 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Distillation Game: Adaptive Attacks & Efficient Defenses
May 21, 2026Distillation attacks create a deployment trade-off for model providers: the same outputs that make a model more useful can also make it easier to imitate. We study this trade-off through a minimax game between a utility-constrained teacher and an adaptive student. Our framework yields tractable one-sided response rules: an adaptive evaluation rule in which the student reweights high-value examples, and a teacher-side defense template that suppresses outputs most useful for distillation. From a cheap proxy for example value, we derive Product-of-Experts (PoE), a simple forward-pass-only defense that combines the teacher with a proxy student during generation. Empirically, adaptive evaluation reveals a large passive--adaptive gap: on state-of-the-art defenses, adaptive students recover substantially more capability than passive evaluation suggests on GSM8K and MATH. Under this stronger evaluation, the apparent robustness gap between expensive defenses and PoE narrows considerably, while PoE remains substantially cheaper and preserves higher-quality reasoning traces. Overall, our results suggest that strong distillation remains difficult to stop, and that progress on antidistillation should be judged against adaptive students rather than passive ones. Our code is available at: https://github.com/ysfalh/distillation-game.
The Sample Complexity of Membership Inference and Privacy Auditing
Aug 26, 2025A membership-inference attack gets the output of a learning algorithm, and a target individual, and tries to determine whether this individual is a member of the training data or an independent sample from the same distribution. A successful membership-inference attack typically requires the attacker to have some knowledge about the distribution that the training data was sampled from, and this knowledge is often captured through a set of independent reference samples from that distribution. In this work we study how much information the attacker needs for membership inference by investigating the sample complexity-the minimum number of reference samples required-for a successful attack. We study this question in the fundamental setting of Gaussian mean estimation where the learning algorithm is given $n$ samples from a Gaussian distribution $\mathcal{N}(\mu,\Sigma)$ in $d$ dimensions, and tries to estimate $\hat\mu$ up to some error $\mathbb{E}[\|\hat \mu - \mu\|^2_{\Sigma}]\leq \rho^2 d$. Our result shows that for membership inference in this setting, $\Omega(n + n^2 \rho^2)$ samples can be necessary to carry out any attack that competes with a fully informed attacker. Our result is the first to show that the attacker sometimes needs many more samples than the training algorithm uses to train the model. This result has significant implications for practice, as all attacks used in practice have a restricted form that uses $O(n)$ samples and cannot benefit from $\omega(n)$ samples. Thus, these attacks may be underestimating the possibility of membership inference, and better attacks may be possible when information about the distribution is easy to obtain.
On the Dichotomy Between Privacy and Traceability in $\ell_p$ Stochastic Convex Optimization
Feb 24, 2025In this paper, we investigate the necessity of memorization in stochastic convex optimization (SCO) under $\ell_p$ geometries. Informally, we say a learning algorithm memorizes $m$ samples (or is $m$-traceable) if, by analyzing its output, it is possible to identify at least $m$ of its training samples. Our main results uncover a fundamental tradeoff between traceability and excess risk in SCO. For every $p\in [1,\infty)$, we establish the existence of a risk threshold below which any sample-efficient learner must memorize a \em{constant fraction} of its sample. For $p\in [1,2]$, this threshold coincides with best risk of differentially private (DP) algorithms, i.e., above this threshold, there are algorithms that do not memorize even a single sample. This establishes a sharp dichotomy between privacy and traceability for $p \in [1,2]$. For $p \in (2,\infty)$, this threshold instead gives novel lower bounds for DP learning, partially closing an open problem in this setup. En route of proving these results, we introduce a complexity notion we term \em{trace value} of a problem, which unifies privacy lower bounds and traceability results, and prove a sparse variant of the fingerprinting lemma.
