 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RDU: A Region-based Approach to Form-style Document Understanding
Jun 14, 2022
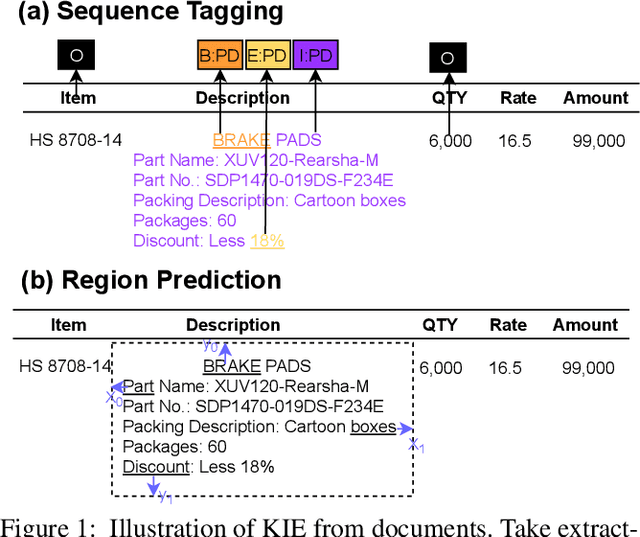
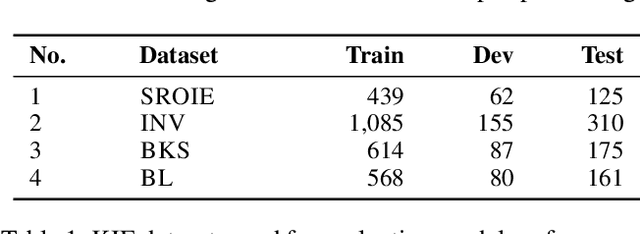
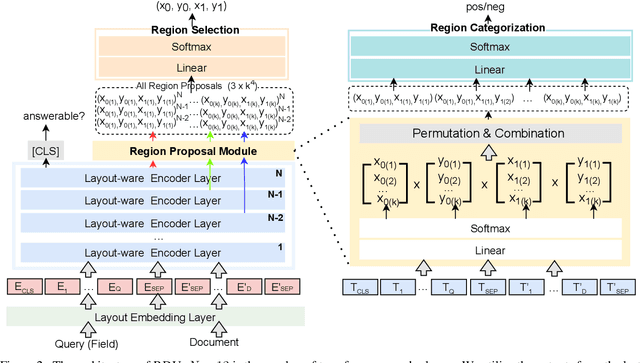
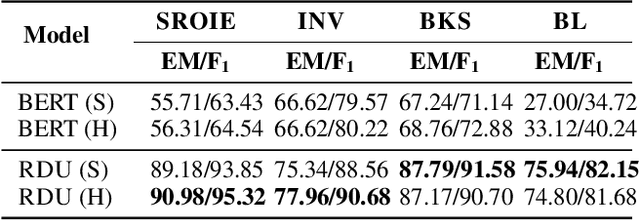
Key Information Extraction (KIE) is aimed at extracting structured information (e.g. key-value pairs) from form-style documents (e.g. invoices), which makes an important step towards intelligent document understanding. Previous approaches generally tackle KIE by sequence tagging, which faces difficulty to process non-flatten sequences, especially for table-text mixed documents. These approaches also suffer from the trouble of pre-defining a fixed set of labels for each type of documents, as well as the label imbalance issue. In this work, we assume Optical Character Recognition (OCR) has been applied to input documents, and reformulate the KIE task as a region prediction problem in the two-dimensional (2D) space given a target field. Following this new setup, we develop a new KIE model named Region-based Document Understanding (RDU) that takes as input the text content and corresponding coordinates of a document, and tries to predict the result by localizing a bounding-box-like region. Our RDU first applies a layout-aware BERT equipped with a soft layout attention masking and bias mechanism to incorporate layout information into the representations. Then, a list of candidate regions is generated from the representations via a Region Proposal Module inspired by computer vision models widely applied for object detection. Finally, a Region Categorization Module and a Region Selection Module are adopted to judge whether a proposed region is valid and select the one with the largest probability from all proposed regions respectively. Experiments on four types of form-style documents show that our proposed method can achieve impressive results. In addition, our RDU model can be trained with different document types seamlessly, which is especially helpful over low-resource documents.
