 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation
Dec 30, 2025Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.
Uni-AIMS: AI-Powered Microscopy Image Analysis
May 11, 2025This paper presents a systematic solution for the intelligent recognition and automatic analysis of microscopy images. We developed a data engine that generates high-quality annotated datasets through a combination of the collection of diverse microscopy images from experiments, synthetic data generation and a human-in-the-loop annotation process. To address the unique challenges of microscopy images, we propose a segmentation model capable of robustly detecting both small and large objects. The model effectively identifies and separates thousands of closely situated targets, even in cluttered visual environments. Furthermore, our solution supports the precise automatic recognition of image scale bars, an essential feature in quantitative microscopic analysis. Building upon these components, we have constructed a comprehensive intelligent analysis platform and validated its effectiveness and practicality in real-world applications. This study not only advances automatic recognition in microscopy imaging but also ensures scalability and generalizability across multiple application domains, offering a powerful tool for automated microscopic analysis in interdisciplinary research.
S3MOT: Monocular 3D Object Tracking with Selective State Space Model
Apr 25, 2025



Accurate and reliable multi-object tracking (MOT) in 3D space is essential for advancing robotics and computer vision applications. However, it remains a significant challenge in monocular setups due to the difficulty of mining 3D spatiotemporal associations from 2D video streams. In this work, we present three innovative techniques to enhance the fusion and exploitation of heterogeneous cues for monocular 3D MOT: (1) we introduce the Hungarian State Space Model (HSSM), a novel data association mechanism that compresses contextual tracking cues across multiple paths, enabling efficient and comprehensive assignment decisions with linear complexity. HSSM features a global receptive field and dynamic weights, in contrast to traditional linear assignment algorithms that rely on hand-crafted association costs. (2) We propose Fully Convolutional One-stage Embedding (FCOE), which eliminates ROI pooling by directly using dense feature maps for contrastive learning, thus improving object re-identification accuracy under challenging conditions such as varying viewpoints and lighting. (3) We enhance 6-DoF pose estimation through VeloSSM, an encoder-decoder architecture that models temporal dependencies in velocity to capture motion dynamics, overcoming the limitations of frame-based 3D inference. Experiments on the KITTI public test benchmark demonstrate the effectiveness of our method, achieving a new state-of-the-art performance of 76.86~HOTA at 31~FPS. Our approach outperforms the previous best by significant margins of +2.63~HOTA and +3.62~AssA, showcasing its robustness and efficiency for monocular 3D MOT tasks. The code and models are available at https://github.com/bytepioneerX/s3mot.
SF-Loc: A Visual Mapping and Geo-Localization System based on Sparse Visual Structure Frames
Dec 02, 2024



For high-level geo-spatial applications and intelligent robotics, accurate global pose information is of crucial importance. Map-aided localization is an important and universal approach to overcome the limitations of global navigation satellite system (GNSS) in challenging environments. However, current solutions face challenges in terms of mapping flexibility, storage burden and re-localization performance. In this work, we present SF-Loc, a lightweight visual mapping and map-aided localization system, whose core idea is the map representation based on sparse frames with dense (though downsampled) depth, termed as visual structure frames. In the mapping phase, multi-sensor dense bundle adjustment (MS-DBA) is applied to construct geo-referenced visual structure frames. The local co-visbility is checked to keep the map sparsity and achieve incremental mapping. In the localization phase, coarse-to-fine vision-based localization is performed, in which multi-frame information and the map distribution are fully integrated. To be specific, the concept of spatially smoothed similarity (SSS) is proposed to overcome the place ambiguity, and pairwise frame matching is applied for efficient and robust pose estimation. Experimental results on both public and self-made datasets verify the effectiveness of the system. In complex urban road scenarios, the map size is down to 3 MB per kilometer and stable decimeter-level re-localization can be achieved. The code will be made open-source soon (https://github.com/GREAT-WHU/SF-Loc).
iKalibr-RGBD: Partially-Specialized Target-Free Visual-Inertial Spatiotemporal Calibration For RGBDs via Continuous-Time Velocity Estimation
Sep 11, 2024



