 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-task Learning for Optical Coherence Tomography Angiography (OCTA) Vessel Segmentation
Nov 03, 2023
Optical Coherence Tomography Angiography (OCTA) is a non-invasive imaging technique that provides high-resolution cross-sectional images of the retina, which are useful for diagnosing and monitoring various retinal diseases. However, manual segmentation of OCTA images is a time-consuming and labor-intensive task, which motivates the development of automated segmentation methods. In this paper, we propose a novel multi-task learning method for OCTA segmentation, called OCTA-MTL, that leverages an image-to-DT (Distance Transform) branch and an adaptive loss combination strategy. The image-to-DT branch predicts the distance from each vessel voxel to the vessel surface, which can provide useful shape prior and boundary information for the segmentation task. The adaptive loss combination strategy dynamically adjusts the loss weights according to the inverse of the average loss values of each task, to balance the learning process and avoid the dominance of one task over the other. We evaluate our method on the ROSE-2 dataset its superiority in terms of segmentation performance against two baseline methods: a single-task segmentation method and a multi-task segmentation method with a fixed loss combination.
Plot Retrieval as an Assessment of Abstract Semantic Association
Nov 03, 2023Retrieving relevant plots from the book for a query is a critical task, which can improve the reading experience and efficiency of readers. Readers usually only give an abstract and vague description as the query based on their own understanding, summaries, or speculations of the plot, which requires the retrieval model to have a strong ability to estimate the abstract semantic associations between the query and candidate plots. However, existing information retrieval (IR) datasets cannot reflect this ability well. In this paper, we propose Plot Retrieval, a labeled dataset to train and evaluate the performance of IR models on the novel task Plot Retrieval. Text pairs in Plot Retrieval have less word overlap and more abstract semantic association, which can reflect the ability of the IR models to estimate the abstract semantic association, rather than just traditional lexical or semantic matching. Extensive experiments across various lexical retrieval, sparse retrieval, dense retrieval, and cross-encoder methods compared with human studies on Plot Retrieval show current IR models still struggle in capturing abstract semantic association between texts. Plot Retrieval can be the benchmark for further research on the semantic association modeling ability of IR models.
Data-Free Distillation of Language Model by Text-to-Text Transfer
Nov 03, 2023Data-Free Knowledge Distillation (DFKD) plays a vital role in compressing the model when original training data is unavailable. Previous works for DFKD in NLP mainly focus on distilling encoder-only structures like BERT on classification tasks, which overlook the notable progress of generative language modeling. In this work, we propose a novel DFKD framework, namely DFKD-T$^{3}$, where the pretrained generative language model can also serve as a controllable data generator for model compression. This novel framework DFKD-T$^{3}$ leads to an end-to-end learnable text-to-text framework to transform the general domain corpus to compression-friendly task data, targeting to improve both the \textit{specificity} and \textit{diversity}. Extensive experiments show that our method can boost the distillation performance in various downstream tasks such as sentiment analysis, linguistic acceptability, and information extraction. Furthermore, we show that the generated texts can be directly used for distilling other language models and outperform the SOTA methods, making our method more appealing in a general DFKD setting. Our code is available at https://gitee.com/mindspore/models/tree/master/research/nlp/DFKD\_T3.
Random ISAC Signals Deserve Dedicated Precoding
Nov 03, 2023Radar systems typically employ well-designed deterministic signals for target sensing, while integrated sensing and communications (ISAC) systems have to adopt random signals to convey useful information. This paper analyzes the sensing and ISAC performance relying on random signaling in a multiantenna system. Towards this end, we define a new sensing performance metric, namely, ergodic linear minimum mean square error (ELMMSE), which characterizes the estimation error averaged over random ISAC signals. Then, we investigate a data-dependent precoding (DDP) scheme to minimize the ELMMSE in sensing-only scenarios, which attains the optimized performance at the cost of high implementation overhead. To reduce the cost, we present an alternative data-independent precoding (DIP) scheme by stochastic gradient projection (SGP). Moreover, we shed light on the optimal structures of both sensing-only DDP and DIP precoders. As a further step, we extend the proposed DDP and DIP approaches to ISAC scenarios, which are solved via a tailored penalty-based alternating optimization algorithm. Our numerical results demonstrate that the proposed DDP and DIP methods achieve substantial performance gains over conventional ISAC signaling schemes that treat the signal sample covariance matrix as deterministic, which proves that random ISAC signals deserve dedicated precoding designs.