Secure UAV-to-Ground MIMO Communications: Joint Transceiver and Location Optimization
Jul 10, 2022



Unmanned aerial vehicles (UAVs) are foreseen to constitute promising airborne communication devices as a benefit of their superior channel quality. But UAV-to-ground (U2G) communications are vulnerable to eavesdropping. Hence, we conceive a sophisticated physical layer security solution for improving the secrecy rate of multi-antenna aided U2G systems. Explicitly, the secrecy rate of the U2G MIMO wiretap channels is derived by using random matrix theory. The resultant explicit expression is then applied in the joint optimization of the MIMO transceiver and the UAV location relying on an alternating optimization technique. Our numerical results show that the joint transceiver and location optimization conceived facilitates secure communications even in the challenging scenario, where the legitimate channel of confidential information is inferior to the eavesdropping channel.
Real-time End-to-End Video Text Spotter with Contrastive Representation Learning
Jul 18, 2022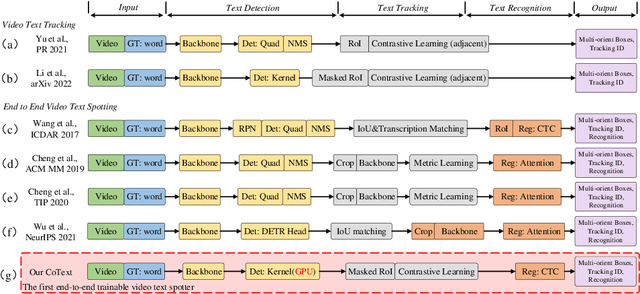

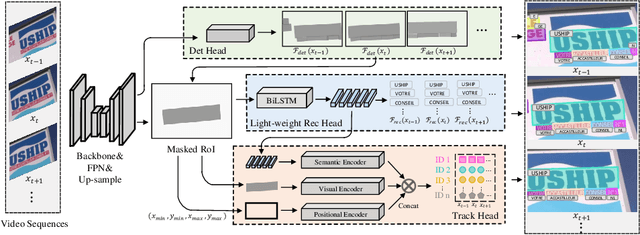
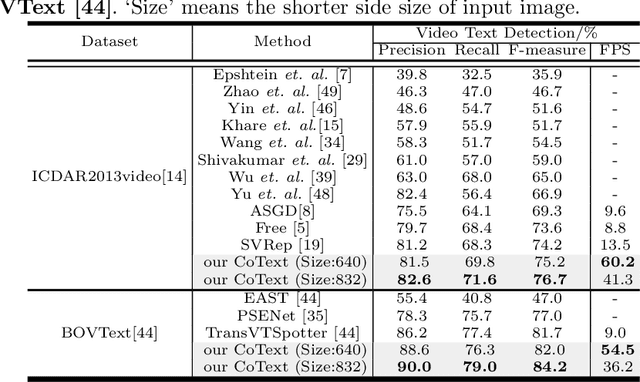
Video text spotting(VTS) is the task that requires simultaneously detecting, tracking and recognizing text in the video. Existing video text spotting methods typically develop sophisticated pipelines and multiple models, which is not friend for real-time applications. Here we propose a real-time end-to-end video text spotter with Contrastive Representation learning (CoText). Our contributions are three-fold: 1) CoText simultaneously address the three tasks (e.g., text detection, tracking, recognition) in a real-time end-to-end trainable framework. 2) With contrastive learning, CoText models long-range dependencies and learning temporal information across multiple frames. 3) A simple, lightweight architecture is designed for effective and accurate performance, including GPU-parallel detection post-processing, CTC-based recognition head with Masked RoI. Extensive experiments show the superiority of our method. Especially, CoText achieves an video text spotting IDF1 of 72.0% at 41.0 FPS on ICDAR2015video, with 10.5% and 32.0 FPS improvement the previous best method. The code can be found at github.com/weijiawu/CoText.
