented Transfer Learning
Mar 24, 2023While substantial progresses have been made in automated 2D portrait stylization, admirable 3D portrait stylization from a single user photo remains to be an unresolved challenge. One primary obstacle here is the lack of high quality stylized 3D training data. In this paper, we propose a novel framework \emph{AgileGAN3D} that can produce 3D artistically appealing and personalized portraits with detailed geometry. New stylization can be obtained with just a few (around 20) unpaired 2D exemplars. We achieve this by first leveraging existing 2D stylization capabilities, \emph{style prior creation}, to produce a large amount of augmented 2D style exemplars. These augmented exemplars are generated with accurate camera pose labels, as well as paired real face images, which prove to be critical for the downstream 3D stylization task. Capitalizing on the recent advancement of 3D-aware GAN models, we perform \emph{guided transfer learning} on a pretrained 3D GAN generator to produce multi-view-consistent stylized renderings. In order to achieve 3D GAN inversion that can preserve subject's identity well, we incorporate \emph{multi-view consistency loss} in the training of our encoder. Our pipeline demonstrates strong capability in turning user photos into a diverse range of 3D artistic portraits. Both qualitative results and quantitative evaluations have been conducted to show the superior performance of our method. Code and pretrained models will be released for reproduction purpose.
CCPL: Contrastive Coherence Preserving Loss for Versatile Style Transfer
Jul 19, 2022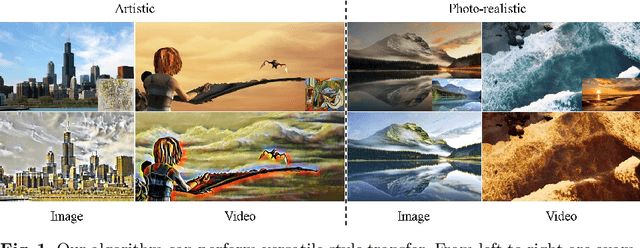
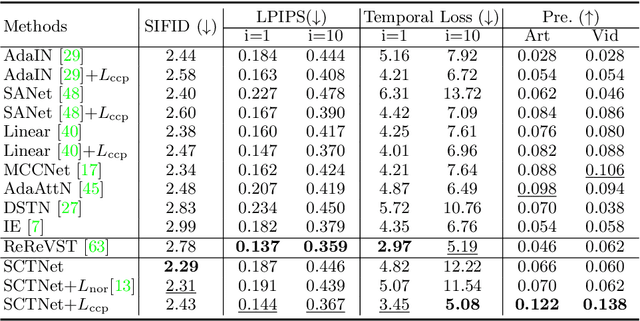
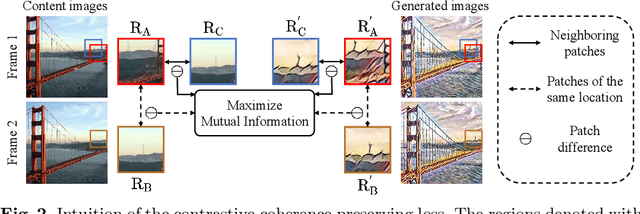

In this paper, we aim to devise a universally versatile style transfer method capable of performing artistic, photo-realistic, and video style transfer jointly, without seeing videos during training. Previous single-frame methods assume a strong constraint on the whole image to maintain temporal consistency, which could be violated in many cases. Instead, we make a mild and reasonable assumption that global inconsistency is dominated by local inconsistencies and devise a generic Contrastive Coherence Preserving Loss (CCPL) applied to local patches. CCPL can preserve the coherence of the content source during style transfer without degrading stylization. Moreover, it owns a neighbor-regulating mechanism, resulting in a vast reduction of local distortions and considerable visual quality improvement. Aside from its superior performance on versatile style transfer, it can be easily extended to other tasks, such as image-to-image translation. Besides, to better fuse content and style features, we propose Simple Covariance Transformation (SCT) to effectively align second-order statistics of the content feature with the style feature. Experiments demonstrate the effectiveness of the resulting model for versatile style transfer, when armed with CCPL.
Face Generation and Editing with StyleGAN: A Survey
Dec 18, 2022



Our goal with this survey is to provide an overview of the state of the art deep learning technologies for face generation and editing. We will cover popular latest architectures and discuss key ideas that make them work, such as inversion, latent representation, loss functions, training procedures, editing methods, and cross domain style transfer. We particularly focus on GAN-based architectures that have culminated in the StyleGAN approaches, which allow generation of high-quality face images and offer rich interfaces for controllable semantics editing and preserving photo quality. We aim to provide an entry point into the field for readers that have basic knowledge about the field of deep learning and are looking for an accessible introduction and overview.
StyleFlow For Content-Fixed Image to Image Translation
Jul 05, 2022

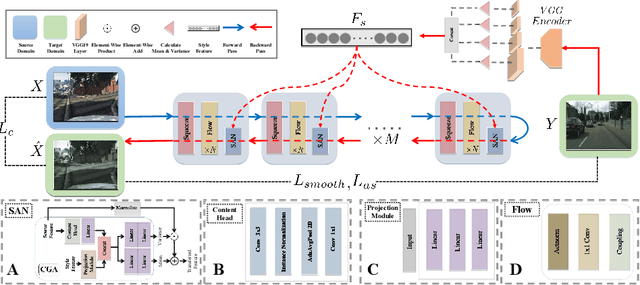

Image-to-image (I2I) translation is a challenging topic in computer vision. We divide this problem into three tasks: strongly constrained translation, normally constrained translation, and weakly constrained translation. The constraint here indicates the extent to which the content or semantic information in the original image is preserved. Although previous approaches have achieved good performance in weakly constrained tasks, they failed to fully preserve the content in both strongly and normally constrained tasks, including photo-realism synthesis, style transfer, and colorization, etc. To achieve content-preserving transfer in strongly constrained and normally constrained tasks, we propose StyleFlow, a new I2I translation model that consists of normalizing flows and a novel Style-Aware Normalization (SAN) module. With the invertible network structure, StyleFlow first projects input images into deep feature space in the forward pass, while the backward pass utilizes the SAN module to perform content-fixed feature transformation and then projects back to image space. Our model supports both image-guided translation and multi-modal synthesis. We evaluate our model in several I2I translation benchmarks, and the results show that the proposed model has advantages over previous methods in both strongly constrained and normally constrained tasks.