Resist Label Noise with PGM for Graph Neural Networks
Nov 03, 2023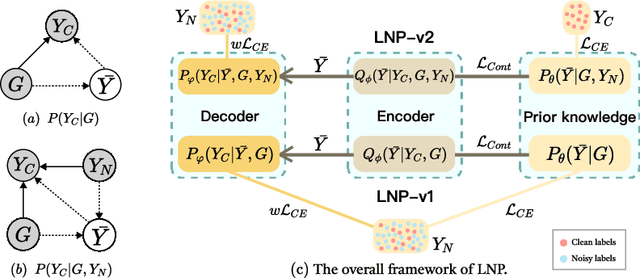
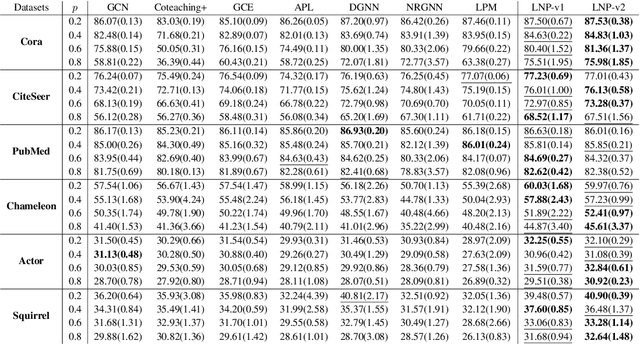
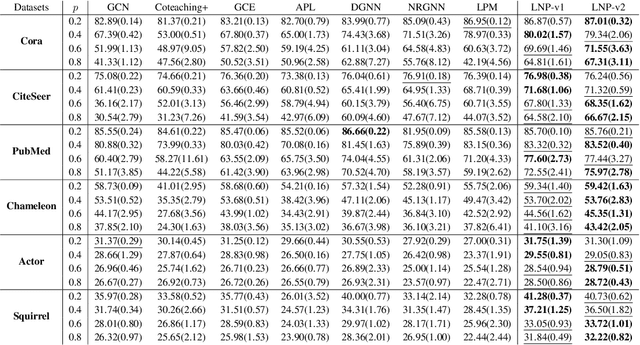
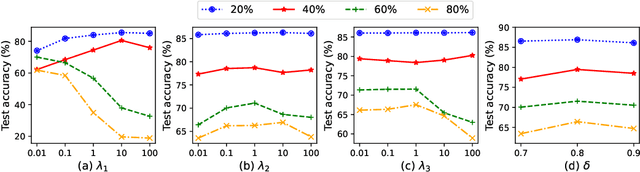
While robust graph neural networks (GNNs) have been widely studied for graph perturbation and attack, those for label noise have received significantly less attention. Most existing methods heavily rely on the label smoothness assumption to correct noisy labels, which adversely affects their performance on heterophilous graphs. Further, they generally perform poorly in high noise-rate scenarios. To address these problems, in this paper, we propose a novel probabilistic graphical model (PGM) based framework LNP. Given a noisy label set and a clean label set, our goal is to maximize the likelihood of labels in the clean set. We first present LNP-v1, which generates clean labels based on graphs only in the Bayesian network. To further leverage the information of clean labels in the noisy label set, we put forward LNP-v2, which incorporates the noisy label set into the Bayesian network to generate clean labels. The generative process can then be used to predict labels for unlabeled nodes. We conduct extensive experiments to show the robustness of LNP on varying noise types and rates, and also on graphs with different heterophilies. In particular, we show that LNP can lead to inspiring performance in high noise-rate situations.
Incorporating Probing Signals into Multimodal Machine Translation via Visual Question-Answering Pairs
Oct 26, 2023This paper presents an in-depth study of multimodal machine translation (MMT), examining the prevailing understanding that MMT systems exhibit decreased sensitivity to visual information when text inputs are complete. Instead, we attribute this phenomenon to insufficient cross-modal interaction, rather than image information redundancy. A novel approach is proposed to generate parallel Visual Question-Answering (VQA) style pairs from the source text, fostering more robust cross-modal interaction. Using Large Language Models (LLMs), we explicitly model the probing signal in MMT to convert it into VQA-style data to create the Multi30K-VQA dataset. An MMT-VQA multitask learning framework is introduced to incorporate explicit probing signals from the dataset into the MMT training process. Experimental results on two widely-used benchmarks demonstrate the effectiveness of this novel approach. Our code and data would be available at: \url{https://github.com/libeineu/MMT-VQA}.