Private Geometric Median
Jun 11, 2024In this paper, we study differentially private (DP) algorithms for computing the geometric median (GM) of a dataset: Given $n$ points, $x_1,\dots,x_n$ in $\mathbb{R}^d$, the goal is to find a point $\theta$ that minimizes the sum of the Euclidean distances to these points, i.e., $\sum_{i=1}^{n} \|\theta - x_i\|_2$. Off-the-shelf methods, such as DP-GD, require strong a priori knowledge locating the data within a ball of radius $R$, and the excess risk of the algorithm depends linearly on $R$. In this paper, we ask: can we design an efficient and private algorithm with an excess error guarantee that scales with the (unknown) radius containing the majority of the datapoints? Our main contribution is a pair of polynomial-time DP algorithms for the task of private GM with an excess error guarantee that scales with the effective diameter of the datapoints. Additionally, we propose an inefficient algorithm based on the inverse smooth sensitivity mechanism, which satisfies the more restrictive notion of pure DP. We complement our results with a lower bound and demonstrate the optimality of our polynomial-time algorithms in terms of sample complexity.
Information Complexity of Stochastic Convex Optimization: Applications to Generalization and Memorization
Feb 14, 2024In this work, we investigate the interplay between memorization and learning in the context of \emph{stochastic convex optimization} (SCO). We define memorization via the information a learning algorithm reveals about its training data points. We then quantify this information using the framework of conditional mutual information (CMI) proposed by Steinke and Zakynthinou (2020). Our main result is a precise characterization of the tradeoff between the accuracy of a learning algorithm and its CMI, answering an open question posed by Livni (2023). We show that, in the $L^2$ Lipschitz--bounded setting and under strong convexity, every learner with an excess error $\varepsilon$ has CMI bounded below by $\Omega(1/\varepsilon^2)$ and $\Omega(1/\varepsilon)$, respectively. We further demonstrate the essential role of memorization in learning problems in SCO by designing an adversary capable of accurately identifying a significant fraction of the training samples in specific SCO problems. Finally, we enumerate several implications of our results, such as a limitation of generalization bounds based on CMI and the incompressibility of samples in SCO problems.
Faster Differentially Private Convex Optimization via Second-Order Methods
May 22, 2023



Differentially private (stochastic) gradient descent is the workhorse of DP private machine learning in both the convex and non-convex settings. Without privacy constraints, second-order methods, like Newton's method, converge faster than first-order methods like gradient descent. In this work, we investigate the prospect of using the second-order information from the loss function to accelerate DP convex optimization. We first develop a private variant of the regularized cubic Newton method of Nesterov and Polyak, and show that for the class of strongly convex loss functions, our algorithm has quadratic convergence and achieves the optimal excess loss. We then design a practical second-order DP algorithm for the unconstrained logistic regression problem. We theoretically and empirically study the performance of our algorithm. Empirical results show our algorithm consistently achieves the best excess loss compared to other baselines and is 10-40x faster than DP-GD/DP-SGD.
Why Is Public Pretraining Necessary for Private Model Training?
Feb 19, 2023



In the privacy-utility tradeoff of a model trained on benchmark language and vision tasks, remarkable improvements have been widely reported with the use of pretraining on publicly available data. This is in part due to the benefits of transfer learning, which is the standard motivation for pretraining in non-private settings. However, the stark contrast in the improvement achieved through pretraining under privacy compared to non-private settings suggests that there may be a deeper, distinct cause driving these gains. To explain this phenomenon, we hypothesize that the non-convex loss landscape of a model training necessitates an optimization algorithm to go through two phases. In the first, the algorithm needs to select a good "basin" in the loss landscape. In the second, the algorithm solves an easy optimization within that basin. The former is a harder problem to solve with private data, while the latter is harder to solve with public data due to a distribution shift or data scarcity. Guided by this intuition, we provide theoretical constructions that provably demonstrate the separation between private training with and without public pretraining. Further, systematic experiments on CIFAR10 and LibriSpeech provide supporting evidence for our hypothesis.
