 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Decoupled Features for Photo-realistic Style Transfer
Dec 05, 2022In this work we propose a photorealistic style transfer method for image and video that is based on vision science principles and on a recent mathematical formulation for the deterministic decoupling of sample statistics. The novel aspects of our approach include matching decoupled moments of higher order than in common style transfer approaches, and matching a descriptor of the power spectrum so as to characterize and transfer diffusion effects between source and target, which is something that has not been considered before in the literature. The results are of high visual quality, without spatio-temporal artifacts, and validation tests in the form of observer preference experiments show that our method compares very well with the state-of-the-art. The computational complexity of the algorithm is low, and we propose a numerical implementation that is amenable for real-time video application. Finally, another contribution of our work is to point out that current deep learning approaches for photorealistic style transfer don't really achieve photorealistic quality outside of limited examples, because the results too often show unacceptable visual artifacts.
Learning Football Body-Orientation as a Matter of Classification
Jun 01, 2021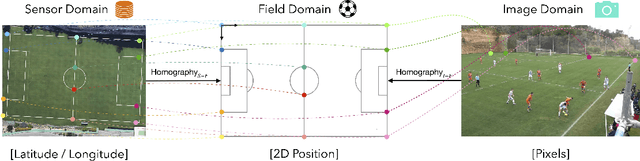
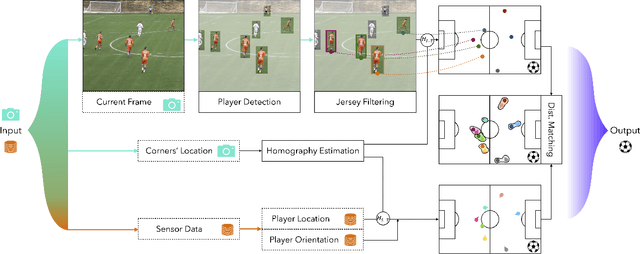
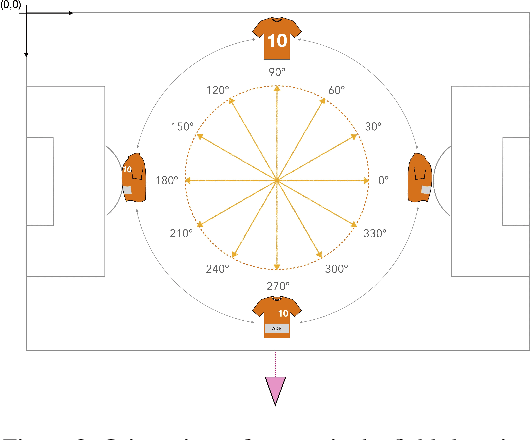
Orientation is a crucial skill for football players that becomes a differential factor in a large set of events, especially the ones involving passes. However, existing orientation estimation methods, which are based on computer-vision techniques, still have a lot of room for improvement. To the best of our knowledge, this article presents the first deep learning model for estimating orientation directly from video footage. By approaching this challenge as a classification problem where classes correspond to orientation bins, and by introducing a cyclic loss function, a well-known convolutional network is refined to provide player orientation data. The model is trained by using ground-truth orientation data obtained from wearable EPTS devices, which are individually compensated with respect to the perceived orientation in the current frame. The obtained results outperform previous methods; in particular, the absolute median error is less than 12 degrees per player. An ablation study is included in order to show the potential generalization to any kind of football video footage.
Using Player's Body-Orientation to Model Pass Feasibility in Soccer
Apr 15, 2020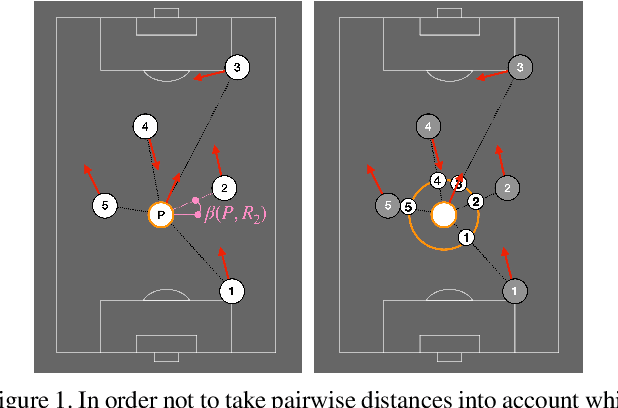
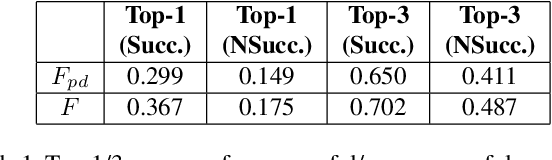
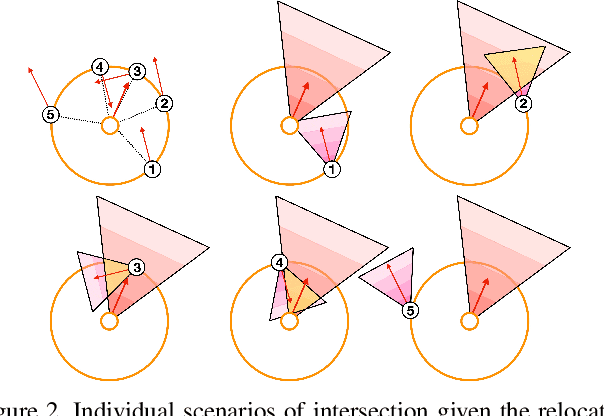
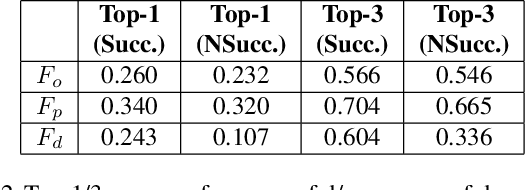