FABULA: Intelligence Report Generation Using Retrieval-Augmented Narrative Construction
Oct 20, 2023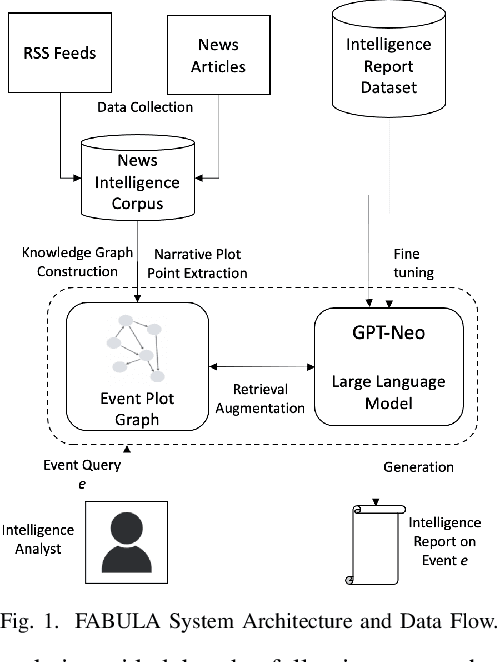
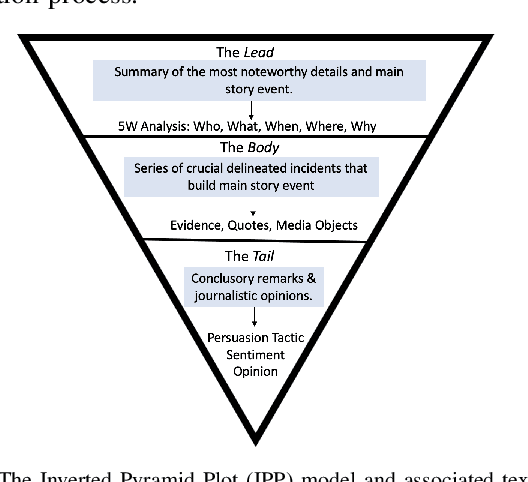
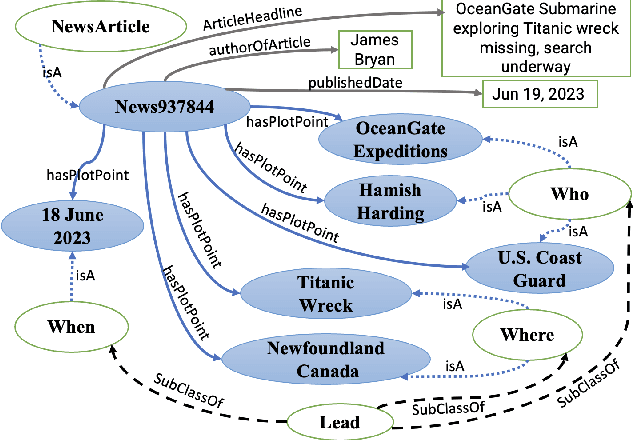
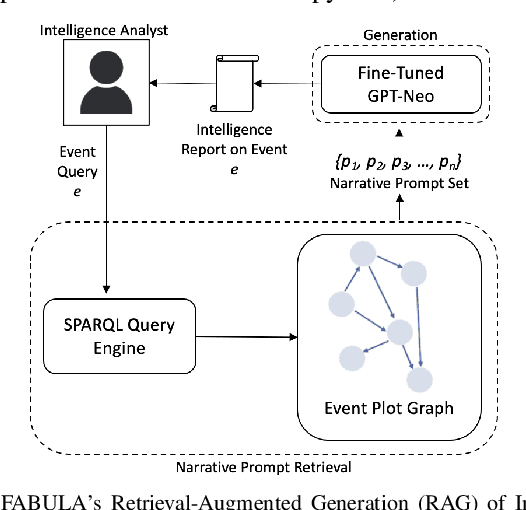
Narrative construction is the process of representing disparate event information into a logical plot structure that models an end to end story. Intelligence analysis is an example of a domain that can benefit tremendously from narrative construction techniques, particularly in aiding analysts during the largely manual and costly process of synthesizing event information into comprehensive intelligence reports. Manual intelligence report generation is often prone to challenges such as integrating dynamic event information, writing fine-grained queries, and closing information gaps. This motivates the development of a system that retrieves and represents critical aspects of events in a form that aids in automatic generation of intelligence reports. We introduce a Retrieval Augmented Generation (RAG) approach to augment prompting of an autoregressive decoder by retrieving structured information asserted in a knowledge graph to generate targeted information based on a narrative plot model. We apply our approach to the problem of neural intelligence report generation and introduce FABULA, framework to augment intelligence analysis workflows using RAG. An analyst can use FABULA to query an Event Plot Graph (EPG) to retrieve relevant event plot points, which can be used to augment prompting of a Large Language Model (LLM) during intelligence report generation. Our evaluation studies show that the plot points included in the generated intelligence reports have high semantic relevance, high coherency, and low data redundancy.