Nonlinear Intensity Underwater Sonar Image Matching Method Based on Phase Information and Deep Convolution Features
Nov 29, 2021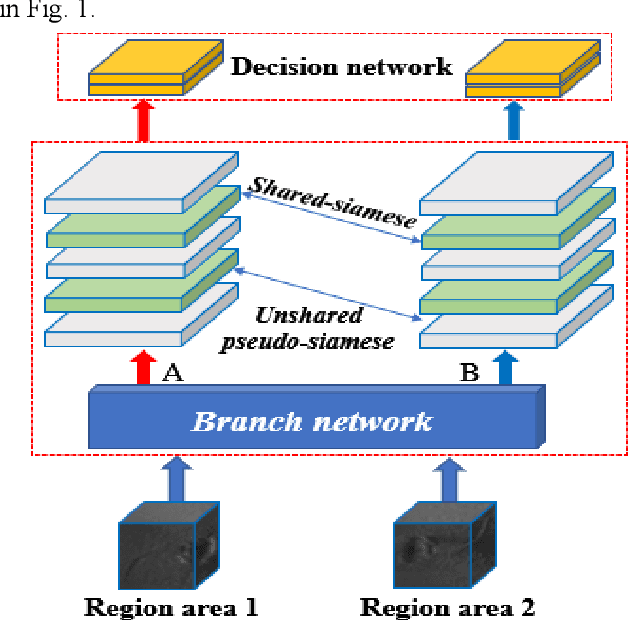
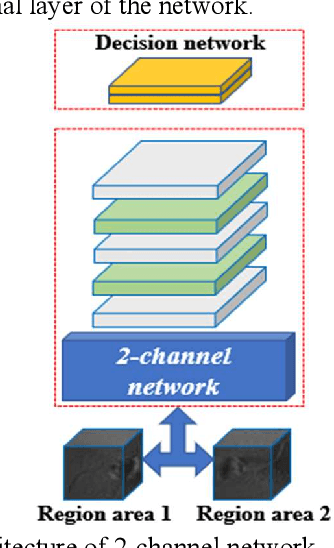
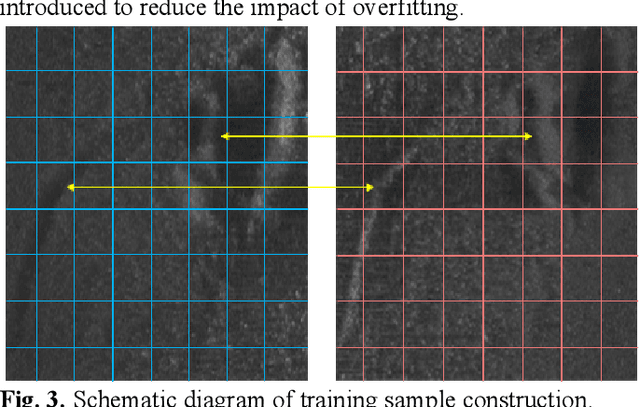
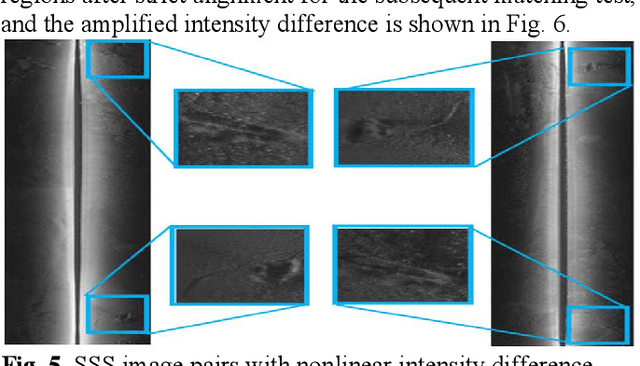
In the field of deep-sea exploration, sonar is presently the only efficient long-distance sensing device. The complicated underwater environment, such as noise interference, low target intensity or background dynamics, has brought many negative effects on sonar imaging. Among them, the problem of nonlinear intensity is extremely prevalent. It is also known as the anisotropy of acoustic sensor imaging, that is, when autonomous underwater vehicles (AUVs) carry sonar to detect the same target from different angles, the intensity variation between image pairs is sometimes very large, which makes the traditional matching algorithm almost ineffective. However, image matching is the basis of comprehensive tasks such as navigation, positioning, and mapping. Therefore, it is very valuable to obtain robust and accurate matching results. This paper proposes a combined matching method based on phase information and deep convolution features. It has two outstanding advantages: one is that