 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsuring Safety in Automated Mechanical Ventilation through Offline Reinforcement Learning and Digital Twin Verification
Mar 11, 2026Mechanical ventilation (MV) is a life-saving intervention for patients with acute respiratory failure (ARF) in the ICU. However, inappropriate ventilator settings could cause ventilator-induced lung injury (VILI). Also, clinicians workload is shown to be directly linked to patient outcomes. Hence, MV should be personalized and automated to improve patient outcomes. Previous attempts to incorporate personalization and automation in MV include traditional supervised learning and offline reinforcement learning (RL) approaches, which often neglect temporal dependencies and rely excessively on mortality-based rewards. As a result, early stage physiological deterioration and the risk of VILI are not adequately captured. To address these limitations, we propose Transformer-based Conservative Q-Learning (T-CQL), a novel offline RL framework that integrates a Transformer encoder for effective temporal modeling of patient dynamics, conservative adaptive regularization based on uncertainty quantification to ensure safety, and consistency regularization for robust decision-making. We build a clinically informed reward function that incorporates indicators of VILI and a score for severity of patients illness. Also, previous work predominantly uses Fitted Q-Evaluation (FQE) for RL policy evaluation on static offline data, which is less responsive to dynamic environmental changes and susceptible to distribution shifts. To overcome these evaluation limitations, interactive digital twins of ARF patients were used for online "at the bedside" evaluation. Our results demonstrate that T-CQL consistently outperforms existing state-of-the-art offline RL methodologies, providing safer and more effective ventilatory adjustments. Our framework demonstrates the potential of Transformer-based models combined with conservative RL strategies as a decision support tool in critical care.
Heteroscedastic Bayesian Optimization-Based Dynamic PID Tuning for Accurate and Robust UAV Trajectory Tracking
Dec 30, 2025Unmanned Aerial Vehicles (UAVs) play an important role in various applications, where precise trajectory tracking is crucial. However, conventional control algorithms for trajectory tracking often exhibit limited performance due to the underactuated, nonlinear, and highly coupled dynamics of quadrotor systems. To address these challenges, we propose HBO-PID, a novel control algorithm that integrates the Heteroscedastic Bayesian Optimization (HBO) framework with the classical PID controller to achieve accurate and robust trajectory tracking. By explicitly modeling input-dependent noise variance, the proposed method can better adapt to dynamic and complex environments, and therefore improve the accuracy and robustness of trajectory tracking. To accelerate the convergence of optimization, we adopt a two-stage optimization strategy that allow us to more efficiently find the optimal controller parameters. Through experiments in both simulation and real-world scenarios, we demonstrate that the proposed method significantly outperforms state-of-the-art (SOTA) methods. Compared to SOTA methods, it improves the position accuracy by 24.7% to 42.9%, and the angular accuracy by 40.9% to 78.4%.
* Accepted by IROS 2025 (2025 IEEE/RSJ International Conference on Intelligent Robots and Systems)
Temporal-Consistent Video Restoration with Pre-trained Diffusion Models
Mar 19, 2025
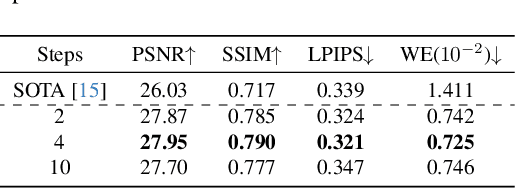
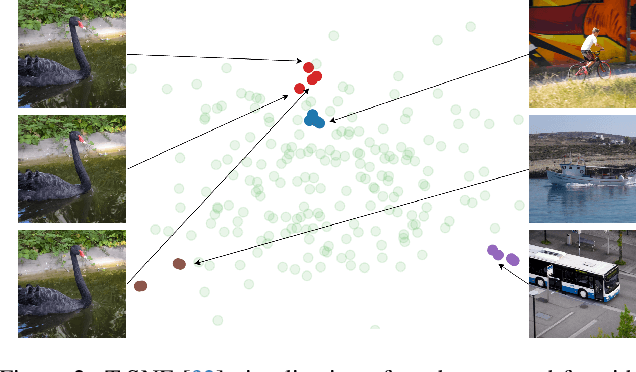
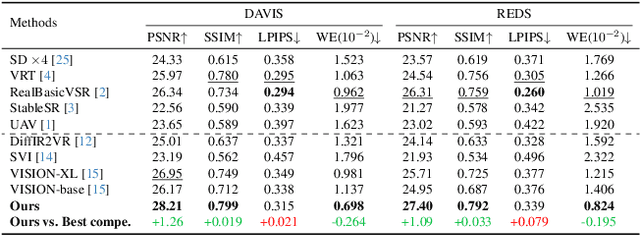
