 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Beyond Learning from Next Item: Sequential Recommendation via Personalized Interest Sustainability
Sep 14, 2022
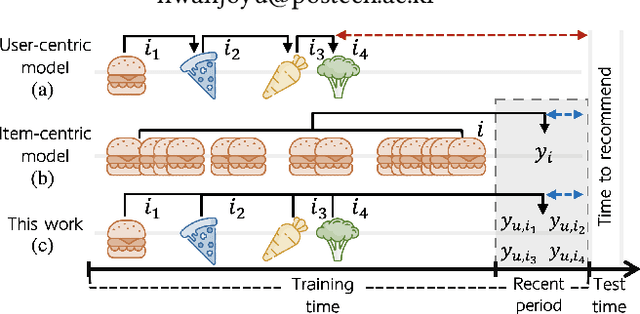
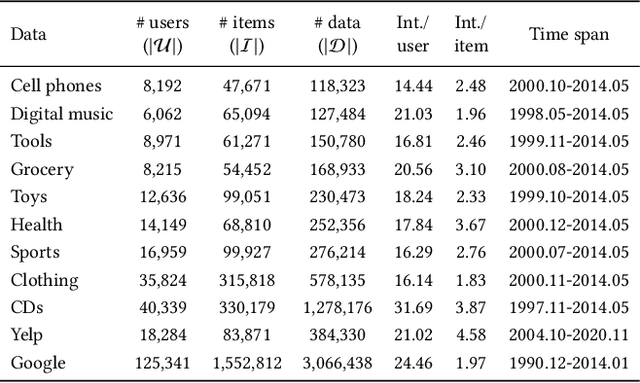
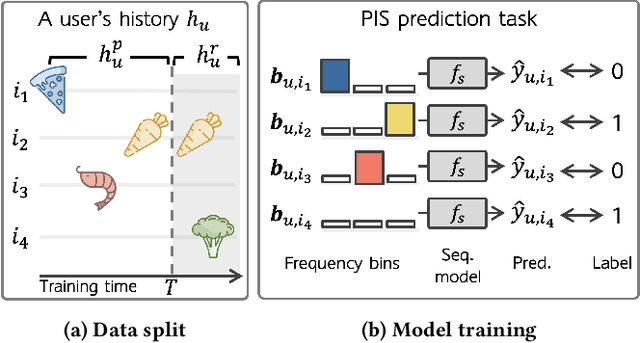
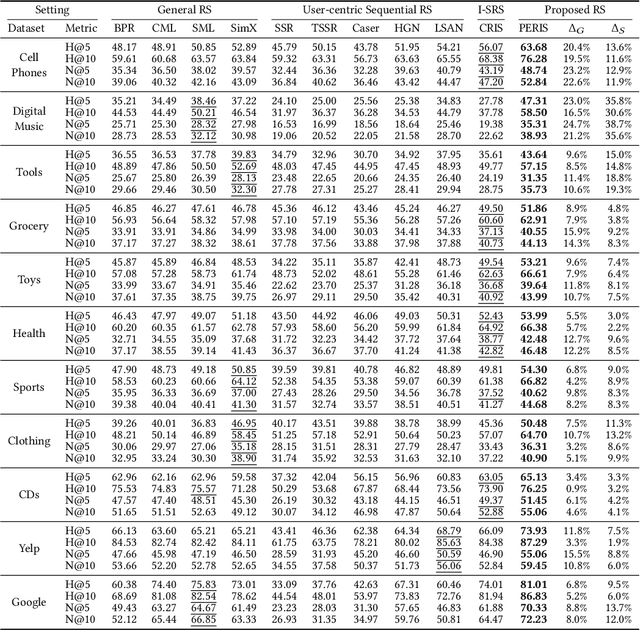
Sequential recommender systems have shown effective suggestions by capturing users' interest drift. There have been two groups of existing sequential models: user- and item-centric models. The user-centric models capture personalized interest drift based on each user's sequential consumption history, but do not explicitly consider whether users' interest in items sustains beyond the training time, i.e., interest sustainability. On the other hand, the item-centric models consider whether users' general interest sustains after the training time, but it is not personalized. In this work, we propose a recommender system taking advantages of the models in both categories. Our proposed model captures personalized interest sustainability, indicating whether each user's interest in items will sustain beyond the training time or not. We first formulate a task that requires to predict which items each user will consume in the recent period of the training time based on users' consumption history. We then propose simple yet effective schemes to augment users' sparse consumption history. Extensive experiments show that the proposed model outperforms 10 baseline models on 11 real-world datasets. The codes are available at https://github.com/dmhyun/PERIS.
