 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bi-Bimodal Modality Fusion for Correlation-Controlled Multimodal Sentiment Analysis
Jul 28, 2021
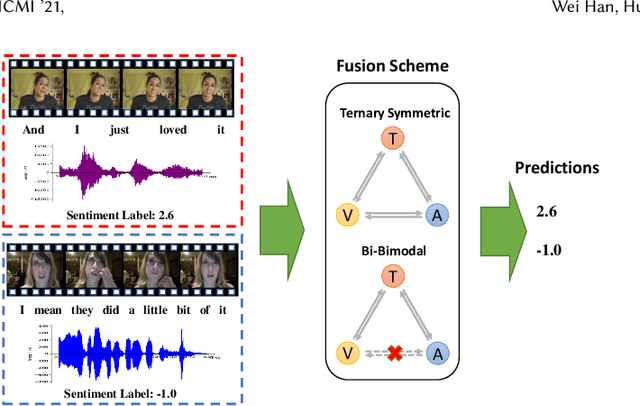
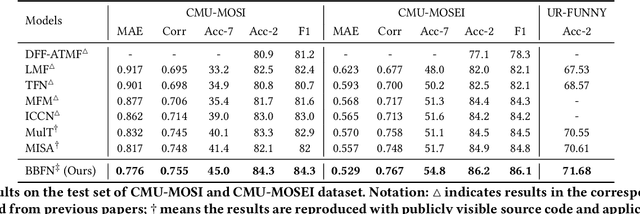
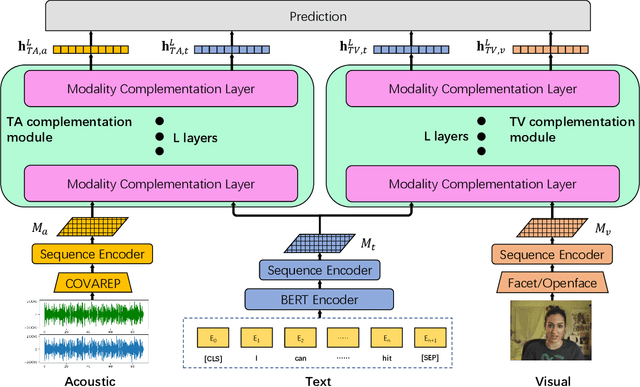
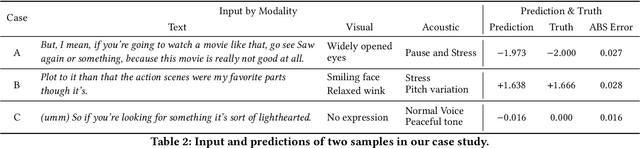
Multimodal sentiment analysis aims to extract and integrate semantic information collected from multiple modalities to recognize the expressed emotions and sentiment in multimodal data. This research area's major concern lies in developing an extraordinary fusion scheme that can extract and integrate key information from various modalities. However, one issue that may restrict previous work to achieve a higher level is the lack of proper modeling for the dynamics of the competition between the independence and relevance among modalities, which could deteriorate fusion outcomes by causing the collapse of modality-specific feature space or introducing extra noise. To mitigate this, we propose the Bi-Bimodal Fusion Network (BBFN), a novel end-to-end network that performs fusion (relevance increment) and separation (difference increment) on pairwise modality representations. The two parts are trained simultaneously such that the combat between them is simulated. The model takes two bimodal pairs as input due to the known information imbalance among modalities. In addition, we leverage a gated control mechanism in the Transformer architecture to further improve the final output. Experimental results on three datasets (CMU-MOSI, CMU-MOSEI, and UR-FUNNY) verifies that our model significantly outperforms the SOTA. The implementation of this work is available at https://github.com/declare-lab/BBFN.
