 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Time and Risk: Risk-Sensitive Reinforcement Learning with General Discounting
Feb 04, 2026Distributional reinforcement learning (RL) is a powerful framework increasingly adopted in safety-critical domains for its ability to optimize risk-sensitive objectives. However, the role of the discount factor is often overlooked, as it is typically treated as a fixed parameter of the Markov decision process or tunable hyperparameter, with little consideration of its effect on the learned policy. In the literature, it is well-known that the discounting function plays a major role in characterizing time preferences of an agent, which an exponential discount factor cannot fully capture. Building on this insight, we propose a novel framework that supports flexible discounting of future rewards and optimization of risk measures in distributional RL. We provide a technical analysis of the optimality of our algorithms, show that our multi-horizon extension fixes issues raised with existing methodologies, and validate the robustness of our methods through extensive experiments. Our results highlight that discounting is a cornerstone in decision-making problems for capturing more expressive temporal and risk preferences profiles, with potential implications for real-world safety-critical applications.
Robust Reinforcement Learning with Dynamic Distortion Risk Measures
Sep 16, 2024In a reinforcement learning (RL) setting, the agent's optimal strategy heavily depends on her risk preferences and the underlying model dynamics of the training environment. These two aspects influence the agent's ability to make well-informed and time-consistent decisions when facing testing environments. In this work, we devise a framework to solve robust risk-aware RL problems where we simultaneously account for environmental uncertainty and risk with a class of dynamic robust distortion risk measures. Robustness is introduced by considering all models within a Wasserstein ball around a reference model. We estimate such dynamic robust risk measures using neural networks by making use of strictly consistent scoring functions, derive policy gradient formulae using the quantile representation of distortion risk measures, and construct an actor-critic algorithm to solve this class of robust risk-aware RL problems. We demonstrate the performance of our algorithm on a portfolio allocation example.
Eliciting Risk Aversion with Inverse Reinforcement Learning via Interactive Questioning
Aug 16, 2023



This paper proposes a novel framework for identifying an agent's risk aversion using interactive questioning. Our study is conducted in two scenarios: a one-period case and an infinite horizon case. In the one-period case, we assume that the agent's risk aversion is characterized by a cost function of the state and a distortion risk measure. In the infinite horizon case, we model risk aversion with an additional component, a discount factor. Assuming the access to a finite set of candidates containing the agent's true risk aversion, we show that asking the agent to demonstrate her optimal policies in various environment, which may depend on their previous answers, is an effective means of identifying the agent's risk aversion. Specifically, we prove that the agent's risk aversion can be identified as the number of questions tends to infinity, and the questions are randomly designed. We also develop an algorithm for designing optimal questions and provide empirical evidence that our method learns risk aversion significantly faster than randomly designed questions in simulations. Our framework has important applications in robo-advising and provides a new approach for identifying an agent's risk preferences.
Conditionally Elicitable Dynamic Risk Measures for Deep Reinforcement Learning
Jun 29, 2022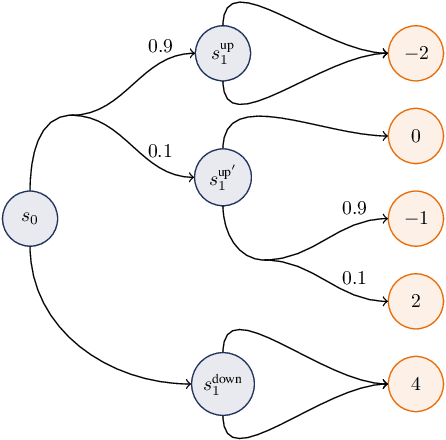
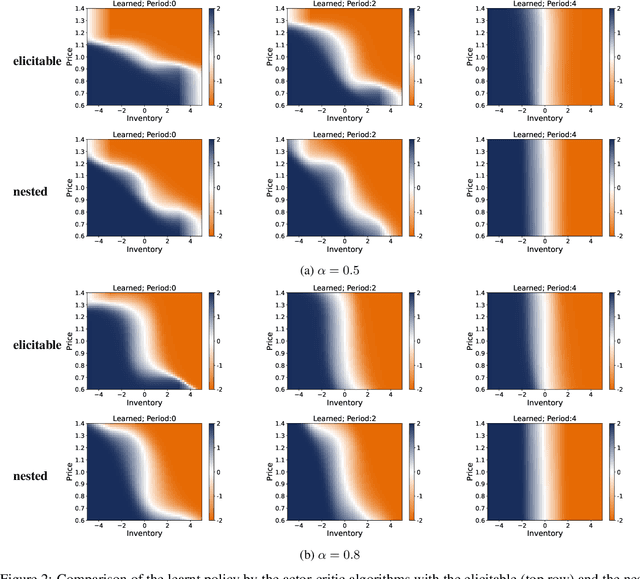
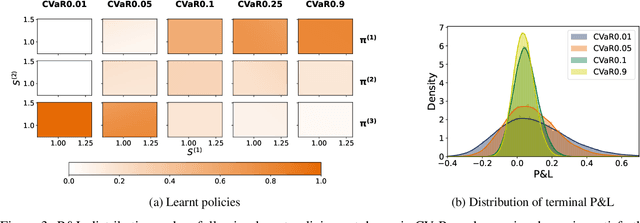
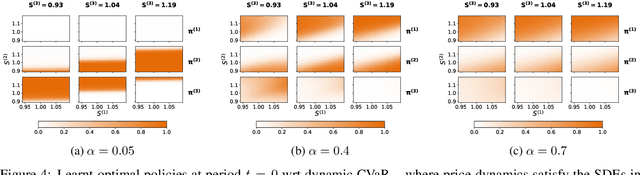
We propose a novel framework to solve risk-sensitive reinforcement learning (RL) problems where the agent optimises time-consistent dynamic spectral risk measures. Based on the notion of conditional elicitability, our methodology constructs (strictly consistent) scoring functions that are used as penalizers in the estimation procedure. Our contribution is threefold: we (i) devise an efficient approach to estimate a class of dynamic spectral risk measures with deep neural networks, (ii) prove that these dynamic spectral risk measures may be approximated to any arbitrary accuracy using deep neural networks, and (iii) develop a risk-sensitive actor-critic algorithm that uses full episodes and does not require any additional nested transitions. We compare our conceptually improved reinforcement learning algorithm with the nested simulation approach and illustrate its performance in two settings: statistical arbitrage and portfolio allocation on both simulated and real data.