the deep convolution features could be used to measure the similarity of the local and global positions of the sonar image; the other is that local feature matching could be performed at the key target position of the sonar image. This method does not need complex manual designs, and completes the matching task of nonlinear intensity sonar images in a close end-to-end manner. Feature matching experiments are carried out on the deep-sea sonar images captured by AUVs, and the results show that our proposal has preeminent matching accuracy and robustness.
Security-Reliability Trade-Off Analysis for SWIPT- and AF-Based IoT Networks with Friendly Jammers
Jun 09, 2022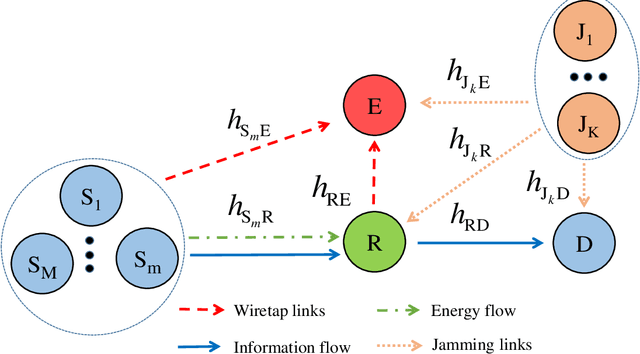
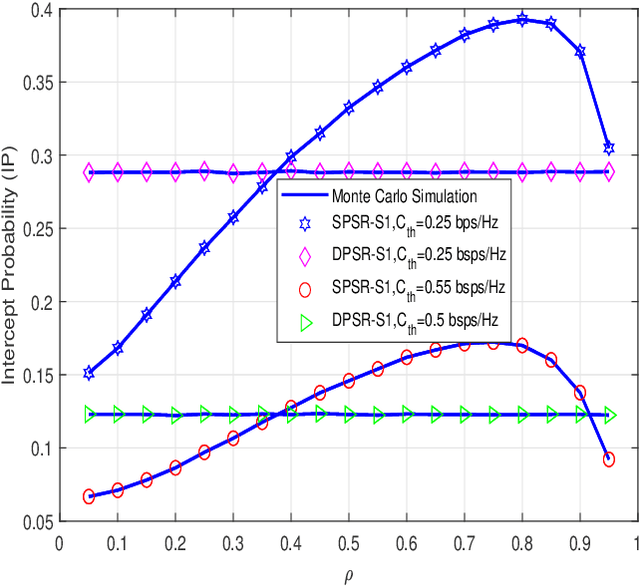
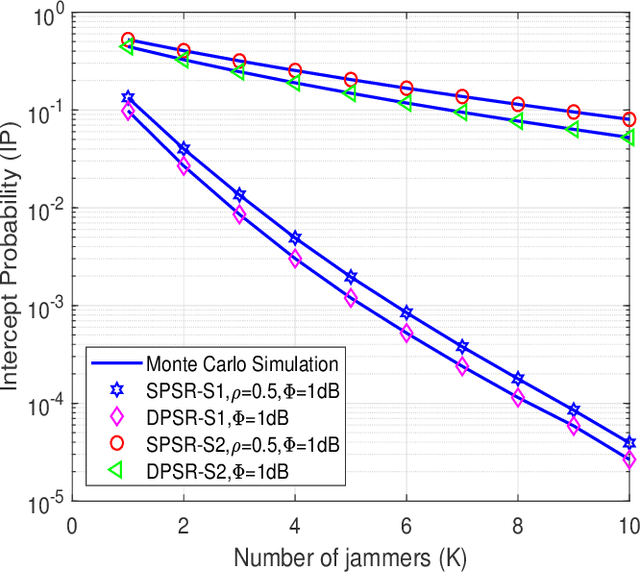
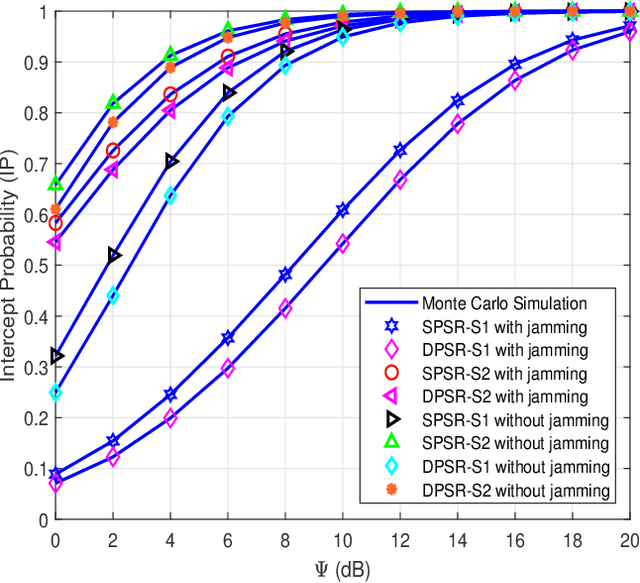
Radio-frequency (RF) energy harvesting (EH) in wireless relaying networks has attracted considerable recent interest, especially for supplying energy to relay nodes in Internet-of-Things (IoT) systems to assist the information exchange between a source and a destination. Moreover, limited hardware, computational resources, and energy availability of IoT devices have raised various security challenges. To this end, physical layer security (PLS) has been proposed as an effective alternative to cryptographic methods for providing information security. In this study, we propose a PLS approach for simultaneous wireless information and power transfer (SWIPT)-based half-duplex (HD) amplify-and-forward (AF) relaying systems in the presence of an eavesdropper. Furthermore, we take into account both static power splitting relaying (SPSR) and dynamic power splitting relaying (DPSR) to thoroughly investigate the benefits of each one. To further enhance secure communication, we consider multiple friendly jammers to help prevent wiretapping attacks from the eavesdropper. More specifically, we provide a reliability and security analysis by deriving closed-form expressions of outage probability (OP) and intercept probability (IP), respectively, for both the SPSR and DPSR schemes. Then, simulations are also performed to validate our analysis and the effectiveness of the proposed schemes. Specifically, numerical results illustrate the non-trivial trade-off between reliability and security of the proposed system. In addition, we conclude from the simulation results that the proposed DPSR scheme outperforms the SPSR-based scheme in terms of OP and IP under the influences of different parameters on system performance.
