 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Syntactic and Semantic-driven Learning for Open Information Extraction
Mar 05, 2021
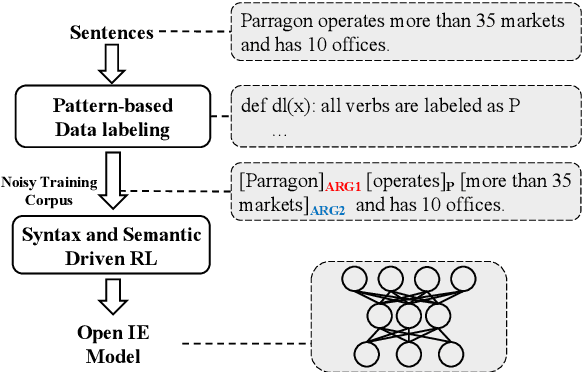
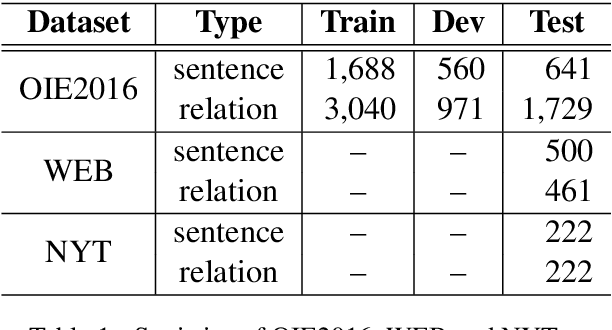

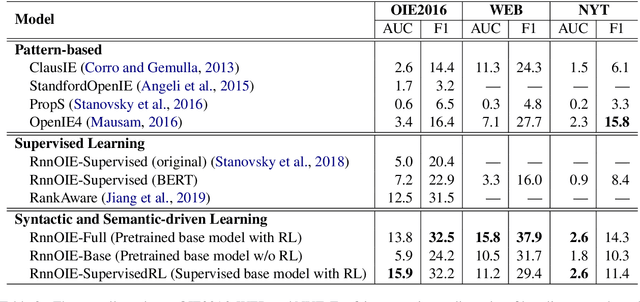
One of the biggest bottlenecks in building accurate, high coverage neural open IE systems is the need for large labelled corpora. The diversity of open domain corpora and the variety of natural language expressions further exacerbate this problem. In this paper, we propose a syntactic and semantic-driven learning approach, which can learn neural open IE models without any human-labelled data by leveraging syntactic and semantic knowledge as noisier, higher-level supervisions. Specifically, we first employ syntactic patterns as data labelling functions and pretrain a base model using the generated labels. Then we propose a syntactic and semantic-driven reinforcement learning algorithm, which can effectively generalize the base model to open situations with high accuracy. Experimental results show that our approach significantly outperforms the supervised counterparts, and can even achieve competitive performance to supervised state-of-the-art (SoA) model
* 11 pages
Who says like a style of Vitamin: Towards Syntax-Aware DialogueSummarization using Multi-task Learning
Sep 29, 2021
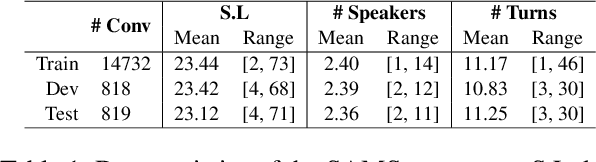
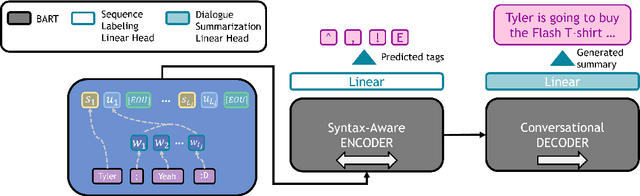
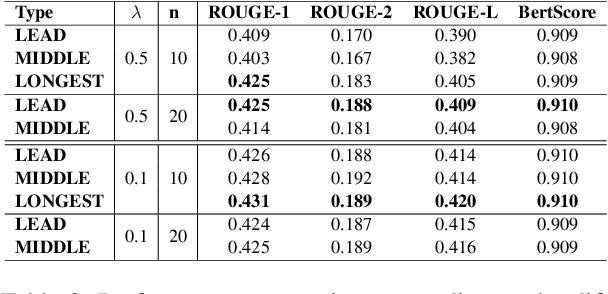
Abstractive dialogue summarization is a challenging task for several reasons. First, most of the important pieces of information in a conversation are scattered across utterances through multi-party interactions with different textual styles. Second, dialogues are often informal structures, wherein different individuals express personal perspectives, unlike text summarization, tasks that usually target formal documents such as news articles. To address these issues, we focused on the association between utterances from individual speakers and unique syntactic structures. Speakers have unique textual styles that can contain linguistic information, such as voiceprint. Therefore, we constructed a syntax-aware model by leveraging linguistic information (i.e., POS tagging), which alleviates the above issues by inherently distinguishing sentences uttered from individual speakers. We employed multi-task learning of both syntax-aware information and dialogue summarization. To the best of our knowledge, our approach is the first method to apply multi-task learning to the dialogue summarization task. Experiments on a SAMSum corpus (a large-scale dialogue summarization corpus) demonstrated that our method improved upon the vanilla model. We further analyze the costs and benefits of our approach relative to baseline models.
