 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Rodin: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion
Dec 12, 2022
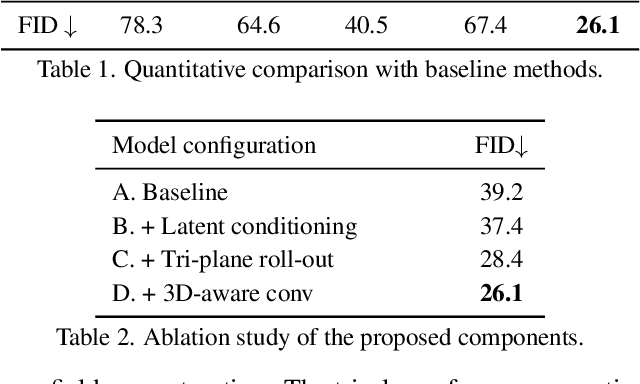
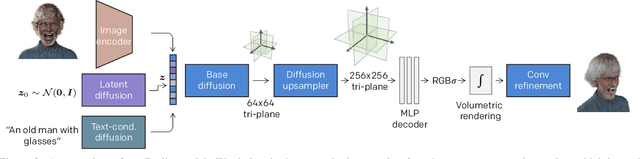
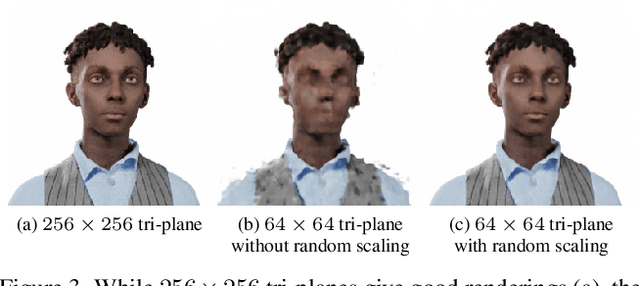
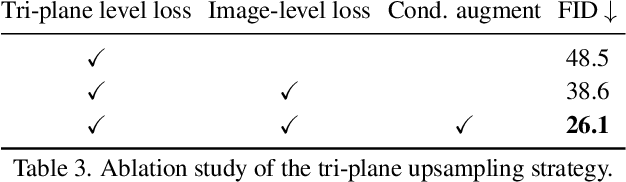
This paper presents a 3D generative model that uses diffusion models to automatically generate 3D digital avatars represented as neural radiance fields. A significant challenge in generating such avatars is that the memory and processing costs in 3D are prohibitive for producing the rich details required for high-quality avatars. To tackle this problem we propose the roll-out diffusion network (Rodin), which represents a neural radiance field as multiple 2D feature maps and rolls out these maps into a single 2D feature plane within which we perform 3D-aware diffusion. The Rodin model brings the much-needed computational efficiency while preserving the integrity of diffusion in 3D by using 3D-aware convolution that attends to projected features in the 2D feature plane according to their original relationship in 3D. We also use latent conditioning to orchestrate the feature generation for global coherence, leading to high-fidelity avatars and enabling their semantic editing based on text prompts. Finally, we use hierarchical synthesis to further enhance details. The 3D avatars generated by our model compare favorably with those produced by existing generative techniques. We can generate highly detailed avatars with realistic hairstyles and facial hair like beards. We also demonstrate 3D avatar generation from image or text as well as text-guided editability.