Holistic Evaluation of Language Models
Nov 16, 2022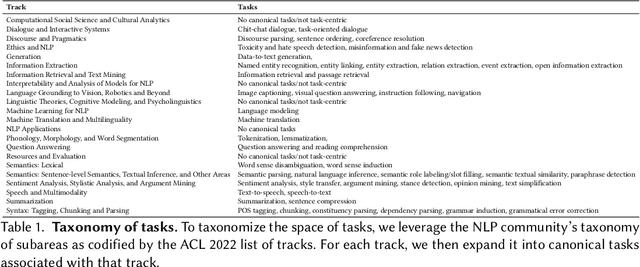



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
Definition and Quantification of Shock/Impact/Transient Vibrations
Nov 16, 2022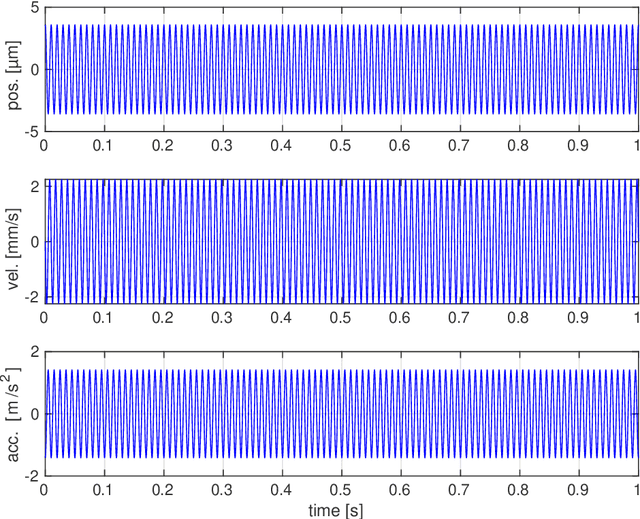
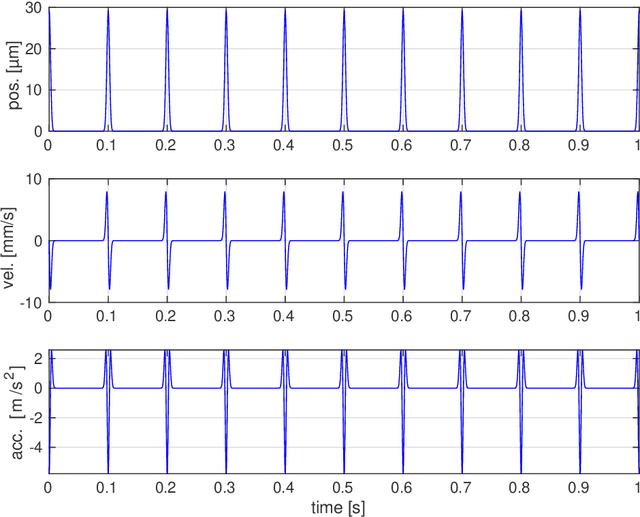
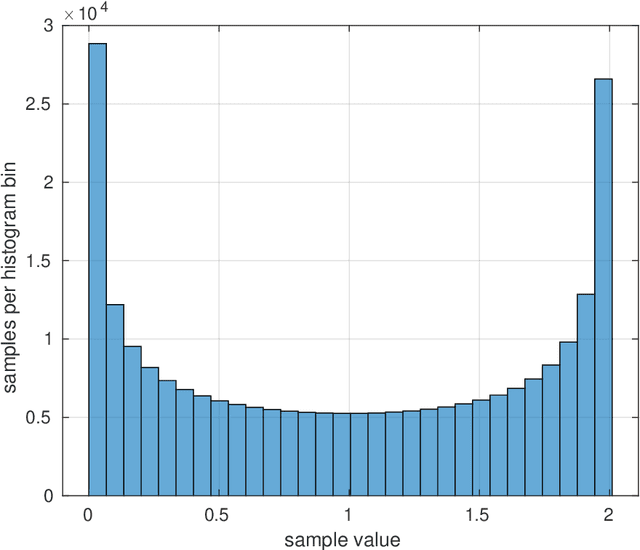
Vibration injury in the hand-arm system from hand-held machines is one of the most common occupational health injuries and causes severe and often chronic nerve and vascular injury to the operator. Machines emitting shock vibrations, e.g., impact wrenches have since long been identified as a special risk factor. In legislative and standard texts the terms shock, impact, and transient vibration are frequently used to underline the special risk associated with these kinds of vibrations. In spite of this, there is no mathematically stringent definition what a shock vibration is or how the amplitude of the shock is defined. This lack of definitions is the subject of this article. This document discusses a number of candidate definitions for a vibration shock index (VSI) that quantifies different vibration signals in terms of how localized they are in the time domain. The VSI is intended to be used to classify and compare different vibration sources. The VSI is independent of the vibration level, i.e., it is unchanged if the vibration signal is rescaled. The traditional root mean square method to determine the vibration level will not produce a value representative for the shocks occurring in a signal with high VSI. Thus, there is a need for a complementing quantification method for the localized signal parts. Possible definitions for such a vibration shock level (VSL) are suggested. A problem formulation is first stated together with a description of the approach used for designing the VSI and the VSL. After this, model signals are defined, which are used to discuss and evaluate the different candidate definitions. Then, a number of candidate definitions are discussed, leading up to a conclusion on which candidate definitions that are promising for experimental evaluation.