Function Computation Under Privacy, Secrecy, Distortion, and Communication Constraints
Jan 11, 2022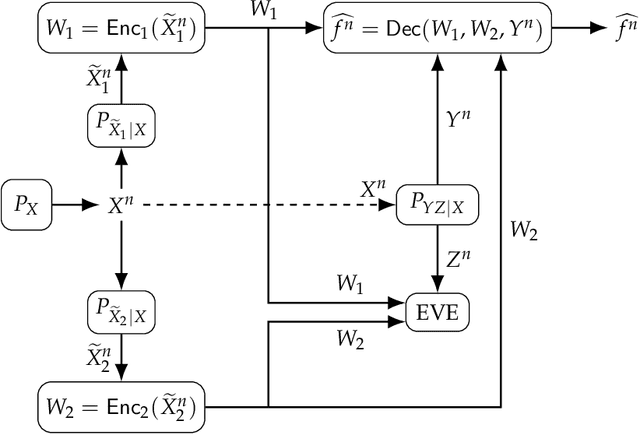
The problem of reliable function computation is extended by imposing privacy, secrecy, and storage constraints on a remote source whose noisy measurements are observed by multiple parties. The main additions to the classic function computation problem include 1) privacy leakage to an eavesdropper is measured with respect to the remote source rather than the transmitting terminals' observed sequences; 2) the information leakage to a fusion center with respect to the remote source is considered as a new privacy leakage metric; 3) the function computed is allowed to be a distorted version of the target function, which allows to reduce the storage rate as compared to a reliable function computation scenario in addition to reducing secrecy and privacy leakages; 4) two transmitting node observations are used to compute a function. Inner and outer bounds on the rate regions are derived for lossless and lossy single-function computation with two transmitting nodes, which recover previous results in the literature. For special cases that include invertible and partially-invertible functions, and degraded measurement channels, exact lossless and lossy rate regions are characterized, and one exact region is evaluated for an example scenario.
