 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Policy Learning over Multiple Uncertainty Sets
Mar 04, 2022
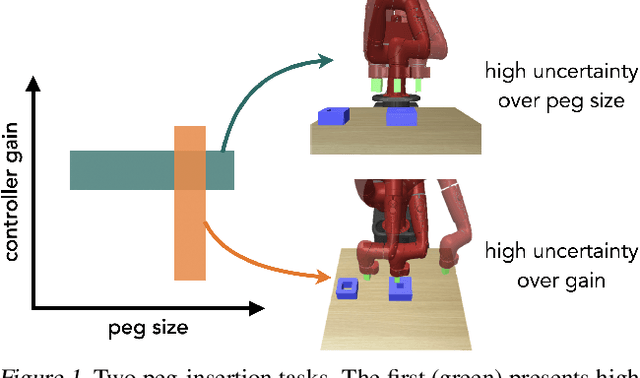
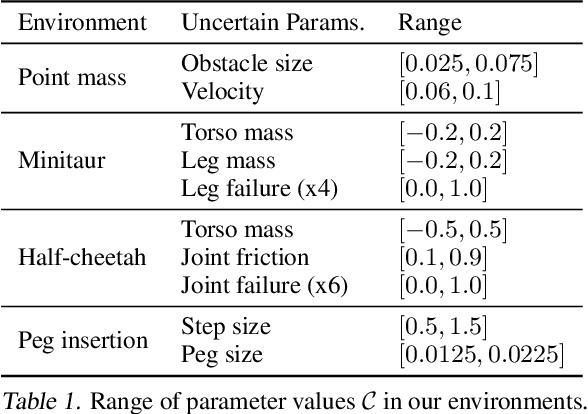
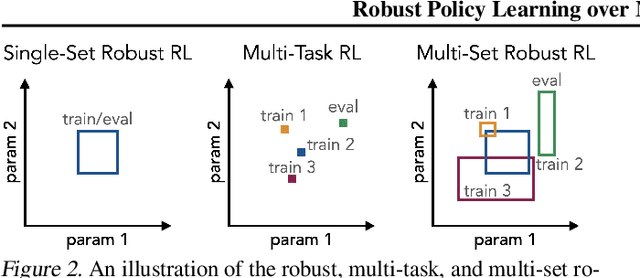

Reinforcement learning (RL) agents need to be robust to variations in safety-critical environments. While system identification methods provide a way to infer the variation from online experience, they can fail in settings where fast identification is not possible. Another dominant approach is robust RL which produces a policy that can handle worst-case scenarios, but these methods are generally designed to achieve robustness to a single uncertainty set that must be specified at train time. Towards a more general solution, we formulate the multi-set robustness problem to learn a policy robust to different perturbation sets. We then design an algorithm that enjoys the benefits of both system identification and robust RL: it reduces uncertainty where possible given a few interactions, but can still act robustly with respect to the remaining uncertainty. On a diverse set of control tasks, our approach demonstrates improved worst-case performance on new environments compared to prior methods based on system identification and on robust RL alone.
