 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow the Signal, Hide the Noise: Spectral Forcing for Pixel-Space Diffusion
Jun 16, 2026Pixel-space diffusion models are trained on full-bandwidth noisy images, yet the useful signal available to the denoiser is strongly frequency dependent. Under rectified-flow diffusion and natural-image power-law spectra, the per-band data-to-noise contour $k^{*}(t) = (1-t)^{-2/α}$ separates a signal-bearing low-frequency region from a noise-dominated high-frequency region at each time $t$. We show that this implicit coarse-to-fine structure is not merely descriptive: it induces a capacity-allocation problem. A standard pixel-space denoiser must discover the moving bandwidth boundary internally and can spend computation on frequency-time regions where the optimal prediction collapses to deterministic baselines rather than data-distribution modeling. To make this boundary explicit, we introduce Spectral Forcing, a parameter-free, time-conditional 2D-DCT low-pass operator applied to the noisy input before the patch embedder. Its cutoff expands monotonically with the diffusion time and becomes the identity at the data endpoint. Through controlled synthetic experiments, we identify the regime in which the operator is beneficial: coarse patch tokenization and data whose high-frequency content is predominantly noise rather than essential signal. On ImageNet-256 with JiT-700M/32, Spectral Forcing consistently improves both FID and Inception Score across different training epochs, demonstrating robust gains throughout training; at finer tokenization, the spectral forcing is still competitive. We further insert the unchanged operator into SenseNova-U1, a unified text-to-image model, where it improves DPG-Bench and GenEval, showing that the input-side spectral prior transfers beyond class-conditional generation. These results suggest a route to capacity-efficient pixel-space diffusion by showing the signal and hiding the noise.
From Pixels to Words -- Towards Native One-Vision Models at Scale
May 27, 2026Current vision-language models (VLMs) typically stitch together separate image encoders and language decoders via multi-stage alignment, a modular framework that inevitably fragments pixel-level signals across frames and scatters early pixel-word interactions. In parallel, native VLMs, despite impressive performance on single images, remain largely unexplored in multi-image, video understanding, and spatial intelligence. Hence, we introduce NEO-ov, a native foundation model that learns cross-frame and pixel-word correspondence end-to-end, without any external encoders, auxiliary adapters, or post-hoc fusion. By eliminating module boundaries entirely, NEO-ov enables fine-grained and unified spatiotemporal modeling to emerge natively inside the model. Notably, NEO-ov largely narrows the gap to modular counterparts while excelling at fine-grained visual perception, validating that native "one-vision" architectures are not only feasible but competitive at scale. Beyond empirical performance, we unveil systematic architectural analyses and detailed training recipes to facilitate subsequent native multimodal modeling. Our code and models are publicly available at: https://github.com/EvolvingLMMs-Lab/NEO.
SenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
May 12, 2026Recent large vision-language models (VLMs) remain fundamentally constrained by a persistent dichotomy: understanding and generation are treated as distinct problems, leading to fragmented architectures, cascaded pipelines, and misaligned representation spaces. We argue that this divide is not merely an engineering artifact, but a structural limitation that hinders the emergence of native multimodal intelligence. Hence, we introduce SenseNova-U1, a native unified multimodal paradigm built upon NEO-unify, in which understanding and generation evolve as synergistic views of a single underlying process. We launch two native unified variants, SenseNova-U1-8B-MoT and SenseNova-U1-A3B-MoT, built on dense (8B) and mixture-of-experts (30B-A3B) understanding baselines, respectively. Designed from first principles, they rival top-tier understanding-only VLMs across text understanding, vision-language perception, knowledge reasoning, agentic decision-making, and spatial intelligence. Meanwhile, they deliver strong semantic consistency and visual fidelity, excelling in conventional or knowledge-intensive any-to-image (X2I) synthesis, complex text-rich infographic generation, and interleaved vision-language generation, with or without think patterns. Beyond performance, we show detailed model design, data preprocessing, pre-/post-training, and inference strategies to support community research. Last but not least, preliminary evidence demonstrates that our models extend beyond perception and generation, performing strongly in vision-language-action (VLA) and world model (WM) scenarios. This points toward a broader roadmap where models do not translate between modalities, but think and act across them in a native manner. Multimodal AI is no longer about connecting separate systems, but about building a unified one and trusting the necessary capabilities to emerge from within.
The Prism Hypothesis: Harmonizing Semantic and Pixel Representations via Unified Autoencoding
Dec 22, 2025Deep representations across modalities are inherently intertwined. In this paper, we systematically analyze the spectral characteristics of various semantic and pixel encoders. Interestingly, our study uncovers a highly inspiring and rarely explored correspondence between an encoder's feature spectrum and its functional role: semantic encoders primarily capture low-frequency components that encode abstract meaning, whereas pixel encoders additionally retain high-frequency information that conveys fine-grained detail. This heuristic finding offers a unifying perspective that ties encoder behavior to its underlying spectral structure. We define it as the Prism Hypothesis, where each data modality can be viewed as a projection of the natural world onto a shared feature spectrum, just like the prism. Building on this insight, we propose Unified Autoencoding (UAE), a model that harmonizes semantic structure and pixel details via an innovative frequency-band modulator, enabling their seamless coexistence. Extensive experiments on ImageNet and MS-COCO benchmarks validate that our UAE effectively unifies semantic abstraction and pixel-level fidelity into a single latent space with state-of-the-art performance.
CFG-Zero*: Improved Classifier-Free Guidance for Flow Matching Models
Mar 24, 2025



