 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spatio-Temporal Graph Contrastive Learning
Aug 26, 2021
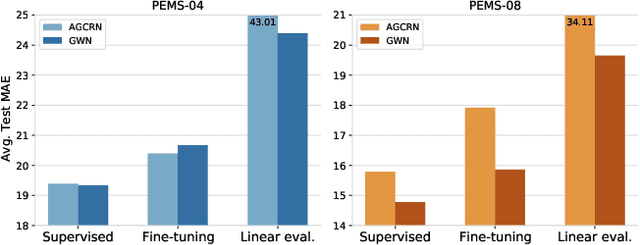
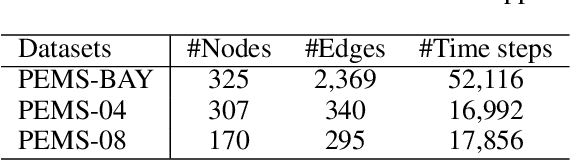
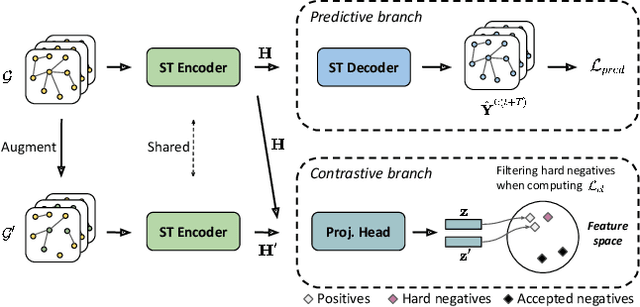
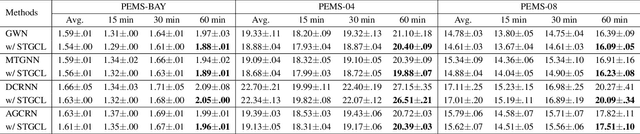
Deep learning models are modern tools for spatio-temporal graph (STG) forecasting. Despite their effectiveness, they require large-scale datasets to achieve better performance and are vulnerable to noise perturbation. To alleviate these limitations, an intuitive idea is to use the popular data augmentation and contrastive learning techniques. However, existing graph contrastive learning methods cannot be directly applied to STG forecasting due to three reasons. First, we empirically discover that the forecasting task is unable to benefit from the pretrained representations derived from contrastive learning. Second, data augmentations that are used for defeating noise are less explored for STG data. Third, the semantic similarity of samples has been overlooked. In this paper, we propose a Spatio-Temporal Graph Contrastive Learning framework (STGCL) to tackle these issues. Specifically, we improve the performance by integrating the forecasting loss with an auxiliary contrastive loss rather than using a pretrained paradigm. We elaborate on four types of data augmentations, which disturb data in terms of graph structure, time domain, and frequency domain. We also extend the classic contrastive loss through a rule-based strategy that filters out the most semantically similar negatives. Our framework is evaluated across three real-world datasets and four state-of-the-art models. The consistent improvements demonstrate that STGCL can be used as an off-the-shelf plug-in for existing deep models.
A Multimodal Machine Learning Framework for Teacher Vocal Delivery Evaluation
Jul 15, 2021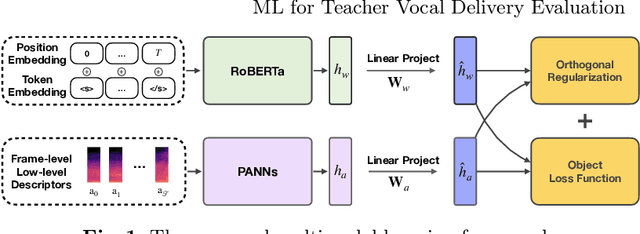
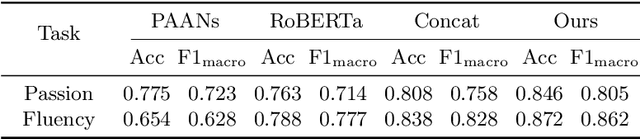
The quality of vocal delivery is one of the key indicators for evaluating teacher enthusiasm, which has been widely accepted to be connected to the overall course qualities. However, existing evaluation for vocal delivery is mainly conducted with manual ratings, which faces two core challenges: subjectivity and time-consuming. In this paper, we present a novel machine learning approach that utilizes pairwise comparisons and a multimodal orthogonal fusing algorithm to generate large-scale objective evaluation results of the teacher vocal delivery in terms of fluency and passion. We collect two datasets from real-world education scenarios and the experiment results demonstrate the effectiveness of our algorithm. To encourage reproducible results, we make our code public available at \url{https://github.com/tal-ai/ML4VocalDelivery.git}.