Deep Time Delay Neural Network for Speech Enhancement with Full Data Learning
Nov 11, 2020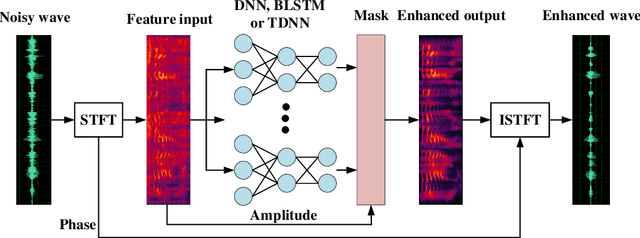
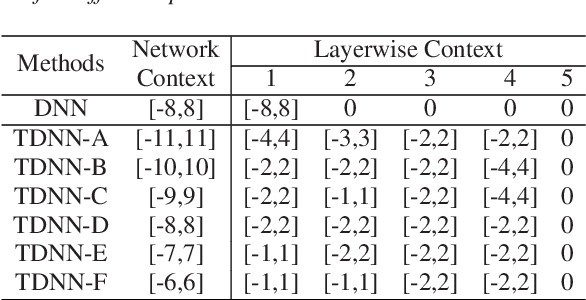
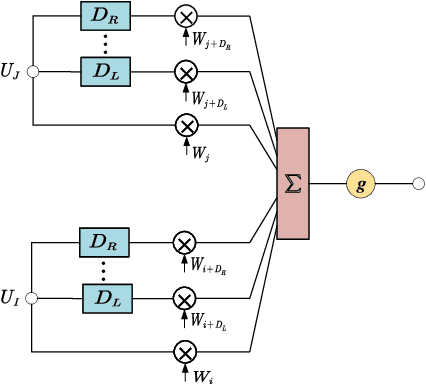
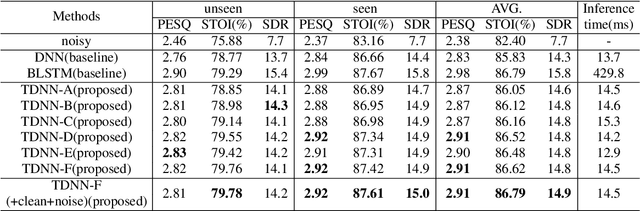
Recurrent neural networks (RNNs) have shown significant improvements in recent years for speech enhancement. However, the model complexity and inference time cost of RNNs are much higher than deep feed-forward neural networks (DNNs). Therefore, these limit the applications of speech enhancement. This paper proposes a deep time delay neural network (TDNN) for speech enhancement with full data learning. The TDNN has excellent potential for capturing long range temporal contexts, which utilizes a modular and incremental design. Besides, the TDNN preserves the feed-forward structure so that its inference cost is comparable to standard DNN. To make full use of the training data, we propose a full data learning method for speech enhancement. More specifically, we not only use the noisy-to-clean (input-to-target) to train the enhanced model, but also the clean-to-clean and noise-to-silence data. Therefore, all of the training data can be used to train the enhanced model. Our experiments are conducted on TIMIT dataset. Experimental results show that our proposed method could achieve a better performance than DNN and comparable even better performance than BLSTM. Meanwhile, compared with the BLSTM, the proposed method drastically reduce the inference time.
Reinforcement Learning with Dynamic Convex Risk Measures
Dec 26, 2021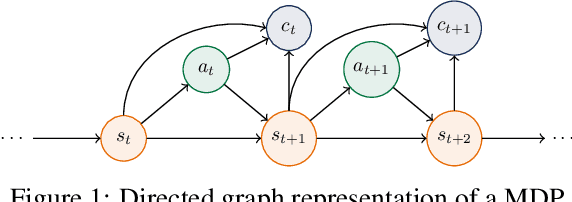
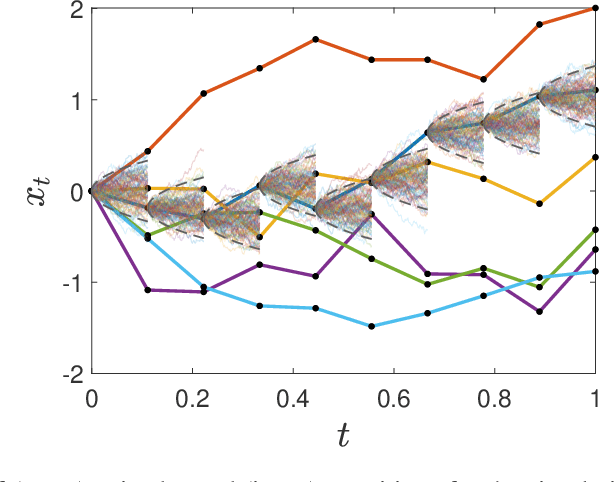
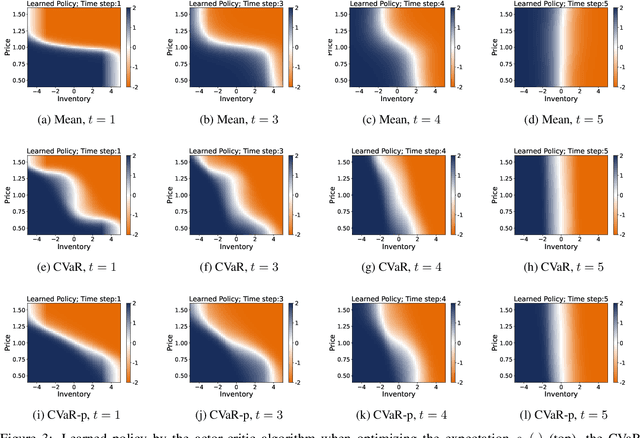
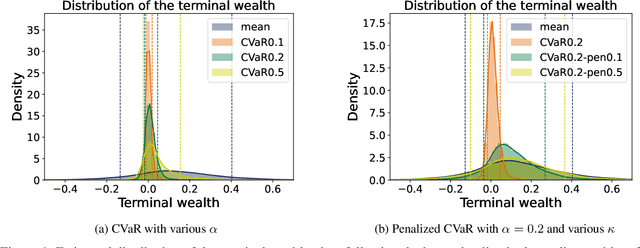
