 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Model Sparsification by Scheduled Grow-and-Prune Methods
Paper and Code
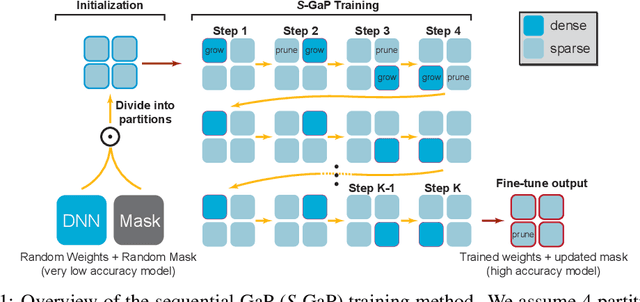

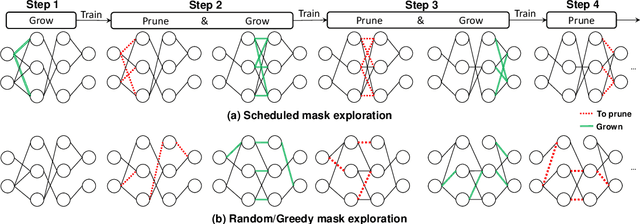
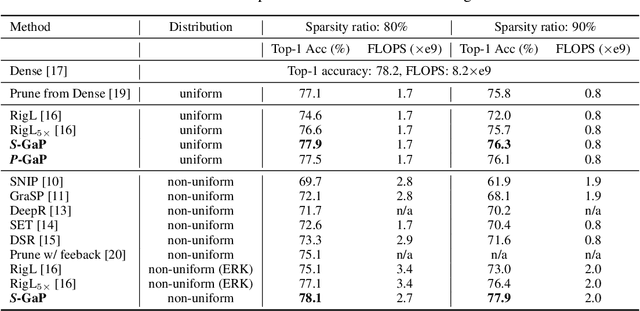
Deep neural networks (DNNs) are effective in solving many real-world problems. Larger DNN models usually exhibit better quality (e.g., accuracy) but their excessive computation results in long training and inference time. Model sparsification can reduce the computation and memory cost while maintaining model quality. Most existing sparsification algorithms unidirectionally remove weights, while others randomly or greedily explore a small subset of weights in each layer. The inefficiency of the algorithms reduces the achievable sparsity level. In addition, many algorithms still require pre-trained dense models and thus suffer from large memory footprint and long training time. In this paper, we propose a novel scheduled grow-and-prune (GaP) methodology without pre-training the dense models. It addresses the shortcomings of the previous works by repeatedly growing a subset of layers to dense and then pruning back to sparse after some training. Experiments have shown that such models can match or beat the quality of highly optimized dense models at 80% sparsity on a variety of tasks, such as image classification, objective detection, 3D object part segmentation, and translation. They also outperform other state-of-the-art (SOTA) pruning methods, including pruning from pre-trained dense models. As an example, a 90% sparse ResNet-50 obtained via GaP achieves 77.9% top-1 accuracy on ImageNet, improving the SOTA results by 1.5%.