 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Agent Optimization
May 07, 2026We introduce Recursive Agent Optimization (RAO), a reinforcement learning approach for training recursive agents: agents that can spawn and delegate sub-tasks to new instantiations of themselves recursively. Recursive agents implement an inference-time scaling algorithm that naturally allows agents to scale to longer contexts and generalize to more difficult problems via divide-and-conquer. RAO provides a method to train models to best take advantage of such recursive inference, teaching agents when and how to delegate and communicate. We find that recursive agents trained in this way enjoy better training efficiency, can scale to tasks that go beyond the model's context window, generalize to tasks much harder than the ones the agent was trained on, and can enjoy reduced wall-clock time compared to single-agent systems.
CodeScout: An Effective Recipe for Reinforcement Learning of Code Search Agents
Mar 18, 2026A prerequisite for coding agents to perform tasks on large repositories is code localization - the identification of relevant files, classes, and functions to work on. While repository-level code localization has been performed using embedding-based retrieval approaches such as vector search, recent work has focused on developing agents to localize relevant code either as a standalone precursor to or interleaved with performing actual work. Most prior methods on agentic code search equip the agent with complex, specialized tools, such as repository graphs derived from static analysis. In this paper, we demonstrate that, with an effective reinforcement learning recipe, a coding agent equipped with nothing more than a standard Unix terminal can be trained to achieve strong results. Our experiments on three benchmarks (SWE-Bench Verified, Pro, and Lite) reveal that our models consistently achieve superior or competitive performance over 2-18x larger base and post-trained LLMs and sometimes approach performance provided by closed models like Claude Sonnet, even when using specialized scaffolds. Our work particularly focuses on techniques for re-purposing existing coding agent environments for code search, reward design, and RL optimization. We release the resulting model family, CodeScout, along with all our code and data for the community to build upon.
Training Versatile Coding Agents in Synthetic Environments
Dec 13, 2025Prior works on training software engineering agents have explored utilizing existing resources such as issues on GitHub repositories to construct software engineering tasks and corresponding test suites. These approaches face two key limitations: (1) their reliance on pre-existing GitHub repositories offers limited flexibility, and (2) their primary focus on issue resolution tasks restricts their applicability to the much wider variety of tasks a software engineer must handle. To overcome these challenges, we introduce SWE-Playground, a novel pipeline for generating environments and trajectories which supports the training of versatile coding agents. Unlike prior efforts, SWE-Playground synthetically generates projects and tasks from scratch with strong language models and agents, eliminating reliance on external data sources. This allows us to tackle a much wider variety of coding tasks, such as reproducing issues by generating unit tests and implementing libraries from scratch. We demonstrate the effectiveness of this approach on three distinct benchmarks, and results indicate that SWE-Playground produces trajectories with dense training signal, enabling agents to reach comparable performance with significantly fewer trajectories than previous works.
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Apr 09, 2025



To survive and thrive in complex environments, humans have evolved sophisticated self-improvement mechanisms through environment exploration, hierarchical abstraction of experiences into reuseable skills, and collaborative construction of an ever-growing skill repertoire. Despite recent advancements, autonomous web agents still lack crucial self-improvement capabilities, struggling with procedural knowledge abstraction, refining skills, and skill composition. In this work, we introduce SkillWeaver, a skill-centric framework enabling agents to self-improve by autonomously synthesizing reusable skills as APIs. Given a new website, the agent autonomously discovers skills, executes them for practice, and distills practice experiences into robust APIs. Iterative exploration continually expands a library of lightweight, plug-and-play APIs, significantly enhancing the agent's capabilities. Experiments on WebArena and real-world websites demonstrate the efficacy of SkillWeaver, achieving relative success rate improvements of 31.8% and 39.8%, respectively. Additionally, APIs synthesized by strong agents substantially enhance weaker agents through transferable skills, yielding improvements of up to 54.3% on WebArena. These results demonstrate the effectiveness of honing diverse website interactions into APIs, which can be seamlessly shared among various web agents.
Inducing Programmatic Skills for Agentic Tasks
Apr 09, 2025



To succeed in common digital tasks such as web navigation, agents must carry out a variety of specialized tasks such as searching for products or planning a travel route. To tackle these tasks, agents can bootstrap themselves by learning task-specific skills online through interaction with the web environment. In this work, we demonstrate that programs are an effective representation for skills. We propose agent skill induction (ASI), which allows agents to adapt themselves by inducing, verifying, and utilizing program-based skills on the fly. We start with an evaluation on the WebArena agent benchmark and show that ASI outperforms the static baseline agent and its text-skill counterpart by 23.5% and 11.3% in success rate, mainly thanks to the programmatic verification guarantee during the induction phase. ASI also improves efficiency by reducing 10.7-15.3% of the steps over baselines, by composing primitive actions (e.g., click) into higher-level skills (e.g., search product). We then highlight the efficacy of ASI in remaining efficient and accurate under scaled-up web activities. Finally, we examine the generalizability of induced skills when transferring between websites, and find that ASI can effectively reuse common skills, while also updating incompatible skills to versatile website changes.
Natural Language Commanding via Program Synthesis
Jun 06, 2023



We present Semantic Interpreter, a natural language-friendly AI system for productivity software such as Microsoft Office that leverages large language models (LLMs) to execute user intent across application features. While LLMs are excellent at understanding user intent expressed as natural language, they are not sufficient for fulfilling application-specific user intent that requires more than text-to-text transformations. We therefore introduce the Office Domain Specific Language (ODSL), a concise, high-level language specialized for performing actions in and interacting with entities in Office applications. Semantic Interpreter leverages an Analysis-Retrieval prompt construction method with LLMs for program synthesis, translating natural language user utterances to ODSL programs that can be transpiled to application APIs and then executed. We focus our discussion primarily on a research exploration for Microsoft PowerPoint.
SLATE: A Sequence Labeling Approach for Task Extraction from Free-form Inked Content
Nov 17, 2022