We develop an approach for solving time-consistent risk-sensitive stochastic optimization problems using model-free reinforcement learning (RL). Specifically, we assume agents assess the risk of a sequence of random variables using dynamic convex risk measures. We employ a time-consistent dynamic programming principle to determine the value of a particular policy, and develop policy gradient update rules. We further develop an actor-critic style algorithm using neural networks to optimize over policies. Finally, we demonstrate the performance and flexibility of our approach by applying it to optimization problems in statistical arbitrage trading and obstacle avoidance robot control.
TensoRF: Tensorial Radiance Fields
Mar 17, 2022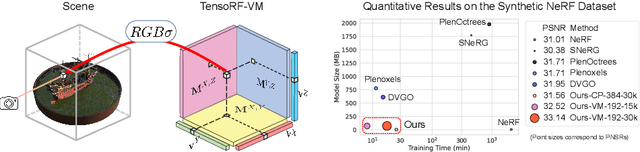
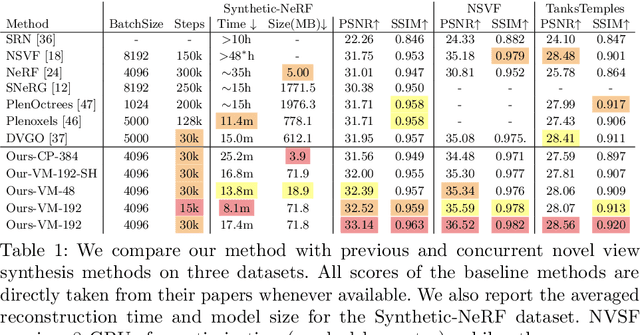

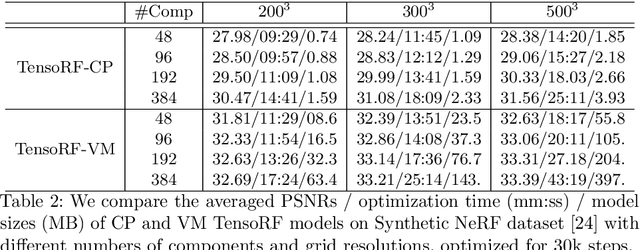
We present TensoRF, a novel approach to model and reconstruct radiance fields. Unlike NeRF that purely uses MLPs, we model the radiance field of a scene as a 4D tensor, which represents a 3D voxel grid with per-voxel multi-channel features. Our central idea is to factorize the 4D scene tensor into multiple compact low-rank tensor components. We demonstrate that applying traditional CP decomposition -- that factorizes tensors into rank-one components with compact vectors -- in our framework leads to improvements over vanilla NeRF. To further boost performance, we introduce a novel vector-matrix (VM) decomposition that relaxes the low-rank constraints for two modes of a tensor and factorizes tensors into compact vector and matrix factors. Beyond superior rendering quality, our models with CP and VM decompositions lead to a significantly lower memory footprint in comparison to previous and concurrent works that directly optimize per-voxel features. Experimentally, we demonstrate that TensoRF with CP decomposition achieves fast reconstruction (<30 min) with better rendering quality and even a smaller model size (<4 MB) compared to NeRF. Moreover, TensoRF with VM decomposition further boosts rendering quality and outperforms previous state-of-the-art methods, while reducing the reconstruction time (<10 min) and retaining a compact model size (<75 MB).