On the Dissipation of Ideal Hamiltonian Monte Carlo Sampler
Sep 15, 2022
We report on what seems to be an intriguing connection between variable integration time and partial velocity refreshment of Ideal Hamiltonian Monte Carlo samplers, both of which can be used for reducing the dissipative behavior of the dynamics. More concretely, we show that on quadratic potentials, efficiency can be improved through these means by a $\sqrt{\kappa}$ factor in Wasserstein-2 distance, compared to classical constant integration time, fully refreshed HMC.
Self-Adaptive Driving in Nonstationary Environments through Conjectural Online Lookahead Adaptation
Oct 06, 2022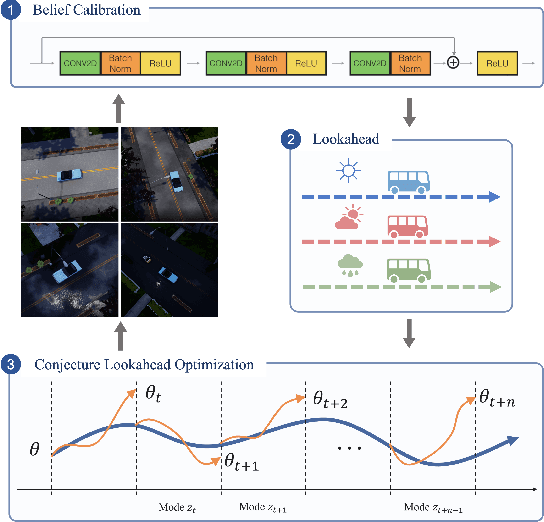
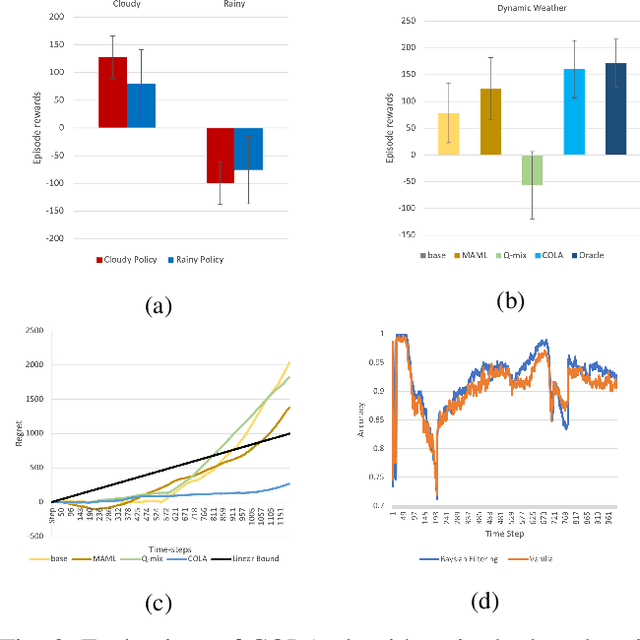
Powered by deep representation learning, reinforcement learning (RL) provides an end-to-end learning framework capable of solving self-driving (SD) tasks without manual designs. However, time-varying nonstationary environments cause proficient but specialized RL policies to fail at execution time. For example, an RL-based SD policy trained under sunny days does not generalize well to rainy weather. Even though meta learning enables the RL agent to adapt to new tasks/environments, its offline operation fails to equip the agent with online adaptation ability when facing nonstationary environments. This work proposes an online meta reinforcement learning algorithm based on the \emph{conjectural online lookahead adaptation} (COLA). COLA determines the online adaptation at every step by maximizing the agent's conjecture of the future performance in a lookahead horizon. Experimental results