Classifier-Free Guidance (CFG) is a widely adopted technique in diffusion/flow models to improve image fidelity and controllability. In this work, we first analytically study the effect of CFG on flow matching models trained on Gaussian mixtures where the ground-truth flow can be derived. We observe that in the early stages of training, when the flow estimation is inaccurate, CFG directs samples toward incorrect trajectories. Building on this observation, we propose CFG-Zero*, an improved CFG with two contributions: (a) optimized scale, where a scalar is optimized to correct for the inaccuracies in the estimated velocity, hence the * in the name; and (b) zero-init, which involves zeroing out the first few steps of the ODE solver. Experiments on both text-to-image (Lumina-Next, Stable Diffusion 3, and Flux) and text-to-video (Wan-2.1) generation demonstrate that CFG-Zero* consistently outperforms CFG, highlighting its effectiveness in guiding Flow Matching models. (Code is available at github.com/WeichenFan/CFG-Zero-star)
RepVideo: Rethinking Cross-Layer Representation for Video Generation
Jan 15, 2025



Video generation has achieved remarkable progress with the introduction of diffusion models, which have significantly improved the quality of generated videos. However, recent research has primarily focused on scaling up model training, while offering limited insights into the direct impact of representations on the video generation process. In this paper, we initially investigate the characteristics of features in intermediate layers, finding substantial variations in attention maps across different layers. These variations lead to unstable semantic representations and contribute to cumulative differences between features, which ultimately reduce the similarity between adjacent frames and negatively affect temporal coherence. To address this, we propose RepVideo, an enhanced representation framework for text-to-video diffusion models. By accumulating features from neighboring layers to form enriched representations, this approach captures more stable semantic information. These enhanced representations are then used as inputs to the attention mechanism, thereby improving semantic expressiveness while ensuring feature consistency across adjacent frames. Extensive experiments demonstrate that our RepVideo not only significantly enhances the ability to generate accurate spatial appearances, such as capturing complex spatial relationships between multiple objects, but also improves temporal consistency in video generation.
Vchitect-2.0: Parallel Transformer for Scaling Up Video Diffusion Models
Jan 14, 2025



We present Vchitect-2.0, a parallel transformer architecture designed to scale up video diffusion models for large-scale text-to-video generation. The overall Vchitect-2.0 system has several key designs. (1) By introducing a novel Multimodal Diffusion Block, our approach achieves consistent alignment between text descriptions and generated video frames, while maintaining temporal coherence across sequences. (2) To overcome memory and computational bottlenecks, we propose a Memory-efficient Training framework that incorporates hybrid parallelism and other memory reduction techniques, enabling efficient training of long video sequences on distributed systems. (3) Additionally, our enhanced data processing pipeline ensures the creation of Vchitect T2V DataVerse, a high-quality million-scale training dataset through rigorous annotation and aesthetic evaluation. Extensive benchmarking demonstrates that Vchitect-2.0 outperforms existing methods in video quality, training efficiency, and scalability, serving as a suitable base for high-fidelity video generation.
Link-Context Learning for Multimodal LLMs
Aug 15, 2023