Transformers in Action: Weakly Supervised Action Segmentation
Jan 20, 2022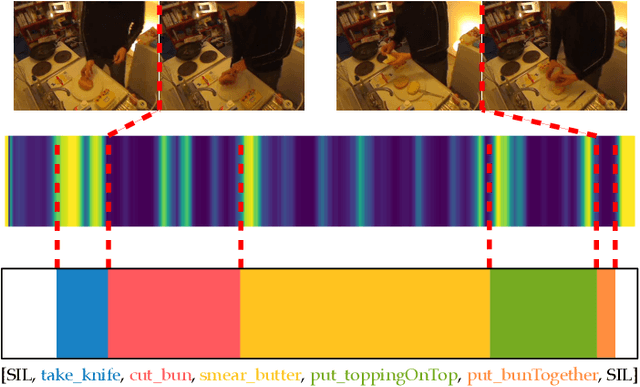
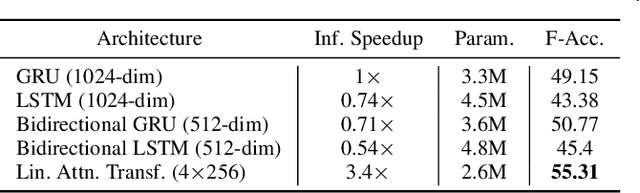
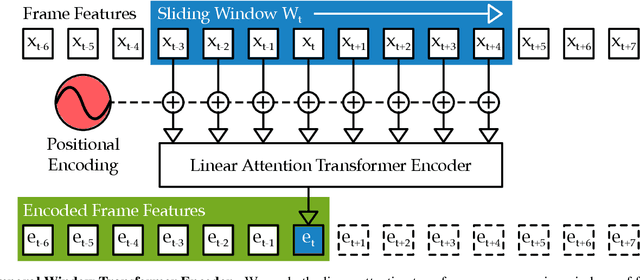
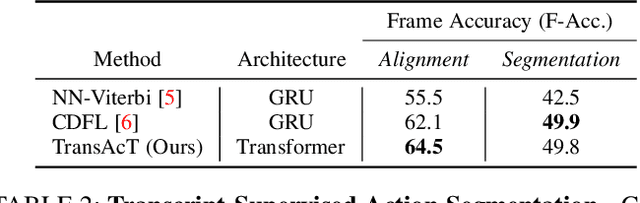
The video action segmentation task is regularly explored under weaker forms of supervision, such as transcript supervision, where a list of actions is easier to obtain than dense frame-wise labels. In this formulation, the task presents various challenges for sequence modeling approaches due to the emphasis on action transition points, long sequence lengths, and frame contextualization, making the task well-posed for transformers. Given developments enabling transformers to scale linearly, we demonstrate through our architecture how they can be applied to improve action alignment accuracy over the equivalent RNN-based models with the attention mechanism focusing around salient action transition regions. Additionally, given the recent focus on inference-time transcript selection, we propose a supplemental transcript embedding approach to select transcripts more quickly at inference-time. Furthermore, we subsequently demonstrate how this approach can also improve the overall segmentation performance. Finally, we evaluate our proposed methods across the benchmark datasets to better understand the applicability of transformers and the importance of transcript selection on this video-driven weakly-supervised task.