AU-Guided Unsupervised Domain Adaptive Facial Expression Recognition
Dec 18, 2020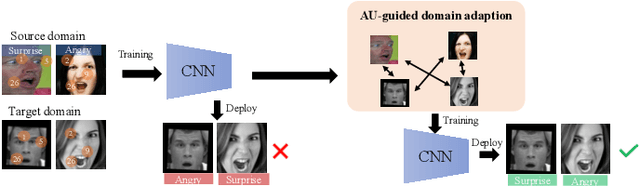
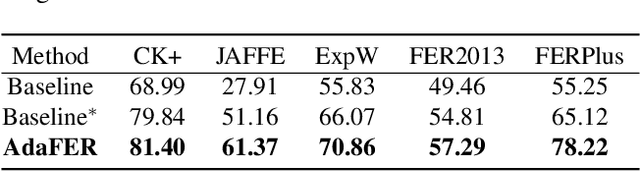
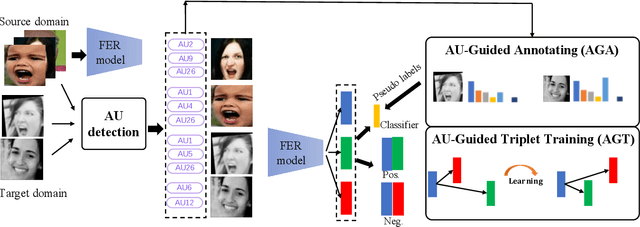
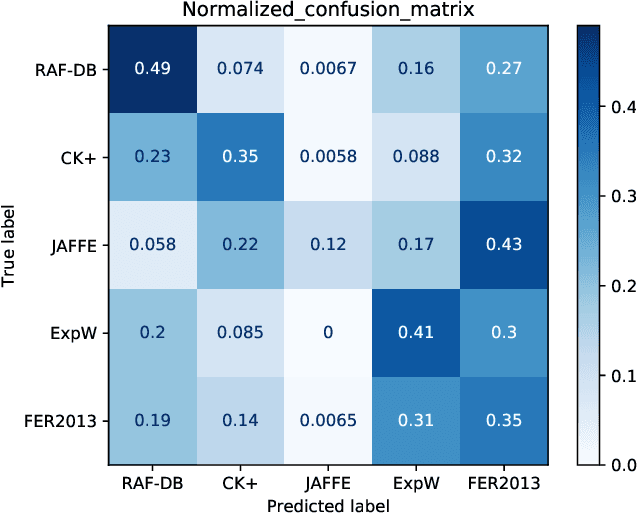
The domain diversities including inconsistent annotation and varied image collection conditions inevitably exist among different facial expression recognition (FER) datasets, which pose an evident challenge for adapting the FER model trained on one dataset to another one. Recent works mainly focus on domain-invariant deep feature learning with adversarial learning mechanism, ignoring the sibling facial action unit (AU) detection task which has obtained great progress. Considering AUs objectively determine facial expressions, this paper proposes an AU-guided unsupervised Domain Adaptive FER (AdaFER) framework. In AdaFER, we first leverage an advanced model for AU detection on both source and target domain. Then, we compare the AU results to perform AU-guided annotating, i.e., target faces that own the same AUs with source faces would inherit the labels from source domain. Meanwhile, to achieve domain-invariant compact features, we utilize an AU-guided triplet training which randomly collects anchor-positive-negative triplets on both domains with AUs. We conduct extensive experiments on several popular benchmarks and show that AdaFER achieves state-of-the-art results on all the benchmarks.
StyleGAN as a Utility-Preserving Face De-identification Method
Dec 05, 2022
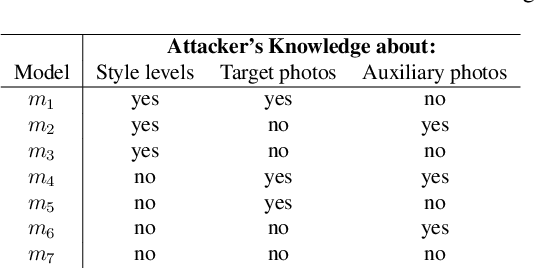
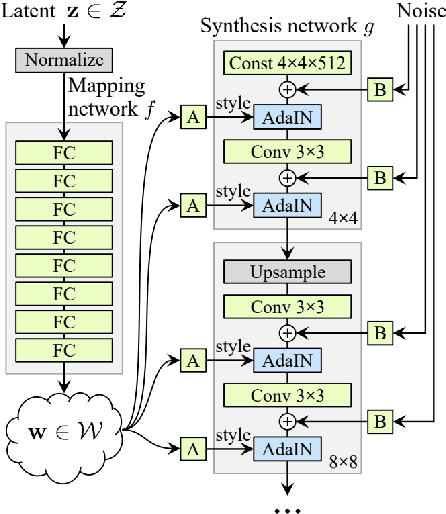
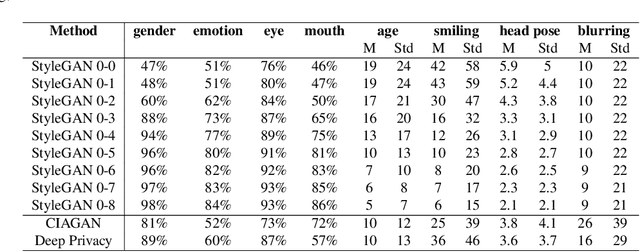
Several face de-identification methods have been proposed to preserve users' privacy by obscuring their faces. These methods, however, can degrade the quality of photos, and they usually do not preserve the utility of faces, e.g., their age, gender, pose, and facial expression. Recently, advanced generative adversarial network models, such as StyleGAN, have been proposed, which generate realistic, high-quality imaginary faces. In this paper, we investigate the use of StyleGAN in generating de-identified faces through style mixing, where the styles or features of