demonstrate that under dynamically changing weather and lighting conditions, the COLA-based self-adaptive driving outperforms the baseline policies in terms of online adaptability. A demo video, source code, and appendixes are available at {\tt https://github.com/Panshark/COLA}
Domain-Specific Word Embeddings with Structure Prediction
Oct 06, 2022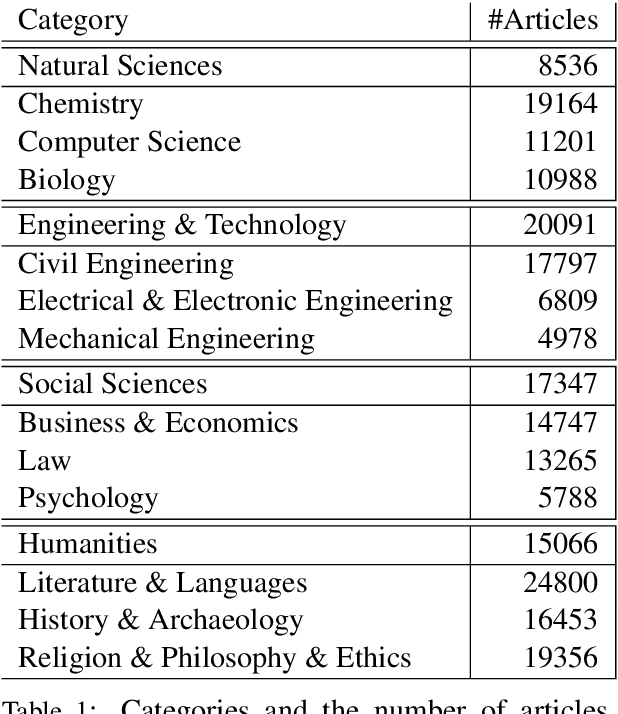
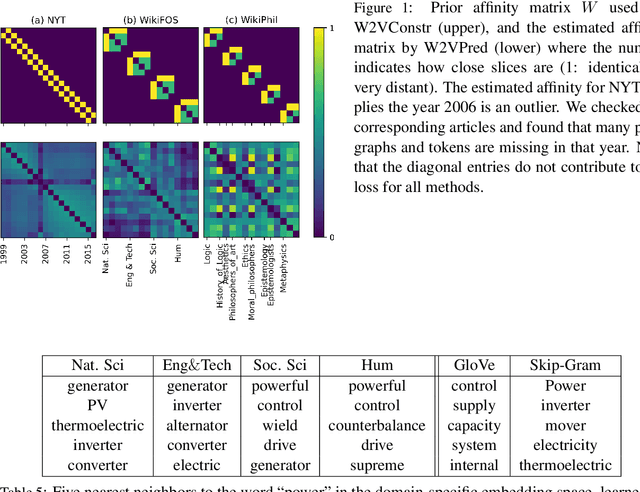
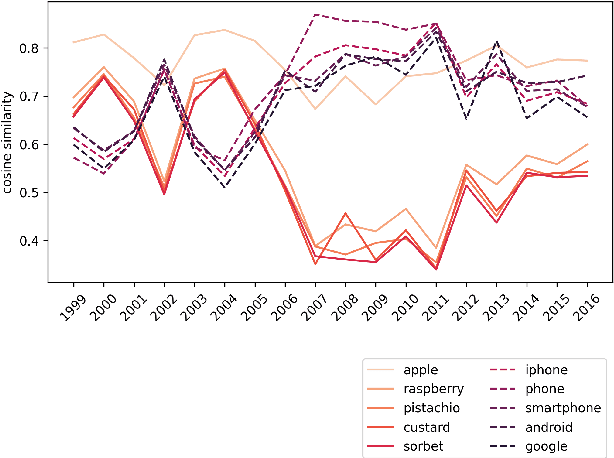
Complementary to finding good general word embeddings, an important question for representation learning is to find dynamic word embeddings, e.g., across time or domain. Current methods do not offer a way to use or predict information on structure between sub-corpora, time or domain and dynamic embeddings can only be compared after post-alignment. We propose novel word embedding methods that provide general word representations for the whole corpus, domain-specific representations for each sub-corpus, sub-corpus structure, and embedding alignment simultaneously. We present an empirical evaluation on New York Times articles and two English Wikipedia datasets with articles on science and philosophy. Our method, called Word2Vec with Structure Prediction (W2VPred), provides better performance than baselines in terms of the general analogy tests, domain-specific analogy tests, and multiple specific word embedding evaluations as well as structure prediction performance when no structure is given a priori. As a use case in the field of Digital Humanities we demonstrate how to raise novel research questions for high literature from the German Text Archive.