Reinforcement Learning with Dynamic Convex Risk Measures
Dec 26, 2021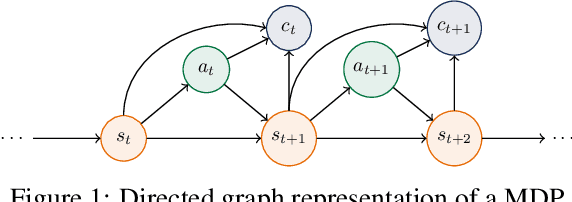
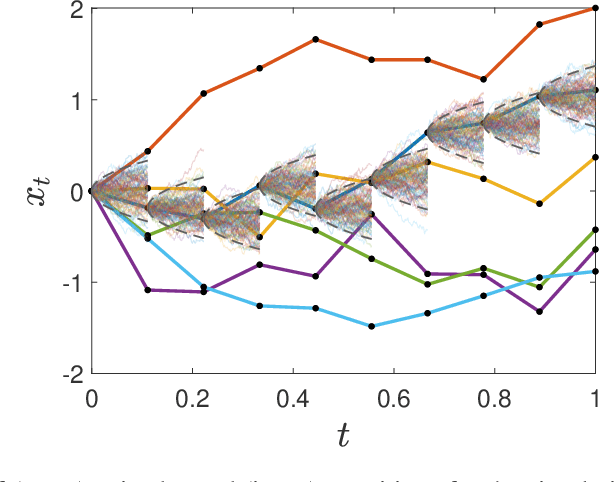
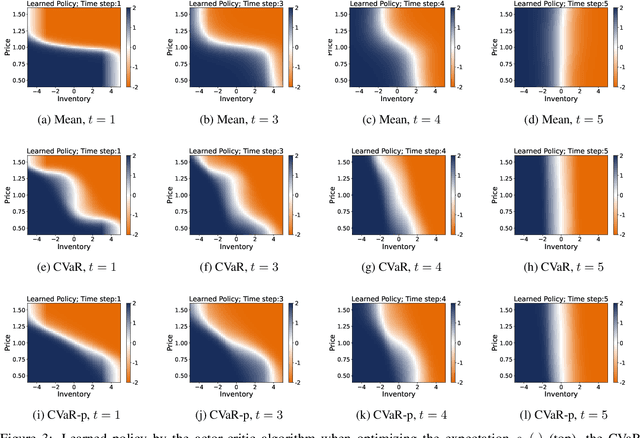
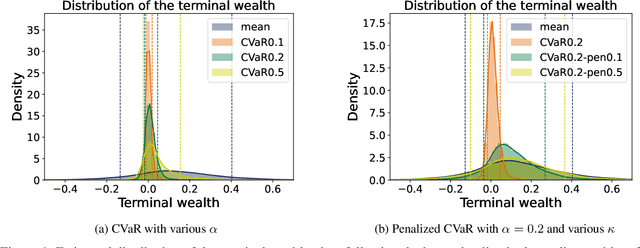
We develop an approach for solving time-consistent risk-sensitive stochastic optimization problems using model-free reinforcement learning (RL). Specifically, we assume agents assess the risk of a sequence of random variables using dynamic convex risk measures. We employ a time-consistent dynamic programming principle to determine the value of a particular policy, and develop policy gradient update rules. We further develop an actor-critic style algorithm using neural networks to optimize over policies. Finally, we demonstrate the performance and flexibility of our approach by applying it to optimization problems in statistical arbitrage trading and obstacle avoidance robot control.