CMA-CLIP: Cross-Modality Attention CLIP for Image-Text Classification
Dec 07, 2021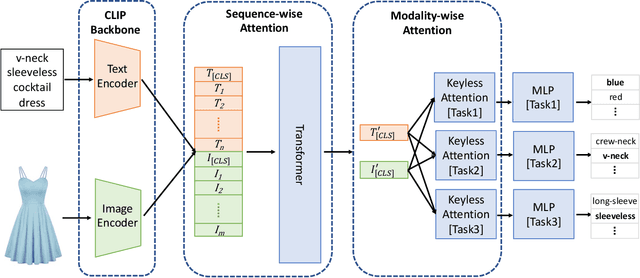

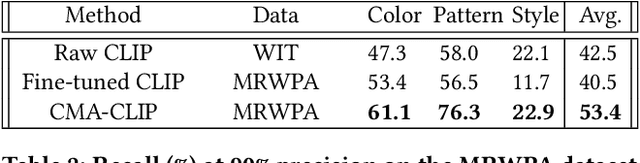

Modern Web systems such as social media and e-commerce contain rich contents expressed in images and text. Leveraging information from multi-modalities can improve the performance of machine learning tasks such as classification and recommendation. In this paper, we propose the Cross-Modality Attention Contrastive Language-Image Pre-training (CMA-CLIP), a new framework which unifies two types of cross-modality attentions, sequence-wise attention and modality-wise attention, to effectively fuse information from image and text pairs. The sequence-wise attention enables the framework to capture the fine-grained relationship between image patches and text tokens, while the modality-wise attention weighs each modality by its relevance to the downstream tasks. In addition, by adding task specific modality-wise attentions and multilayer perceptrons, our proposed framework is capable of performing multi-task classification with multi-modalities. We conduct experiments on a Major Retail Website Product Attribute (MRWPA) dataset and two public datasets, Food101 and Fashion-Gen. The results show that CMA-CLIP outperforms the pre-trained and fine-tuned CLIP by an average of 11.9% in recall at the same level of precision on the MRWPA dataset for multi-task classification. It also surpasses the state-of-the-art method on Fashion-Gen Dataset by 5.5% in accuracy and achieves competitive performance on Food101 Dataset. Through detailed ablation studies, we further demonstrate the effectiveness of both cross-modality attention modules and our method's robustness against noise in image and text inputs, which is a common challenge in practice.
Information-Theoretic Generalization Bounds for SGLD via Data-Dependent Estimates
Nov 06, 2019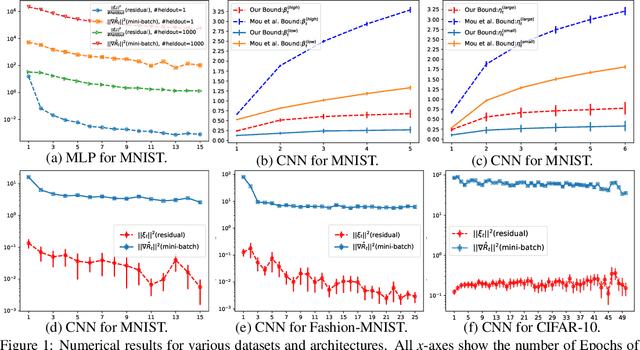
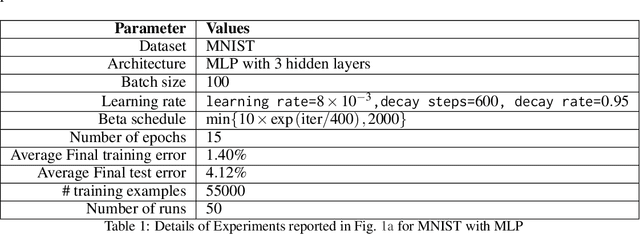

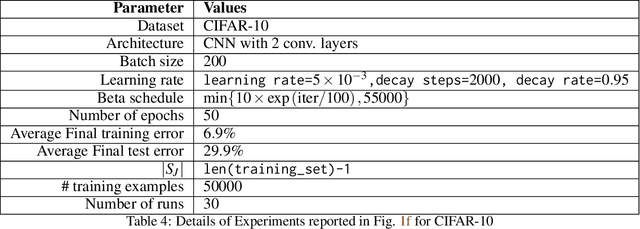
In this work, we improve upon the stepwise analysis of noisy iterative learning algorithms initiated by Pensia, Jog, and Loh (2018) and recently extended by Bu, Zou, and Veeravalli (2019). Our main contributions are significantly improved mutual information bounds for Stochastic Gradient Langevin Dynamics via data-dependent estimates. Our approach is based on the variational characterization of mutual information and the use of data-dependent priors that forecast the mini-batch gradient based on a subset of the training samples. Our approach is broadly applicable within the information-theoretic framework of Russo and Zou (2015) and Xu and Raginsky (2017). Our bound can be tied to a measure of flatness of the empirical risk surface. As compared with other bounds that depend on the squared norms of gradients, empirical investigations show that the terms in our bounds are orders of magnitude smaller.