Given a monocular video of a soccer match, this paper presents a computational model to estimate the most feasible pass at any given time. The method leverages offensive player's orientation (plus their location) and opponents' spatial configuration to compute the feasibility of pass events within players of the same team. Orientation data is gathered from body pose estimations that are properly projected onto the 2D game field; moreover, a geometrical solution is provided, through the definition of a feasibility measure, to determine which players are better oriented towards each other. Once analyzed more than 6000 pass events, results show that, by including orientation as a feasibility measure, a robust computational model can be built, reaching more than 0.7 Top-3 accuracy. Finally, the combination of the orientation feasibility measure with the recently introduced Expected Possession Value metric is studied; promising results are obtained, thus showing that existing models can be refined by using orientation as a key feature. These models could help both coaches and analysts to have a better understanding of the game and to improve the players' decision-making process.
Always Look on the Bright Side of the Field: Merging Pose and Contextual Data to Estimate Orientation of Soccer Players
Mar 02, 2020
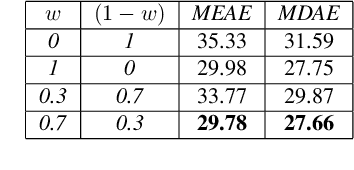
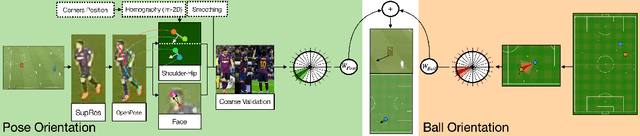
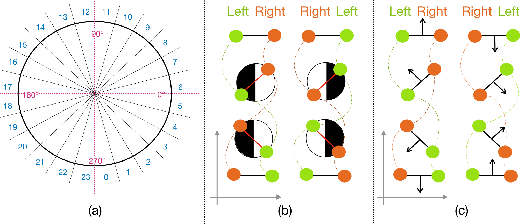
Although orientation has proven to be a key skill of soccer players in order to succeed in a broad spectrum of plays, body orientation is a yet-little-explored area in sports analytics' research. Despite being an inherently ambiguous concept, player orientation can be defined as the projection (2D) of the normal vector placed in the center of the upper-torso of players (3D). This research presents a novel technique to obtain player orientation from monocular video recordings by mapping pose parts (shoulders and hips) in a 2D field by combining OpenPose with a super-resolution network, and merging the obtained estimation with contextual information (ball position). Results have been validated with players-held EPTS devices, obtaining a median error of 27 degrees/player. Moreover, three novel types of orientation maps are proposed in order to make raw orientation data easy to visualize and understand, thus allowing further analysis at team- or player-level.
Convolutional Neural Networks Deceived by Visual Illusions
Nov 26, 2018
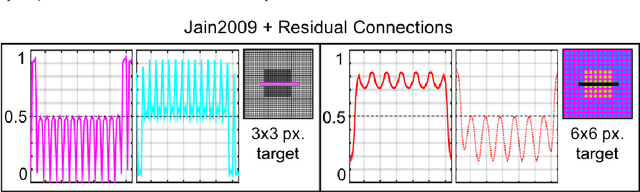
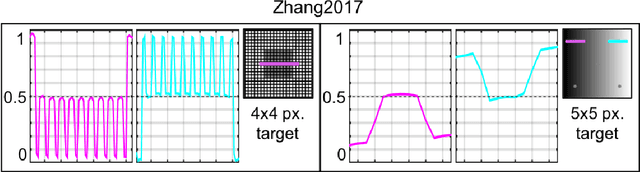
Visual illusions teach us that what we see is not always what it is represented in the physical world. Its special nature make them a fascinating tool to test and validate any new vision model proposed. In general, current vision models are based on the concatenation of linear convolutions and non-linear operations. In this paper we get inspiration from the similarity of this structure with the operations present in Convolutional Neural Networks (CNNs). This motivated us to study if CNNs trained for low-level visual tasks are deceived by visual illusions. In particular, we show that CNNs trained for image denoising, image deblurring, and computational color constancy are able to replicate the human response to visual illusions, and that the extent of this replication varies with respect to variation in architecture and spatial pattern size. We believe that this CNNs behaviour appears as a by-product of the training for the low level vision tasks of denoising, color constancy or deblurring. Our work opens a new bridge between human perception and CNNs: in order to obtain CNNs that better replicate human behaviour, we may need to start aiming for them to better replicate visual illusions.