Video restoration (VR) aims to recover high-quality videos from degraded ones. Although recent zero-shot VR methods using pre-trained diffusion models (DMs) show good promise, they suffer from approximation errors during reverse diffusion and insufficient temporal consistency. Moreover, dealing with 3D video data, VR is inherently computationally intensive. In this paper, we advocate viewing the reverse process in DMs as a function and present a novel Maximum a Posterior (MAP) framework that directly parameterizes video frames in the seed space of DMs, eliminating approximation errors. We also introduce strategies to promote bilevel temporal consistency: semantic consistency by leveraging clustering structures in the seed space, and pixel-level consistency by progressive warping with optical flow refinements. Extensive experiments on multiple virtual reality tasks demonstrate superior visual quality and temporal consistency achieved by our method compared to the state-of-the-art.
Hierarchical Conditional Semi-Paired Image-to-Image Translation For Multi-Task Image Defect Correction On Shopping Websites
Sep 12, 2023On shopping websites, product images of low quality negatively affect customer experience. Although there are plenty of work in detecting images with different defects, few efforts have been dedicated to correct those defects at scale. A major challenge is that there are thousands of product types and each has specific defects, therefore building defect specific models is unscalable. In this paper, we propose a unified Image-to-Image (I2I) translation model to correct multiple defects across different product types. Our model leverages an attention mechanism to hierarchically incorporate high-level defect groups and specific defect types to guide the network to focus on defect-related image regions. Evaluated on eight public datasets, our model reduces the Frechet Inception Distance (FID) by 24.6% in average compared with MoNCE, the state-of-the-art I2I method. Unlike public data, another practical challenge on shopping websites is that some paired images are of low quality. Therefore we design our model to be semi-paired by combining the L1 loss of paired data with the cycle loss of unpaired data. Tested on a shopping website dataset to correct three image defects, our model reduces (FID) by 63.2% in average compared with WS-I2I, the state-of-the art semi-paired I2I method.
Token Sparsification for Faster Medical Image Segmentation
Mar 11, 2023



Can we use sparse tokens for dense prediction, e.g., segmentation? Although token sparsification has been applied to Vision Transformers (ViT) to accelerate classification, it is still unknown how to perform segmentation from sparse tokens. To this end, we reformulate segmentation as a sparse encoding -> token completion -> dense decoding (SCD) pipeline. We first empirically show that naively applying existing approaches from classification token pruning and masked image modeling (MIM) leads to failure and inefficient training caused by inappropriate sampling algorithms and the low quality of the restored dense features. In this paper, we propose Soft-topK Token Pruning (STP) and Multi-layer Token Assembly (MTA) to address these problems. In sparse encoding, STP predicts token importance scores with a lightweight sub-network and samples the topK tokens. The intractable topK gradients are approximated through a continuous perturbed score distribution. In token completion, MTA restores a full token sequence by assembling both sparse output tokens and pruned multi-layer intermediate ones. The last dense decoding stage is compatible with existing segmentation decoders, e.g., UNETR. Experiments show SCD pipelines equipped with STP and MTA are much faster than baselines without token pruning in both training (up to 120% higher throughput and inference up to 60.6% higher throughput) while maintaining segmentation quality.