Effective Model Sparsification by Scheduled Grow-and-Prune Methods
Jun 18, 2021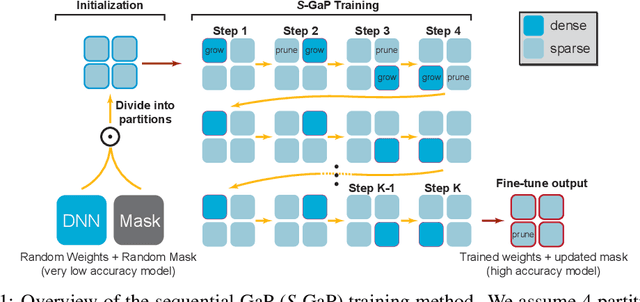

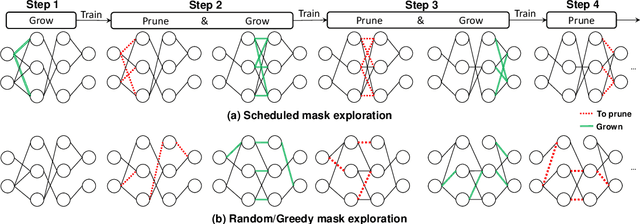
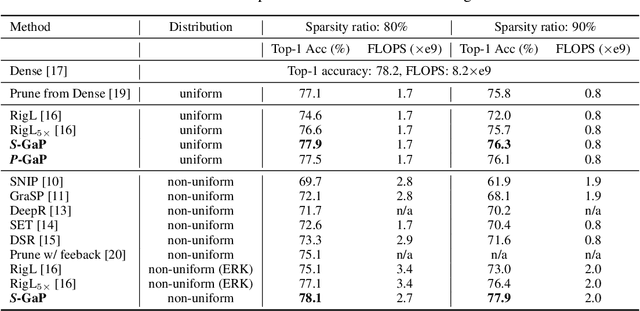
Deep neural networks (DNNs) are effective in solving many real-world problems. Larger DNN models usually exhibit better quality (e.g., accuracy) but their excessive computation results in long training and inference time. Model sparsification can reduce the computation and memory cost while maintaining model quality. Most existing sparsification algorithms unidirectionally remove weights, while others randomly or greedily explore a small subset of weights in each layer. The inefficiency of the algorithms reduces the achievable sparsity level. In addition, many algorithms still require pre-trained dense models and thus suffer from large memory footprint and long training time. In this paper, we propose a novel scheduled grow-and-prune (GaP) methodology without pre-training the dense models. It addresses the shortcomings of the previous works by repeatedly growing a subset of layers to dense and then pruning back to sparse after some training. Experiments have shown that such models can match or beat the quality of highly optimized dense models at 80% sparsity on a variety of tasks, such as image classification, objective detection, 3D object part segmentation, and translation. They also outperform other state-of-the-art (SOTA) pruning methods, including pruning from pre-trained dense models. As an example, a 90% sparse ResNet-50 obtained via GaP achieves 77.9% top-1 accuracy on ImageNet, improving the SOTA results by 1.5%.
