 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoInertia-MI: A Multimodal Egocentric Vision and IMU Benchmark for Motor Impairment Assessment
Jul 04, 2026Motor impairments, including tremor, bradykinesia, gait abnormalities, and postural instability, are common across many neurological and movement-related conditions. Conventional clinical assessments are often intermittent and may fail to capture subtle temporal variations in motor behavior. While wearable IMUs and third-person video have shown promise for objective motor assessment, third-person recordings raise privacy concerns and require constrained acquisition setups. In contrast, egocentric vision provides a more naturalistic and privacyaware alternative. In this work, we introduce EgoInertia-MI, a multimodal benchmark dataset combining synchronized egocentric video and wearable IMU signals for motor impairment analysis. The dataset contains 19 upper- and lower-body activities performed by healthy volunteers simulating varying levels of motor impairment severity levels: no impairment, mild impairment, and severe impairment. We establish two benchmark tasks: action recognition and motor impairment severity estimation, and evaluate multiple unimodal and multimodal baselines. Experimental results show that egocentric video provides strong cues for motor impairment assessment, while multimodal fusion achieves the best overall performance, reaching 0.78 Macro-F1 for severity estimation and 0.93 Macro-F1 for action recognition. These findings highlight the potential of combining egocentric vision and wearable sensing for ecologically valid and privacy-aware motor assessment. Code and data are available at:https://fatemah-alh.github.io/EgoInertia-MI-Page/.
PEPR: Privileged Event-based Predictive Regularization for Domain Generalization
Feb 04, 2026Deep neural networks for visual perception are highly susceptible to domain shift, which poses a critical challenge for real-world deployment under conditions that differ from the training data. To address this domain generalization challenge, we propose a cross-modal framework under the learning using privileged information (LUPI) paradigm for training a robust, single-modality RGB model. We leverage event cameras as a source of privileged information, available only during training. The two modalities exhibit complementary characteristics: the RGB stream is semantically dense but domain-dependent, whereas the event stream is sparse yet more domain-invariant. Direct feature alignment between them is therefore suboptimal, as it forces the RGB encoder to mimic the sparse event representation, thereby losing semantic detail. To overcome this, we introduce Privileged Event-based Predictive Regularization (PEPR), which reframes LUPI as a predictive problem in a shared latent space. Instead of enforcing direct cross-modal alignment, we train the RGB encoder with PEPR to predict event-based latent features, distilling robustness without sacrificing semantic richness. The resulting standalone RGB model consistently improves robustness to day-to-night and other domain shifts, outperforming alignment-based baselines across object detection and semantic segmentation.
Drone Detection with Event Cameras
Aug 06, 2025The diffusion of drones presents significant security and safety challenges. Traditional surveillance systems, particularly conventional frame-based cameras, struggle to reliably detect these targets due to their small size, high agility, and the resulting motion blur and poor performance in challenging lighting conditions. This paper surveys the emerging field of event-based vision as a robust solution to these problems. Event cameras virtually eliminate motion blur and enable consistent detection in extreme lighting. Their sparse, asynchronous output suppresses static backgrounds, enabling low-latency focus on motion cues. We review the state-of-the-art in event-based drone detection, from data representation methods to advanced processing pipelines using spiking neural networks. The discussion extends beyond simple detection to cover more sophisticated tasks such as real-time tracking, trajectory forecasting, and unique identification through propeller signature analysis. By examining current methodologies, available datasets, and the distinct advantages of the technology, this work demonstrates that event-based vision provides a powerful foundation for the next generation of reliable, low-latency, and efficient counter-UAV systems.
FRED: The Florence RGB-Event Drone Dataset
Jun 05, 2025Small, fast, and lightweight drones present significant challenges for traditional RGB cameras due to their limitations in capturing fast-moving objects, especially under challenging lighting conditions. Event cameras offer an ideal solution, providing high temporal definition and dynamic range, yet existing benchmarks often lack fine temporal resolution or drone-specific motion patterns, hindering progress in these areas. This paper introduces the Florence RGB-Event Drone dataset (FRED), a novel multimodal dataset specifically designed for drone detection, tracking, and trajectory forecasting, combining RGB video and event streams. FRED features more than 7 hours of densely annotated drone trajectories, using 5 different drone models and including challenging scenarios such as rain and adverse lighting conditions. We provide detailed evaluation protocols and standard metrics for each task, facilitating reproducible benchmarking. The authors hope FRED will advance research in high-speed drone perception and multimodal spatiotemporal understanding.
