 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-Distribution Prediction with Quantile Tokens and Neighbor Context
Apr 22, 2026Many applications of LLM-based text regression require predicting a full conditional distribution rather than a single point value. We study distributional regression under empirical-quantile supervision, where each input is paired with multiple observed quantile outcomes, and the target distribution is represented by a dense grid of quantiles. We address two key limitations of current approaches: the lack of local grounding for distribution estimates, and the reliance on shared representations that create an indirect bottleneck between inputs and quantile outputs. In this paper, we introduce Quantile Token Regression, which, to our knowledge, is the first work to insert dedicated quantile tokens into the input sequence, enabling direct input-output pathways for each quantile through self-attention. We further augment these quantile tokens with retrieval, incorporating semantically similar neighbor instances and their empirical distributions to ground predictions with local evidence from similar instances. We also provide the first theoretical analysis of loss functions for quantile regression, clarifying which distributional objectives each optimizes. Experiments on the Inside Airbnb and StackSample benchmark datasets with LLMs ranging from 1.7B to 14B parameters show that quantile tokens with neighbors consistently outperform baselines (~4 points lower MAPE and 2x narrower prediction intervals), with especially large gains on smaller and more challenging datasets where quantile tokens produce substantially sharper and more accurate distributions.
Vidmento: Creating Video Stories Through Context-Aware Expansion With Generative Video
Jan 29, 2026Video storytelling is often constrained by available material, limiting creative expression and leaving undesired narrative gaps. Generative video offers a new way to address these limitations by augmenting captured media with tailored visuals. To explore this potential, we interviewed eight video creators to identify opportunities and challenges in integrating generative video into their workflows. Building on these insights and established filmmaking principles, we developed Vidmento, a tool for authoring hybrid video stories that combine captured and generated media through context-aware expansion. Vidmento surfaces opportunities for story development, generates clips that blend stylistically and narratively with surrounding media, and provides controls for refinement. In a study with 12 creators, Vidmento supported narrative development and exploration by systematically expanding initial materials with generative media, enabling expressive video storytelling aligned with creative intent. We highlight how creators bridge story gaps with generative content and where they find this blending capability most valuable.
VidTune: Creating Video Soundtracks with Generative Music and Contextual Thumbnails
Jan 17, 2026Music shapes the tone of videos, yet creators often struggle to find soundtracks that match their video's mood and narrative. Recent text-to-music models let creators generate music from text prompts, but our formative study (N=8) shows creators struggle to construct diverse prompts, quickly review and compare tracks, and understand their impact on the video. We present VidTune, a system that supports soundtrack creation by generating diverse music options from a creator's prompt and producing contextual thumbnails for rapid review. VidTune extracts representative video subjects to ground thumbnails in context, maps each track's valence and energy onto visual cues like color and brightness, and depicts prominent genres and instruments. Creators can refine tracks through natural language edits, which VidTune expands into new generations. In a controlled user study (N=12) and an exploratory case study (N=6), participants found VidTune helpful for efficiently reviewing and comparing music options and described the process as playful and enriching.
Multi-Agent Retrieval-Augmented Framework for Evidence-Based Counterspeech Against Health Misinformation
Jul 09, 2025Large language models (LLMs) incorporated with Retrieval-Augmented Generation (RAG) have demonstrated powerful capabilities in generating counterspeech against misinformation. However, current studies rely on limited evidence and offer less control over final outputs. To address these challenges, we propose a Multi-agent Retrieval-Augmented Framework to generate counterspeech against health misinformation, incorporating multiple LLMs to optimize knowledge retrieval, evidence enhancement, and response refinement. Our approach integrates both static and dynamic evidence, ensuring that the generated counterspeech is relevant, well-grounded, and up-to-date. Our method outperforms baseline approaches in politeness, relevance, informativeness, and factual accuracy, demonstrating its effectiveness in generating high-quality counterspeech. To further validate our approach, we conduct ablation studies to verify the necessity of each component in our framework. Furthermore, human evaluations reveal that refinement significantly enhances counterspeech quality and obtains human preference.