Breast Cancer Induced Bone Osteolysis Prediction Using Temporal Variational Auto-Encoders
Mar 28, 2022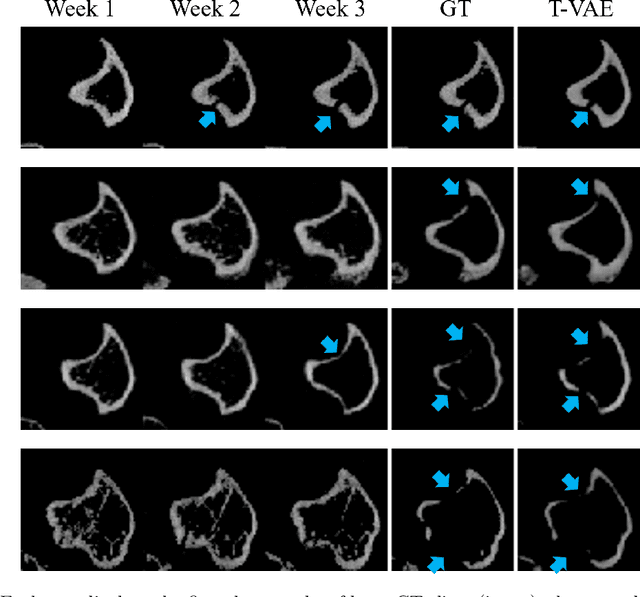
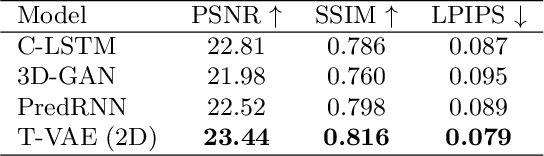
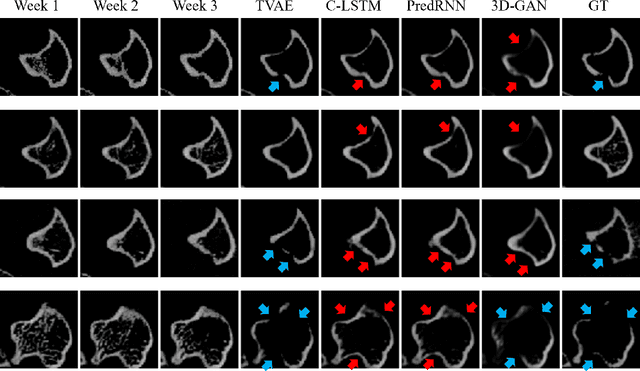

Objective and Impact Statement. We adopt a deep learning model for bone osteolysis prediction on computed tomography (CT) images of murine breast cancer bone metastases. Given the bone CT scans at previous time steps, the model incorporates the bone-cancer interactions learned from the sequential images and generates future CT images. Its ability of predicting the development of bone lesions in cancer-invading bones can assist in assessing the risk of impending fractures and choosing proper treatments in breast cancer bone metastasis. Introduction. Breast cancer often metastasizes to bone, causes osteolytic lesions, and results in skeletal related events (SREs) including severe pain and even fatal fractures. Although current imaging techniques can detect macroscopic bone lesions, predicting the occurrence and progression of bone lesions remains a challenge. Methods. We adopt a temporal variational auto-encoder (T-VAE) model that utilizes a combination of variational auto-encoders and long short-term memory networks to predict bone lesion emergence on our micro-CT dataset containing sequential images of murine tibiae. Given the CT scans of murine tibiae at early weeks, our model can learn the distribution of their future states from data. Results. We test our model against other deep learning-based prediction models on the bone lesion progression prediction task. Our model produces much more accurate predictions than existing models under various evaluation metrics. Conclusion. We develop a deep learning framework that can accurately predict and visualize the progression of osteolytic bone lesions. It will assist in planning and evaluating treatment strategies to prevent SREs in breast cancer patients.