the target face and an auxiliary face get mixed to generate a de-identified face that carries the utilities of the target face. We examined this de-identification method with respect to preserving utility and privacy, by implementing several face detection, verification, and identification attacks. Through extensive experiments and also comparing with two state-of-the-art face de-identification methods, we show that StyleGAN preserves the quality and utility of the faces much better than the other approaches and also by choosing the style mixing levels correctly, it can preserve the privacy of the faces much better than other methods.
Enhancing Quality of Pose-varied Face Restoration with Local Weak Feature Sensing and GAN Prior
May 28, 2022
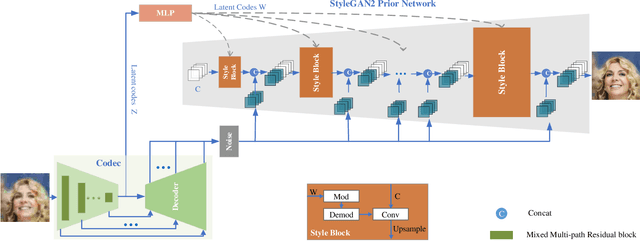
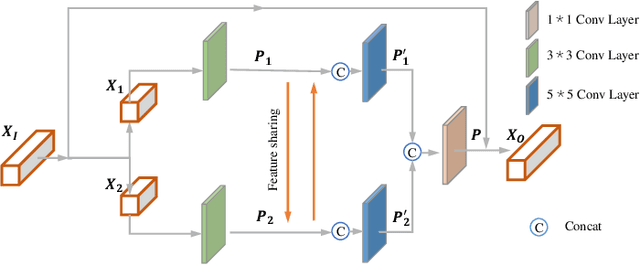

Facial semantic guidance (facial landmarks, facial parsing maps, facial heatmaps, etc.) and facial generative adversarial networks (GAN) prior have been widely used in blind face restoration (BFR) in recent years. Although existing BFR methods have achieved good performance in ordinary cases, these solutions have limited resilience when applied to face images with serious degradation and pose-varied (look up, look down, laugh, etc.) in real-world scenarios. In this work, we propose a well-designed blind face restoration network with generative facial prior. The proposed network is mainly comprised of an asymmetric codec and StyleGAN2 prior network. In the asymmetric codec, we adopt a mixed multi-path residual block (MMRB) to gradually extract weak texture features of input images, which can improve the texture integrity and authenticity of our networks. Furthermore, the MMRB block can also be plug-and-play in any other network. Besides, a novel self-supervised training strategy is specially designed for face restoration tasks to fit the distribution closer to the target and maintain training stability. Extensive experiments over synthetic and real-world datasets demonstrate that our model achieves superior performance to the prior art for face restoration and face super-resolution tasks and can tackle seriously degraded face images in diverse poses and expressions.
