 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DBA-Fusion: Tightly Integrating Deep Dense Visual Bundle Adjustment with Multiple Sensors for Large-Scale Localization and Mapping
Mar 20, 2024
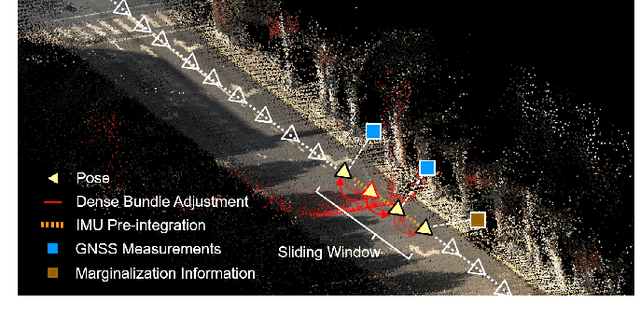


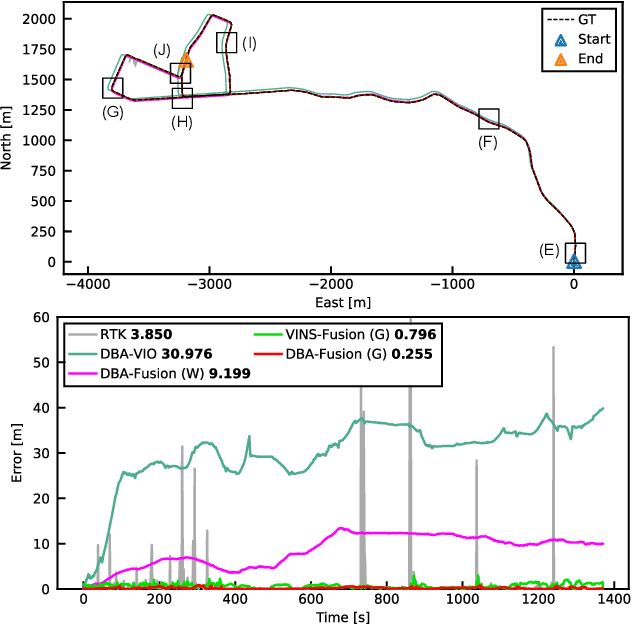
Visual simultaneous localization and mapping (VSLAM) has broad applications, with state-of-the-art methods leveraging deep neural networks for better robustness and applicability. However, there is a lack of research in fusing these learning-based methods with multi-sensor information, which could be indispensable to push related applications to large-scale and complex scenarios. In this paper, we tightly integrate the trainable deep dense bundle adjustment (DBA) with multi-sensor information through a factor graph. In the framework, recurrent optical flow and DBA are performed among sequential images. The Hessian information derived from DBA is fed into a generic factor graph for multi-sensor fusion, which employs a sliding window and supports probabilistic marginalization. A pipeline for visual-inertial integration is firstly developed, which provides the minimum ability of metric-scale localization and mapping. Furthermore, other sensors (e.g., global navigation satellite system) are integrated for driftless and geo-referencing functionality. Extensive tests are conducted on both public datasets and self-collected datasets. The results validate the superior localization performance of our approach, which enables real-time dense mapping in large-scale environments. The code has been made open-source (https://github.com/GREAT-WHU/DBA-Fusion).