ABCNet v2: Adaptive Bezier-Curve Network for Real-time End-to-end Text Spotting
May 29, 2021
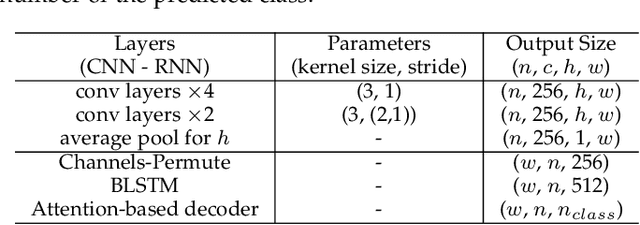


End-to-end text-spotting, which aims to integrate detection and recognition in a unified framework, has attracted increasing attention due to its simplicity of the two complimentary tasks. It remains an open problem especially when processing arbitrarily-shaped text instances. Previous methods can be roughly categorized into two groups: character-based and segmentation-based, which often require character-level annotations and/or complex post-processing due to the unstructured output. Here, we tackle end-to-end text spotting by presenting Adaptive Bezier Curve Network v2 (ABCNet v2). Our main contributions are four-fold: 1) For the first time, we adaptively fit arbitrarily-shaped text by a parameterized Bezier curve, which, compared with segmentation-based methods, can not only provide structured output but also controllable representation. 2) We design a novel BezierAlign layer for extracting accurate convolution features of a text instance of arbitrary shapes, significantly improving the precision of recognition over previous methods. 3) Different from previous methods, which often suffer from complex post-processing and sensitive hyper-parameters, our ABCNet v2 maintains a simple pipeline with the only post-processing non-maximum suppression (NMS). 4) As the performance of text recognition closely depends on feature alignment, ABCNet v2 further adopts a simple yet effective coordinate convolution to encode the position of the convolutional filters, which leads to a considerable improvement with negligible computation overhead. Comprehensive experiments conducted on various bilingual (English and Chinese) benchmark datasets demonstrate that ABCNet v2 can achieve state-of-the-art performance while maintaining very high efficiency.
ALDI++: Automatic and parameter-less discord and outlier detection for building energy load profiles
Mar 13, 2022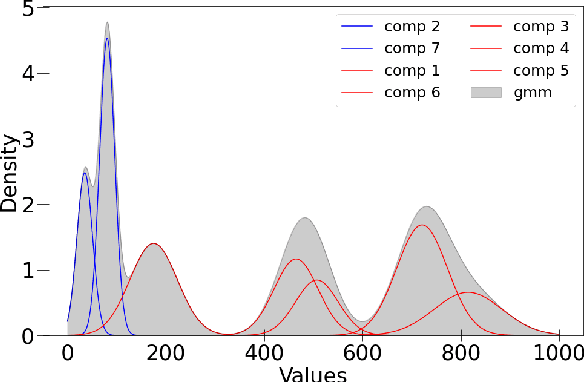
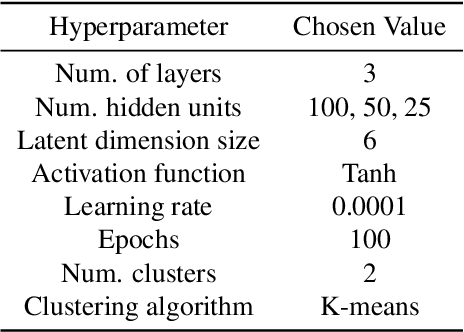
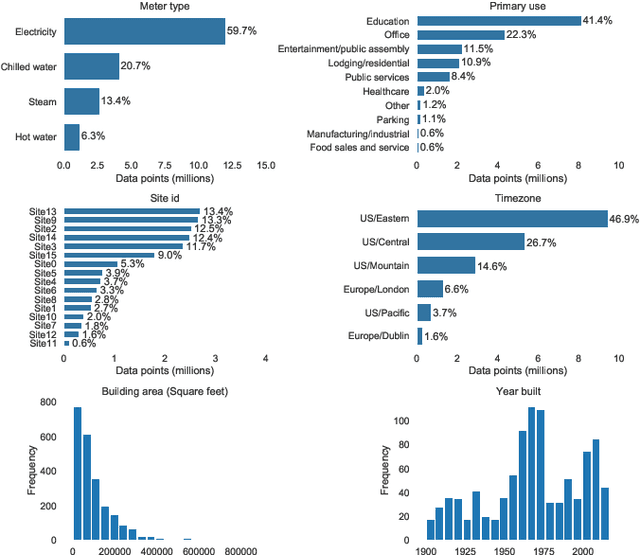
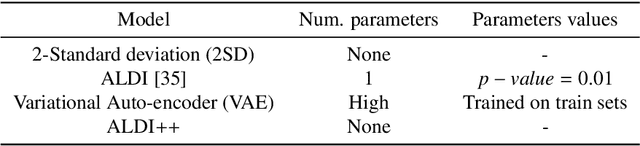
Data-driven building energy prediction is an integral part of the process for measurement and verification, building benchmarking, and building-to-grid interaction. The ASHRAE Great Energy Predictor III (GEPIII) machine learning competition used an extensive meter data set to crowdsource the most accurate machine learning workflow for whole building energy prediction. A significant component of the winning solutions was the pre-processing