Geometry-Entangled Visual Semantic Transformer for Image Captioning
Sep 29, 2021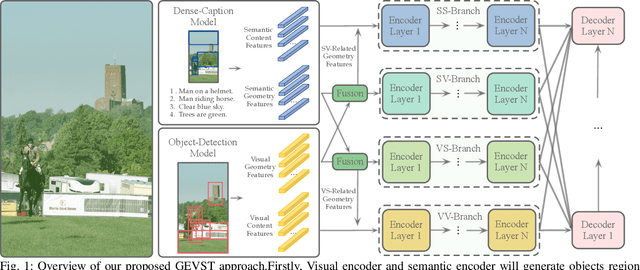
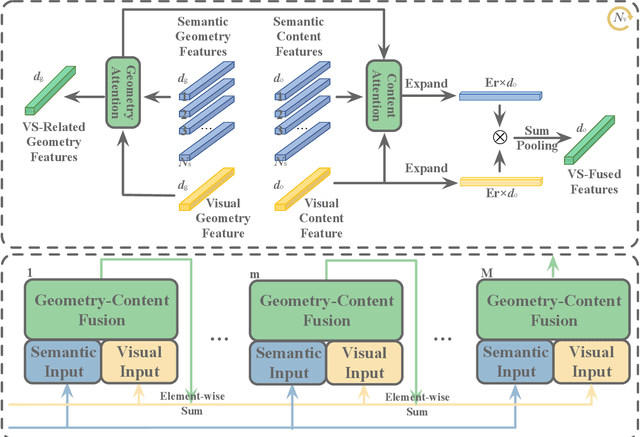
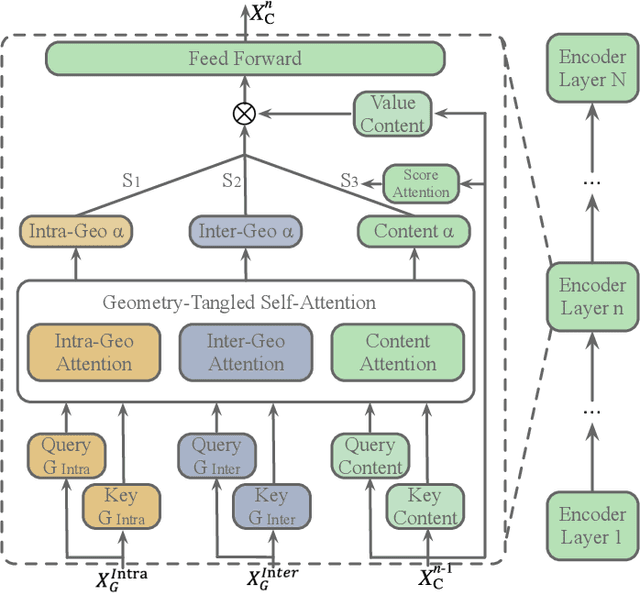
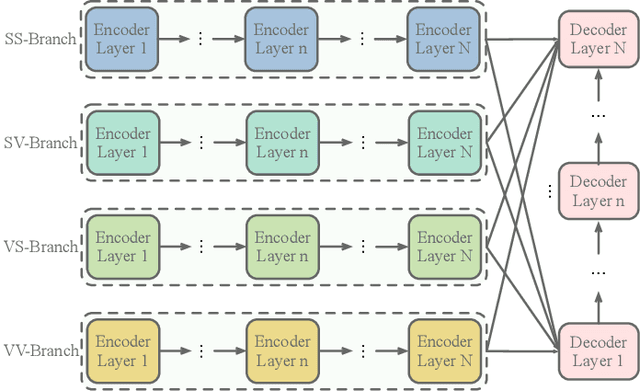
Recent advancements of image captioning have featured Visual-Semantic Fusion or Geometry-Aid attention refinement. However, those fusion-based models, they are still criticized for the lack of geometry information for inter and intra attention refinement. On the other side, models based on Geometry-Aid attention still suffer from the modality gap between visual and semantic information. In this paper, we introduce a novel Geometry-Entangled Visual Semantic Transformer (GEVST) network to realize the complementary advantages of Visual-Semantic Fusion and Geometry-Aid attention refinement. Concretely, a Dense-Cap model proposes some dense captions with corresponding geometry information at first. Then, to empower GEVST with the ability to bridge the modality gap among visual and semantic information, we build four parallel transformer encoders VV(Pure Visual), VS(Semantic fused to Visual), SV(Visual fused to Semantic), SS(Pure Semantic) for final caption generation. Both visual and semantic geometry features are used in the Fusion module and also the Self-Attention module for better attention measurement. To validate our model, we conduct extensive experiments on the MS-COCO dataset, the experimental results show that our GEVST model can obtain promising performance gains.