Learning Viewpoint-Agnostic Visual Representations by Recovering Tokens in 3D Space
Jun 23, 2022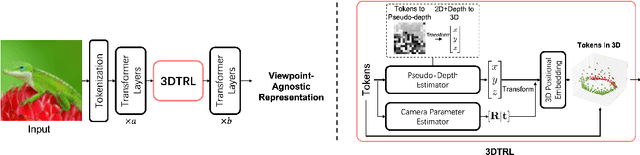
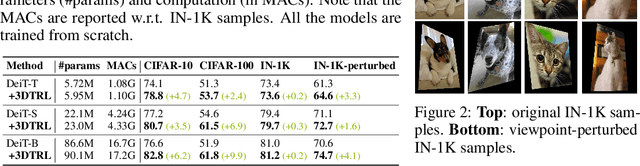


Humans are remarkably flexible in understanding viewpoint changes due to visual cortex supporting the perception of 3D structure. In contrast, most of the computer vision models that learn visual representation from a pool of 2D images often fail to generalize over novel camera viewpoints. Recently, the vision architectures have shifted towards convolution-free architectures, visual Transformers, which operate on tokens derived from image patches. However, neither these Transformers nor 2D convolutional networks perform explicit operations to learn viewpoint-agnostic representation for visual understanding. To this end, we propose a 3D Token Representation Layer (3DTRL) that estimates the 3D positional information of the visual tokens and leverages it for learning viewpoint-agnostic representations. The key elements of 3DTRL include a pseudo-depth estimator and a learned camera matrix to impose geometric transformations on the tokens. These enable 3DTRL to recover the 3D positional information of the tokens from 2D patches. In practice, 3DTRL is easily plugged-in into a Transformer. Our experiments demonstrate the effectiveness of 3DTRL in many vision tasks including image classification, multi-view video alignment, and action recognition. The models with 3DTRL outperform their backbone Transformers in all the tasks with minimal added computation. Our project page is at https://www3.cs.stonybrook.edu/~jishang/3dtrl/3dtrl.html
DEVIANT: Depth EquiVarIAnt NeTwork for Monocular 3D Object Detection
Jul 21, 2022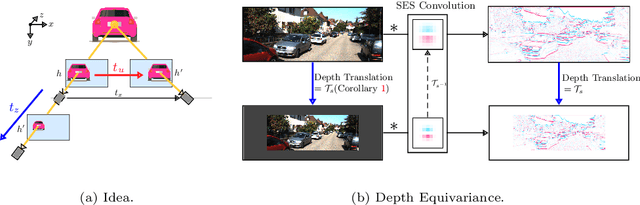
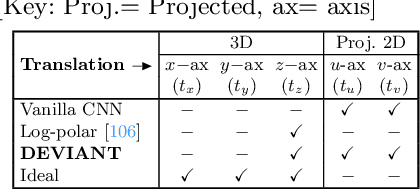
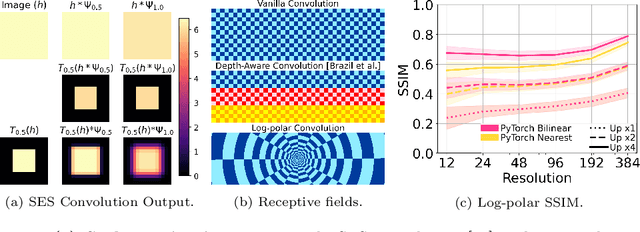
Modern neural networks use building blocks such as convolutions that are equivariant to arbitrary 2D translations. However, these vanilla blocks are not equivariant to arbitrary 3D translations in the projective manifold. Even then, all monocular 3D detectors use vanilla blocks to obtain the 3D coordinates, a task for which the vanilla blocks are not designed for. This paper takes the first step towards convolutions equivariant to arbitrary 3D translations in the