Estimation of Doubly-Dispersive Channels in Linearly Precoded Multicarrier Systems Using Smoothness Regularization
Oct 11, 2022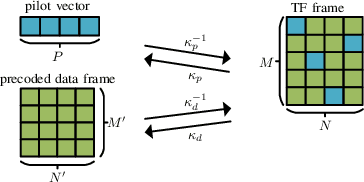
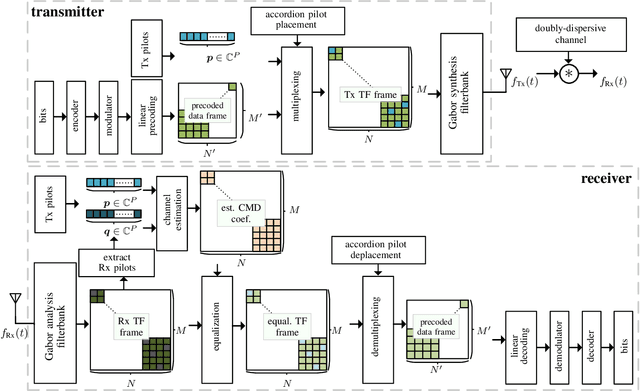
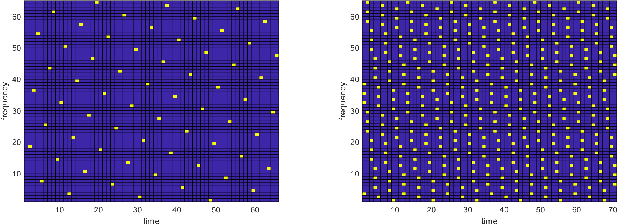
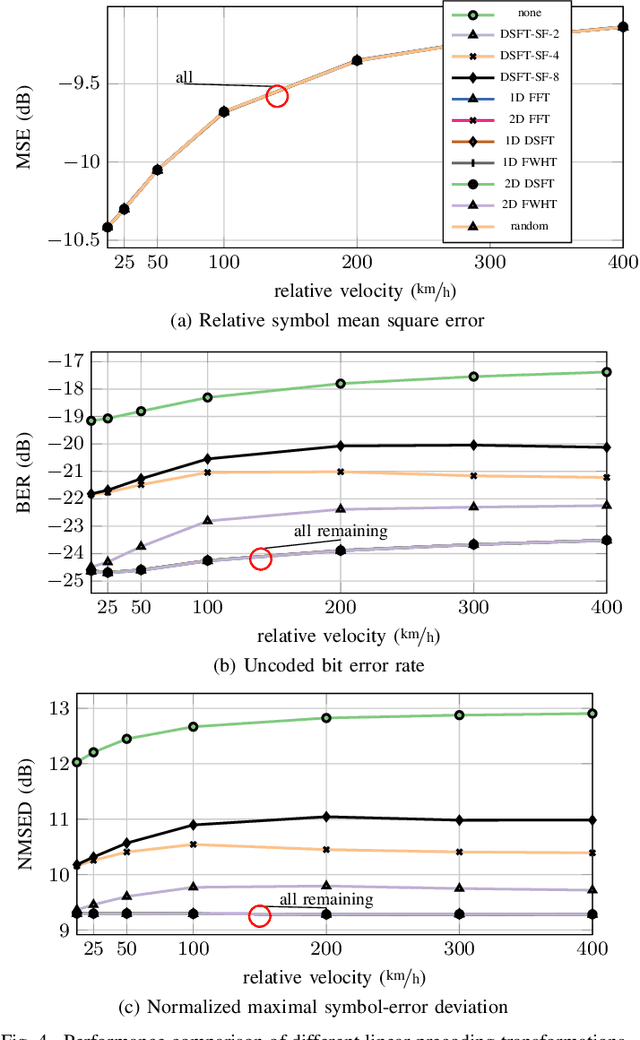
In this paper, we propose a novel channel estimation scheme for pulse-shaped multicarrier systems using smoothness regularization for ultra-reliable low-latency communication (URLLC). It can be applied to any multicarrier system with or without linear precoding to estimate challenging doubly-dispersive channels. A recently proposed modulation scheme using orthogonal precoding is orthogonal time-frequency and space modulation (OTFS). In OTFS, pilot and data symbols are placed in delay-Doppler (DD) domain and are jointly precoded to the time-frequency (TF) domain. On the one hand, such orthogonal precoding increases the achievable channel estimation accuracy and enables high TF diversity at the receiver. On the other hand, it introduces leakage effects which requires extensive leakage suppression when the piloting is jointly precoded with the data. To avoid this, we propose to precode the data symbols only, place pilot symbols without precoding into the TF domain, and estimate the channel coefficients by interpolating smooth functions from the pilot samples. Furthermore, we present a piloting scheme enabling a smooth control of the number and position of the pilot symbols. Our numerical results suggest that the proposed scheme provides accurate channel estimation with reduced signaling overhead compared to standard estimators using Wiener filtering in the discrete DD domain.
