 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErgodic Imitation for Adaptive Exploration around Demonstrations
May 13, 2026In robotics, a common challenge in imitation learning is the mismatch between training and deployment conditions, caused, for example, by environmental changes or imperfect observation and control. When a robot follows a nominal trajectory under such mismatch, it may become stuck and fail to complete the task. This calls for adaptive online exploration strategies that remain grounded in demonstrations. To this end, we propose an adaptive ergodic imitation approach that constructs a target distribution from the geometry of the retrieved demonstrations and uses it to generate trajectories that adaptively interpolate between tracking and exploration. Our method extends ergodic control beyond its traditional role in area-coverage and search by incorporating demonstrations into a retrieval-based receding-horizon framework for adaptive imitation.
XGrammar 2: Dynamic and Efficient Structured Generation Engine for Agentic LLMs
Jan 07, 2026Modern LLM agents are required to handle increasingly complex structured generation tasks, such as tool calling and conditional structured generation. These tasks are significantly more dynamic than predefined structures, posing new challenges to the current structured generation engines. In this paper, we propose XGrammar 2, a highly optimized structured generation engine for agentic LLMs. XGrammar 2 accelerates the mask generation for these dynamic structured generation tasks through a new dynamic dispatching semantics: TagDispatch. We further introduce a just-in-time (JIT) compilation method to reduce compilation time and a cross-grammar caching mechanism to leverage the common sub-structures across different grammars. Additionally, we extend the previous PDA-based mask generation algorithm to the Earley-parser-based one and design a repetition compression algorithm to handle repetition structures in grammars. Evaluation results show that XGrammar 2 can achieve more than 6x speedup over the existing structured generation engines. Integrated with an LLM inference engine, XGrammar 2 can handle dynamic structured generation tasks with near-zero overhead.
3D Near-Field Beam Training for Uniform Planar Arrays through Beam Diverging
Sep 19, 2025In future 6G communication systems, large-scale antenna arrays promise enhanced signal strength and spatial resolution, but they also increase the complexity of beam training. Moreover, as antenna counts grow and carrier wavelengths shrink, the channel model transits from far-field (FF) planar waves to near-field (NF) spherical waves, further complicating the beam training process. This paper focuses on millimeter-wave (mmWave) systems equipped with large-scale uniform planar arrays (UPAs), which produce 3D beam patterns and introduce additional challenges for NF beam training. Existing methods primarily rely on either FF steering or NF focusing codewords, both of which are highly sensitive to mismatches in user equipment (UE) location, leading to high sensitivity to even slight mismatch and excessive training overhead. In contrast, we introduce a novel beam training approach leveraging the beam-diverging effect, which enables adjustable wide-beam coverage using only a single radio frequency (RF) chain. Specifically, we first analyze the spatial characteristics of this effect in UPA systems and leverage them to construct hierarchical codebooks for coarse UE localization. Then, we develop a 3D sampling mechanism to build an NF refinement codebook for precise beam training. Numerical results demonstrate that the proposed algorithm achieves superior beam training performance while maintaining low training overhead.