Relightable Neural Human Assets from Multi-view Gradient Illuminations
Dec 16, 2022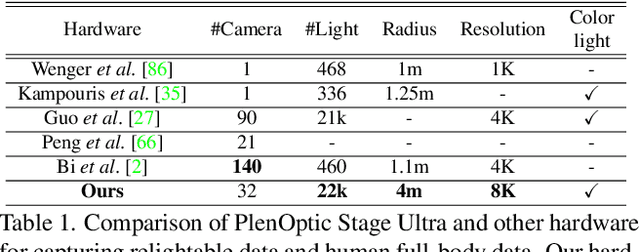

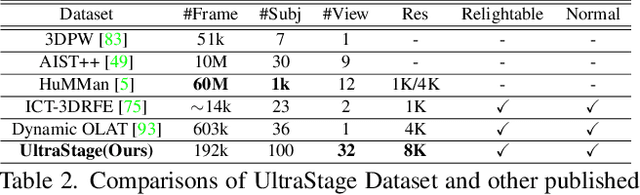
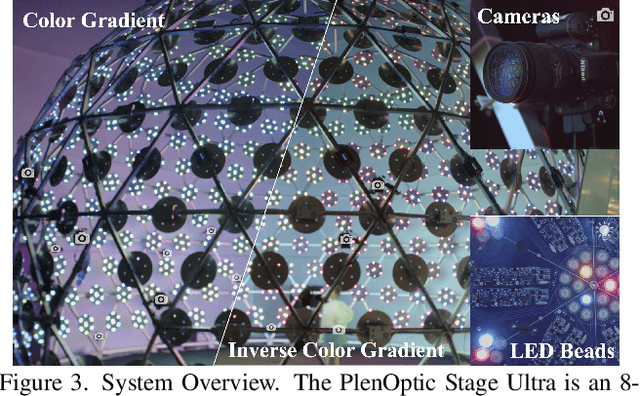
Human modeling and relighting are two fundamental problems in computer vision and graphics, where high-quality datasets can largely facilitate related research. However, most existing human datasets only provide multi-view human images captured under the same illumination. Although valuable for modeling tasks, they are not readily used in relighting problems. To promote research in both fields, in this paper, we present UltraStage, a new 3D human dataset that contains more than 2K high-quality human assets captured under both multi-view and multi-illumination settings. Specifically, for each example, we provide 32 surrounding views illuminated with one white light and two gradient illuminations. In addition to regular multi-view images, gradient illuminations help recover detailed surface normal and spatially-varying material maps, enabling various relighting applications. Inspired by recent advances in neural representation, we further interpret each example into a neural human asset which allows novel view synthesis under arbitrary lighting conditions. We show our neural human assets can achieve extremely high capture performance and are capable of representing fine details such as facial wrinkles and cloth folds. We also validate UltraStage in single image relighting tasks, training neural networks with virtual relighted data from neural assets and demonstrating realistic rendering improvements over prior arts. UltraStage will be publicly available to the community to stimulate significant future developments in various human modeling and rendering tasks.
CooGAN: A Memory-Efficient Framework for High-Resolution Facial Attribute Editing
Nov 03, 2020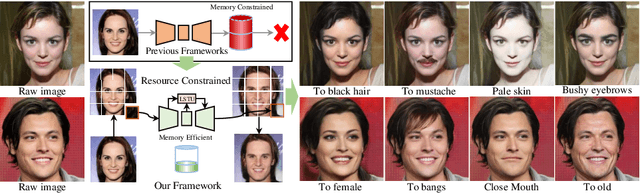

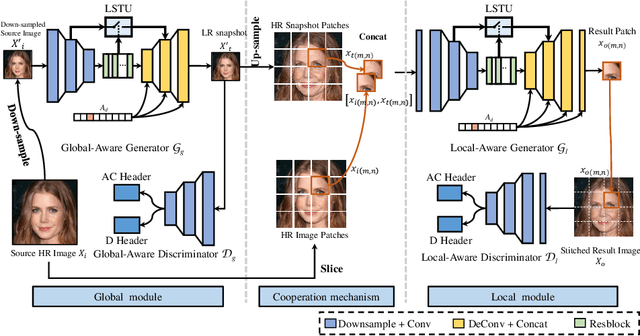

In contrast to great success of memory-consuming face editing methods at a low resolution, to manipulate high-resolution (HR) facial images, i.e., typically larger than 7682 pixels, with very limited memory is still challenging. This is due to the reasons of 1) intractable huge demand of memory; 2) inefficient multi-scale features fusion. To address these issues, we propose a NOVEL pixel translation framework called Cooperative GAN(CooGAN) for HR facial image editing. This framework features a local path for fine-grained local facial patch generation (i.e., patch-level HR, LOW memory) and a global path for global lowresolution (LR) facial structure monitoring (i.e., image-level LR, LOW memory), which largely reduce memory requirements. Both paths work in a cooperative manner under a local-to-global consistency objective (i.e., for smooth stitching). In addition, we propose a lighter selective transfer unit for more efficient multi-scale features fusion, yielding higher fidelity facial attributes manipulation. Extensive experiments on CelebAHQ well demonstrate the memory efficiency as well as the high image generation quality of the proposed framework.