We present SLATE, a sequence labeling approach for extracting tasks from free-form content such as digitally handwritten (or "inked") notes on a virtual whiteboard. Our approach allows us to create a single, low-latency model to simultaneously perform sentence segmentation and classification of these sentences into task/non-task sentences. SLATE greatly outperforms a baseline two-model (sentence segmentation followed by classification model) approach, achieving a task F1 score of 84.4%, a sentence segmentation (boundary similarity) score of 88.4% and three times lower latency compared to the baseline. Furthermore, we provide insights into tackling challenges of performing NLP on the inking domain. We release both our code and dataset for this novel task.
The Tensor Data Platform: Towards an AI-centric Database System
Nov 04, 2022


Database engines have historically absorbed many of the innovations in data processing, adding features to process graph data, XML, object oriented, and text among many others. In this paper, we make the case that it is time to do the same for AI -- but with a twist! While existing approaches have tried to achieve this by integrating databases with external ML tools, in this paper we claim that achieving a truly AI-centric database requires moving the DBMS engine, at its core, from a relational to a tensor abstraction. This allows us to: (1) support multi-modal data processing such as images, videos, audio, text as well as relational; (2) leverage the wellspring of innovation in HW and runtimes for tensor computation; and (3) exploit automatic differentiation to enable a novel class of "trainable" queries that can learn to perform a task. To support the above scenarios, we introduce TDP: a system that builds upon our prior work mapping relational queries to tensors. Thanks to a tighter integration with the tensor runtime, TDP is able to provide a broader coverage of new emerging scenarios requiring access to multi-modal data and automatic differentiation.
Adversarial Perturbations Fool Deepfake Detectors
Mar 24, 2020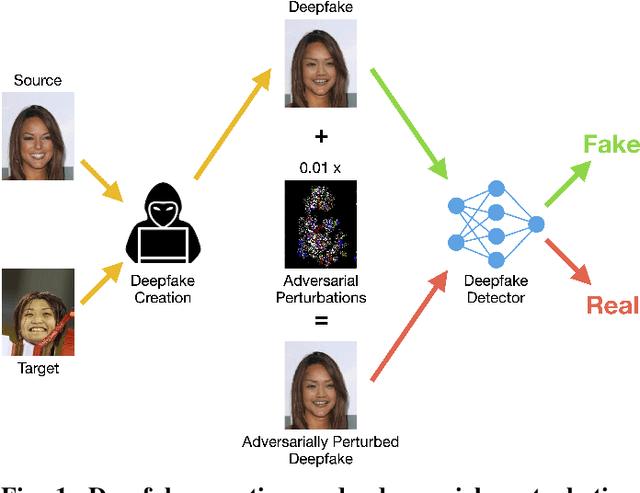

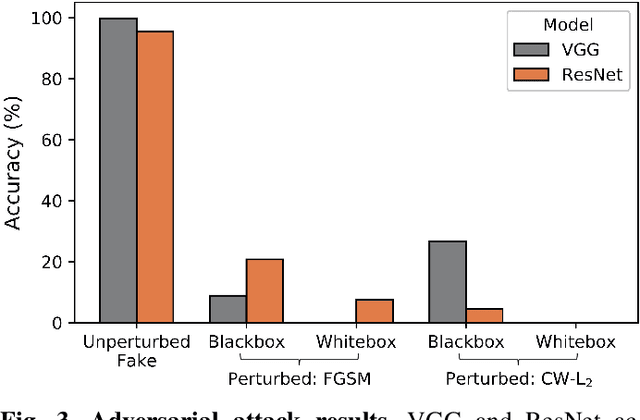
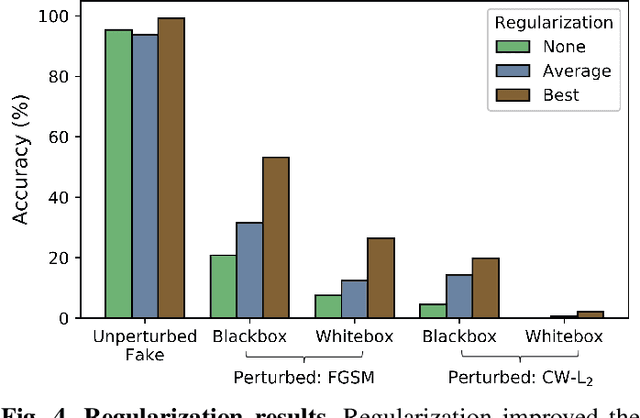
This work uses adversarial perturbations to enhance deepfake images and fool common deepfake detectors. We created adversarial perturbations using the Fast Gradient Sign Method and the Carlini and Wagner L2 norm attack in both blackbox and whitebox settings. Detectors achieved over 95% accuracy on unperturbed deepfakes, but less than 27% accuracy on perturbed deepfakes. We also explore two improvements to deepfake detectors: (i) Lipschitz regularization, and (ii) Deep Image Prior (DIP). Lipschitz regularization constrains the gradient of the detector with respect to the input in order to increase robustness to input perturbations. The DIP defense removes perturbations using generative convolutional neural networks in an unsupervised manner. Regularization improved the detection of perturbed deepfakes on average, including a 10% accuracy boost in the blackbox case. The DIP defense achieved 95% accuracy on perturbed deepfakes that fooled the original detector, while retaining 98% accuracy in other cases on a 100 image subsample.