The ability to learn from context with novel concepts, and deliver appropriate responses are essential in human conversations. Despite current Multimodal Large Language Models (MLLMs) and Large Language Models (LLMs) being trained on mega-scale datasets, recognizing unseen images or understanding novel concepts in a training-free manner remains a challenge. In-Context Learning (ICL) explores training-free few-shot learning, where models are encouraged to ``learn to learn" from limited tasks and generalize to unseen tasks. In this work, we propose link-context learning (LCL), which emphasizes "reasoning from cause and effect" to augment the learning capabilities of MLLMs. LCL goes beyond traditional ICL by explicitly strengthening the causal relationship between the support set and the query set. By providing demonstrations with causal links, LCL guides the model to discern not only the analogy but also the underlying causal associations between data points, which empowers MLLMs to recognize unseen images and understand novel concepts more effectively. To facilitate the evaluation of this novel approach, we introduce the ISEKAI dataset, comprising exclusively of unseen generated image-label pairs designed for link-context learning. Extensive experiments show that our LCL-MLLM exhibits strong link-context learning capabilities to novel concepts over vanilla MLLMs. Code and data will be released at https://github.com/isekai-portal/Link-Context-Learning.
Hierarchy Flow For High-Fidelity Image-to-Image Translation
Aug 14, 2023



Image-to-image (I2I) translation comprises a wide spectrum of tasks. Here we divide this problem into three levels: strong-fidelity translation, normal-fidelity translation, and weak-fidelity translation, indicating the extent to which the content of the original image is preserved. Although existing methods achieve good performance in weak-fidelity translation, they fail to fully preserve the content in both strong- and normal-fidelity tasks, e.g. sim2real, style transfer and low-level vision. In this work, we propose Hierarchy Flow, a novel flow-based model to achieve better content preservation during translation. Specifically, 1) we first unveil the drawbacks of standard flow-based models when applied to I2I translation. 2) Next, we propose a new design, namely hierarchical coupling for reversible feature transformation and multi-scale modeling, to constitute Hierarchy Flow. 3) Finally, we present a dedicated aligned-style loss for a better trade-off between content preservation and stylization during translation. Extensive experiments on a wide range of I2I translation benchmarks demonstrate that our approach achieves state-of-the-art performance, with convincing advantages in both strong- and normal-fidelity tasks. Code and models will be at https://github.com/WeichenFan/HierarchyFlow.
StyleFlow For Content-Fixed Image to Image Translation
Jul 05, 2022

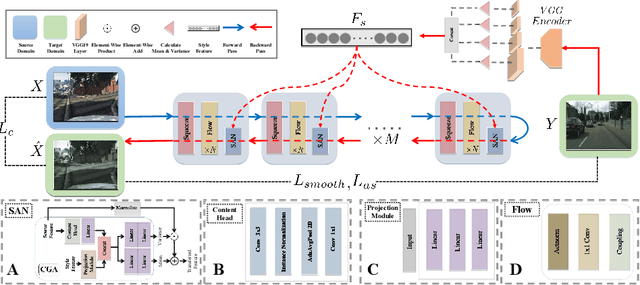

Image-to-image (I2I) translation is a challenging topic in computer vision. We divide this problem into three tasks: strongly constrained translation, normally constrained translation, and weakly constrained translation. The constraint here indicates the extent to which the content or semantic information in the original image is preserved. Although previous approaches have achieved good performance in weakly constrained tasks, they failed to fully preserve the content in both strongly and normally constrained tasks, including photo-realism synthesis, style transfer, and colorization, etc. To achieve content-preserving transfer in strongly constrained and normally constrained tasks, we propose StyleFlow, a new I2I translation model that consists of normalizing flows and a novel Style-Aware Normalization (SAN) module. With the invertible network structure, StyleFlow first projects input images into deep feature space in the forward pass, while the backward pass utilizes the SAN module to perform content-fixed feature transformation and then projects back to image space. Our model supports both image-guided translation and multi-modal synthesis. We evaluate our model in several I2I translation benchmarks, and the results show that the proposed model has advantages over previous methods in both strongly constrained and normally constrained tasks.