Kernel Multigrid: Accelerate Back-fitting via Sparse Gaussian Process Regression
Mar 20, 2024
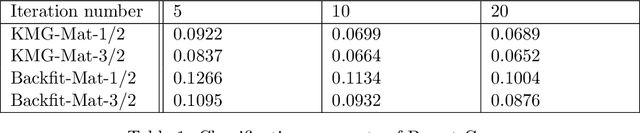
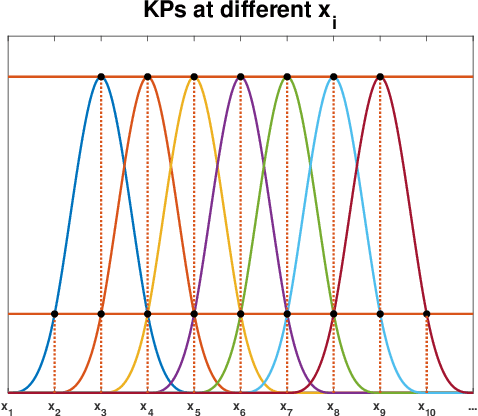
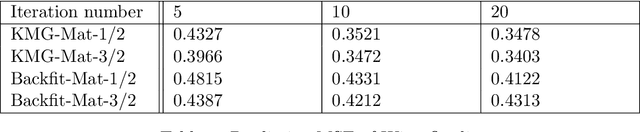
Additive Gaussian Processes (GPs) are popular approaches for nonparametric feature selection. The common training method for these models is Bayesian Back-fitting. However, the convergence rate of Back-fitting in training additive GPs is still an open problem. By utilizing a technique called Kernel Packets (KP), we prove that the convergence rate of Back-fitting is no faster than $(1-\mathcal{O}(\frac{1}{n}))^t$, where $n$ and $t$ denote the data size and the iteration number, respectively. Consequently, Back-fitting requires a minimum of $\mathcal{O}(n\log n)$ iterations to achieve convergence. Based on KPs, we further propose an algorithm called Kernel Multigrid (KMG). This algorithm enhances Back-fitting by incorporating a sparse Gaussian Process Regression (GPR) to process the residuals subsequent to each Back-fitting iteration. It is applicable to additive GPs with both structured and scattered data. Theoretically, we prove that KMG reduces the required iterations to $\mathcal{O}(\log n)$ while preserving the time and space complexities at $\mathcal{O}(n\log n)$ and $\mathcal{O}(n)$ per iteration, respectively. Numerically, by employing a sparse GPR with merely 10 inducing points, KMG can produce accurate approximations of high-dimensional targets within 5 iterations.
DVMNet: Computing Relative Pose for Unseen Objects Beyond Hypotheses
Mar 20, 2024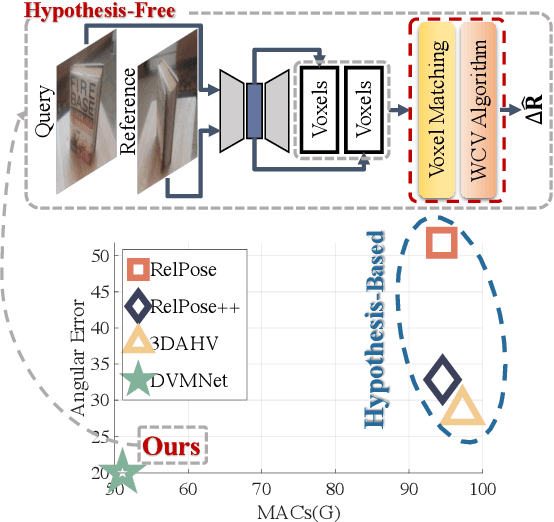
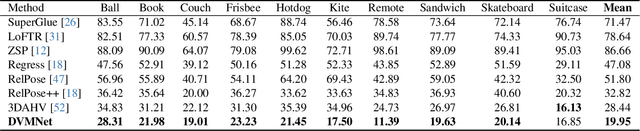
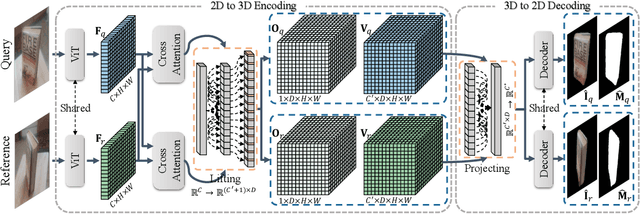
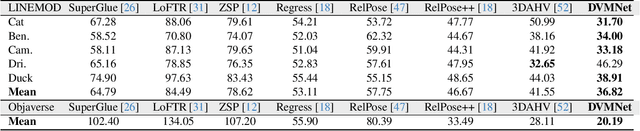
Determining the relative pose of an object between two images is pivotal to the success of generalizable object pose estimation. Existing approaches typically approximate the continuous pose representation with a large number of discrete pose hypotheses, which incurs a computationally expensive process of scoring each hypothesis at test time. By contrast, we present a Deep Voxel Matching Network (DVMNet) that eliminates the need for pose hypotheses and computes the relative object pose in a single pass. To this end, we map the two input RGB images, reference and query, to their respective voxelized 3D representations. We then pass the resulting voxels through a pose estimation module, where the voxels are aligned and the pose is computed in an end-to-end fashion by solving a least-squares problem. To enhance robustness, we introduce a weighted closest voxel algorithm capable of mitigating the impact of noisy voxels. We conduct extensive experiments on the CO3D, LINEMOD, and Objaverse datasets, demonstrating that our method delivers more accurate relative pose estimates for novel objects at a lower computational cost compared to state-of-the-art methods. Our code is released at: https://github.com/sailor-z/DVMNet/.