Towards Successful Collaboration: Design Guidelines for AI-based Services enriching Information Systems in Organisations
Dec 02, 2019Information systems (IS) are widely used in organisations to improve business performance. The steady progression in improving technologies like artificial intelligence (AI) and the need of securing future success of organisations lead to new requirements for IS. This research in progress firstly introduces the term AI-based services (AIBS) describing AI as a component enriching IS aiming at collaborating with employees and assisting in the execution of work-related tasks. The study derives requirements from ten expert interviews to successful design AIBS following Design Science Research (DSR). For a successful deployment of AIBS in organisations the D&M IS Success Model will be considered to validated requirements within three major dimensions of quality: Information Quality, System Quality, and Service Quality. Amongst others, preliminary findings propose that AIBS must be preferably authentic. Further discussion and research on AIBS is forced, thus, providing first insights on the deployment of AIBS in organisations.
Triple-level Model Inferred Collaborative Network Architecture for Video Deraining
Nov 08, 2021
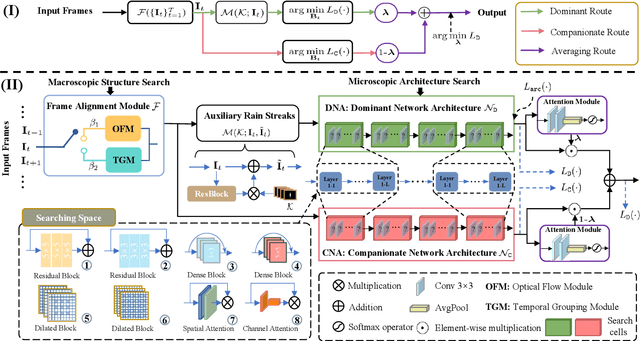
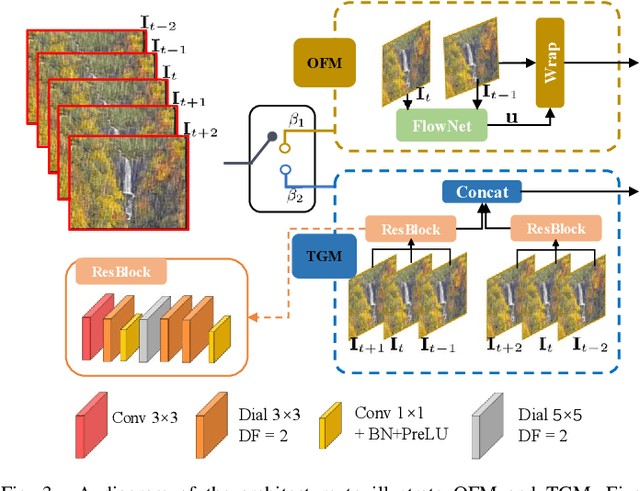
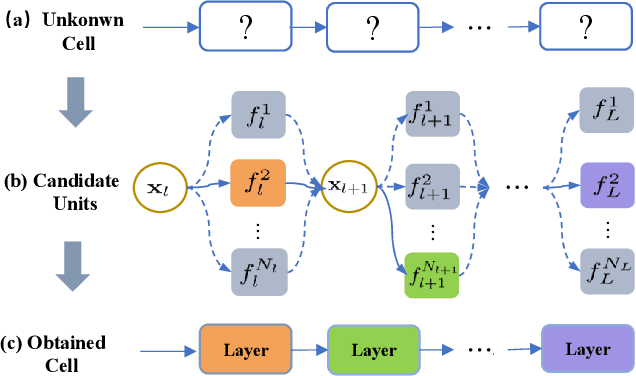
Video deraining is an important issue for outdoor vision systems and has been investigated extensively. However, designing optimal architectures by the aggregating model formation and data distribution is a challenging task for video deraining. In this paper, we develop a model-guided triple-level optimization framework to deduce network architecture with cooperating optimization and auto-searching mechanism, named Triple-level Model Inferred Cooperating Searching (TMICS), for dealing with various video rain circumstances. In particular, to mitigate the problem that existing methods cannot cover various rain streaks distribution, we first design a hyper-parameter optimization model about task variable and hyper-parameter. Based on the proposed optimization model, we design a collaborative structure for video deraining. This structure includes Dominant Network Architecture (DNA) and Companionate Network Architecture (CNA) that is cooperated by introducing an Attention-based Averaging Scheme (AAS). To better explore inter-frame information from videos, we introduce a macroscopic structure searching scheme that searches from Optical Flow Module (OFM) and Temporal Grouping Module (TGM) to help restore latent frame. In addition, we apply the differentiable neural architecture searching from a compact candidate set of task-specific operations to discover desirable rain streaks removal architectures automatically. Extensive experiments on various datasets demonstrate that our model shows significant improvements in fidelity and temporal consistency over the state-of-the-art works. Source code is available at https://github.com/vis-opt-group/TMICS.