MapStory: LLM-Powered Text-Driven Map Animation Prototyping with Human-in-the-Loop Editing
May 28, 2025We introduce MapStory, an LLM-powered animation authoring tool that generates editable map animation sequences directly from natural language text. Given a user-written script, MapStory leverages an agentic architecture to automatically produce a scene breakdown, which decomposes the script into key animation building blocks such as camera movements, visual highlights, and animated elements. Our system includes a researcher component that accurately queries geospatial information by leveraging an LLM with web search, enabling the automatic extraction of relevant regions, paths, and coordinates while allowing users to edit and query for changes or additional information to refine the results. Additionally, users can fine-tune parameters of these blocks through an interactive timeline editor. We detail the system's design and architecture, informed by formative interviews with professional animators and an analysis of 200 existing map animation videos. Our evaluation, which includes expert interviews (N=5) and a usability study (N=12), demonstrates that MapStory enables users to create map animations with ease, facilitates faster iteration, encourages creative exploration, and lowers barriers to creating map-centric stories.
Temporal-Consistent Video Restoration with Pre-trained Diffusion Models
Mar 19, 2025
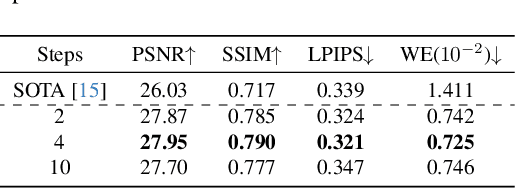
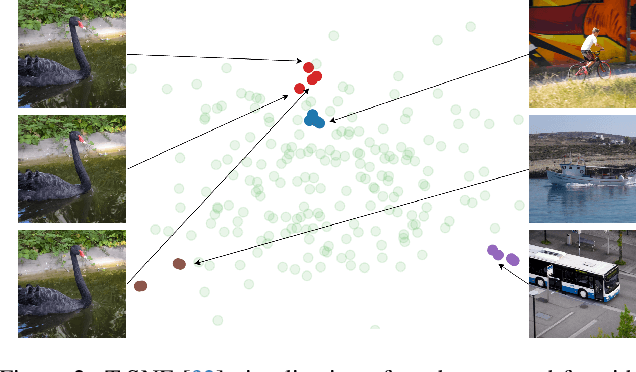
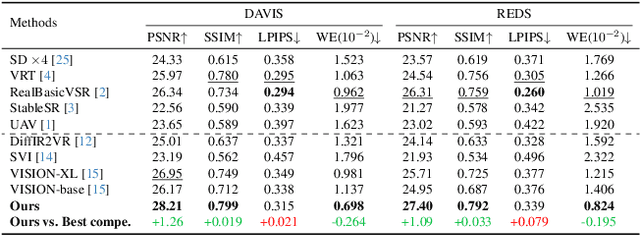
Video restoration (VR) aims to recover high-quality videos from degraded ones. Although recent zero-shot VR methods using pre-trained diffusion models (DMs) show good promise, they suffer from approximation errors during reverse diffusion and insufficient temporal consistency. Moreover, dealing with 3D video data, VR is inherently computationally intensive. In this paper, we advocate viewing the reverse process in DMs as a function and present a novel Maximum a Posterior (MAP) framework that directly parameterizes video frames in the seed space of DMs, eliminating approximation errors. We also introduce strategies to promote bilevel temporal consistency: semantic consistency by leveraging clustering structures in the seed space, and pixel-level consistency by progressive warping with optical flow refinements. Extensive experiments on multiple virtual reality tasks demonstrate superior visual quality and temporal consistency achieved by our method compared to the state-of-the-art.