FACT: Fast and Active Coordinate Initialization for Vision-based Drone Swarms
Mar 20, 2024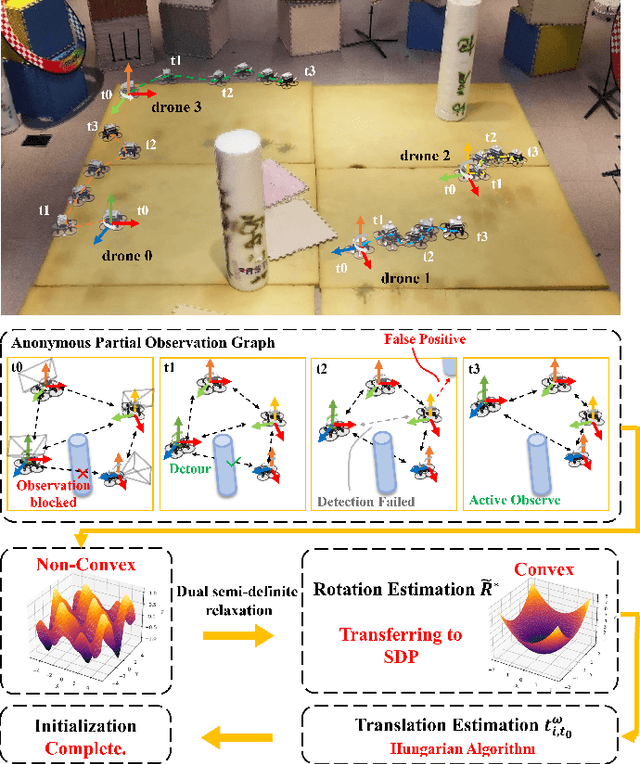
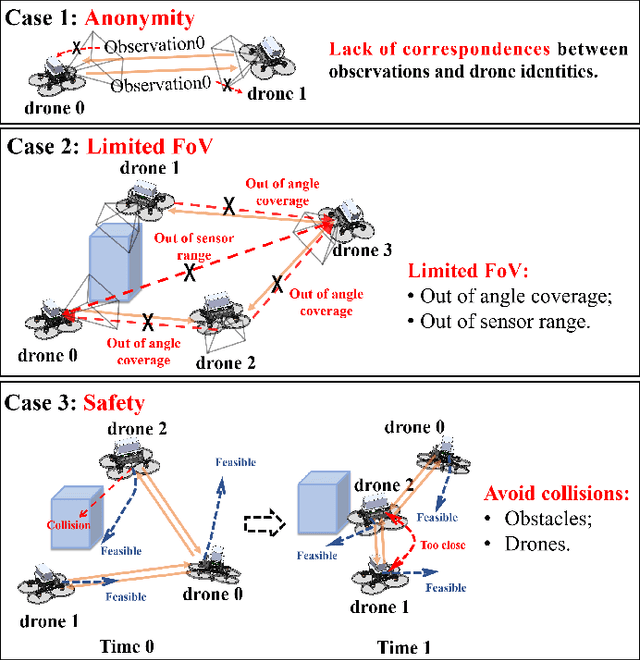
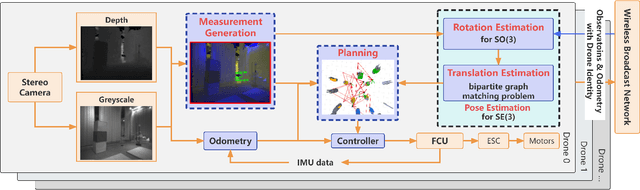

Swarm robots have sparked remarkable developments across a range of fields. While it is necessary for various applications in swarm robots, a fast and robust coordinate initialization in vision-based drone swarms remains elusive. To this end, our paper proposes a complete system to recover a swarm's initial relative pose on platforms with size, weight, and power (SWaP) constraints. To overcome limited coverage of field-of-view (FoV), the drones rotate in place to obtain observations. To tackle the anonymous measurements, we formulate a non-convex rotation estimation problem and transform it into a semi-definite programming (SDP) problem, which can steadily obtain global optimal values. Then we utilize the Hungarian algorithm to recover relative translation and correspondences between observations and drone identities. To safely acquire complete observations, we actively search for positions and generate feasible trajectories to avoid collisions. To validate the practicability of our system, we conduct experiments on a vision-based drone swarm with only stereo cameras and inertial measurement units (IMUs) as sensors. The results demonstrate that the system can robustly get accurate relative poses in real time with limited onboard computation resources. The source code is released.
Accurately Predicting Probabilities of Safety-Critical Rare Events for Intelligent Systems