Near-Field Beam Training Through Beam Diverging
Sep 19, 2025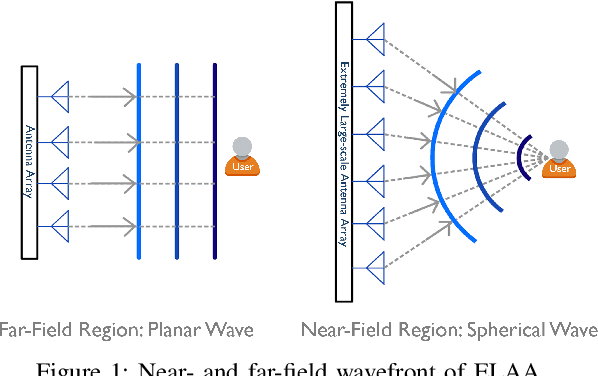
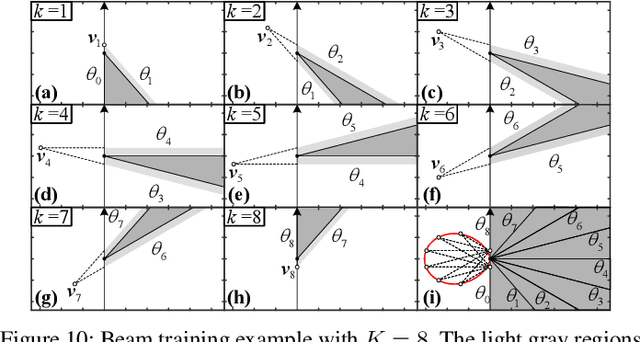
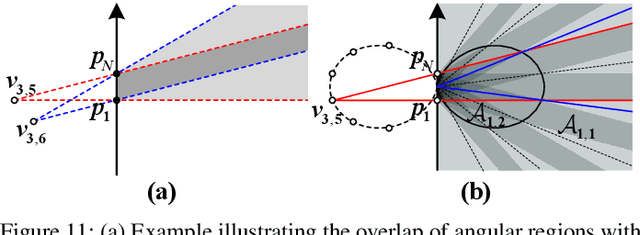
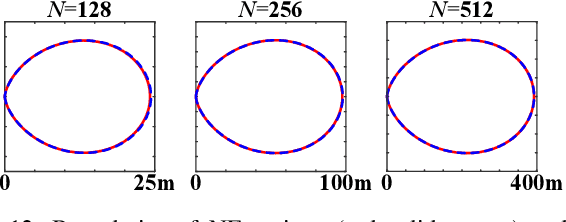
This paper investigates beam training techniques for near-field (NF) extremely large-scale antenna arrays (ELAAs). Existing NF beam training methods predominantly rely on beam focusing, where the base station (BS) transmits highly spatially selective beams to locate the user equipment (UE). However, these beam-focusing-based schemes suffer from both high beam sweeping overhead and limited accuracy in the NF, primarily due to the narrow beams' high susceptibility to misalignment. To address this, we propose a novel NF beam training paradigm using diverging beams. Specifically, we introduce the beam diverging effect and exploit it for low-overhead, high-accuracy beam training. First, we design a diverging codeword to induce the beam diverging effect with a single radio frequency (RF) chain. Next, we develop a diverging polar-domain codebook (DPC) along with a hierarchical method that enables angular-domain localization of the UE with only 2 log_2(N) pilots, where N denotes the number of antennas. Finally, we enhance beam training performance through two additional techniques: a DPC angular range reduction strategy to improve the effectiveness of beam diverging, and a pilot set expansion method to increase overall beam training accuracy. Numerical results show that our algorithm achieves near-optimal accuracy with a small pilot overhead, outperforming existing methods.
LEMON-Mapping: Loop-Enhanced Large-Scale Multi-Session Point Cloud Merging and Optimization for Globally Consistent Mapping
May 15, 2025With the rapid development of robotics, multi-robot collaboration has become critical and challenging. One key problem is integrating data from multiple robots to build a globally consistent and accurate map for robust cooperation and precise localization. While traditional multi-robot pose graph optimization (PGO) maintains basic global consistency, it focuses primarily on pose optimization and ignores the geometric structure of the map. Moreover, PGO only uses loop closure as a constraint between two nodes, failing to fully exploit its capability to maintaining local consistency of multi-robot maps. Therefore, PGO-based multi-robot mapping methods often suffer from serious map divergence and blur, especially in regions with overlapping submaps. To address this issue, we propose Lemon-Mapping, a loop-enhanced framework for large-scale multi-session point cloud map fusion and optimization, which reasonably utilizes loop closure and improves the geometric quality of the map. We re-examine the role of loops for multi-robot mapping and introduce three key innovations. First, we develop a robust loop processing mechanism that effectively rejects outliers and a novel loop recall strategy to recover mistakenly removed loops. Second, we introduce a spatial bundle adjustment method for multi-robot maps that significantly reduces the divergence in overlapping regions and eliminates map blur. Third, we design a PGO strategy that leverages the refined constraints of bundle adjustment to extend the local accuracy to the global map. We validate our framework on several public datasets and a self-collected dataset. Experimental results demonstrate that our method outperforms traditional map merging approaches in terms of mapping accuracy and reduction of map divergence. Scalability experiments also demonstrate the strong capability of our framework to handle scenarios involving numerous robots.