phase to remove anomalous training data. Contemporary pre-processing methods focus on filtering statistical threshold values or deep learning methods requiring training data and multiple hyper-parameters. A recent method named ALDI (Automated Load profile Discord Identification) managed to identify these discords using matrix profile, but the technique still requires user-defined parameters. We develop ALDI++, a method based on the previous work that bypasses user-defined parameters and takes advantage of discord similarity. We evaluate ALDI++ against a statistical threshold, variational auto-encoder, and the original ALDI as baselines in classifying discords and energy forecasting scenarios. Our results demonstrate that while the classification performance improvement over the original method is marginal, ALDI++ helps achieve the best forecasting error improving 6% over the winning's team approach with six times less computation time.
A Differentiable Two-stage Alignment Scheme for Burst Image Reconstruction with Large Shift
Mar 17, 2022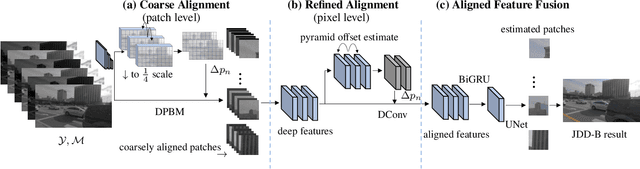
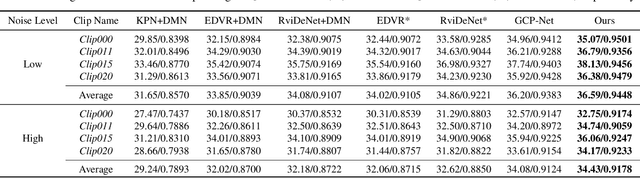
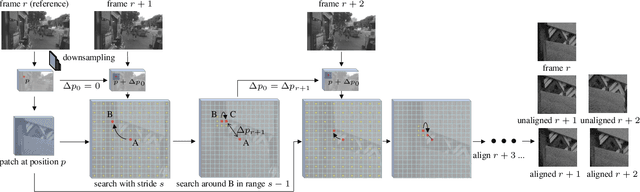
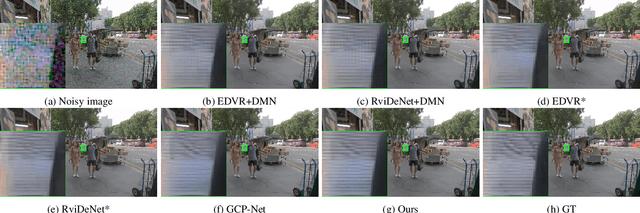
Denoising and demosaicking are two essential steps to reconstruct a clean full-color image from the raw data. Recently, joint denoising and demosaicking (JDD) for burst images, namely JDD-B, has attracted much attention by using multiple raw images captured in a short time to reconstruct a single high-quality image. One key challenge of JDD-B lies in the robust alignment of image frames. State-of-the-art alignment methods in feature domain cannot effectively utilize the temporal information of burst images, where large shifts commonly exist due to camera and object motion. In addition, the higher resolution (e.g., 4K) of modern imaging devices results in larger displacement between frames. To address these challenges, we design a differentiable two-stage alignment scheme sequentially in patch and pixel level for effective JDD-B. The input burst images are firstly aligned in the patch level by using a differentiable progressive block matching method, which can estimate the offset between distant frames with small computational cost. Then we perform implicit pixel-wise alignment in full-resolution feature domain to refine the alignment results. The two stages are jointly trained in an end-to-end manner. Extensive experiments demonstrate the significant improvement of our method over existing JDD-B methods. Codes are available at https://github.com/GuoShi28/2StageAlign.