Cost-Effective Hallucination Detection for LLMs
Jul 31, 2024



Large language models (LLMs) can be prone to hallucinations - generating unreliable outputs that are unfaithful to their inputs, external facts or internally inconsistent. In this work, we address several challenges for post-hoc hallucination detection in production settings. Our pipeline for hallucination detection entails: first, producing a confidence score representing the likelihood that a generated answer is a hallucination; second, calibrating the score conditional on attributes of the inputs and candidate response; finally, performing detection by thresholding the calibrated score. We benchmark a variety of state-of-the-art scoring methods on different datasets, encompassing question answering, fact checking, and summarization tasks. We employ diverse LLMs to ensure a comprehensive assessment of performance. We show that calibrating individual scoring methods is critical for ensuring risk-aware downstream decision making. Based on findings that no individual score performs best in all situations, we propose a multi-scoring framework, which combines different scores and achieves top performance across all datasets. We further introduce cost-effective multi-scoring, which can match or even outperform more expensive detection methods, while significantly reducing computational overhead.
Q-Tuning: Queue-based Prompt Tuning for Lifelong Few-shot Language Learning
Apr 22, 2024



This paper introduces \textbf{Q-tuning}, a novel approach for continual prompt tuning that enables the lifelong learning of a pre-trained language model. When learning a new task, Q-tuning trains a task-specific prompt by adding it to a prompt queue consisting of the prompts from older tasks. To better transfer the knowledge of old tasks, we design an adaptive knowledge aggregation technique that reweighs previous prompts in the queue with a learnable low-rank matrix. Once the prompt queue reaches its maximum capacity, we leverage a PCA-based eviction rule to reduce the queue's size, allowing the newly trained prompt to be added while preserving the primary knowledge of old tasks. In order to mitigate the accumulation of information loss caused by the eviction, we additionally propose a globally shared prefix prompt and a memory retention regularization based on information theory. Extensive experiments demonstrate that our approach outperforms the state-of-the-art methods substantially on continual prompt tuning benchmarks. Moreover, our approach enables lifelong learning on linearly growing task sequences while requiring constant complexity for training and inference.
LAVE: LLM-Powered Agent Assistance and Language Augmentation for Video Editing
Feb 15, 2024



Video creation has become increasingly popular, yet the expertise and effort required for editing often pose barriers to beginners. In this paper, we explore the integration of large language models (LLMs) into the video editing workflow to reduce these barriers. Our design vision is embodied in LAVE, a novel system that provides LLM-powered agent assistance and language-augmented editing features. LAVE automatically generates language descriptions for the user's footage, serving as the foundation for enabling the LLM to process videos and assist in editing tasks. When the user provides editing objectives, the agent plans and executes relevant actions to fulfill them. Moreover, LAVE allows users to edit videos through either the agent or direct UI manipulation, providing flexibility and enabling manual refinement of agent actions. Our user study, which included eight participants ranging from novices to proficient editors, demonstrated LAVE's effectiveness. The results also shed light on user perceptions of the proposed LLM-assisted editing paradigm and its impact on users' creativity and sense of co-creation. Based on these findings, we propose design implications to inform the future development of agent-assisted content editing.
SynthScribe: Deep Multimodal Tools for Synthesizer Sound Retrieval and Exploration
Dec 07, 2023Synthesizers are powerful tools that allow musicians to create dynamic and original sounds. Existing commercial interfaces for synthesizers typically require musicians to interact with complex low-level parameters or to manage large libraries of premade sounds. To address these challenges, we implement SynthScribe -- a fullstack system that uses multimodal deep learning to let users express their intentions at a much higher level. We implement features which address a number of difficulties, namely 1) searching through existing sounds, 2) creating completely new sounds, 3) making meaningful modifications to a given sound. This is achieved with three main features: a multimodal search engine for a large library of synthesizer sounds; a user centered genetic algorithm by which completely new sounds can be created and selected given the users preferences; a sound editing support feature which highlights and gives examples for key control parameters with respect to a text or audio based query. The results of our user studies show SynthScribe is capable of reliably retrieving and modifying sounds while also affording the ability to create completely new sounds that expand a musicians creative horizon.