Mar 20, 2024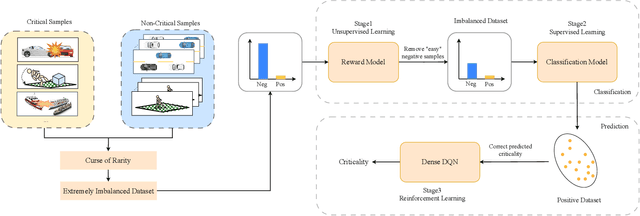
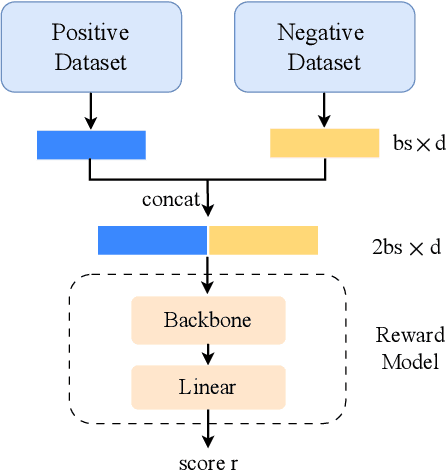
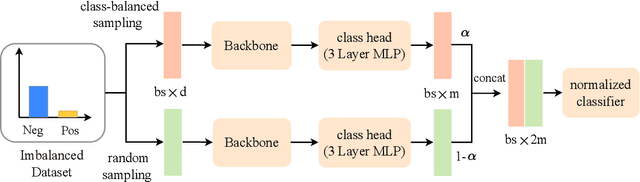
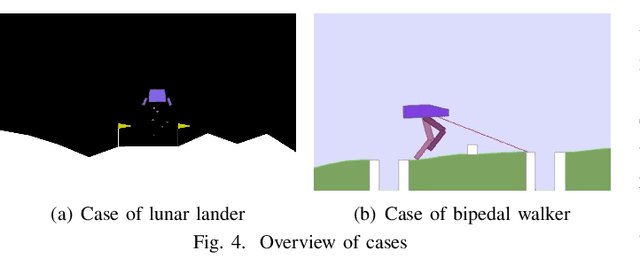
Intelligent systems are increasingly integral to our daily lives, yet rare safety-critical events present significant latent threats to their practical deployment. Addressing this challenge hinges on accurately predicting the probability of safety-critical events occurring within a given time step from the current state, a metric we define as 'criticality'. The complexity of predicting criticality arises from the extreme data imbalance caused by rare events in high dimensional variables associated with the rare events, a challenge we refer to as the curse of rarity. Existing methods tend to be either overly conservative or prone to overlooking safety-critical events, thus struggling to achieve both high precision and recall rates, which severely limits their applicability. This study endeavors to develop a criticality prediction model that excels in both precision and recall rates for evaluating the criticality of safety-critical autonomous systems. We propose a multi-stage learning framework designed to progressively densify the dataset, mitigating the curse of rarity across stages. To validate our approach, we evaluate it in two cases: lunar lander and bipedal walker scenarios. The results demonstrate that our method surpasses traditional approaches, providing a more accurate and dependable assessment of criticality in intelligent systems.