DexRay: A Simple, yet Effective Deep Learning Approach to Android Malware Detection based on Image Representation of Bytecode
Sep 05, 2021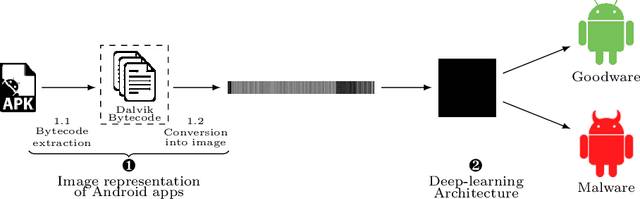


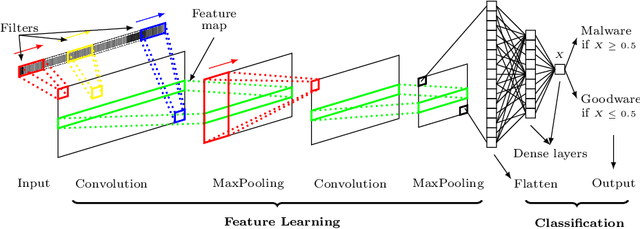
Computer vision has witnessed several advances in recent years, with unprecedented performance provided by deep representation learning research. Image formats thus appear attractive to other fields such as malware detection, where deep learning on images alleviates the need for comprehensively hand-crafted features generalising to different malware variants. We postulate that this research direction could become the next frontier in Android malware detection, and therefore requires a clear roadmap to ensure that new approaches indeed bring novel contributions. We contribute with a first building block by developing and assessing a baseline pipeline for image-based malware detection with straightforward steps. We propose DexRay, which converts the bytecode of the app DEX files into grey-scale "vector" images and feeds them to a 1-dimensional Convolutional Neural Network model. We view DexRay as foundational due to the exceedingly basic nature of the design choices, allowing to infer what could be a minimal performance that can be obtained with image-based learning in malware detection. The performance of DexRay evaluated on over 158k apps demonstrates that, while simple, our approach is effective with a high detection rate(F1-score= 0.96). Finally, we investigate the impact of time decay and image-resizing on the performance of DexRay and assess its resilience to obfuscation. This work-in-progress paper contributes to the domain of Deep Learning based Malware detection by providing a sound, simple, yet effective approach (with available artefacts) that can be the basis to scope the many profound questions that will need to be investigated to fully develop this domain.