projective manifold. Since the depth is the hardest to estimate for monocular detection, this paper proposes Depth EquiVarIAnt NeTwork (DEVIANT) built with existing scale equivariant steerable blocks. As a result, DEVIANT is equivariant to the depth translations in the projective manifold whereas vanilla networks are not. The additional depth equivariance forces the DEVIANT to learn consistent depth estimates, and therefore, DEVIANT achieves state-of-the-art monocular 3D detection results on KITTI and Waymo datasets in the image-only category and performs competitively to methods using extra information. Moreover, DEVIANT works better than vanilla networks in cross-dataset evaluation. Code and models at https://github.com/abhi1kumar/DEVIANT
On Mitigating Hard Clusters for Face Clustering
Jul 25, 2022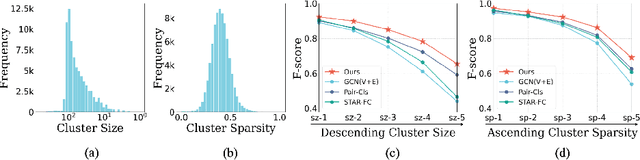
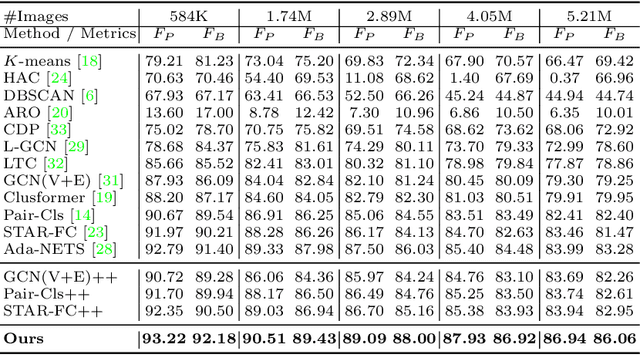
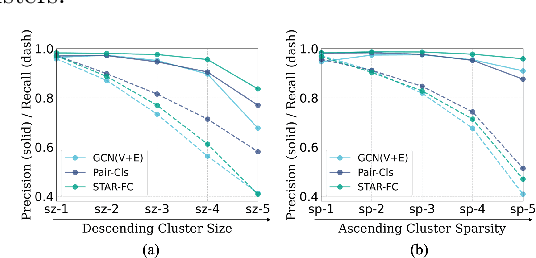
Face clustering is a promising way to scale up face recognition systems using large-scale unlabeled face images. It remains challenging to identify small or sparse face image clusters that we call hard clusters, which is caused by the heterogeneity, \ie, high variations in size and sparsity, of the clusters. Consequently, the conventional way of using a uniform threshold (to identify clusters) often leads to a terrible misclassification for the samples that should belong to hard clusters. We tackle this problem by leveraging the neighborhood information of samples and inferring the cluster memberships (of samples) in a probabilistic way. We introduce two novel modules, Neighborhood-Diffusion-based Density (NDDe) and Transition-Probability-based Distance (TPDi), based on which we can simply apply the standard Density Peak Clustering algorithm with a uniform threshold. Our experiments on multiple benchmarks show that each module contributes to the final performance of our method, and by incorporating them into other advanced face clustering methods, these two modules can boost the performance of these methods to a new state-of-the-art. Code is available at: https://github.com/echoanran/On-Mitigating-Hard-Clusters.
Happenstance: Utilizing Semantic Search to Track Russian State Media Narratives about the Russo-Ukrainian War On Reddit
