 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Guided Learning Network for Infrared Small Target Detection
Dec 10, 2025Recently, infrared small target detection has attracted extensive attention. However, due to the small size and the lack of intrinsic features of infrared small targets, the existing methods generally have the problem of inaccurate edge positioning and the target is easily submerged by the background. Therefore, we propose an innovative gradient-guided learning network (GGL-Net). Specifically, we are the first to explore the introduction of gradient magnitude images into the deep learning-based infrared small target detection method, which is conducive to emphasizing the edge details and alleviating the problem of inaccurate edge positioning of small targets. On this basis, we propose a novel dual-branch feature extraction network that utilizes the proposed gradient supplementary module (GSM) to encode raw gradient information into deeper network layers and embeds attention mechanisms reasonably to enhance feature extraction ability. In addition, we construct a two-way guidance fusion module (TGFM), which fully considers the characteristics of feature maps at different levels. It can facilitate the effective fusion of multi-scale feature maps and extract richer semantic information and detailed information through reasonable two-way guidance. Extensive experiments prove that GGL-Net has achieves state-of-the-art results on the public real NUAA-SIRST dataset and the public synthetic NUDT-SIRST dataset. Our code has been integrated into https://github.com/YuChuang1205/MSDA-Net
Refined Infrared Small Target Detection Scheme with Single-Point Supervision
Aug 05, 2024Recently, infrared small target detection with single-point supervision has attracted extensive attention. However, the detection accuracy of existing methods has difficulty meeting actual needs. Therefore, we propose an innovative refined infrared small target detection scheme with single-point supervision, which has excellent segmentation accuracy and detection rate. Specifically, we introduce label evolution with single point supervision (LESPS) framework and explore the performance of various excellent infrared small target detection networks based on this framework. Meanwhile, to improve the comprehensive performance, we construct a complete post-processing strategy. On the one hand, to improve the segmentation accuracy, we use a combination of test-time augmentation (TTA) and conditional random field (CRF) for post-processing. On the other hand, to improve the detection rate, we introduce an adjustable sensitivity (AS) strategy for post-processing, which fully considers the advantages of multiple detection results and reasonably adds some areas with low confidence to the fine segmentation image in the form of centroid points. In addition, to further improve the performance and explore the characteristics of this task, on the one hand, we construct and find that a multi-stage loss is helpful for fine-grained detection. On the other hand, we find that a reasonable sliding window cropping strategy for test samples has better performance for actual multi-size samples. Extensive experimental results show that the proposed scheme achieves state-of-the-art (SOTA) performance. Notably, the proposed scheme won the third place in the "ICPR 2024 Resource-Limited Infrared Small Target Detection Challenge Track 1: Weakly Supervised Infrared Small Target Detection".
LR-Net: A Lightweight and Robust Network for Infrared Small Target Detection
Aug 05, 2024



Limited by equipment limitations and the lack of target intrinsic features, existing infrared small target detection methods have difficulty meeting actual comprehensive performance requirements. Therefore, we propose an innovative lightweight and robust network (LR-Net), which abandons the complex structure and achieves an effective balance between detection accuracy and resource consumption. Specifically, to ensure the lightweight and robustness, on the one hand, we construct a lightweight feature extraction attention (LFEA) module, which can fully extract target features and strengthen information interaction across channels. On the other hand, we construct a simple refined feature transfer (RFT) module. Compared with direct cross-layer connections, the RFT module can improve the network's feature refinement extraction capability with little resource consumption. Meanwhile, to solve the problem of small target loss in high-level feature maps, on the one hand, we propose a low-level feature distribution (LFD) strategy to use low-level features to supplement the information of high-level features. On the other hand, we introduce an efficient simplified bilinear interpolation attention module (SBAM) to promote the guidance constraints of low-level features on high-level features and the fusion of the two. In addition, We abandon the traditional resizing method and adopt a new training and inference cropping strategy, which is more robust to datasets with multi-scale samples. Extensive experimental results show that our LR-Net achieves state-of-the-art (SOTA) performance. Notably, on the basis of the proposed LR-Net, we achieve 3rd place in the "ICPR 2024 Resource-Limited Infrared Small Target Detection Challenge Track 2: Lightweight Infrared Small Target Detection".
Multi-Scale Direction-Aware Network for Infrared Small Target Detection
Jun 04, 2024



Infrared small target detection faces the problem that it is difficult to effectively separate the background and the target. Existing deep learning-based methods focus on appearance features and ignore high-frequency directional features. Therefore, we propose a multi-scale direction-aware network (MSDA-Net), which is the first attempt to integrate the high-frequency directional features of infrared small targets as domain prior knowledge into neural networks. Specifically, an innovative multi-directional feature awareness (MDFA) module is constructed, which fully utilizes the prior knowledge of targets and emphasizes the focus on high-frequency directional features. On this basis, combined with the multi-scale local relation learning (MLRL) module, a multi-scale direction-aware (MSDA) module is further constructed. The MSDA module promotes the full extraction of local relations at different scales and the full perception of key features in different directions. Meanwhile, a high-frequency direction injection (HFDI) module without training parameters is constructed to inject the high-frequency directional information of the original image into the network. This helps guide the network to pay attention to detailed information such as target edges and shapes. In addition, we propose a feature aggregation (FA) structure that aggregates multi-level features to solve the problem of small targets disappearing in deep feature maps. Furthermore, a lightweight feature alignment fusion (FAF) module is constructed, which can effectively alleviate the pixel offset existing in multi-level feature map fusion. Extensive experimental results show that our MSDA-Net achieves state-of-the-art (SOTA) results on the public NUDT-SIRST, SIRST and IRSTD-1k datasets.
Relational Representation Learning Network for Cross-Spectral Image Patch Matching
Mar 18, 2024