Spike-TBR: a Noise Resilient Neuromorphic Event Representation
Jun 05, 2025Event cameras offer significant advantages over traditional frame-based sensors, including higher temporal resolution, lower latency and dynamic range. However, efficiently converting event streams into formats compatible with standard computer vision pipelines remains a challenging problem, particularly in the presence of noise. In this paper, we propose Spike-TBR, a novel event-based encoding strategy based on Temporal Binary Representation (TBR), addressing its vulnerability to noise by integrating spiking neurons. Spike-TBR combines the frame-based advantages of TBR with the noise-filtering capabilities of spiking neural networks, creating a more robust representation of event streams. We evaluate four variants of Spike-TBR, each using different spiking neurons, across multiple datasets, demonstrating superior performance in noise-affected scenarios while improving the results on clean data. Our method bridges the gap between spike-based and frame-based processing, offering a simple noise-resilient solution for event-driven vision applications.
EV-Flying: an Event-based Dataset for In-The-Wild Recognition of Flying Objects
Jun 04, 2025Monitoring aerial objects is crucial for security, wildlife conservation, and environmental studies. Traditional RGB-based approaches struggle with challenges such as scale variations, motion blur, and high-speed object movements, especially for small flying entities like insects and drones. In this work, we explore the potential of event-based vision for detecting and recognizing flying objects, in particular animals that may not follow short and long-term predictable patters. Event cameras offer high temporal resolution, low latency, and robustness to motion blur, making them well-suited for this task. We introduce EV-Flying, an event-based dataset of flying objects, comprising manually annotated birds, insects and drones with spatio-temporal bounding boxes and track identities. To effectively process the asynchronous event streams, we employ a point-based approach leveraging lightweight architectures inspired by PointNet. Our study investigates the classification of flying objects using point cloud-based event representations. The proposed dataset and methodology pave the way for more efficient and reliable aerial object recognition in real-world scenarios.
Neuromorphic Drone Detection: an Event-RGB Multimodal Approach
Sep 24, 2024In recent years, drone detection has quickly become a subject of extreme interest: the potential for fast-moving objects of contained dimensions to be used for malicious intents or even terrorist attacks has posed attention to the necessity for precise and resilient systems for detecting and identifying such elements. While extensive literature and works exist on object detection based on RGB data, it is also critical to recognize the limits of such modality when applied to UAVs detection. Detecting drones indeed poses several challenges such as fast-moving objects and scenes with a high dynamic range or, even worse, scarce illumination levels. Neuromorphic cameras, on the other hand, can retain precise and rich spatio-temporal information in situations that are challenging for RGB cameras. They are resilient to both high-speed moving objects and scarce illumination settings, while prone to suffer a rapid loss of information when the objects in the scene are static. In this context, we present a novel model for integrating both domains together, leveraging multimodal data to take advantage of the best of both worlds. To this end, we also release NeRDD (Neuromorphic-RGB Drone Detection), a novel spatio-temporally synchronized Event-RGB Drone detection dataset of more than 3.5 hours of multimodal annotated recordings.
Addressing Limitations of State-Aware Imitation Learning for Autonomous Driving
Oct 31, 2023



Conditional Imitation learning is a common and effective approach to train autonomous driving agents. However, two issues limit the full potential of this approach: (i) the inertia problem, a special case of causal confusion where the agent mistakenly correlates low speed with no acceleration, and (ii) low correlation between offline and online performance due to the accumulation of small errors that brings the agent in a previously unseen state. Both issues are critical for state-aware models, yet informing the driving agent of its internal state as well as the state of the environment is of crucial importance. In this paper we propose a multi-task learning agent based on a multi-stage vision transformer with state token propagation. We feed the state of the vehicle along with the representation of the environment as a special token of the transformer and propagate it throughout the network. This allows us to tackle the aforementioned issues from different angles: guiding the driving policy with learned stop/go information, performing data augmentation directly on the state of the vehicle and visually explaining the model's decisions. We report a drastic decrease in inertia and a high correlation between offline and online metrics.