Visual-inertial systems have been widely studied and applied in the last two decades, mainly due to their low cost and power consumption, small footprint, and high availability. Such a trend simultaneously leads to a large amount of visual-inertial calibration methods being presented, as accurate spatiotemporal parameters between sensors are a prerequisite for visual-inertial fusion. In our previous work, i.e., iKalibr, a continuous-time-based visual-inertial calibration method was proposed as a part of one-shot multi-sensor resilient spatiotemporal calibration. While requiring no artificial target brings considerable convenience, computationally expensive pose estimation is demanded in initialization and batch optimization, limiting its availability. Fortunately, this could be vastly improved for the RGBDs with additional depth information, by employing mapping-free ego-velocity estimation instead of mapping-based pose estimation. In this paper, we present the continuous-time ego-velocity estimation-based RGBD-inertial spatiotemporal calibration, termed as iKalibr-RGBD, which is also targetless but computationally efficient. The general pipeline of iKalibr-RGBD is inherited from iKalibr, composed of a rigorous initialization procedure and several continuous-time batch optimizations. The implementation of iKalibr-RGBD is open-sourced at (https://github.com/Unsigned-Long/iKalibr) to benefit the research community.
RIs-Calib: An Open-Source Spatiotemporal Calibrator for Multiple 3D Radars and IMUs Based on Continuous-Time Estimation
Aug 05, 2024



Aided inertial navigation system (INS), typically consisting of an inertial measurement unit (IMU) and an exteroceptive sensor, has been widely accepted as a feasible solution for navigation. Compared with vision-aided and LiDAR-aided INS, radar-aided INS could achieve better performance in adverse weather conditions since the radar utilizes low-frequency measuring signals with less attenuation effect in atmospheric gases and rain. For such a radar-aided INS, accurate spatiotemporal transformation is a fundamental prerequisite to achieving optimal information fusion. In this work, we present RIs-Calib: a spatiotemporal calibrator for multiple 3D radars and IMUs based on continuous-time estimation, which enables accurate spatiotemporal calibration and does not require any additional artificial infrastructure or prior knowledge. Our approach starts with a rigorous and robust procedure for state initialization, followed by batch optimizations, where all parameters can be refined to global optimal states steadily. We validate and evaluate RIs-Calib on both simulated and real-world experiments, and the results demonstrate that RIs-Calib is capable of accurate and consistent calibration. We open-source our implementations at (https://github.com/Unsigned-Long/RIs-Calib) to benefit the research community.
iKalibr: Unified Targetless Spatiotemporal Calibration for Resilient Integrated Inertial Systems
Jul 16, 2024



The integrated inertial system, typically integrating an IMU and an exteroceptive sensor such as radar, LiDAR, and camera, has been widely accepted and applied in modern robotic applications for ego-motion estimation, motion control, or autonomous exploration. To improve system accuracy, robustness, and further usability, both multiple and various sensors are generally resiliently integrated, which benefits the system performance regarding failure tolerance, perception capability, and environment compatibility. For such systems, accurate and consistent spatiotemporal calibration is required to maintain a unique spatiotemporal framework for multi-sensor fusion. Considering most existing calibration methods (i) are generally oriented to specific integrated inertial systems, (ii) often only focus on spatial determination, (iii) usually require artificial targets, lacking convenience and usability, we propose iKalibr: a unified targetless spatiotemporal calibration framework for resilient integrated inertial systems, which overcomes the above issues, and enables both accurate and consistent calibration. Altogether four commonly employed sensors are supported in iKalibr currently, namely IMU, radar, LiDAR, and camera. The proposed method starts with a rigorous and efficient dynamic initialization, where all parameters in the estimator would be accurately recovered. Following that, several continuous-time-based batch optimizations would be carried out to refine initialized parameters to global optimal ones. Sufficient real-world experiments were conducted to verify the feasibility and evaluate the calibration performance of iKalibr. The results demonstrate that iKalibr can achieve accurate resilient spatiotemporal calibration. We open-source our implementations at (https://github.com/Unsigned-Long/iKalibr) to benefit the research community.
DBA-Fusion: Tightly Integrating Deep Dense Visual Bundle Adjustment with Multiple Sensors for Large-Scale Localization and Mapping
Mar 20, 2024



Visual simultaneous localization and mapping (VSLAM) has broad applications, with state-of-the-art methods leveraging deep neural networks for better robustness and applicability. However, there is a lack of research in fusing these learning-based methods with multi-sensor information, which could be indispensable to push related applications to large-scale and complex scenarios. In this paper, we tightly integrate the trainable deep dense bundle adjustment (DBA) with multi-sensor information through a factor graph. In the framework, recurrent optical flow and DBA are performed among sequential images. The Hessian information derived from DBA is fed into a generic factor graph for multi-sensor fusion, which employs a sliding window and supports probabilistic marginalization. A pipeline for visual-inertial integration is firstly developed, which provides the minimum ability of metric-scale localization and mapping. Furthermore, other sensors (e.g., global navigation satellite system) are integrated for driftless and geo-referencing functionality. Extensive tests are conducted on both public datasets and self-collected datasets. The results validate the superior localization performance of our approach, which enables real-time dense mapping in large-scale environments. The code has been made open-source (https://github.com/GREAT-WHU/DBA-Fusion).
Ground-VIO: Monocular Visual-Inertial Odometry with Online Calibration of Camera-Ground Geometric Parameters
Jun 18, 2023



