 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredict-then-Diffuse: Adaptive Response Length for Compute-Budgeted Inference in Diffusion LLMs
May 05, 2026Diffusion-based Large Language Models (D-LLMs) represent a promising frontier in generative AI, offering fully parallel token generation that can lead to significant throughput advantages and superior GPU utilization over traditional autoregressive paradigm. However, this parallelism is constrained by the requirement of a fixed-size response length prior to generation. This architectural limitation imposes a severe trade-off: oversized response length results in computational waste on semantically meaningless padding tokens, while undersized response length cause output truncation requiring costly re-computations that introduce unpredictable latency spikes. To tackle this issue, we propose Predict-then-Diffuse, a simple and model-agnostic framework, that enables compute-budgeted inference per input query by first estimating the response length and then using it to run inference with D-LLM. At its core lies a Adaptive Response Length Predictor (AdaRLP) auxiliary predictor that predicts the optimal response length given an input query. As a measure against under-predicting the response length and re-running inference with a higher response length, we introduce a data-driven safety mechanism, which trades a negligible padding overhead. As a whole, our framework limits the significant waste of computation on padding tokens and preserves output quality. Experimental validation on multiple datasets demonstrate that Predict-then-Diffuse significantly reduces computational costs (FLOP) compared to the default D-LLM inference mechanism and baselines based on heuristics, while being robust to skewed data distributions.
ProactiveBench: Benchmarking Proactiveness in Multimodal Large Language Models
Mar 19, 2026Effective collaboration begins with knowing when to ask for help. For example, when trying to identify an occluded object, a human would ask someone to remove the obstruction. Can MLLMs exhibit a similar "proactive" behavior by requesting simple user interventions? To investigate this, we introduce ProactiveBench, a benchmark built from seven repurposed datasets that tests proactiveness across different tasks such as recognizing occluded objects, enhancing image quality, and interpreting coarse sketches. We evaluate 22 MLLMs on ProactiveBench, showing that (i) they generally lack proactiveness; (ii) proactiveness does not correlate with model capacity; (iii) "hinting" at proactiveness yields only marginal gains. Surprisingly, we found that conversation histories and in-context learning introduce negative biases, hindering performance. Finally, we explore a simple fine-tuning strategy based on reinforcement learning: its results suggest that proactiveness can be learned, even generalizing to unseen scenarios. We publicly release ProactiveBench as a first step toward building proactive multimodal models.
LT-Soups: Bridging Head and Tail Classes via Subsampled Model Soups
Nov 11, 2025Real-world datasets typically exhibit long-tailed (LT) distributions, where a few head classes dominate and many tail classes are severely underrepresented. While recent work shows that parameter-efficient fine-tuning (PEFT) methods like LoRA and AdaptFormer preserve tail-class performance on foundation models such as CLIP, we find that they do so at the cost of head-class accuracy. We identify the head-tail ratio, the proportion of head to tail classes, as a crucial but overlooked factor influencing this trade-off. Through controlled experiments on CIFAR100 with varying imbalance ratio ($ρ$) and head-tail ratio ($η$), we show that PEFT excels in tail-heavy scenarios but degrades in more balanced and head-heavy distributions. To overcome these limitations, we propose LT-Soups, a two-stage model soups framework designed to generalize across diverse LT regimes. In the first stage, LT-Soups averages models fine-tuned on balanced subsets to reduce head-class bias; in the second, it fine-tunes only the classifier on the full dataset to restore head-class accuracy. Experiments across six benchmark datasets show that LT-Soups achieves superior trade-offs compared to both PEFT and traditional model soups across a wide range of imbalance regimes.
FedMVP: Federated Multi-modal Visual Prompt Tuning for Vision-Language Models
Apr 29, 2025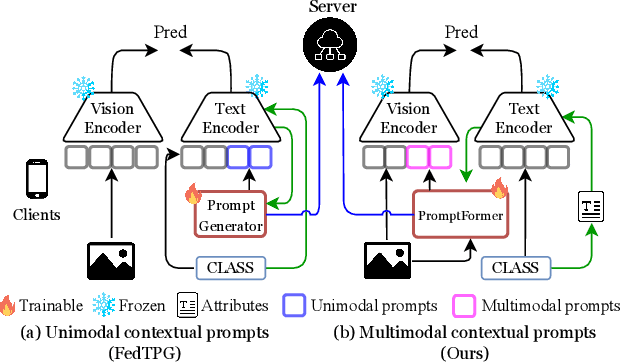
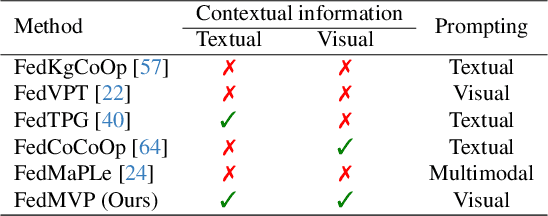
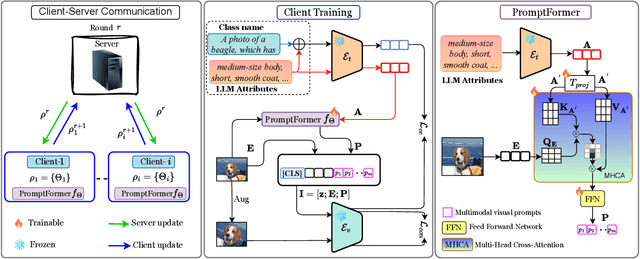
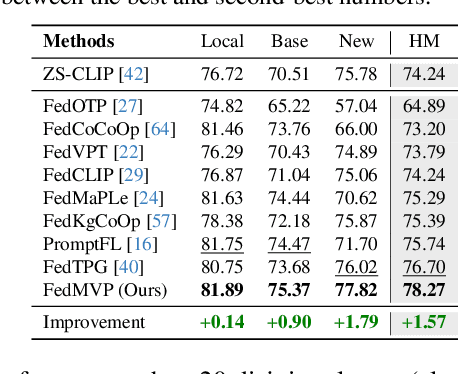
Textual prompt tuning adapts Vision-Language Models (e.g., CLIP) in federated learning by tuning lightweight input tokens (or prompts) on local client data, while keeping network weights frozen. Post training, only the prompts are shared by the clients with the central server for aggregation. However, textual prompt tuning often struggles with overfitting to known concepts and may be overly reliant on memorized text features, limiting its adaptability to unseen concepts. To address this limitation, we propose Federated Multimodal Visual Prompt Tuning (FedMVP) that conditions the prompts on comprehensive contextual information -- image-conditioned features and textual attribute features of a class -- that is multimodal in nature. At the core of FedMVP is a PromptFormer module that synergistically aligns textual and visual features through cross-attention, enabling richer contexual integration. The dynamically generated multimodal visual prompts are then input to the frozen vision encoder of CLIP, and trained with a combination of CLIP similarity loss and a consistency loss. Extensive evaluation on 20 datasets spanning three generalization settings demonstrates that FedMVP not only preserves performance on in-distribution classes and domains, but also displays higher generalizability to unseen classes and domains when compared to state-of-the-art methods. Codes will be released upon acceptance.
Group-robust Machine Unlearning
Mar 12, 2025