Magnetic Field Sensing for Pedestrian and Robot Indoor Positioning
Aug 26, 2021
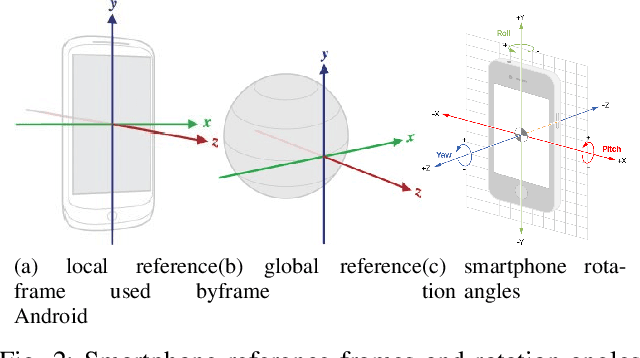
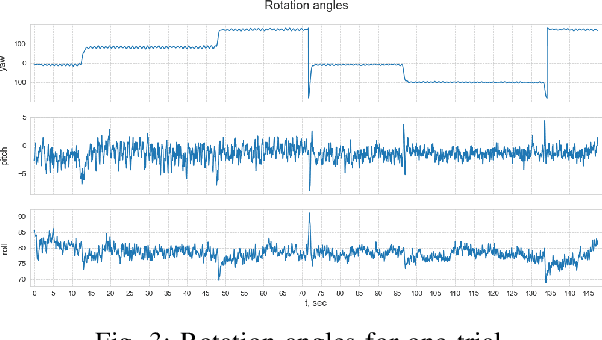
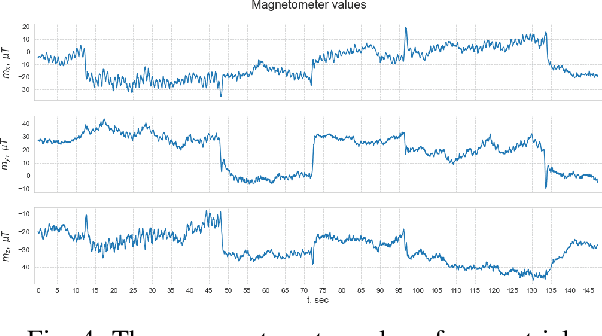
In this paper we address the problem of indoor localization using magnetic field data in two setups, when data is collected by (i) human-held mobile phone and (ii) by localization robots that perturb magnetic data with their own electromagnetic field. For the first setup, we revise the state of the art approaches and propose a novel extended pipeline to benefit from the presence of magnetic anomalies in indoor environment created by different ferromagnetic objects. We capture changes of the Earth's magnetic field due to indoor magnetic anomalies and transform them in multi-variate times series. We then convert temporal patterns into visual ones. We use methods of Recurrence Plots, Gramian Angular Fields and Markov Transition Fields to represent magnetic field time series as image sequences. We regress the continuous values of user position in a deep neural network that combines convolutional and recurrent layers. For the second setup, we analyze how magnetic field data get perturbed by robots' electromagnetic field. We add an alignment step to the main pipeline, in order to compensate the mismatch between train and test sets obtained by different robots. We test our methods on two public (MagPie and IPIN'20) and one proprietary (Hyundai department store) datasets. We report evaluation results and show that our methods outperform the state of the art methods by a large margin.
Towards a distributed and real-time framework for robots: Evaluation of ROS 2.0 communications for real-time robotic applications