Learning to Rank Graph-based Application Objects on Heterogeneous Memories
Nov 04, 2022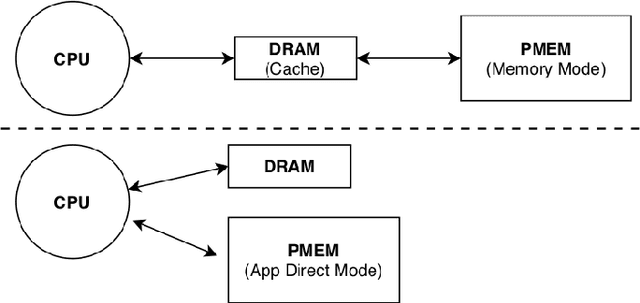
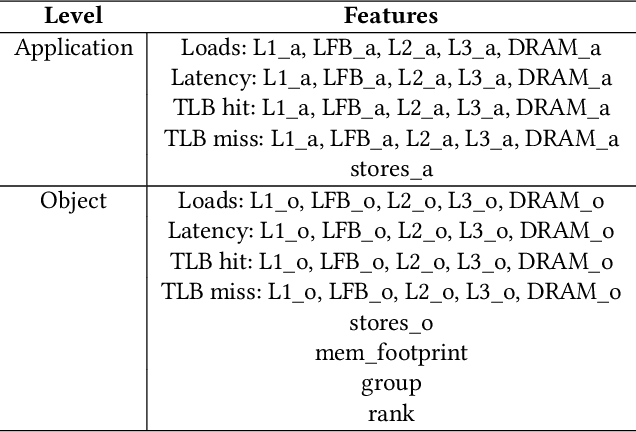
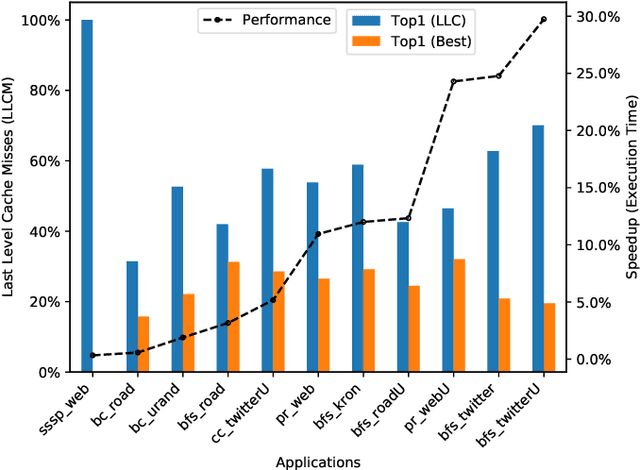
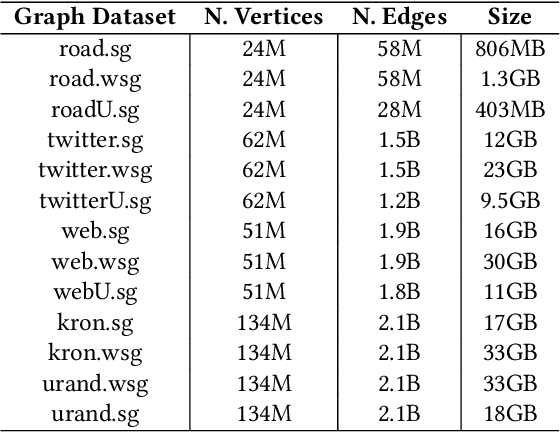
Persistent Memory (PMEM), also known as Non-Volatile Memory (NVM), can deliver higher density and lower cost per bit when compared with DRAM. Its main drawback is that it is typically slower than DRAM. On the other hand, DRAM has scalability problems due to its cost and energy consumption. Soon, PMEM will likely coexist with DRAM in computer systems but the biggest challenge is to know which data to allocate on each type of memory. This paper describes a methodology for identifying and characterizing application objects that have the most influence on the application's performance using Intel Optane DC Persistent Memory. In the first part of our work, we built a tool that automates the profiling and analysis of application objects. In the second part, we build a machine learning model to predict the most critical object within large-scale graph-based applications. Our results show that using isolated features does not bring the same benefit compared to using a carefully chosen set of features. By performing data placement using our predictive model, we can reduce the execution time degradation by 12\% (average) and 30\% (max) when compared to the baseline's approach based on LLC misses indicator.