Machine unlearning is an emerging paradigm to remove the influence of specific training data (i.e., the forget set) from a model while preserving its knowledge of the rest of the data (i.e., the retain set). Previous approaches assume the forget data to be uniformly distributed from all training datapoints. However, if the data to unlearn is dominant in one group, we empirically show that performance for this group degrades, leading to fairness issues. This work tackles the overlooked problem of non-uniformly distributed forget sets, which we call group-robust machine unlearning, by presenting a simple, effective strategy that mitigates the performance loss in dominant groups via sample distribution reweighting. Moreover, we present MIU (Mutual Information-aware Machine Unlearning), the first approach for group robustness in approximate machine unlearning. MIU minimizes the mutual information between model features and group information, achieving unlearning while reducing performance degradation in the dominant group of the forget set. Additionally, MIU exploits sample distribution reweighting and mutual information calibration with the original model to preserve group robustness. We conduct experiments on three datasets and show that MIU outperforms standard methods, achieving unlearning without compromising model robustness. Source code available at https://github.com/tdemin16/group-robust_machine_unlearning.
Organizing Unstructured Image Collections using Natural Language
Oct 07, 2024



Organizing unstructured visual data into semantic clusters is a key challenge in computer vision. Traditional deep clustering (DC) approaches focus on a single partition of data, while multiple clustering (MC) methods address this limitation by uncovering distinct clustering solutions. The rise of large language models (LLMs) and multimodal LLMs (MLLMs) has enhanced MC by allowing users to define clustering criteria in natural language. However, manually specifying criteria for large datasets is impractical. In this work, we introduce the task Semantic Multiple Clustering (SMC) that aims to automatically discover clustering criteria from large image collections, uncovering interpretable substructures without requiring human input. Our framework, Text Driven Semantic Multiple Clustering (TeDeSC), uses text as a proxy to concurrently reason over large image collections, discover partitioning criteria, expressed in natural language, and reveal semantic substructures. To evaluate TeDeSC, we introduce the COCO-4c and Food-4c benchmarks, each containing four grouping criteria and ground-truth annotations. We apply TeDeSC to various applications, such as discovering biases and analyzing social media image popularity, demonstrating its utility as a tool for automatically organizing image collections and revealing novel insights.
One-Shot Unlearning of Personal Identities
Jul 16, 2024