Class-Aware Generative Adversarial Transformers for Medical Image Segmentation
Jan 28, 2022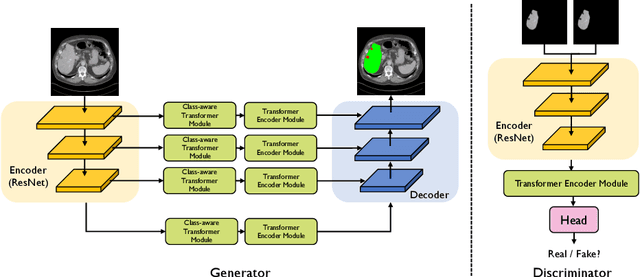
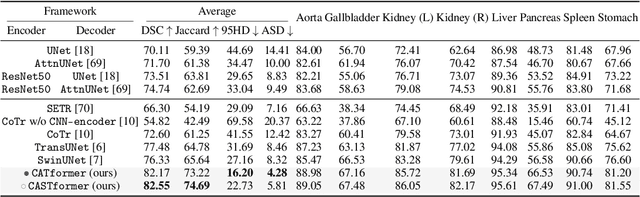
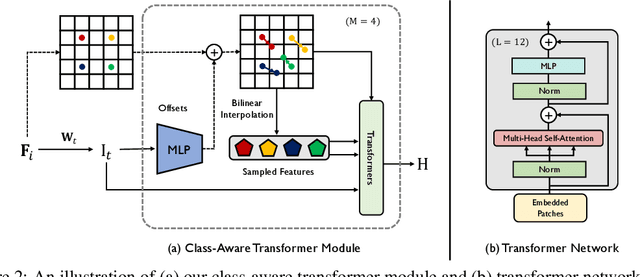
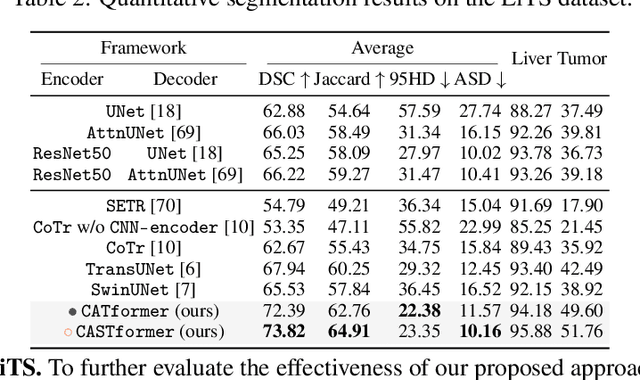
Transformers have made remarkable progress towards modeling long-range dependencies within the medical image analysis domain. However, current transformer-based models suffer from several disadvantages: (1) existing methods fail to capture the important features of the images due to the naive tokenization scheme; (2) the models suffer from information loss because they only consider single-scale feature representations; and (3) the segmentation label maps generated by the models are not accurate enough without considering rich semantic contexts and anatomical textures. In this work, we present CA-GANformer, a novel type of generative adversarial transformers, for medical image segmentation. First, we take advantage of the pyramid structure to construct multi-scale representations and handle multi-scale variations. We then design a novel class-aware transformer module to better learn the discriminative regions of objects with semantic structures. Lastly, we utilize an adversarial training strategy that boosts segmentation accuracy and correspondingly allows a transformer-based discriminator to capture high-level semantically correlated contents and low-level anatomical features. Our experiments demonstrate that CA-GANformer dramatically outperforms previous state-of-the-art transformer-based approaches on three benchmarks, obtaining 2.54%-5.88% absolute improvements in Dice over previous models. Further qualitative experiments provide a more detailed picture of the model's inner workings, shed light on the challenges in improved transparency, and demonstrate that transfer learning can greatly improve performance and reduce the size of medical image datasets in training, making CA-GANformer a strong starting point for downstream medical image analysis tasks. Codes and models will be available to the public.