The Tensor Data Platform: Towards an AI-centric Database System
Nov 04, 2022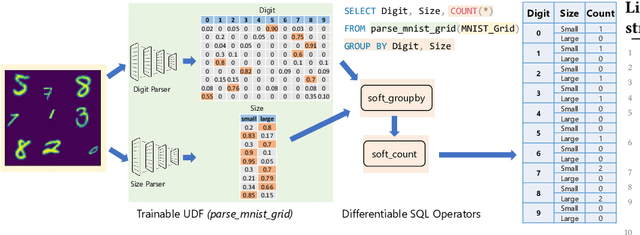
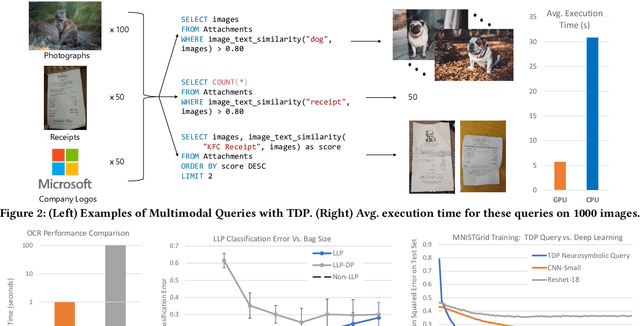
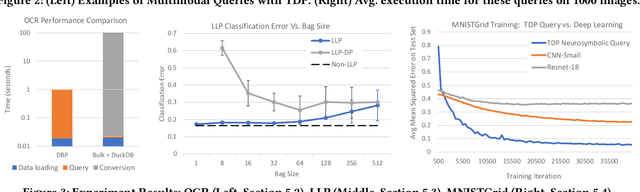
Database engines have historically absorbed many of the innovations in data processing, adding features to process graph data, XML, object oriented, and text among many others. In this paper, we make the case that it is time to do the same for AI -- but with a twist! While existing approaches have tried to achieve this by integrating databases with external ML tools, in this paper we claim that achieving a truly AI-centric database requires moving the DBMS engine, at its core, from a relational to a tensor abstraction. This allows us to: (1) support multi-modal data processing such as images, videos, audio, text as well as relational; (2) leverage the wellspring of innovation in HW and runtimes for tensor computation; and (3) exploit automatic differentiation to enable a novel class of "trainable" queries that can learn to perform a task. To support the above scenarios, we introduce TDP: a system that builds upon our prior work mapping relational queries to tensors. Thanks to a tighter integration with the tensor runtime, TDP is able to provide a broader coverage of new emerging scenarios requiring access to multi-modal data and automatic differentiation.