Automatic Estimation of Self-Reported Pain by Trajectory Analysis in the Manifold of Fixed Rank Positive Semi-Definite Matrices
Sep 17, 2022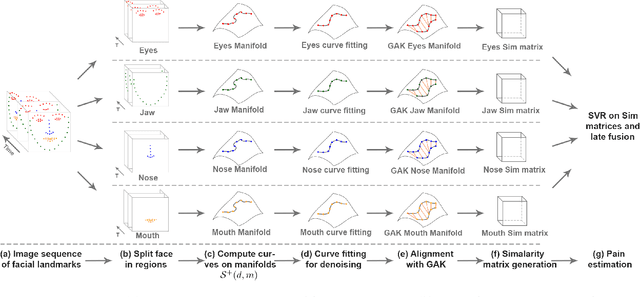
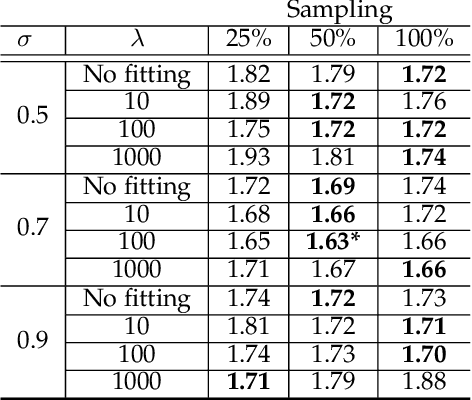
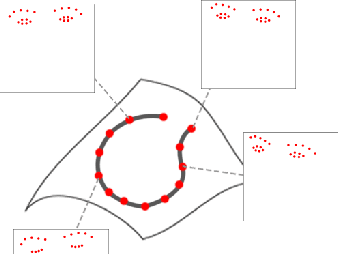
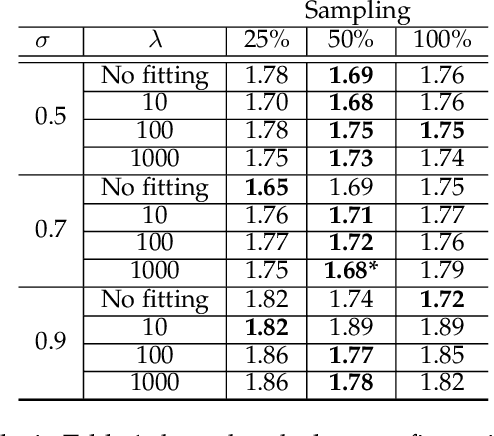
We propose an automatic method to estimate self-reported pain based on facial landmarks extracted from videos. For each video sequence, we decompose the face into four different regions and the pain intensity is measured by modeling the dynamics of facial movement using the landmarks of these regions. A formulation based on Gram matrices is used for representing the trajectory of landmarks on the Riemannian manifold of symmetric positive semi-definite matrices of fixed rank. A curve fitting algorithm is used to smooth the trajectories and temporal alignment is performed to compute the similarity between the trajectories on the manifold. A Support Vector Regression classifier is then trained to encode extracted trajectories into pain intensity levels consistent with self-reported pain intensity measurement. Finally, a late fusion of the estimation for each region is performed to obtain the final predicted pain level. The proposed approach is evaluated on two publicly available datasets, the UNBCMcMaster Shoulder Pain Archive and the Biovid Heat Pain dataset. We compared our method to the state-of-the-art on both datasets using different testing protocols, showing the competitiveness of the proposed approach.