Recently, feature relation learning has drawn widespread attention in cross-spectral image patch matching. However, existing related research focuses on extracting diverse relations between image patch features and ignores sufficient intrinsic feature representations of individual image patches. Therefore, an innovative relational representation learning idea is proposed for the first time, which simultaneously focuses on sufficiently mining the intrinsic features of individual image patches and the relations between image patch features. Based on this, we construct a lightweight Relational Representation Learning Network (RRL-Net). Specifically, we innovatively construct an autoencoder to fully characterize the individual intrinsic features, and introduce a Feature Interaction Learning (FIL) module to extract deep-level feature relations. To further fully mine individual intrinsic features, a lightweight Multi-dimensional Global-to-Local Attention (MGLA) module is constructed to enhance the global feature extraction of individual image patches and capture local dependencies within global features. By combining the MGLA module, we further explore the feature extraction network and construct an Attention-based Lightweight Feature Extraction (ALFE) network. In addition, we propose a Multi-Loss Post-Pruning (MLPP) optimization strategy, which greatly promotes network optimization while avoiding increases in parameters and inference time. Extensive experiments demonstrate that our RRL-Net achieves state-of-the-art (SOTA) performance on multiple public datasets. Our code will be made public later.
$\mathcal{G}^2Pxy$: Generative Open-Set Node Classification on Graphs with Proxy Unknowns
Aug 10, 2023Node classification is the task of predicting the labels of unlabeled nodes in a graph. State-of-the-art methods based on graph neural networks achieve excellent performance when all labels are available during training. But in real-life, models are often applied on data with new classes, which can lead to massive misclassification and thus significantly degrade performance. Hence, developing open-set classification methods is crucial to determine if a given sample belongs to a known class. Existing methods for open-set node classification generally use transductive learning with part or all of the features of real unseen class nodes to help with open-set classification. In this paper, we propose a novel generative open-set node classification method, i.e. $\mathcal{G}^2Pxy$, which follows a stricter inductive learning setting where no information about unknown classes is available during training and validation. Two kinds of proxy unknown nodes, inter-class unknown proxies and external unknown proxies are generated via mixup to efficiently anticipate the distribution of novel classes. Using the generated proxies, a closed-set classifier can be transformed into an open-set one, by augmenting it with an extra proxy classifier. Under the constraints of both cross entropy loss and complement entropy loss, $\mathcal{G}^2Pxy$ achieves superior effectiveness for unknown class detection and known class classification, which is validated by experiments on benchmark graph datasets. Moreover, $\mathcal{G}^2Pxy$ does not have specific requirement on the GNN architecture and shows good generalizations.
Dimensionality Reduction on Grassmannian via Riemannian Optimization: A Generalized Perspective
Nov 17, 2017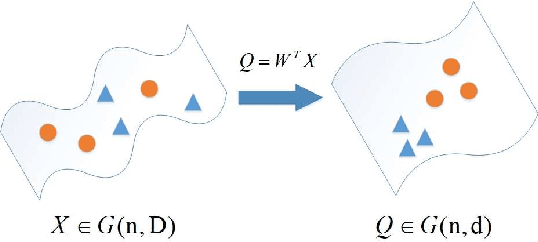
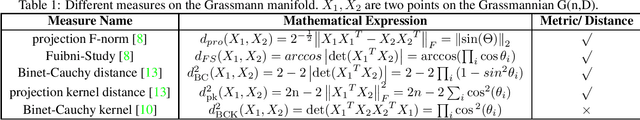
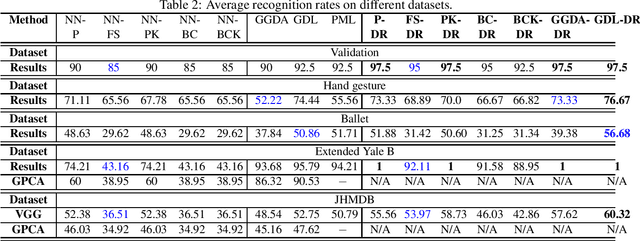
This paper proposes a generalized framework with joint normalization which learns lower-dimensional subspaces with maximum discriminative power by making use of the Riemannian geometry. In particular, we model the similarity/dissimilarity between subspaces using various metrics defined on Grassmannian and formulate dimen-sionality reduction as a non-linear constraint optimization problem considering the orthogonalization. To obtain the linear mapping, we derive the components required to per-form Riemannian optimization (e.g., Riemannian conju-gate gradient) from the original Grassmannian through an orthonormal projection. We respect the Riemannian ge-ometry of the Grassmann manifold and search for this projection directly from one Grassmann manifold to an-other face-to-face without any additional transformations. In this natural geometry-aware way, any metric on the Grassmann manifold can be resided in our model theoreti-cally. We have combined five metrics with our model and the learning process can be treated as an unconstrained optimization problem on a Grassmann manifold. Exper-iments on several datasets demonstrate that our approach leads to a significant accuracy gain over state-of-the-art methods.