Image-Guided Navigation of a Robotic Ultrasound Probe for Autonomous Spinal Sonography Using a Shadow-aware Dual-Agent Framework
Nov 03, 2021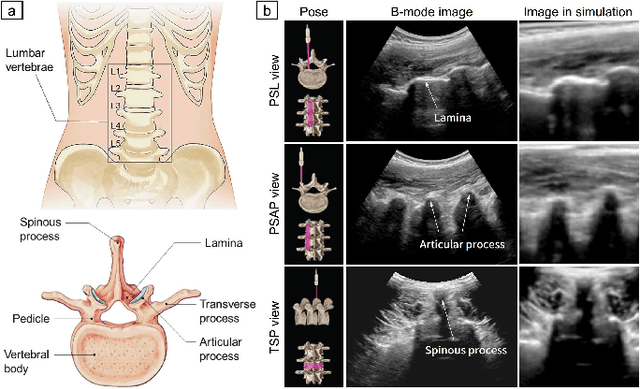
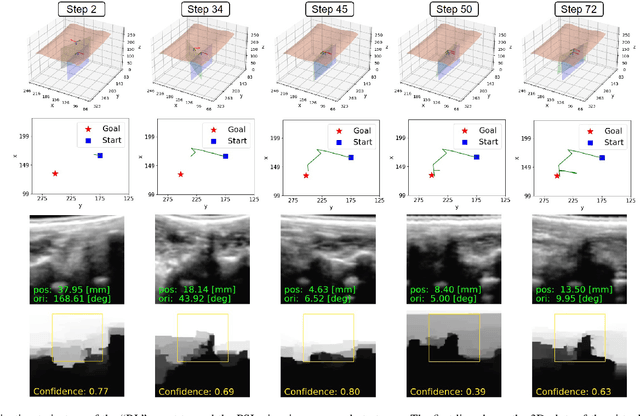
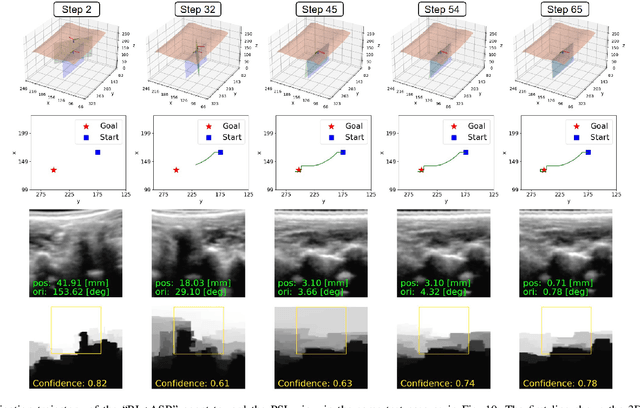
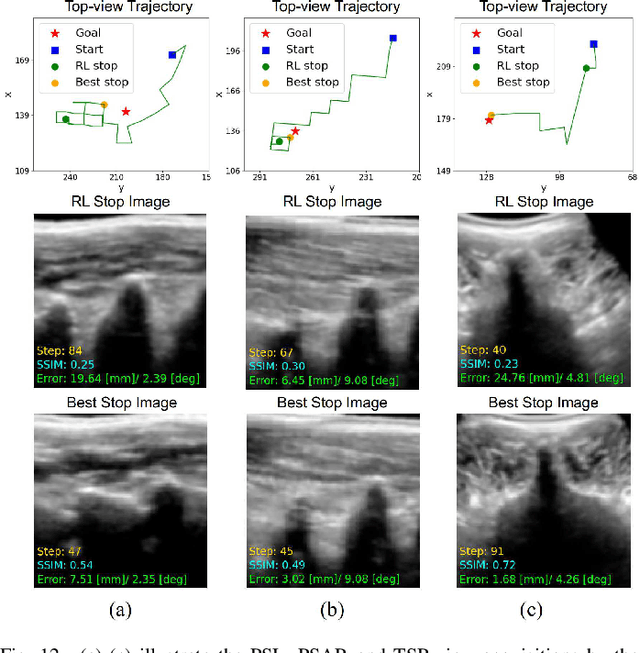
Ultrasound (US) imaging is commonly used to assist in the diagnosis and interventions of spine diseases, while the standardized US acquisitions performed by manually operating the probe require substantial experience and training of sonographers. In this work, we propose a novel dual-agent framework that integrates a reinforcement learning (RL) agent and a deep learning (DL) agent to jointly determine the movement of the US probe based on the real-time US images, in order to mimic the decision-making process of an expert sonographer to achieve autonomous standard view acquisitions in spinal sonography. Moreover, inspired by the nature of US propagation and the characteristics of the spinal anatomy, we introduce a view-specific acoustic shadow reward to utilize the shadow information to implicitly guide the navigation of the probe toward different standard views of the spine. Our method is validated in both quantitative and qualitative experiments in a simulation environment built with US data acquired from $17$ volunteers. The average navigation accuracy toward different standard views achieves $5.18mm/5.25^\circ$ and $12.87mm/17.49^\circ$ in the intra- and inter-subject settings, respectively. The results demonstrate that our method can effectively interpret the US images and navigate the probe to acquire multiple standard views of the spine.
Out of Context: A New Clue for Context Modeling of Aspect-based Sentiment Analysis
Jun 21, 2021

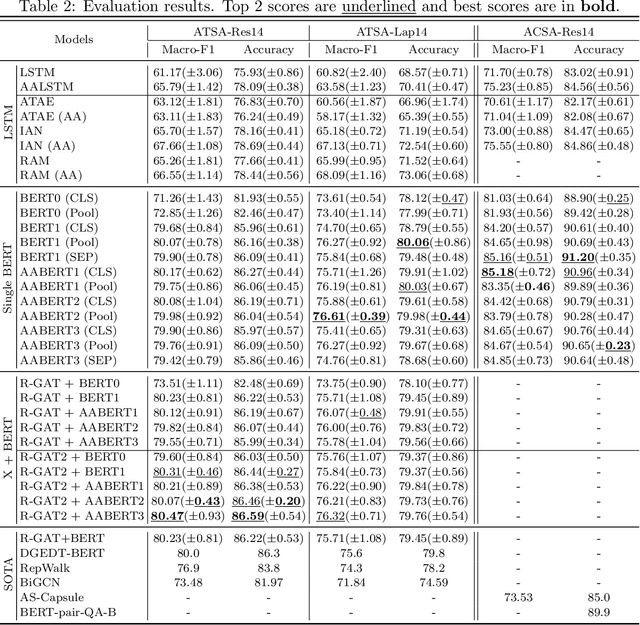