May 28, 2022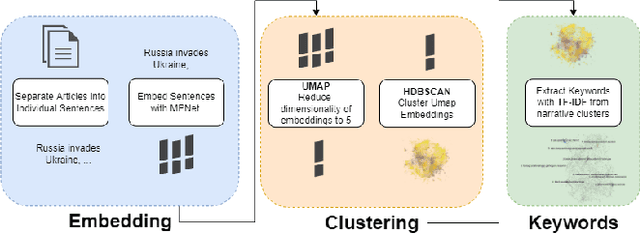
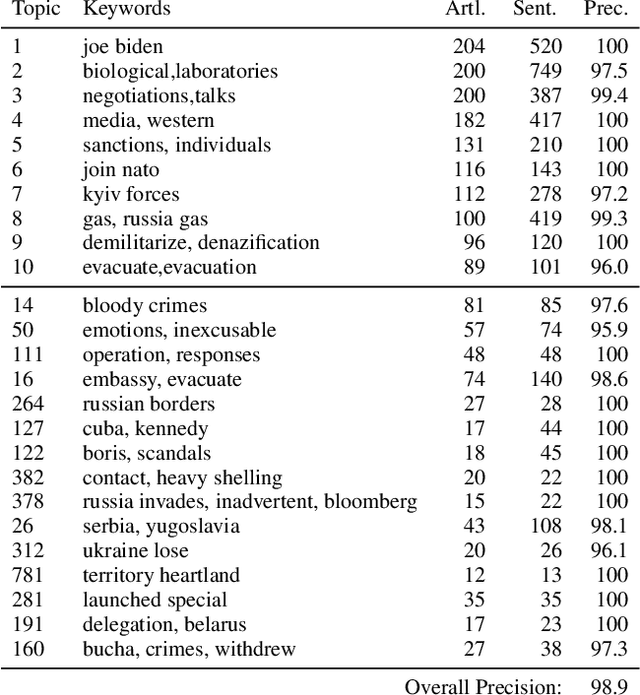
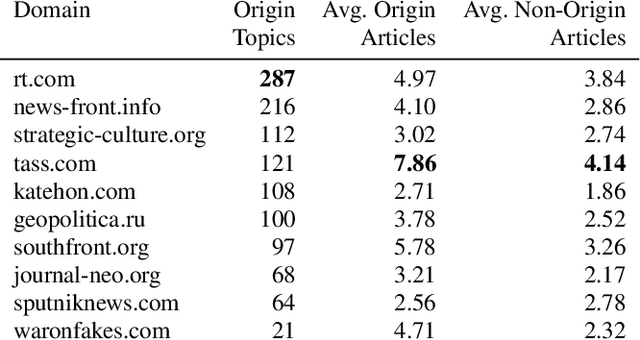
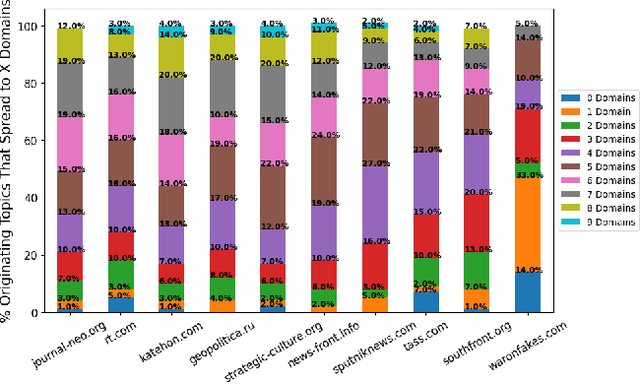
In the buildup to and in the weeks following the Russian Federation's invasion of Ukraine, Russian disinformation outlets output torrents of misleading and outright false information. In this work, we study the coordinated information campaign to understand the most prominent disinformation narratives touted by the Russian government to English-speaking audiences. To do this, we first perform sentence-level topic analysis using the large-language model MPNet on articles published by nine different Russian disinformation websites and the new Russian "fact-checking" website waronfakes.com. We show that smaller websites like katehon.com were highly effective at producing topics that were later echoed by other disinformation sites. After analyzing the set of Russian information narratives, we analyze their correspondence with narratives and topics of discussion on the r/Russia and 10 other political subreddits. Using MPNet and a semantic search algorithm, we map these subreddits' comments to the set of topics extracted from our set of disinformation websites, finding that 39.6% of r/Russia comments corresponded to narratives from Russian disinformation websites, compared to 8.86% on r/politics.
Explaining Chest X-ray Pathologies in Natural Language
Jul 09, 2022



Most deep learning algorithms lack explanations for their predictions, which limits their deployment in clinical practice. Approaches to improve explainability, especially in medical imaging, have often been shown to convey limited information, be overly reassuring, or lack robustness. In this work, we introduce the task of generating natural language explanations (NLEs) to justify predictions made on medical images. NLEs are human-friendly and comprehensive, and enable the training of intrinsically explainable models. To this goal, we introduce MIMIC-NLE, the first, large-scale, medical imaging dataset with NLEs. It contains over 38,000 NLEs, which explain the presence of various thoracic pathologies and chest X-ray findings. We propose a general approach to solve the task and evaluate several architectures on this dataset, including via clinician assessment.