Global-Local Attention for Emotion Recognition
Nov 07, 2021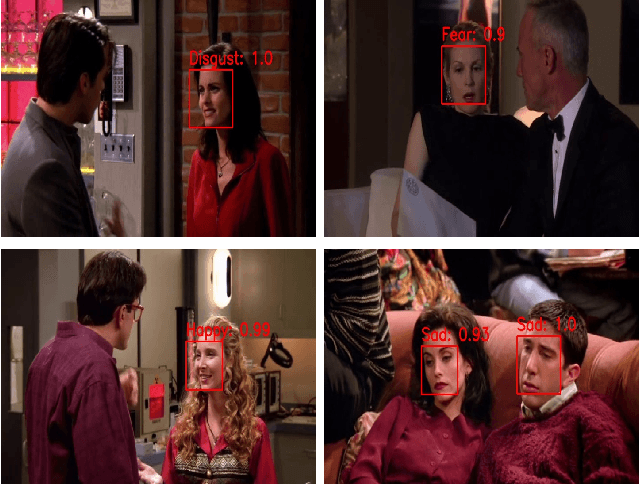
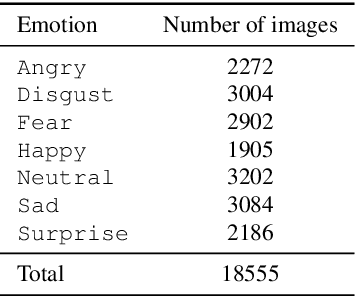
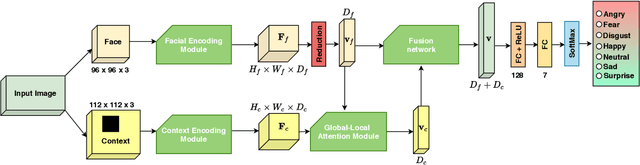
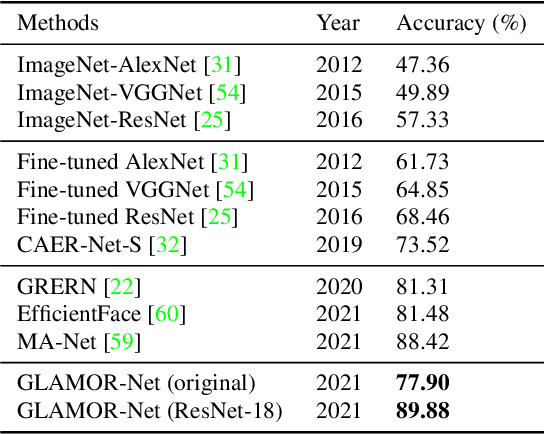
Human emotion recognition is an active research area in artificial intelligence and has made substantial progress over the past few years. Many recent works mainly focus on facial regions to infer human affection, while the surrounding context information is not effectively utilized. In this paper, we proposed a new deep network to effectively recognize human emotions using a novel global-local attention mechanism. Our network is designed to extract features from both facial and context regions independently, then learn them together using the attention module. In this way, both the facial and contextual information is used to infer human emotions, therefore enhancing the discrimination of the classifier. The intensive experiments show that our method surpasses the current state-of-the-art methods on recent emotion datasets by a fair margin. Qualitatively, our global-local attention module can extract more meaningful attention maps than previous methods. The source code and trained model of our network are available at https://github.com/minhnhatvt/glamor-net
IKEA Object State Dataset: A 6DoF object pose estimation dataset and benchmark for multi-state assembly objects
Nov 16, 2021


Utilizing 6DoF(Degrees of Freedom) pose information of an object and its components is critical for object state detection tasks. We present IKEA Object State Dataset, a new dataset that contains IKEA furniture 3D models, RGBD video of the assembly process, the 6DoF pose of furniture parts and their bounding box. The proposed dataset will be available at https://github.com/mxllmx/IKEAObjectStateDataset.