Centroidal State Estimation based on the Koopman Embedding for Dynamic Legged Locomotion
Mar 20, 2024
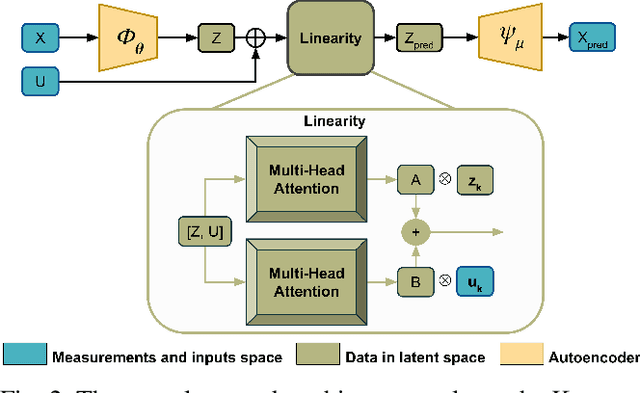
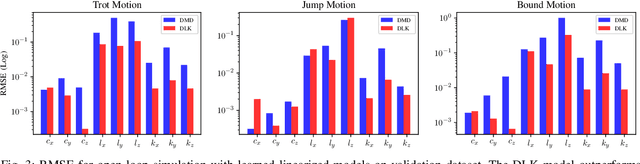
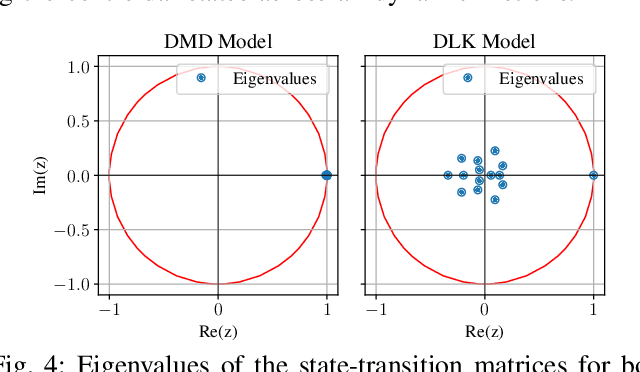
In this paper, we introduce a novel approach to centroidal state estimation, which plays a crucial role in predictive model-based control strategies for dynamic legged locomotion. Our approach uses the Koopman operator theory to transform the robot's complex nonlinear dynamics into a linear system, by employing dynamic mode decomposition and deep learning for model construction. We evaluate both models on their linearization accuracy and capability to capture both fast and slow dynamic system responses. We then select the most suitable model for estimation purposes, and integrate it within a moving horizon estimator. This estimator is formulated as a convex quadratic program, to facilitate robust, real-time centroidal state estimation. Through extensive simulation experiments on a quadruped robot executing various dynamic gaits, our data-driven framework outperforms conventional filtering techniques based on nonlinear dynamics. Our estimator addresses challenges posed by force/torque measurement noise in highly dynamic motions and accurately recovers the centroidal states, demonstrating the adaptability and effectiveness of the Koopman-based linear representation for complex locomotive behaviors. Importantly, our model based on dynamic mode decomposition, trained with two locomotion patterns (trot and jump), successfully estimates the centroidal states for a different motion (bound) without retraining.