Self Pre-training with Masked Autoencoders for Medical Image Analysis
Mar 10, 2022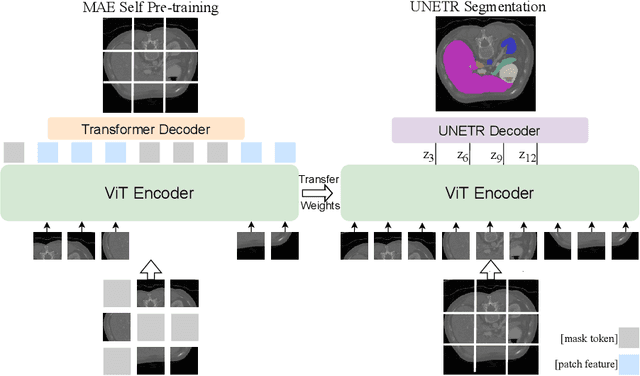
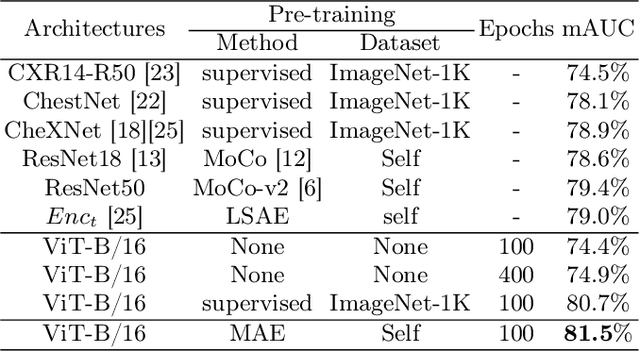
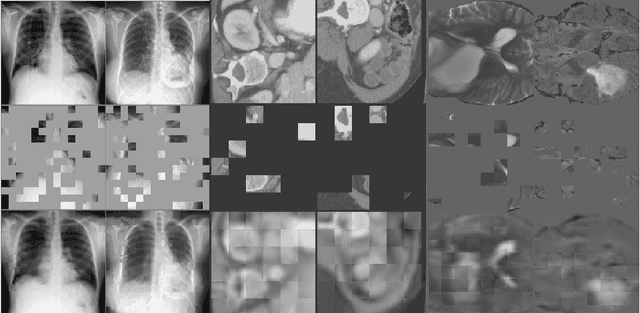
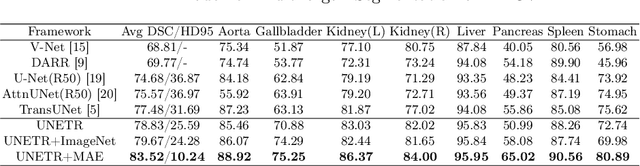
Masked Autoencoder (MAE) has recently been shown to be effective in pre-training Vision Transformers (ViT) for natural image analysis. By performing the pretext task of reconstructing the original image from only partial observations, the encoder, which is a ViT, is encouraged to aggregate contextual information to infer content in masked image regions. We believe that this context aggregation ability is also essential to the medical image domain where each anatomical structure is functionally and mechanically connected to other structures and regions. However, there is no ImageNet-scale medical image dataset for pre-training. Thus, in this paper, we investigate a self pre-training paradigm with MAE for medical images, i.e., models are pre-trained on the same target dataset. To validate the MAE self pre-training, we consider three diverse medical image tasks including chest X-ray disease classification, CT abdomen multi-organ segmentation and MRI brain tumor segmentation. It turns out MAE self pre-training benefits all the tasks markedly. Specifically, the mAUC on lung disease classification is increased by 9.4%. The average DSC on brain tumor segmentation is improved from 77.4% to 78.9%. Most interestingly, on the small-scale multi-organ segmentation dataset (N=30), the average DSC improves from 78.8% to 83.5% and the HD95 is reduced by 60%, indicating its effectiveness in limited data scenarios. The segmentation and classification results reveal the promising potential of MAE self pre-training for medical image analysis.