Limitations of Information-Theoretic Generalization Bounds for Gradient Descent Methods in Stochastic Convex Optimization
Dec 27, 2022

To date, no "information-theoretic" frameworks for reasoning about generalization error have been shown to establish minimax rates for gradient descent in the setting of stochastic convex optimization. In this work, we consider the prospect of establishing such rates via several existing information-theoretic frameworks: input-output mutual information bounds, conditional mutual information bounds and variants, PAC-Bayes bounds, and recent conditional variants thereof. We prove that none of these bounds are able to establish minimax rates. We then consider a common tactic employed in studying gradient methods, whereby the final iterate is corrupted by Gaussian noise, producing a noisy "surrogate" algorithm. We prove that minimax rates cannot be established via the analysis of such surrogates. Our results suggest that new ideas are required to analyze gradient descent using information-theoretic techniques.
Understanding Generalization via Leave-One-Out Conditional Mutual Information
Jun 29, 2022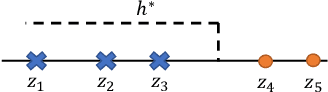
We study the mutual information between (certain summaries of) the output of a learning algorithm and its $n$ training data, conditional on a supersample of $n+1$ i.i.d. data from which the training data is chosen at random without replacement. These leave-one-out variants of the conditional mutual information (CMI) of an algorithm (Steinke and Zakynthinou, 2020) are also seen to control the mean generalization error of learning algorithms with bounded loss functions. For learning algorithms achieving zero empirical risk under 0-1 loss (i.e., interpolating algorithms), we provide an explicit connection between leave-one-out CMI and the classical leave-one-out error estimate of the risk. Using this connection, we obtain upper and lower bounds on risk in terms of the (evaluated) leave-one-out CMI. When the limiting risk is constant or decays polynomially, the bounds converge to within a constant factor of two. As an application, we analyze the population risk of the one-inclusion graph algorithm, a general-purpose transductive learning algorithm for VC classes in the realizable setting. Using leave-one-out CMI, we match the optimal bound for learning VC classes in the realizable setting, answering an open challenge raised by Steinke and Zakynthinou (2020). Finally, in order to understand the role of leave-one-out CMI in studying generalization, we place leave-one-out CMI in a hierarchy of measures, with a novel unconditional mutual information at the root. For 0-1 loss and interpolating learning algorithms, this mutual information is observed to be precisely the risk.
Towards a Unified Information-Theoretic Framework for Generalization
Nov 17, 2021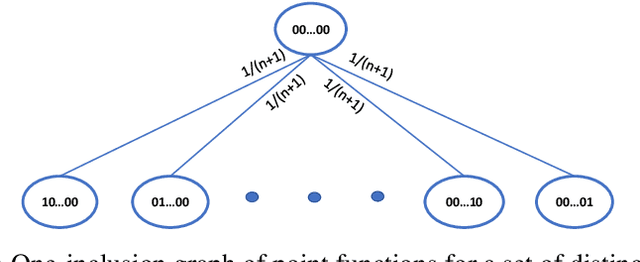
In this work, we investigate the expressiveness of the "conditional mutual information" (CMI) framework of Steinke and Zakynthinou (2020) and the prospect of using it to provide a unified framework for proving generalization bounds in the realizable setting. We first demonstrate that one can use this framework to express non-trivial (but sub-optimal) bounds for any learning algorithm that outputs hypotheses from a class of bounded VC dimension. We prove that the CMI framework yields the optimal bound on the expected risk of Support Vector Machines (SVMs) for learning halfspaces. This result is an application of our general result showing that stable compression schemes Bousquet al. (2020) of size $k$ have uniformly bounded CMI of order $O(k)$. We further show that an inherent limitation of proper learning of VC classes contradicts the existence of a proper learner with constant CMI, and it implies a negative resolution to an open problem of Steinke and Zakynthinou (2020). We further study the CMI of empirical risk minimizers (ERMs) of class $H$ and show that it is possible to output all consistent classifiers (version space) with bounded CMI if and only if $H$ has a bounded star number (Hanneke and Yang (2015)). Moreover, we prove a general reduction showing that "leave-one-out" analysis is expressible via the CMI framework. As a corollary we investigate the CMI of the one-inclusion-graph algorithm proposed by Haussler et al. (1994). More generally, we show that the CMI framework is universal in the sense that for every consistent algorithm and data distribution, the expected risk vanishes as the number of samples diverges if and only if its evaluated CMI has sublinear growth with the number of samples.