AnchorCrafter: Animate CyberAnchors Saling Your Products via Human-Object Interacting Video Generation
Nov 26, 2024



The automatic generation of anchor-style product promotion videos presents promising opportunities in online commerce, advertising, and consumer engagement. However, this remains a challenging task despite significant advancements in pose-guided human video generation. In addressing this challenge, we identify the integration of human-object interactions (HOI) into pose-guided human video generation as a core issue. To this end, we introduce AnchorCrafter, a novel diffusion-based system designed to generate 2D videos featuring a target human and a customized object, achieving high visual fidelity and controllable interactions. Specifically, we propose two key innovations: the HOI-appearance perception, which enhances object appearance recognition from arbitrary multi-view perspectives and disentangles object and human appearance, and the HOI-motion injection, which enables complex human-object interactions by overcoming challenges in object trajectory conditioning and inter-occlusion management. Additionally, we introduce the HOI-region reweighting loss, a training objective that enhances the learning of object details. Extensive experiments demonstrate that our proposed system outperforms existing methods in preserving object appearance and shape awareness, while simultaneously maintaining consistency in human appearance and motion. Project page: https://cangcz.github.io/Anchor-Crafter/
XGrammar: Flexible and Efficient Structured Generation Engine for Large Language Models
Nov 22, 2024



The applications of LLM Agents are becoming increasingly complex and diverse, leading to a high demand for structured outputs that can be parsed into code, structured function calls, and embodied agent commands. These developments bring significant demands for structured generation in LLM inference. Context-free grammar is a flexible approach to enable structured generation via constrained decoding. However, executing context-free grammar requires going through several stack states over all tokens in vocabulary during runtime, bringing non-negligible overhead for structured generation. In this paper, we propose XGrammar, a flexible and efficient structure generation engine for large language models. XGrammar accelerates context-free grammar execution by dividing the vocabulary into context-independent tokens that can be prechecked and context-dependent tokens that need to be interpreted during runtime. We further build transformations to expand the grammar context and reduce the number of context-independent tokens. Additionally, we build an efficient persistent stack to accelerate the context-dependent token checks. Finally, we co-design the grammar engine with LLM inference engine to overlap grammar computation with GPU executions. Evaluation results show that XGrammar can achieve up to 100x speedup over existing solutions. Combined with an LLM inference engine, it can generate near-zero overhead structure generation in end-to-end low-LLM serving.
Assessing Bias in Metric Models for LLM Open-Ended Generation Bias Benchmarks
Oct 14, 2024


Open-generation bias benchmarks evaluate social biases in Large Language Models (LLMs) by analyzing their outputs. However, the classifiers used in analysis often have inherent biases, leading to unfair conclusions. This study examines such biases in open-generation benchmarks like BOLD and SAGED. Using the MGSD dataset, we conduct two experiments. The first uses counterfactuals to measure prediction variations across demographic groups by altering stereotype-related prefixes. The second applies explainability tools (SHAP) to validate that the observed biases stem from these counterfactuals. Results reveal unequal treatment of demographic descriptors, calling for more robust bias metric models.
Preserving Relative Localization of FoV-Limited Drone Swarm via Active Mutual Observation
Jul 01, 2024Relative state estimation is crucial for vision-based swarms to estimate and compensate for the unavoidable drift of visual odometry. For autonomous drones equipped with the most compact sensor setting -- a stereo camera that provides a limited field of view (FoV), the demand for mutual observation for relative state estimation conflicts with the demand for environment observation. To balance the two demands for FoV limited swarms by acquiring mutual observations with a safety guarantee, this paper proposes an active localization correction system, which plans camera orientations via a yaw planner during the flight. The yaw planner manages the contradiction by calculating suitable timing and yaw angle commands based on the evaluation of localization uncertainty estimated by the Kalman Filter. Simulation validates the scalability of our algorithm. In real-world experiments, we reduce positioning drift by up to 65% and managed to maintain a given formation in both indoor and outdoor GPS-denied flight, from which the accuracy, efficiency, and robustness of the proposed system are verified.
FACT: Fast and Active Coordinate Initialization for Vision-based Drone Swarms
Mar 20, 2024



Swarm robots have sparked remarkable developments across a range of fields. While it is necessary for various applications in swarm robots, a fast and robust coordinate initialization in vision-based drone swarms remains elusive. To this end, our paper proposes a complete system to recover a swarm's initial relative pose on platforms with size, weight, and power (SWaP) constraints. To overcome limited coverage of field-of-view (FoV), the drones rotate in place to obtain observations. To tackle the anonymous measurements, we formulate a non-convex rotation estimation problem and transform it into a semi-definite programming (SDP) problem, which can steadily obtain global optimal values. Then we utilize the Hungarian algorithm to recover relative translation and correspondences between observations and drone identities. To safely acquire complete observations, we actively search for positions and generate feasible trajectories to avoid collisions. To validate the practicability of our system, we conduct experiments on a vision-based drone swarm with only stereo cameras and inertial measurement units (IMUs) as sensors. The results demonstrate that the system can robustly get accurate relative poses in real time with limited onboard computation resources. The source code is released.