Multi-Task Learning for Emotion Descriptors Estimation at the fourth ABAW Challenge
Jul 20, 2022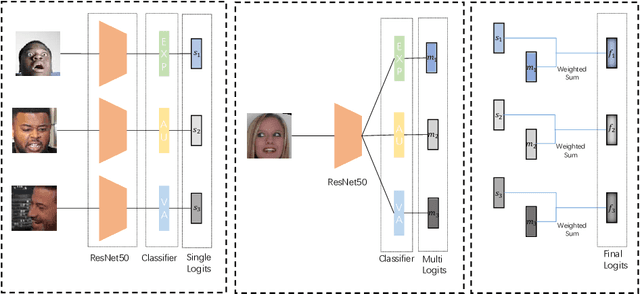

Facial valence/arousal, expression and action unit are related tasks in facial affective analysis. However, the tasks only have limited performance in the wild due to the various collected conditions. The 4th competition on affective behavior analysis in the wild (ABAW) provided images with valence/arousal, expression and action unit labels. In this paper, we introduce multi-task learning framework to enhance the performance of three related tasks in the wild. Feature sharing and label fusion are used to utilize their relations. We conduct experiments on the provided training and validating data.
Video-based Facial Expression Recognition using Graph Convolutional Networks
Oct 26, 2020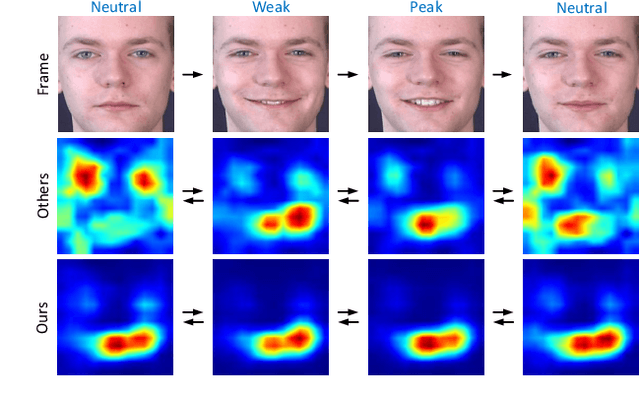
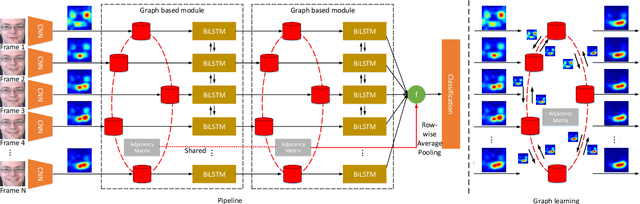

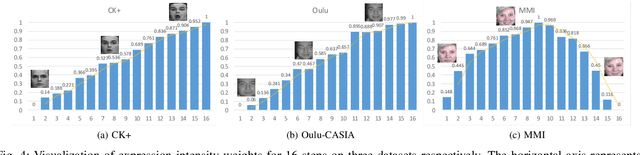
Facial expression recognition (FER), aiming to classify the expression present in the facial image or video, has attracted a lot of research interests in the field of artificial intelligence and multimedia. In terms of video based FER task, it is sensible to capture the dynamic expression variation among the frames to recognize facial expression. However, existing methods directly utilize CNN-RNN or 3D CNN to extract the spatial-temporal features from different facial units, instead of concentrating on a certain region during expression variation capturing, which leads to limited performance in FER. In our paper, we introduce a Graph Convolutional Network (GCN) layer into a common CNN-RNN based model for video-based FER. First, the GCN layer is utilized to learn more significant facial expression features which concentrate on certain regions after sharing information between extracted CNN features of nodes. Then, a LSTM layer is applied to learn long-term dependencies among the GCN learned features to model the variation. In addition, a weight assignment mechanism is also designed to weight the output of different nodes for final classification by characterizing the expression intensities in each frame. To the best of our knowledge, it is the first time to use GCN in FER task. We evaluate our method on three widely-used datasets, CK+, Oulu-CASIA and MMI, and also one challenging wild dataset AFEW8.0, and the experimental results demonstrate that our method has superior performance to existing methods.