Sep 07, 2018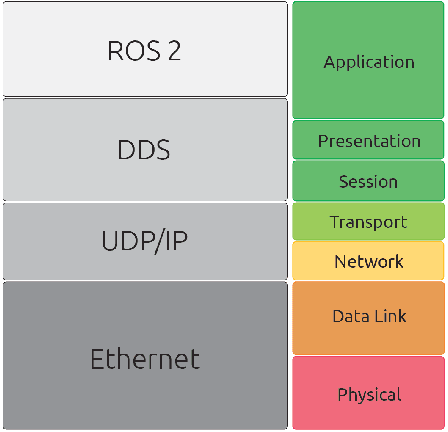
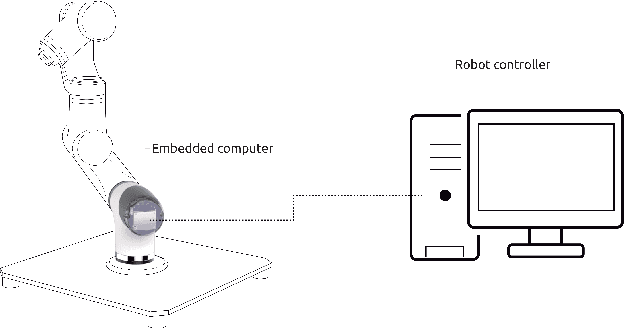
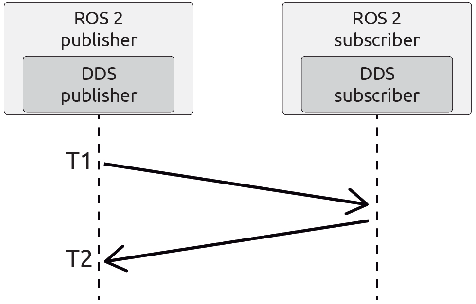
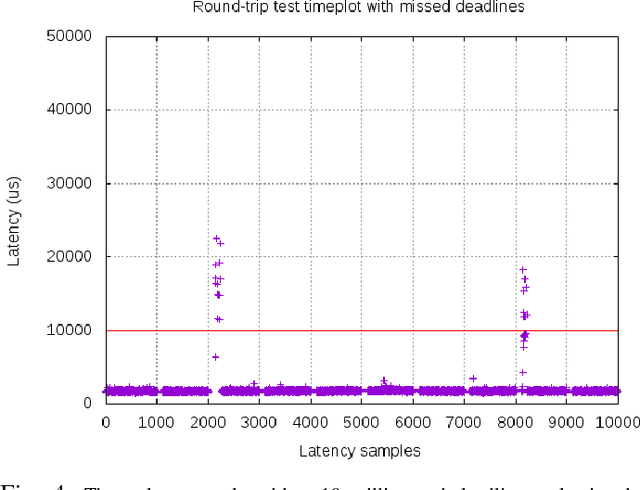
In this work we present an experimental setup to show the suitability of ROS 2.0 for real-time robotic applications. We disclose an evaluation of ROS 2.0 communications in a robotic inter-component (hardware) communication case on top of Linux. We benchmark and study the worst case latencies and missed deadlines to characterize ROS 2.0 communications for real-time applications. We demonstrate experimentally how computation and network congestion impacts the communication latencies and ultimately, propose a setup that, under certain conditions, mitigates these delays and obtains bounded traffic.
Real-time Soft Robot 3D Proprioception via Deep Vision-based Sensing
Apr 08, 2019
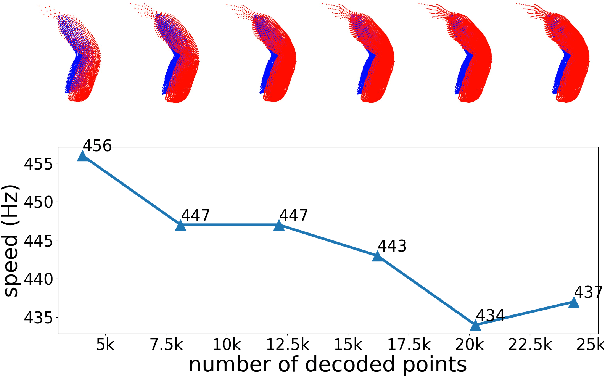
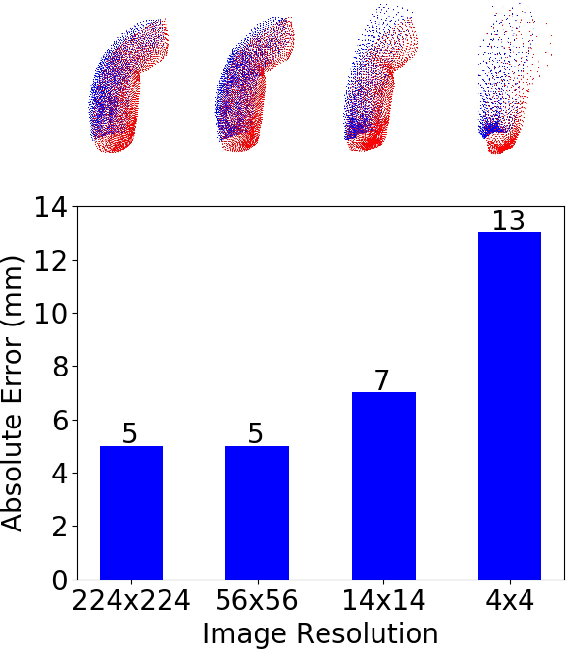
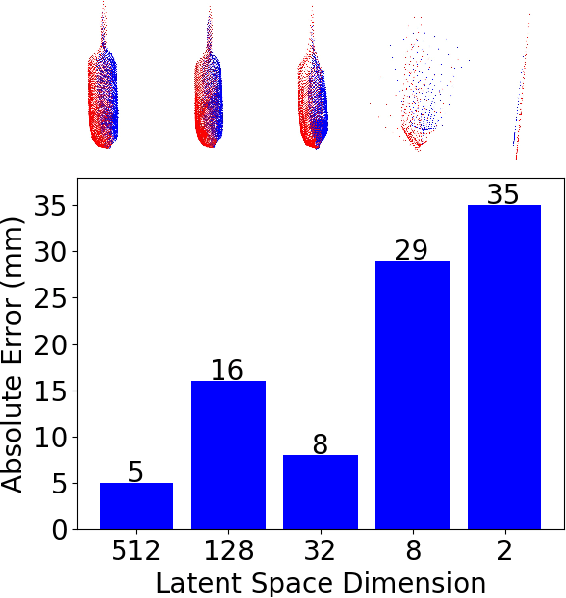
The soft robots are welcomed in many robotic applications because of their high flexibility, which also poses a long-standing challenge on their proprioception, or measuring the real-time 3D shapes of the soft robots from internal sensors. The challenge exists in both the sensor design and robot modeling. In this paper, we propose a framework to measure the real-time high-resolution 3D shapes of soft robots. The framework is based on an embedded camera to capture the inside/outside patterns of the robots under different loading conditions, and a CNN to produce a latent code representing the robot state, which can then be used to reconstruct the 3D shape using a neural network improved from FoldingNet. We tested the framework on four different soft actuators with various kinds of deformations, and achieved real-time