Uncertainty Estimation for Safety-critical Scene Segmentation via Fine-grained Reward Maximization
Nov 05, 2023Uncertainty estimation plays an important role for future reliable deployment of deep segmentation models in safety-critical scenarios such as medical applications. However, existing methods for uncertainty estimation have been limited by the lack of explicit guidance for calibrating the prediction risk and model confidence. In this work, we propose a novel fine-grained reward maximization (FGRM) framework, to address uncertainty estimation by directly utilizing an uncertainty metric related reward function with a reinforcement learning based model tuning algorithm. This would benefit the model uncertainty estimation through direct optimization guidance for model calibration. Specifically, our method designs a new uncertainty estimation reward function using the calibration metric, which is maximized to fine-tune an evidential learning pre-trained segmentation model for calibrating prediction risk. Importantly, we innovate an effective fine-grained parameter update scheme, which imposes fine-grained reward-weighting of each network parameter according to the parameter importance quantified by the fisher information matrix. To the best of our knowledge, this is the first work exploring reward optimization for model uncertainty estimation in safety-critical vision tasks. The effectiveness of our method is demonstrated on two large safety-critical surgical scene segmentation datasets under two different uncertainty estimation settings. With real-time one forward pass at inference, our method outperforms state-of-the-art methods by a clear margin on all the calibration metrics of uncertainty estimation, while maintaining a high task accuracy for the segmentation results. Code is available at \url{https://github.com/med-air/FGRM}.
Contrastive Learning for Inference in Dialogue
Oct 19, 2023Inference, especially those derived from inductive processes, is a crucial component in our conversation to complement the information implicitly or explicitly conveyed by a speaker. While recent large language models show remarkable advances in inference tasks, their performance in inductive reasoning, where not all information is present in the context, is far behind deductive reasoning. In this paper, we analyze the behavior of the models based on the task difficulty defined by the semantic information gap -- which distinguishes inductive and deductive reasoning (Johnson-Laird, 1988, 1993). Our analysis reveals that the disparity in information between dialogue contexts and desired inferences poses a significant challenge to the inductive inference process. To mitigate this information gap, we investigate a contrastive learning approach by feeding negative samples. Our experiments suggest negative samples help models understand what is wrong and improve their inference generations.
CenterRadarNet: Joint 3D Object Detection and Tracking Framework using 4D FMCW Radar
Nov 04, 2023Robust perception is a vital component for ensuring safe autonomous and assisted driving. Automotive radar (77 to 81 GHz), which offers weather-resilient sensing, provides a complementary capability to the vision- or LiDAR-based autonomous driving systems. Raw radio-frequency (RF) radar tensors contain rich spatiotemporal semantics besides 3D location information. The majority of previous methods take in 3D (Doppler-range-azimuth) RF radar tensors, allowing prediction of an object's location, heading angle, and size in bird's-eye-view (BEV). However, they lack the ability to at the same time infer objects' size, orientation, and identity in the 3D space. To overcome this limitation, we propose an efficient joint architecture called CenterRadarNet, designed to facilitate high-resolution representation learning from 4D (Doppler-range-azimuth-elevation) radar data for 3D object detection and re-identification (re-ID) tasks. As a single-stage 3D object detector, CenterRadarNet directly infers the BEV object distribution confidence maps, corresponding 3D bounding box attributes, and appearance embedding for each pixel. Moreover, we build an online tracker utilizing the learned appearance embedding for re-ID. CenterRadarNet achieves the state-of-the-art result on the K-Radar 3D object detection benchmark. In addition, we present the first 3D object-tracking result using radar on the K-Radar dataset V2. In diverse driving scenarios, CenterRadarNet shows consistent, robust performance, emphasizing its wide applicability.