Aspect-based sentiment analysis (ABSA) aims to predict the sentiment expressed in a review with respect to a given aspect. The core of ABSA is to model the interaction between the context and given aspect to extract the aspect-related information. In prior work, attention mechanisms and dependency graph networks are commonly adopted to capture the relations between the context and given aspect. And the weighted sum of context hidden states is used as the final representation fed to the classifier. However, the information related to the given aspect may be already discarded and adverse information may be retained in the context modeling processes of existing models. This problem cannot be solved by subsequent modules and there are two reasons: first, their operations are conducted on the encoder-generated context hidden states, whose value cannot change after the encoder; second, existing encoders only consider the context while not the given aspect. To address this problem, we argue the given aspect should be considered as a new clue out of context in the context modeling process. As for solutions, we design several aspect-aware context encoders based on different backbones: an aspect-aware LSTM and three aspect-aware BERTs. They are dedicated to generate aspect-aware hidden states which are tailored for ABSA task. In these aspect-aware context encoders, the semantics of the given aspect is used to regulate the information flow. Consequently, the aspect-related information can be retained and aspect-irrelevant information can be excluded in the generated hidden states. We conduct extensive experiments on several benchmark datasets with empirical analysis, demonstrating the efficacies and advantages of our proposed aspect-aware context encoders.