A Robust Matching Pursuit Algorithm Using Information Theoretic Learning
May 10, 2020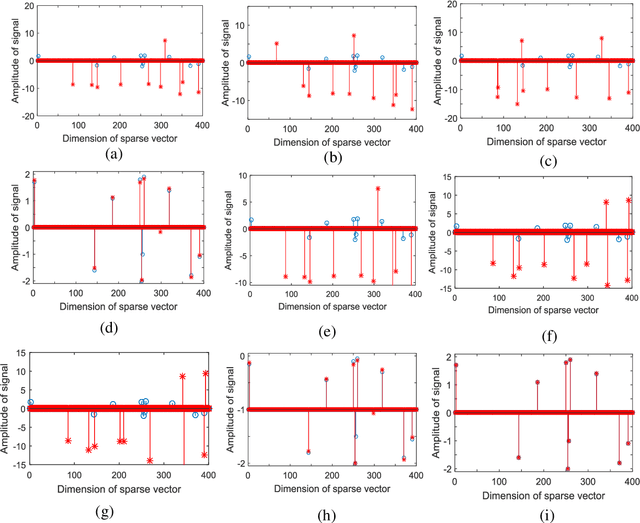
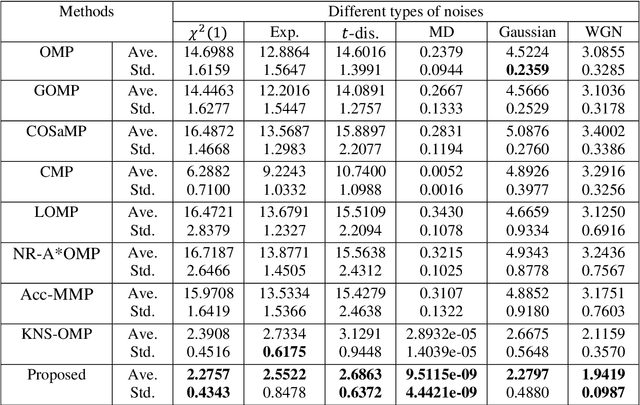
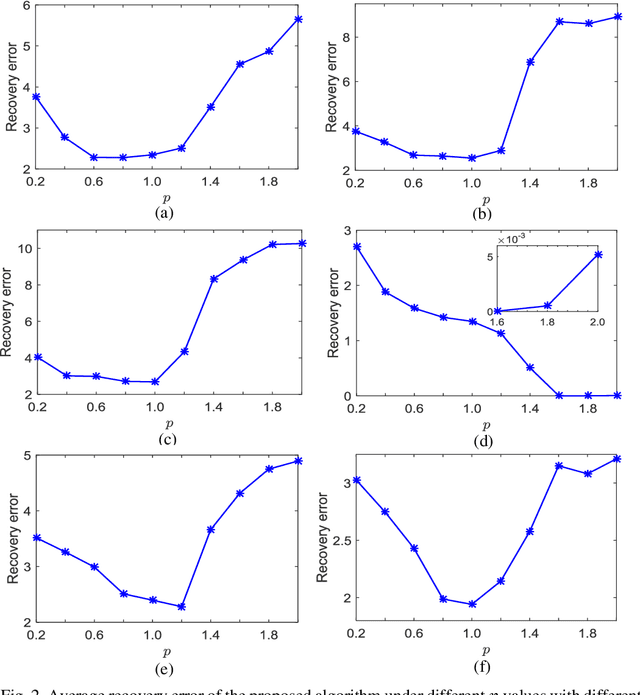
Current orthogonal matching pursuit (OMP) algorithms calculate the correlation between two vectors using the inner product operation and minimize the mean square error, which are both suboptimal when there are non-Gaussian noises or outliers in the observation data. To overcome these problems, a new OMP algorithm is developed based on the information theoretic learning (ITL), which is built on the following new techniques: (1) an ITL-based correlation (ITL-Correlation) is developed as a new similarity measure which can better exploit higher-order statistics of the data, and is robust against many different types of noise and outliers in a sparse representation framework; (2) a non-second order statistic measurement and minimization method is developed to improve the robustness of OMP by overcoming the limitation of Gaussianity inherent in cost function based on second-order moments. The experimental results on both simulated and real-world data consistently demonstrate the superiority of the proposed OMP algorithm in data recovery, image reconstruction, and classification.