Lung Swapping Autoencoder: Learning a Disentangled Structure-texture Representation of Chest Radiographs
Jan 18, 2022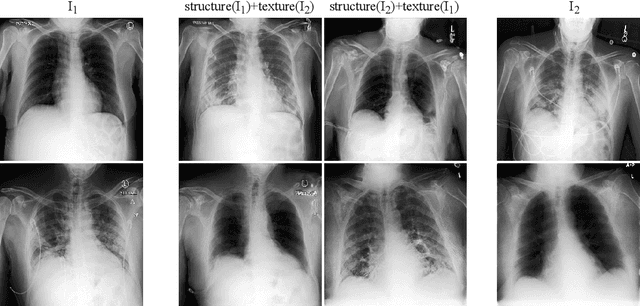

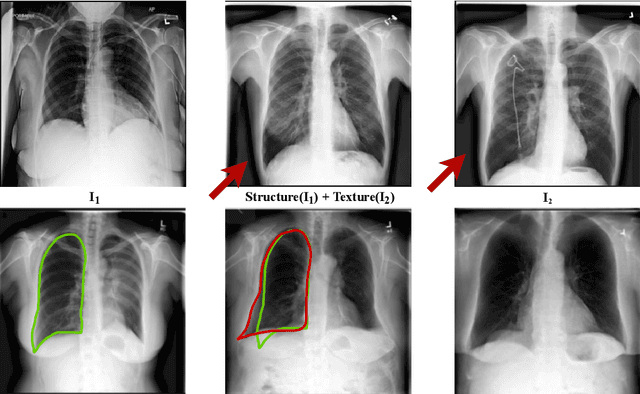
Well-labeled datasets of chest radiographs (CXRs) are difficult to acquire due to the high cost of annotation. Thus, it is desirable to learn a robust and transferable representation in an unsupervised manner to benefit tasks that lack labeled data. Unlike natural images, medical images have their own domain prior; e.g., we observe that many pulmonary diseases, such as the COVID-19, manifest as changes in the lung tissue texture rather than the anatomical structure. Therefore, we hypothesize that studying only the texture without the influence of structure variations would be advantageous for downstream prognostic and predictive modeling tasks. In this paper, we propose a generative framework, the Lung Swapping Autoencoder (LSAE), that learns factorized representations of a CXR to disentangle the texture factor from the structure factor. Specifically, by adversarial training, the LSAE is optimized to generate a hybrid image that preserves the lung shape in one image but inherits the lung texture of another. To demonstrate the effectiveness of the disentangled texture representation, we evaluate the texture encoder $Enc^t$ in LSAE on ChestX-ray14 (N=112,120), and our own multi-institutional COVID-19 outcome prediction dataset, COVOC (N=340 (Subset-1) + 53 (Subset-2)). On both datasets, we reach or surpass the state-of-the-art by finetuning $Enc^t$ in LSAE that is 77% smaller than a baseline Inception v3. Additionally, in semi-and-self supervised settings with a similar model budget, $Enc^t$ in LSAE is also competitive with the state-of-the-art MoCo. By "re-mixing" the texture and shape factors, we generate meaningful hybrid images that can augment the training set. This data augmentation method can further improve COVOC prediction performance. The improvement is consistent even when we directly evaluate the Subset-1 trained model on Subset-2 without any fine-tuning.
CMA-CLIP: Cross-Modality Attention CLIP for Image-Text Classification
Dec 09, 2021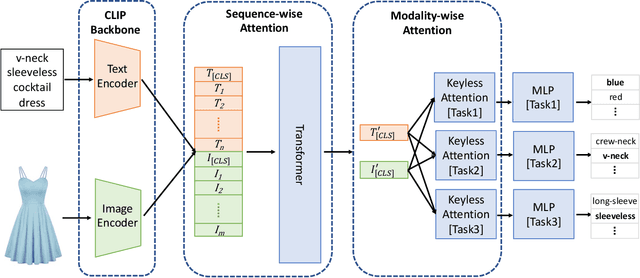

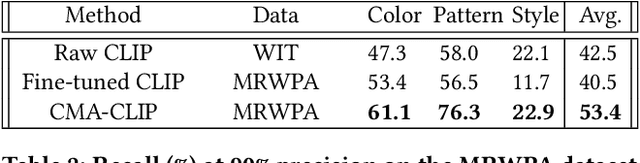

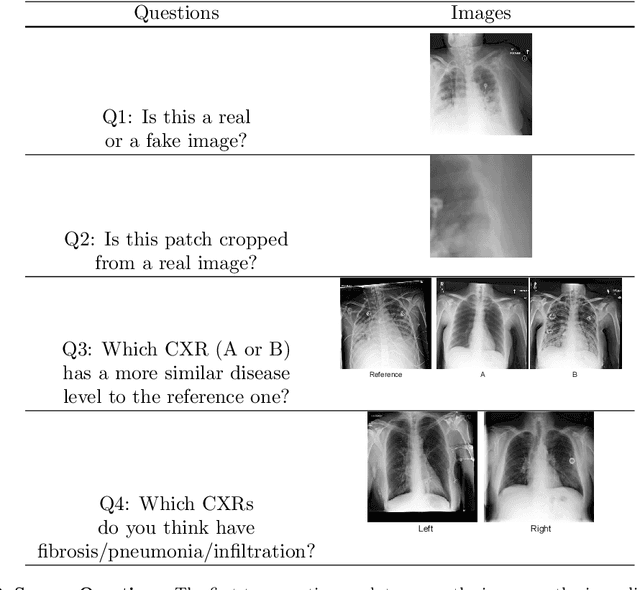