Transfer learning for cross-modal demand prediction of bike-share and public transit
Mar 17, 2022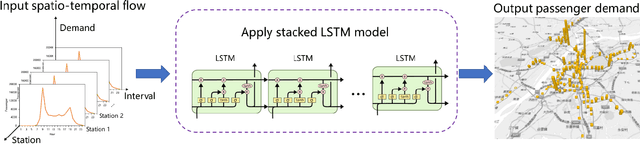
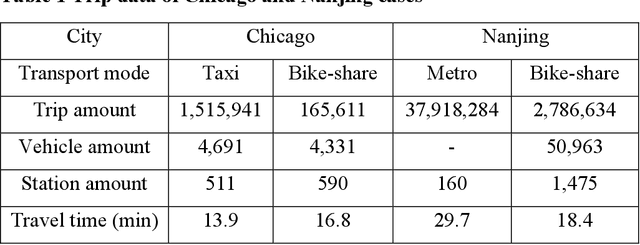
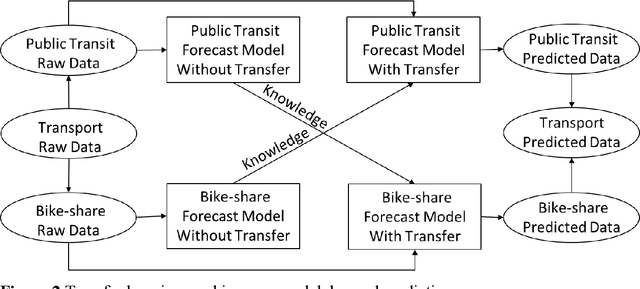
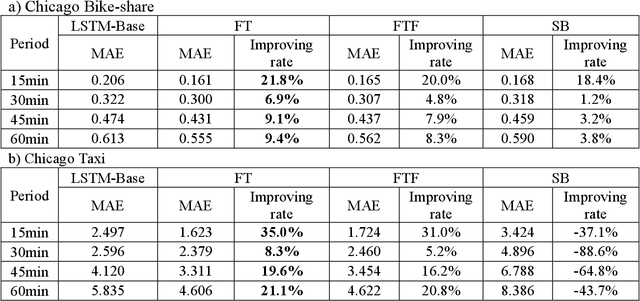
The urban transportation system is a combination of multiple transport modes, and the interdependencies across those modes exist. This means that the travel demand across different travel modes could be correlated as one mode may receive demand from or create demand for another mode, not to mention natural correlations between different demand time series due to general demand flow patterns across the network. It is expectable that cross-modal ripple effects become more prevalent, with Mobility as a Service. Therefore, by propagating demand data across modes, a better demand prediction could be obtained. To this end, this study explores various machine learning models and transfer learning strategies for cross-modal demand prediction. The trip data of bike-share, metro, and taxi are processed as the station-level passenger flows, and then the proposed prediction method is tested in the large-scale case studies of Nanjing and Chicago. The results suggest that prediction models with transfer learning perform better than unimodal prediction models. Furthermore, stacked Long Short-Term Memory model performs particularly well in cross-modal demand prediction. These results verify our combined method's forecasting improvement over existing benchmarks and demonstrate the good transferability for cross-modal demand prediction in multiple cities.