RL in Markov Games with Independent Function Approximation: Improved Sample Complexity Bound under the Local Access Model
Mar 20, 2024
Efficiently learning equilibria with large state and action spaces in general-sum Markov games while overcoming the curse of multi-agency is a challenging problem. Recent works have attempted to solve this problem by employing independent linear function classes to approximate the marginal $Q$-value for each agent. However, existing sample complexity bounds under such a framework have a suboptimal dependency on the desired accuracy $\varepsilon$ or the action space. In this work, we introduce a new algorithm, Lin-Confident-FTRL, for learning coarse correlated equilibria (CCE) with local access to the simulator, i.e., one can interact with the underlying environment on the visited states. Up to a logarithmic dependence on the size of the state space, Lin-Confident-FTRL learns $\epsilon$-CCE with a provable optimal accuracy bound $O(\epsilon^{-2})$ and gets rids of the linear dependency on the action space, while scaling polynomially with relevant problem parameters (such as the number of agents and time horizon). Moreover, our analysis of Linear-Confident-FTRL generalizes the virtual policy iteration technique in the single-agent local planning literature, which yields a new computationally efficient algorithm with a tighter sample complexity bound when assuming random access to the simulator.
Relational Representation Learning Network for Cross-Spectral Image Patch Matching
Mar 18, 2024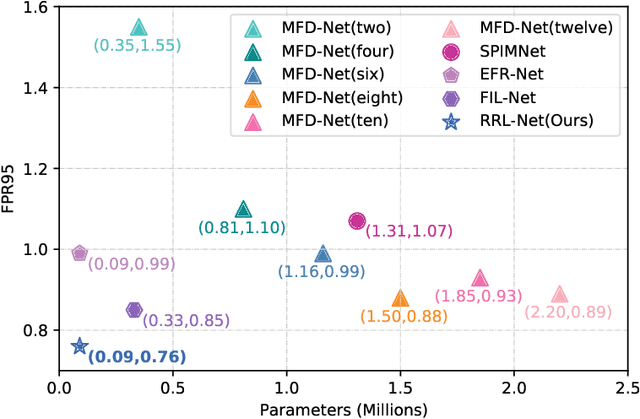
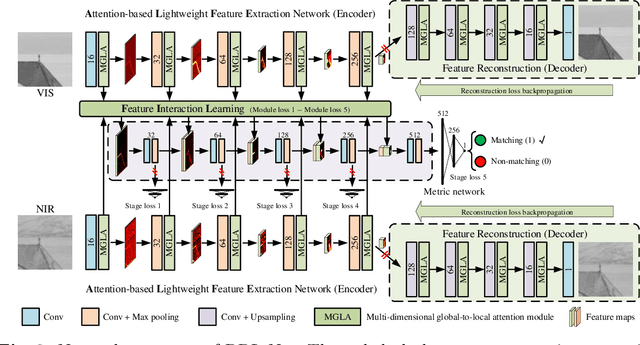
Recently, feature relation learning has drawn widespread attention in cross-spectral image patch matching. However, existing related research focuses on extracting diverse relations between image patch features and ignores sufficient intrinsic feature representations of individual image patches. Therefore, an innovative relational representation learning idea is proposed for the first time, which simultaneously focuses on sufficiently mining the intrinsic features of individual image patches and the relations between image patch features. Based on this, we construct a lightweight Relational Representation Learning Network (RRL-Net). Specifically, we innovatively construct an autoencoder to fully characterize the individual intrinsic features, and introduce a Feature Interaction Learning (FIL) module to extract deep-level feature relations. To further fully mine individual intrinsic features, a lightweight Multi-dimensional Global-to-Local Attention (MGLA) module is constructed to enhance the global feature extraction of individual image patches and capture local dependencies within global features. By combining the MGLA module, we further explore the feature extraction network and construct an Attention-based Lightweight Feature Extraction (ALFE) network. In addition, we propose a Multi-Loss Post-Pruning (MLPP) optimization strategy, which greatly promotes network optimization while avoiding increases in parameters and inference time. Extensive experiments demonstrate that our RRL-Net achieves state-of-the-art (SOTA) performance on multiple public datasets. Our code will be made public later.