EMScore: Evaluating Video Captioning via Coarse-Grained and Fine-Grained Embedding Matching
Nov 17, 2021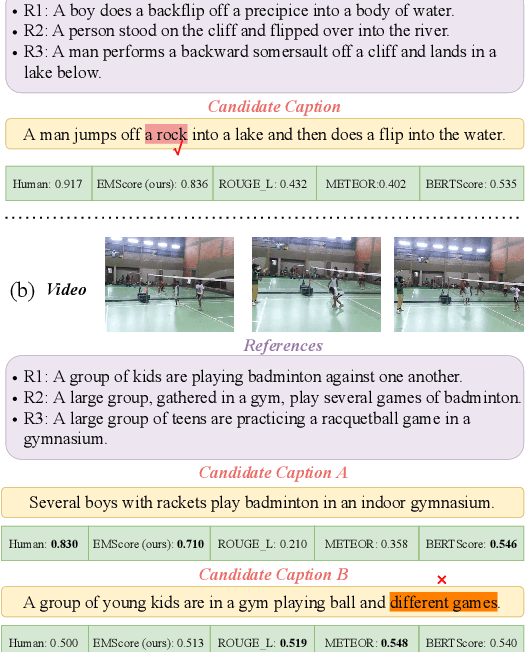
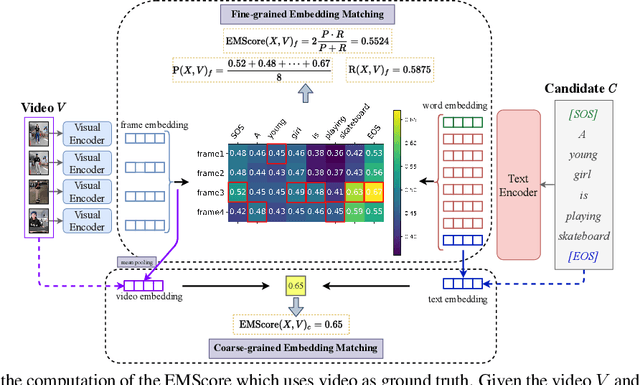
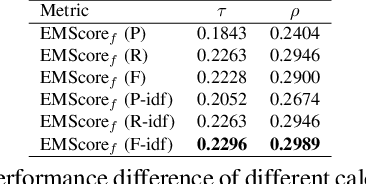

Current metrics for video captioning are mostly based on the text-level comparison between reference and candidate captions. However, they have some insuperable drawbacks, e.g., they cannot handle videos without references, and they may result in biased evaluation due to the one-to-many nature of video-to-text and the neglect of visual relevance. From the human evaluator's viewpoint, a high-quality caption should be consistent with the provided video, but not necessarily be similar to the reference in literal or semantics. Inspired by human evaluation, we propose EMScore (Embedding Matching-based score), a novel reference-free metric for video captioning, which directly measures similarity between video and candidate captions. Benefit from the recent development of large-scale pre-training models, we exploit a well pre-trained vision-language model to extract visual and linguistic embeddings for computing EMScore. Specifically, EMScore combines matching scores of both coarse-grained (video and caption) and fine-grained (frames and words) levels, which takes the overall understanding and detailed characteristics of the video into account. Furthermore, considering the potential information gain, EMScore can be flexibly extended to the conditions where human-labeled references are available. Last but not least, we collect VATEX-EVAL and ActivityNet-FOIl datasets to systematically evaluate the existing metrics. VATEX-EVAL experiments demonstrate that EMScore has higher human correlation and lower reference dependency. ActivityNet-FOIL experiment verifies that EMScore can effectively identify "hallucinating" captions. The datasets will be released to facilitate the development of video captioning metrics. The code is available at: https://github.com/ShiYaya/emscore.