Machine unlearning (MU) aims to erase data from a model as if it never saw them during training. To this extent, existing MU approaches assume complete or partial access to the training data, which can be limited over time due to privacy regulations. However, no setting or benchmark exists to probe the effectiveness of MU methods in such scenarios, i.e. when training data is missing. To fill this gap, we propose a novel task we call One-Shot Unlearning of Personal Identities (O-UPI) that evaluates unlearning models when the training data is not accessible. Specifically, we focus on the identity unlearning case, which is relevant due to current regulations requiring data deletion after training. To cope with data absence, we expect users to provide a portraiting picture to perform unlearning. To evaluate methods in O-UPI, we benchmark the forgetting on CelebA and CelebA-HQ datasets with different unlearning set sizes. We test applicable methods on this challenging benchmark, proposing also an effective method that meta-learns to forget identities from a single image. Our findings indicate that existing approaches struggle when data availability is limited, with greater difficulty when there is dissimilarity between provided samples and data used at training time. We will release the code and benchmark upon acceptance.
Less is more: Summarizing Patch Tokens for efficient Multi-Label Class-Incremental Learning
May 24, 2024Prompt tuning has emerged as an effective rehearsal-free technique for class-incremental learning (CIL) that learns a tiny set of task-specific parameters (or prompts) to instruct a pre-trained transformer to learn on a sequence of tasks. Albeit effective, prompt tuning methods do not lend well in the multi-label class incremental learning (MLCIL) scenario (where an image contains multiple foreground classes) due to the ambiguity in selecting the correct prompt(s) corresponding to different foreground objects belonging to multiple tasks. To circumvent this issue we propose to eliminate the prompt selection mechanism by maintaining task-specific pathways, which allow us to learn representations that do not interact with the ones from the other tasks. Since independent pathways in truly incremental scenarios will result in an explosion of computation due to the quadratically complex multi-head self-attention (MSA) operation in prompt tuning, we propose to reduce the original patch token embeddings into summarized tokens. Prompt tuning is then applied to these fewer summarized tokens to compute the final representation. Our proposed method Multi-Label class incremental learning via summarising pAtch tokeN Embeddings (MULTI-LANE) enables learning disentangled task-specific representations in MLCIL while ensuring fast inference. We conduct experiments in common benchmarks and demonstrate that our MULTI-LANE achieves a new state-of-the-art in MLCIL. Additionally, we show that MULTI-LANE is also competitive in the CIL setting. Source code available at https://github.com/tdemin16/multi-lane
Democratizing Fine-grained Visual Recognition with Large Language Models
Jan 24, 2024



Identifying subordinate-level categories from images is a longstanding task in computer vision and is referred to as fine-grained visual recognition (FGVR). It has tremendous significance in real-world applications since an average layperson does not excel at differentiating species of birds or mushrooms due to subtle differences among the species. A major bottleneck in developing FGVR systems is caused by the need of high-quality paired expert annotations. To circumvent the need of expert knowledge we propose Fine-grained Semantic Category Reasoning (FineR) that internally leverages the world knowledge of large language models (LLMs) as a proxy in order to reason about fine-grained category names. In detail, to bridge the modality gap between images and LLM, we extract part-level visual attributes from images as text and feed that information to a LLM. Based on the visual attributes and its internal world knowledge the LLM reasons about the subordinate-level category names. Our training-free FineR outperforms several state-of-the-art FGVR and language and vision assistant models and shows promise in working in the wild and in new domains where gathering expert annotation is arduous.
Collaborating Foundation models for Domain Generalized Semantic Segmentation
Dec 15, 2023



Domain Generalized Semantic Segmentation (DGSS) deals with training a model on a labeled source domain with the aim of generalizing to unseen domains during inference. Existing DGSS methods typically effectuate robust features by means of Domain Randomization (DR). Such an approach is often limited as it can only account for style diversification and not content. In this work, we take an orthogonal approach to DGSS and propose to use an assembly of CoLlaborative FOUndation models for Domain Generalized Semantic Segmentation (CLOUDS). In detail, CLOUDS is a framework that integrates FMs of various kinds: (i) CLIP backbone for its robust feature representation, (ii) generative models to diversify the content, thereby covering various modes of the possible target distribution, and (iii) Segment Anything Model (SAM) for iteratively refining the predictions of the segmentation model. Extensive experiments show that our CLOUDS excels in adapting from synthetic to real DGSS benchmarks and under varying weather conditions, notably outperforming prior methods by 5.6% and 6.7% on averaged miou, respectively. The code is available at : https://github.com/yasserben/CLOUDS