Modern Web systems such as social media and e-commerce contain rich contents expressed in images and text. Leveraging information from multi-modalities can improve the performance of machine learning tasks such as classification and recommendation. In this paper, we propose the Cross-Modality Attention Contrastive Language-Image Pre-training (CMA-CLIP), a new framework which unifies two types of cross-modality attentions, sequence-wise attention and modality-wise attention, to effectively fuse information from image and text pairs. The sequence-wise attention enables the framework to capture the fine-grained relationship between image patches and text tokens, while the modality-wise attention weighs each modality by its relevance to the downstream tasks. In addition, by adding task specific modality-wise attentions and multilayer perceptrons, our proposed framework is capable of performing multi-task classification with multi-modalities. We conduct experiments on a Major Retail Website Product Attribute (MRWPA) dataset and two public datasets, Food101 and Fashion-Gen. The results show that CMA-CLIP outperforms the pre-trained and fine-tuned CLIP by an average of 11.9% in recall at the same level of precision on the MRWPA dataset for multi-task classification. It also surpasses the state-of-the-art method on Fashion-Gen Dataset by 5.5% in accuracy and achieves competitive performance on Food101 Dataset. Through detailed ablation studies, we further demonstrate the effectiveness of both cross-modality attention modules and our method's robustness against noise in image and text inputs, which is a common challenge in practice.
Training Federated GANs with Theoretical Guarantees: A Universal Aggregation Approach
Feb 09, 2021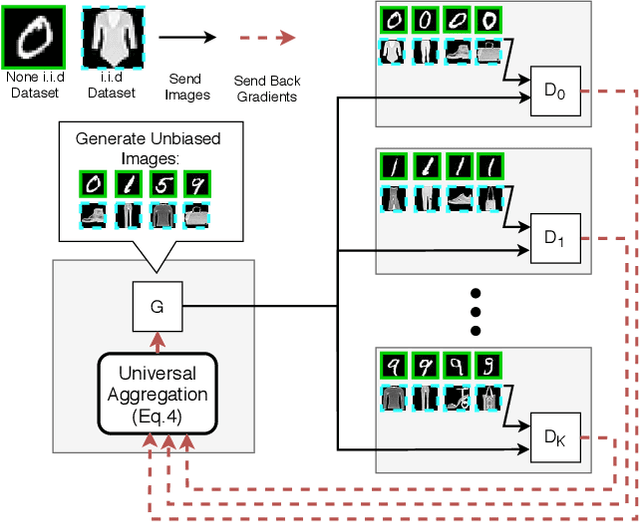
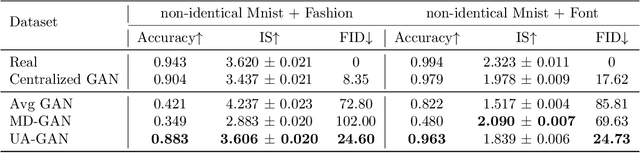
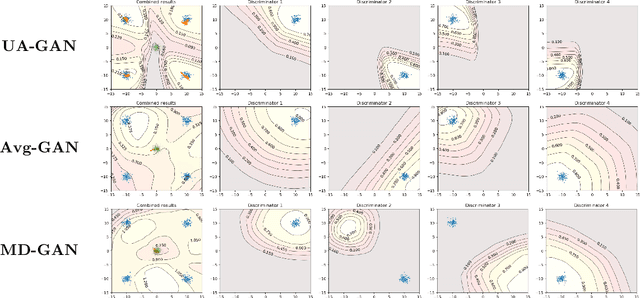
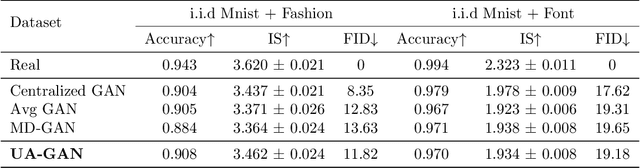
Recently, Generative Adversarial Networks (GANs) have demonstrated their potential in federated learning, i.e., learning a centralized model from data privately hosted by multiple sites. A federatedGAN jointly trains a centralized generator and multiple private discriminators hosted at different sites. A major theoretical challenge for the federated GAN is the heterogeneity of the local data distributions. Traditional approaches cannot guarantee to learn the target distribution, which isa mixture of the highly different local distributions. This paper tackles this theoretical challenge, and for the first time, provides a provably correct framework for federated GAN. We propose a new approach called Universal Aggregation, which simulates a centralized discriminator via carefully aggregating the mixture of all private discriminators. We prove that a generator trained with this simulated centralized discriminator can learn the desired target distribution. Through synthetic and real datasets, we show that our method can learn the mixture of largely different distributions where existing federated GAN methods fail.