Automatic Estimation of Self-Reported Pain by Trajectory Analysis in the Manifold of Fixed Rank Positive Semi-Definite Matrices
Sep 17, 2022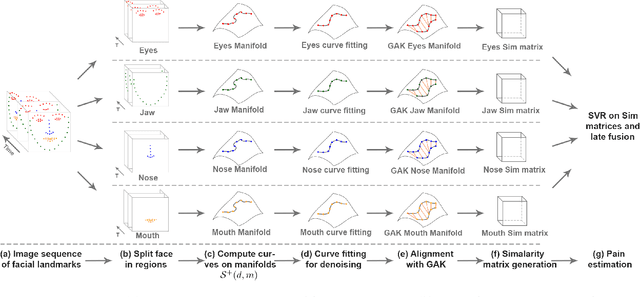
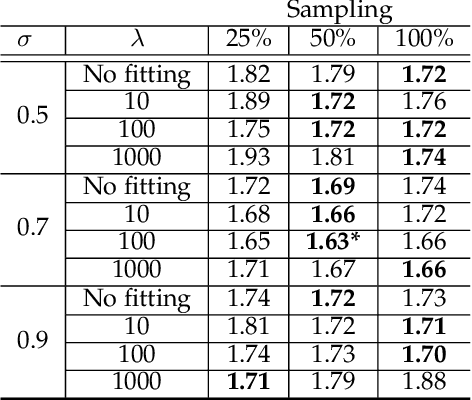
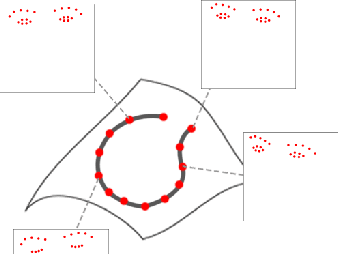
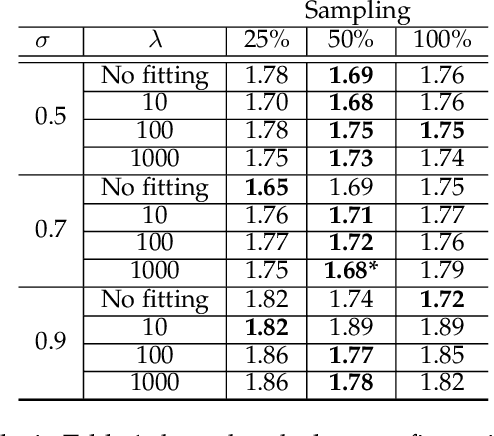
We propose an automatic method to estimate self-reported pain based on facial landmarks extracted from videos. For each video sequence, we decompose the face into four different regions and the pain intensity is measured by modeling the dynamics of facial movement using the landmarks of these regions. A formulation based on Gram matrices is used for representing the trajectory of landmarks on the Riemannian manifold of symmetric positive semi-definite matrices of fixed rank. A curve fitting algorithm is used to smooth the trajectories and temporal alignment is performed to compute the similarity between the trajectories on the manifold. A Support Vector Regression classifier is then trained to encode extracted trajectories into pain intensity levels consistent with self-reported pain intensity measurement. Finally, a late fusion of the estimation for each region is performed to obtain the final predicted pain level. The proposed approach is evaluated on two publicly available datasets, the UNBCMcMaster Shoulder Pain Archive and the Biovid Heat Pain dataset. We compared our method to the state-of-the-art on both datasets using different testing protocols, showing the competitiveness of the proposed approach.
Modelling the Statistics of Cyclic Activities by Trajectory Analysis on the Manifold of Positive-Semi-Definite Matrices
Jun 24, 2020

In this paper, a model is presented to extract statistical summaries to characterize the repetition of a cyclic body action, for instance a gym exercise, for the purpose of checking the compliance of the observed action to a template one and highlighting the parts of the action that are not correctly executed (if any). The proposed system relies on a Riemannian metric to compute the distance between two poses in such a way that the geometry of the manifold where the pose descriptors lie is preserved; a model to detect the begin and end of each cycle; a model to temporally align the poses of different cycles so as to accurately estimate the \emph{cross-sectional} mean and variance of poses across different cycles. The proposed model is demonstrated using gym videos taken from the Internet.