Towards the D-Optimal Online Experiment Design for Recommender Selection
Oct 23, 2021
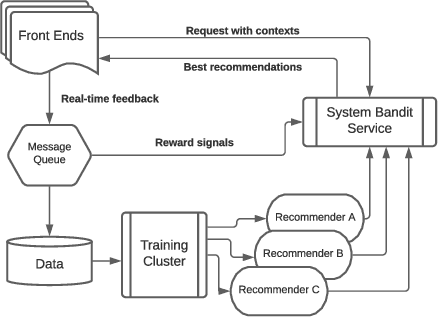
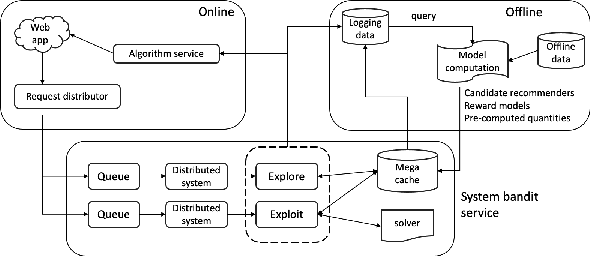
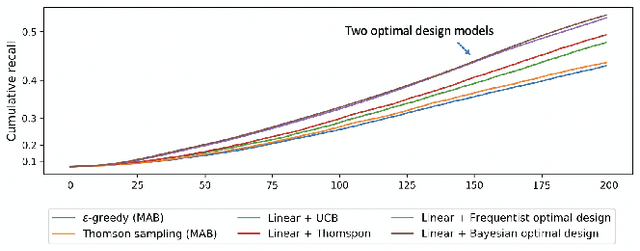
Selecting the optimal recommender via online exploration-exploitation is catching increasing attention where the traditional A/B testing can be slow and costly, and offline evaluations are prone to the bias of history data. Finding the optimal online experiment is nontrivial since both the users and displayed recommendations carry contextual features that are informative to the reward. While the problem can be formalized via the lens of multi-armed bandits, the existing solutions are found less satisfactorily because the general methodologies do not account for the case-specific structures, particularly for the e-commerce recommendation we study. To fill in the gap, we leverage the \emph{D-optimal design} from the classical statistics literature to achieve the maximum information gain during exploration, and reveal how it fits seamlessly with the modern infrastructure of online inference. To demonstrate the effectiveness of the optimal designs, we provide semi-synthetic simulation studies with published code and data for reproducibility purposes. We then use our deployment example on Walmart.com to fully illustrate the practical insights and effectiveness of the proposed methods.