computation ($<$2ms/frame) for robust shape estimation of high precision ($<$5% relative error for 2025 points) at an arbitrary resolution. We believe the method could be widely applied to different designs of soft robots for proprioception, and enabling people to better control them under complicated environments. Our code is available at https://ai4ce.github.io/Deep-Soft-Prorioception/.
Fast Manipulability Maximization Using Continuous-Time Trajectory Optimization
Aug 08, 2019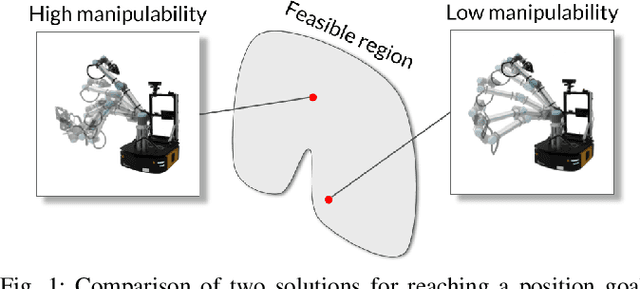
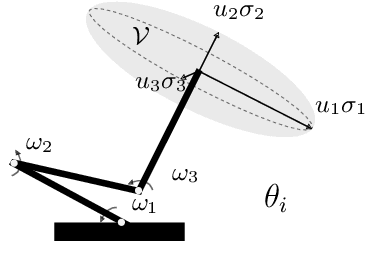
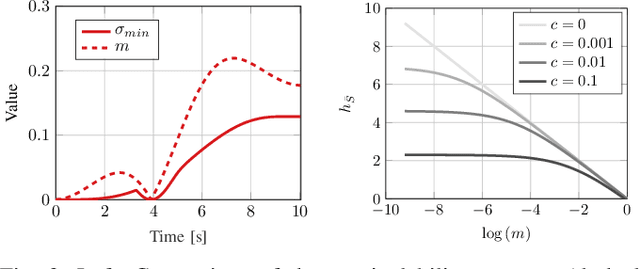
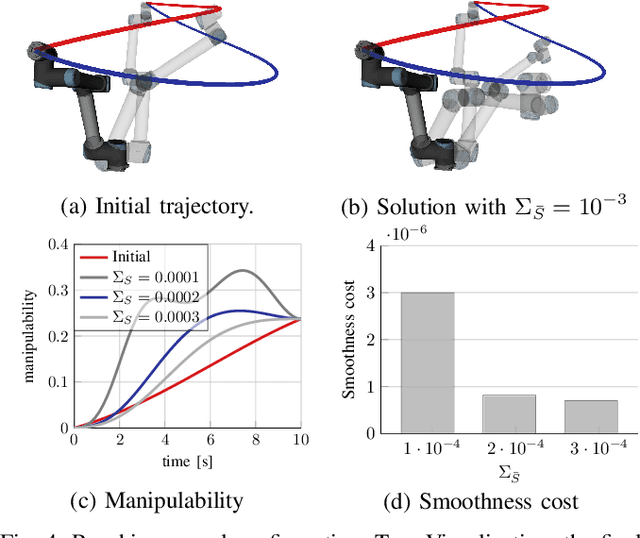
A significant challenge in manipulation motion planning is to ensure agility in the face of unpredictable changes during task execution. This requires the identification and possible modification of suitable joint-space trajectories, since the joint velocities required to achieve a specific end-effector motion vary with manipulator configuration. For a given manipulator configuration, the joint space-to-task space velocity mapping is characterized by a quantity known as the manipulability index. In contrast to previous control-based approaches, we examine the maximization of manipulability during planning as a way of achieving adaptable and safe joint space-to-task space motion mappings in various scenarios. By representing the manipulator trajectory as a continuous-time Gaussian process (GP), we are able to leverage recent advances in trajectory optimization to maximize the manipulability index during trajectory generation. Moreover, the sparsity of our chosen representation reduces the typically large computational cost associated with maximizing manipulability when additional constraints exist. Results from simulation studies and experiments with a real manipulator demonstrate increases in manipulability, while maintaining smooth trajectories with more dexterous (and therefore more agile) arm configurations.