On the Achievable SINR in MU-MIMO Systems Operating in Time-Varying Rayleigh Fading
Mar 24, 2022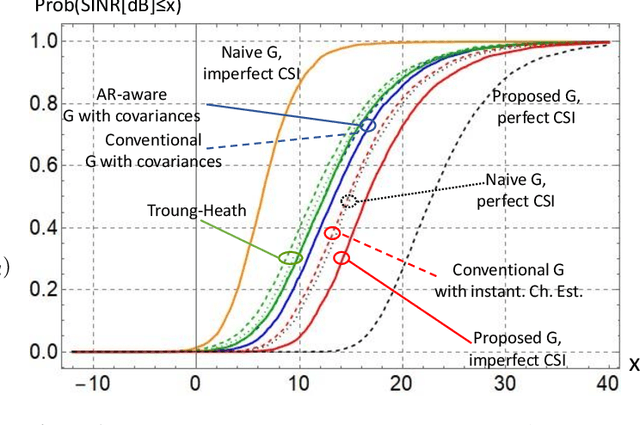
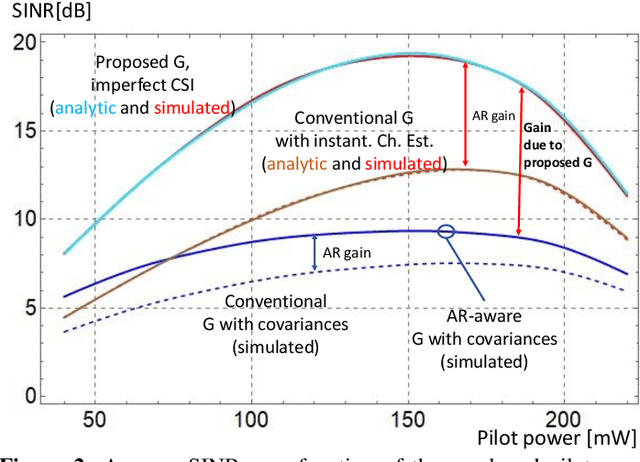
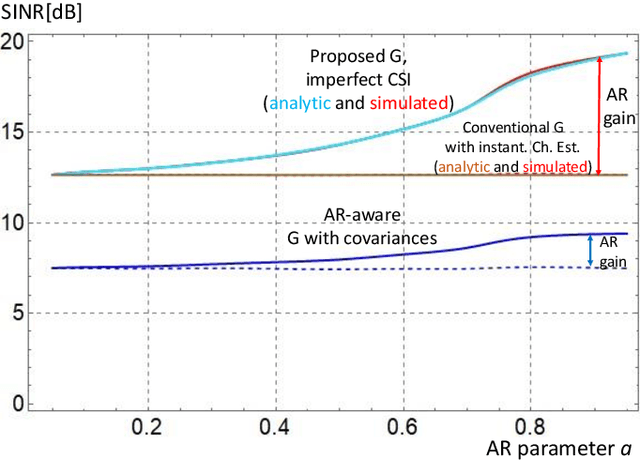
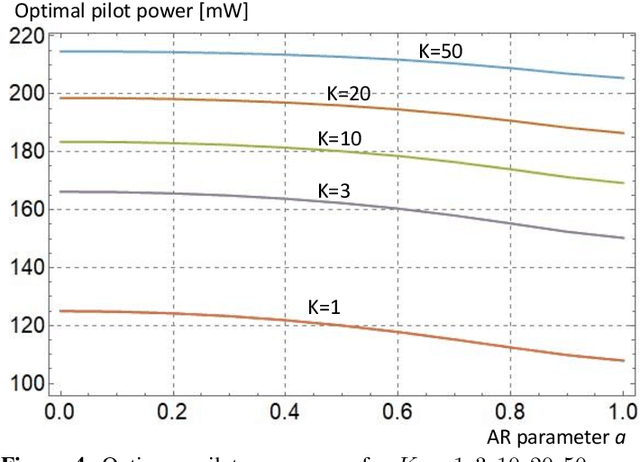
Minimizing the symbol error in the uplink of multi-user multiple input multiple output systems is important, because the symbol error affects the achieved signal-to-interference-plus-noise ratio (SINR) and thereby the spectral efficiency of the system. Despite the vast literature available on minimum mean squared error (MMSE) receivers, previously proposed receivers for block fading channels do not minimize the symbol error in time-varying Rayleigh fading channels. Specifically, we show that the true MMSE receiver structure does not only depend on the statistics of the CSI error, but also on the autocorrelation coefficient of the time-variant channel. It turns out that calculating the average SINR when using the proposed receiver is highly non-trivial. In this paper, we employ a random matrix theoretical approach, which allows us to derive a quasi-closed form for the average SINR, which allows to obtain analytical exact results that give valuable insights into how the SINR depends on the number of antennas, employed pilot and data power and the covariance of the time-varying channel. We benchmark the performance of the proposed receiver against recently proposed receivers and find that the proposed MMSE receiver achieves higher SINR than the previously proposed ones, and this benefit increases with increasing autoregressive coefficient.
* 15 pages, 9 figures, 4 tables