Conditional Attention Networks for Distilling Knowledge Graphs in Recommendation
Nov 03, 2021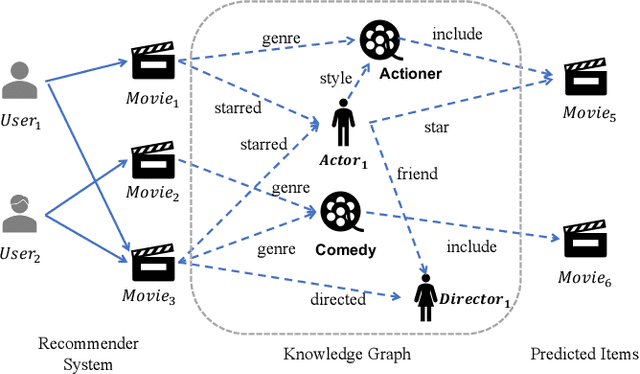
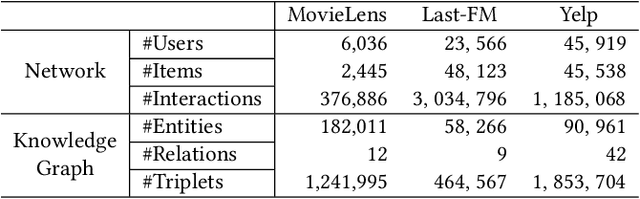
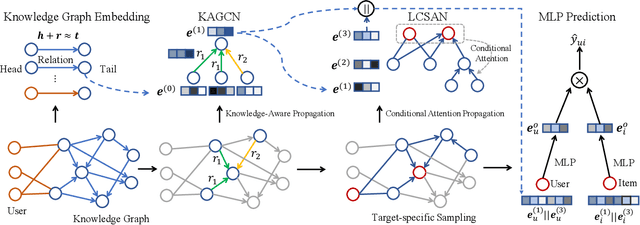
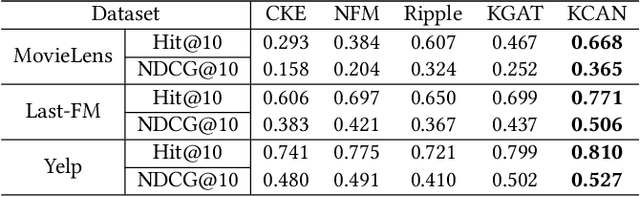
Knowledge graph is generally incorporated into recommender systems to improve overall performance. Due to the generalization and scale of the knowledge graph, most knowledge relationships are not helpful for a target user-item prediction. To exploit the knowledge graph to capture target-specific knowledge relationships in recommender systems, we need to distill the knowledge graph to reserve the useful information and refine the knowledge to capture the users' preferences. To address the issues, we propose Knowledge-aware Conditional Attention Networks (KCAN), which is an end-to-end model to incorporate knowledge graph into a recommender system. Specifically, we use a knowledge-aware attention propagation manner to obtain the node representation first, which captures the global semantic similarity on the user-item network and the knowledge graph. Then given a target, i.e., a user-item pair, we automatically distill the knowledge graph into the target-specific subgraph based on the knowledge-aware attention. Afterward, by applying a conditional attention aggregation on the subgraph, we refine the knowledge graph to obtain target-specific node representations. Therefore, we can gain both representability and personalization to achieve overall performance. Experimental results on real-world datasets demonstrate the effectiveness of our framework over the state-of-the-art algorithms.