Disentangling What and Where for 3D Object-Centric Representations Through Active Inference
Aug 26, 2021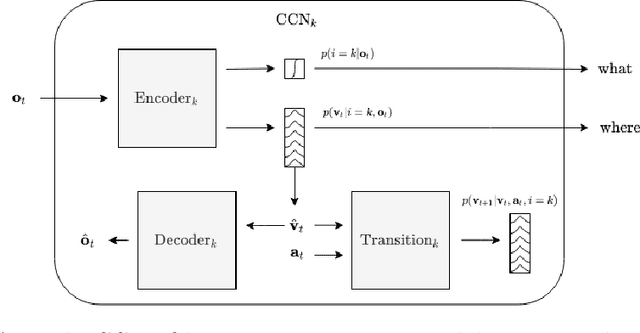
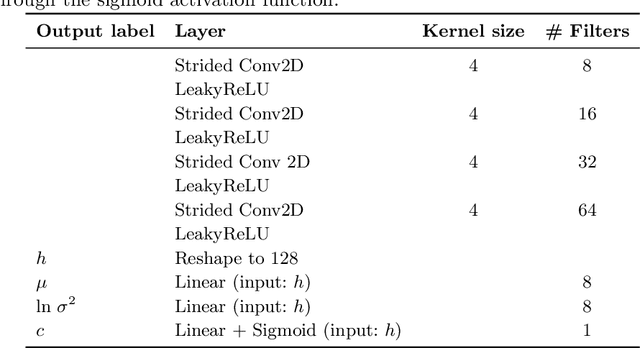
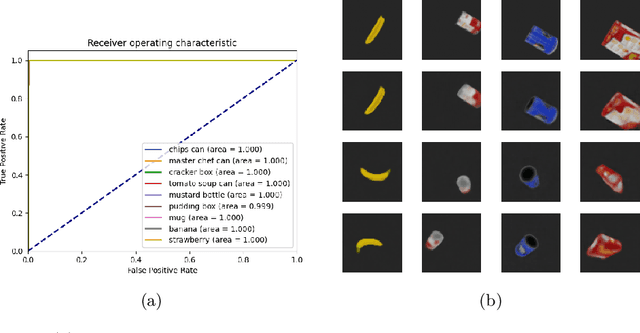
Although modern object detection and classification models achieve high accuracy, these are typically constrained in advance on a fixed train set and are therefore not flexible to deal with novel, unseen object categories. Moreover, these models most often operate on a single frame, which may yield incorrect classifications in case of ambiguous viewpoints. In this paper, we propose an active inference agent that actively gathers evidence for object classifications, and can learn novel object categories over time. Drawing inspiration from the human brain, we build object-centric generative models composed of two information streams, a what- and a where-stream. The what-stream predicts whether the observed object belongs to a specific category, while the where-stream is responsible for representing the object in its internal 3D reference frame. We show that our agent (i) is able to learn representations for many object categories in an unsupervised way, (ii) achieves state-of-the-art classification accuracies, actively resolving ambiguity when required and (iii) identifies novel object categories. Furthermore, we validate our system in an end-to-end fashion where the agent is able to search for an object at a given pose from a pixel-based rendering. We believe that this is a first step towards building modular, intelligent systems that can be used for a wide range of tasks involving three dimensional objects.