Monocular visual-inertial odometry (VIO) is a low-cost solution to provide high-accuracy, low-drifting pose estimation. However, it has been meeting challenges in vehicular scenarios due to limited dynamics and lack of stable features. In this paper, we propose Ground-VIO, which utilizes ground features and the specific camera-ground geometry to enhance monocular VIO performance in realistic road environments. In the method, the camera-ground geometry is modeled with vehicle-centered parameters and integrated into an optimization-based VIO framework. These parameters could be calibrated online and simultaneously improve the odometry accuracy by providing stable scale-awareness. Besides, a specially designed visual front-end is developed to stably extract and track ground features via the inverse perspective mapping (IPM) technique. Both simulation tests and real-world experiments are conducted to verify the effectiveness of the proposed method. The results show that our implementation could dramatically improve monocular VIO accuracy in vehicular scenarios, achieving comparable or even better performance than state-of-art stereo VIO solutions. The system could also be used for the auto-calibration of IPM which is widely used in vehicle perception. A toolkit for ground feature processing, together with the experimental datasets, would be made open-source (https://github.com/GREAT-WHU/gv_tools).
Dynamic Supervisor for Cross-dataset Object Detection
Apr 01, 2022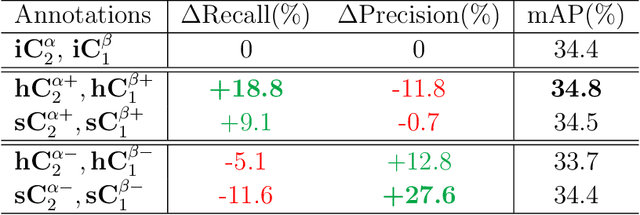
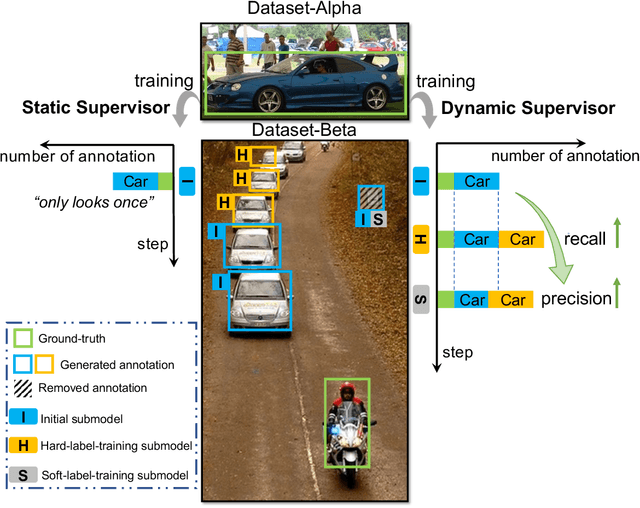

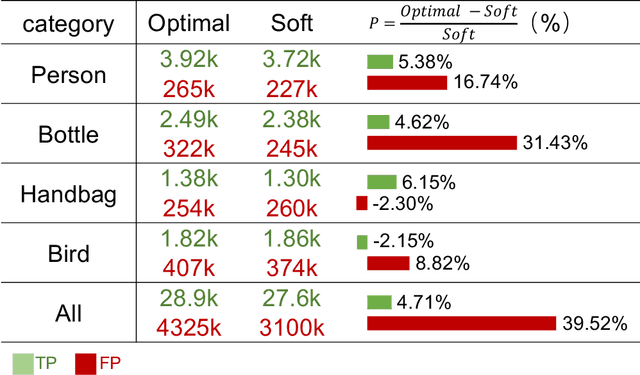
The application of cross-dataset training in object detection tasks is complicated because the inconsistency in the category range across datasets transforms fully supervised learning into semi-supervised learning. To address this problem, recent studies focus on the generation of high-quality missing annotations. In this study, we first point out that it is not enough to generate high-quality annotations using a single model, which only looks once for annotations. Through detailed experimental analyses, we further conclude that hard-label training is conducive to generating high-recall annotations, while soft-label training tends to obtain high-precision annotations. Inspired by the aspects mentioned above, we propose a dynamic supervisor framework that updates the annotations multiple times through multiple-updated submodels trained using hard and soft labels. In the final generated annotations, both recall and precision improve significantly through the integration of hard-label training with soft-label training. Extensive experiments conducted on various dataset combination settings support our analyses and demonstrate the superior performance of the proposed dynamic supervisor.