Chinese Embedding via Stroke and Glyph Information: A Dual-channel View
Jun 03, 2019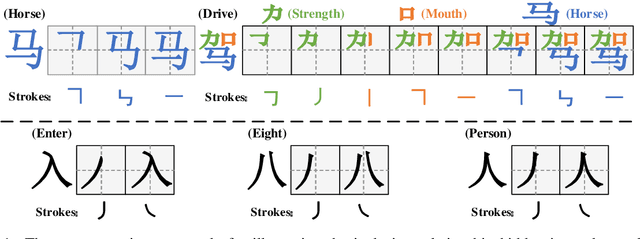
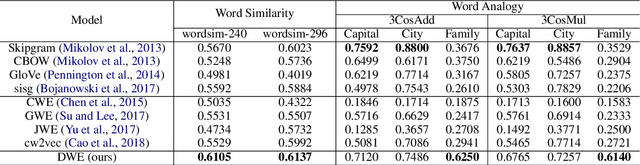
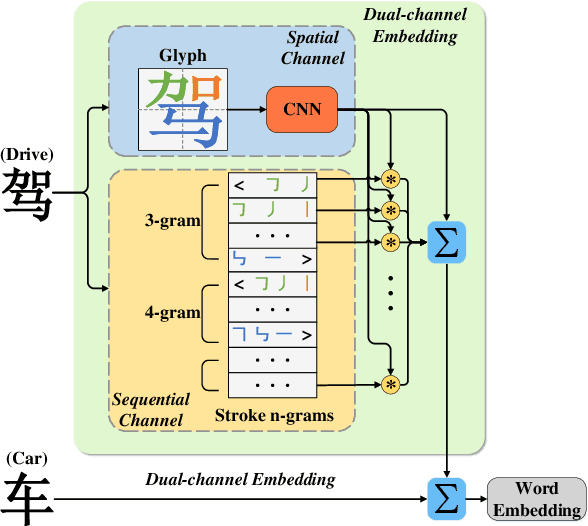
Recent studies have consistently given positive hints that morphology is helpful in enriching word embeddings. In this paper, we argue that Chinese word embeddings can be substantially enriched by the morphological information hidden in characters which is reflected not only in strokes order sequentially, but also in character glyphs spatially. Then, we propose a novel Dual-channel Word Embedding (DWE) model to realize the joint learning of sequential and spatial information of characters. Through the evaluation on both word similarity and word analogy tasks, our model shows its rationality and superiority in modelling the morphology of Chinese.
Semantic-Based Explainable AI: Leveraging Semantic Scene Graphs and Pairwise Ranking to Explain Robot Failures
Aug 08, 2021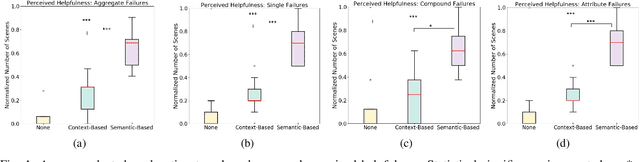
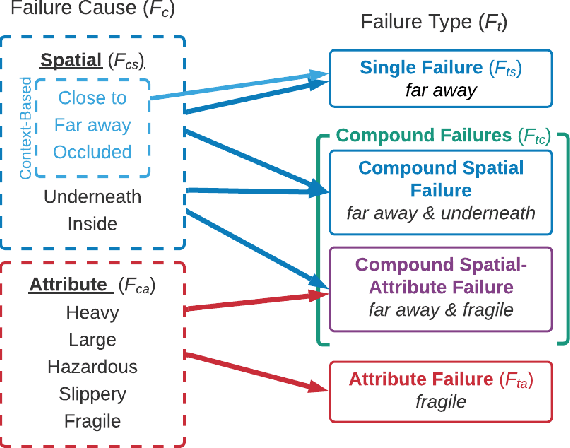
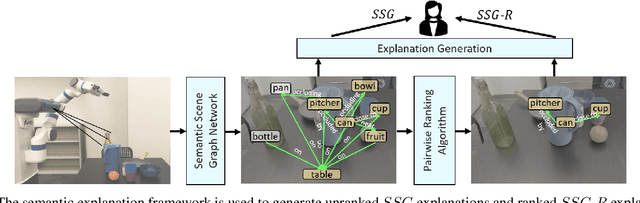
When interacting in unstructured human environments, occasional robot failures are inevitable. When such failures occur, everyday people, rather than trained technicians, will be the first to respond. Existing natural language explanations hand-annotate contextual information from an environment to help everyday people understand robot failures. However, this methodology lacks generalizability and scalability. In our work, we introduce a more generalizable semantic explanation framework. Our framework autonomously captures the semantic information in a scene to produce semantically descriptive explanations for everyday users. To generate failure-focused explanations that are semantically grounded, we leverages both semantic scene graphs to extract spatial relations and object attributes from an environment, as well as pairwise ranking. Our results show that these semantically descriptive explanations significantly improve everyday users' ability to both identify failures and provide assistance for recovery than the existing state-of-the-art context-based explanations.