PyroTrack: Belief-Based Deep Reinforcement Learning Path Planning for Aerial Wildfire Monitoring in Partially Observable Environments
Mar 17, 2024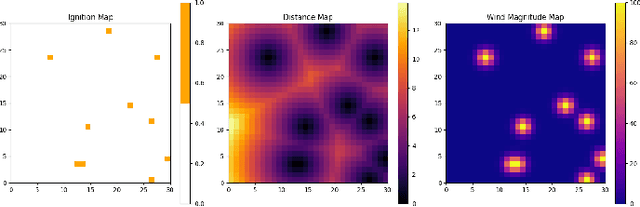
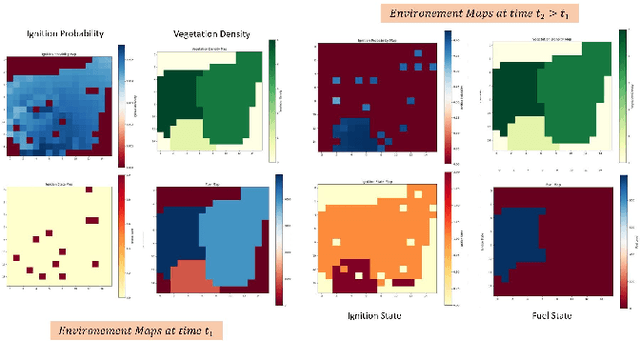
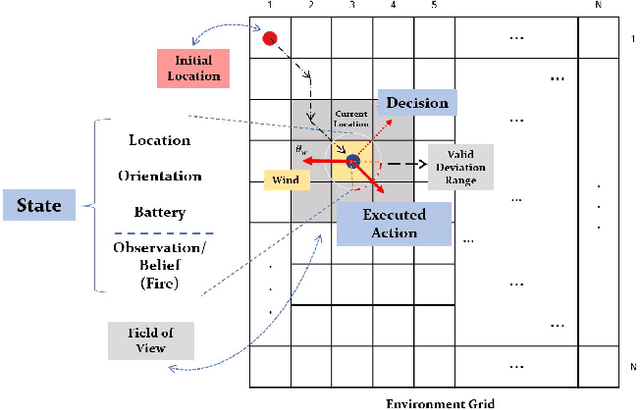
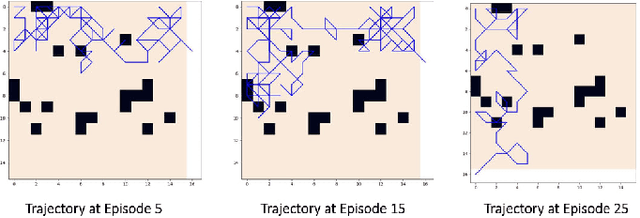
Motivated by agility, 3D mobility, and low-risk operation compared to human-operated management systems of autonomous unmanned aerial vehicles (UAVs), this work studies UAV-based active wildfire monitoring where a UAV detects fire incidents in remote areas and tracks the fire frontline. A UAV path planning solution is proposed considering realistic wildfire management missions, where a single low-altitude drone with limited power and flight time is available. Noting the limited field of view of commercial low-altitude UAVs, the problem formulates as a partially observable Markov decision process (POMDP), in which wildfire progression outside the field of view causes inaccurate state representation that prevents the UAV from finding the optimal path to track the fire front in limited time. Common deep reinforcement learning (DRL)-based trajectory planning solutions require diverse drone-recorded wildfire data to generalize pre-trained models to real-time systems, which is not currently available at a diverse and standard scale. To narrow down the gap caused by partial observability in the space of possible policies, a belief-based state representation with broad, extensive simulated data is proposed where the beliefs (i.e., ignition probabilities of different grid areas) are updated using a Bayesian framework for the cells within the field of view. The performance of the proposed solution in terms of the ratio of detected fire cells and monitored ignited area (MIA) is evaluated in a complex fire scenario with multiple rapidly growing fire batches, indicating that the belief state representation outperforms the observation state representation both in fire coverage and the distance to fire frontline.