Training Quantized Neural Networks to Global Optimality via Semidefinite Programming
May 04, 2021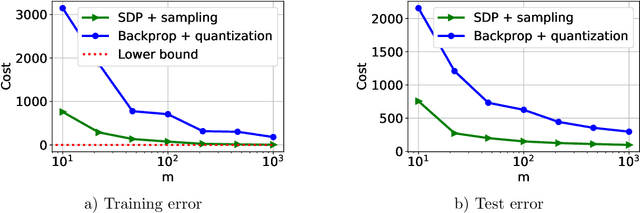
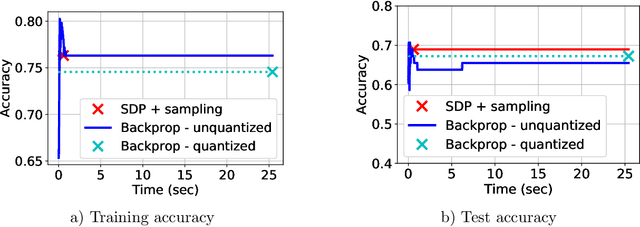
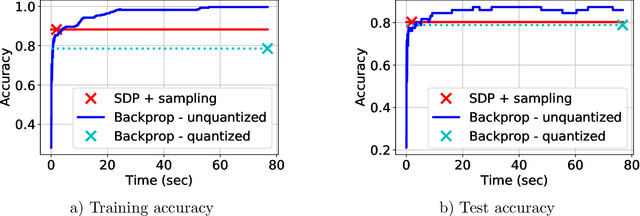
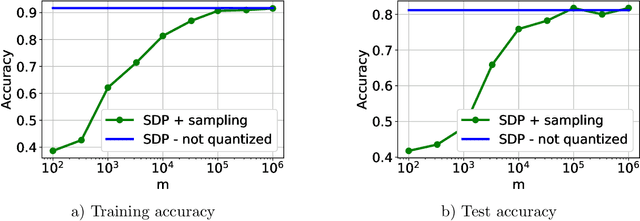
Neural networks (NNs) have been extremely successful across many tasks in machine learning. Quantization of NN weights has become an important topic due to its impact on their energy efficiency, inference time and deployment on hardware. Although post-training quantization is well-studied, training optimal quantized NNs involves combinatorial non-convex optimization problems which appear intractable. In this work, we introduce a convex optimization strategy to train quantized NNs with polynomial activations. Our method leverages hidden convexity in two-layer neural networks from the recent literature, semidefinite lifting, and Grothendieck's identity. Surprisingly, we show that certain quantized NN problems can be solved to global optimality in polynomial-time in all relevant parameters via semidefinite relaxations. We present numerical examples to illustrate the effectiveness of our method.