Distribution Matching for Crowd Counting
Oct 25, 2020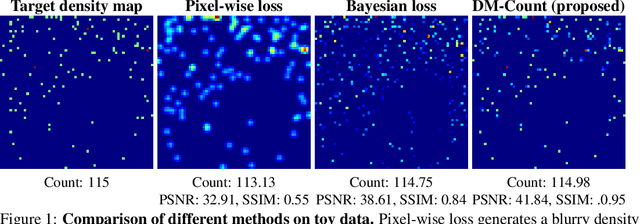
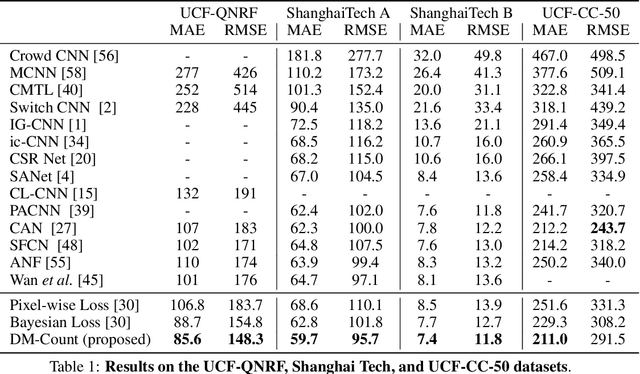
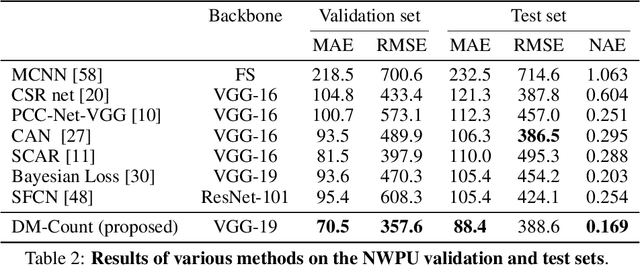

In crowd counting, each training image contains multiple people, where each person is annotated by a dot. Existing crowd counting methods need to use a Gaussian to smooth each annotated dot or to estimate the likelihood of every pixel given the annotated point. In this paper, we show that imposing Gaussians to annotations hurts generalization performance. Instead, we propose to use Distribution Matching for crowd COUNTing (DM-Count). In DM-Count, we use Optimal Transport (OT) to measure the similarity between the normalized predicted density map and the normalized ground truth density map. To stabilize OT computation, we include a Total Variation loss in our model. We show that the generalization error bound of DM-Count is tighter than that of the Gaussian smoothed methods. In terms of Mean Absolute Error, DM-Count outperforms the previous state-of-the-art methods by a large margin on two large-scale counting datasets, UCF-QNRF and NWPU, and achieves the state-of-the-art results on the ShanghaiTech and UCF-CC50 datasets. DM-Count reduced the error of the state-of-the-art published result by approximately 16%. Code is available at https://github.com/cvlab-stonybrook/DM-Count.