Training Survival Models using Scoring Rules
Mar 19, 2024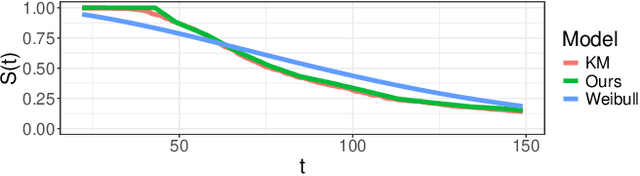
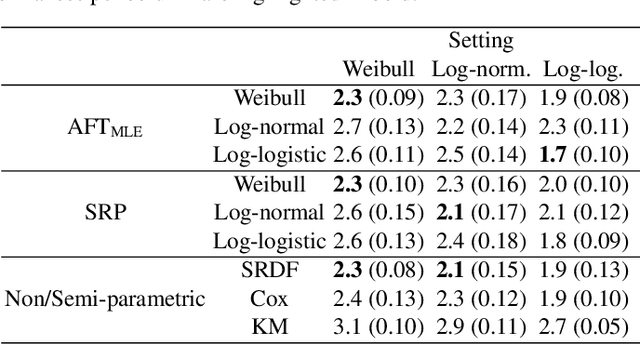
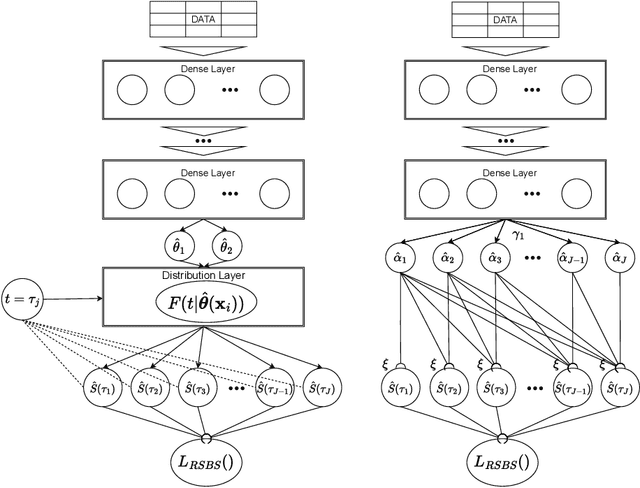
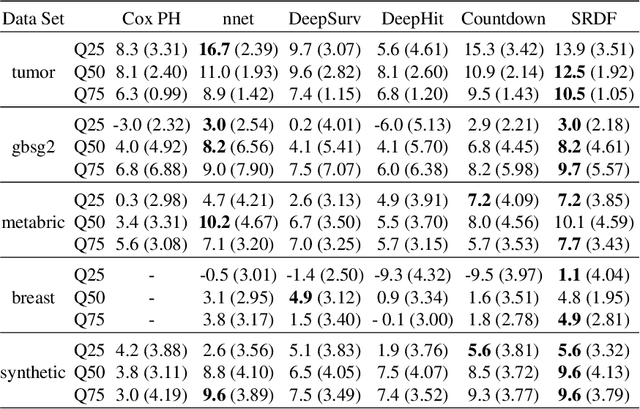
Survival Analysis provides critical insights for partially incomplete time-to-event data in various domains. It is also an important example of probabilistic machine learning. The probabilistic nature of the predictions can be exploited by using (proper) scoring rules in the model fitting process instead of likelihood-based optimization. Our proposal does so in a generic manner and can be used for a variety of model classes. We establish different parametric and non-parametric sub-frameworks that allow different degrees of flexibility. Incorporated into neural networks, it leads to a computationally efficient and scalable optimization routine, yielding state-of-the-art predictive performance. Finally, we show that using our framework, we can recover various parametric models and demonstrate that optimization works equally well when compared to likelihood-based methods.