 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASEval: Extending Multi-Agent Evaluation from Models to Systems
Mar 09, 2026The rapid adoption of LLM-based agentic systems has produced a rich ecosystem of frameworks (smolagents, LangGraph, AutoGen, CAMEL, LlamaIndex, i.a.). Yet existing benchmarks are model-centric: they fix the agentic setup and do not compare other system components. We argue that implementation decisions substantially impact performance, including choices such as topology, orchestration logic, and error handling. MASEval addresses this evaluation gap with a framework-agnostic library that treats the entire system as the unit of analysis. Through a systematic system-level comparison across 3 benchmarks, 3 models, and 3 frameworks, we find that framework choice matters as much as model choice. MASEval allows researchers to explore all components of agentic systems, opening new avenues for principled system design, and practitioners to identify the best implementation for their use case. MASEval is available under the MIT licence https://github.com/parameterlab/MASEval.
Privacy Collapse: Benign Fine-Tuning Can Break Contextual Privacy in Language Models
Jan 21, 2026We identify a novel phenomenon in language models: benign fine-tuning of frontier models can lead to privacy collapse. We find that diverse, subtle patterns in training data can degrade contextual privacy, including optimisation for helpfulness, exposure to user information, emotional and subjective dialogue, and debugging code printing internal variables, among others. Fine-tuned models lose their ability to reason about contextual privacy norms, share information inappropriately with tools, and violate memory boundaries across contexts. Privacy collapse is a ``silent failure'' because models maintain high performance on standard safety and utility benchmarks whilst exhibiting severe privacy vulnerabilities. Our experiments show evidence of privacy collapse across six models (closed and open weight), five fine-tuning datasets (real-world and controlled data), and two task categories (agentic and memory-based). Our mechanistic analysis reveals that privacy representations are uniquely fragile to fine-tuning, compared to task-relevant features which are preserved. Our results reveal a critical gap in current safety evaluations, in particular for the deployment of specialised agents.
Shh, don't say that! Domain Certification in LLMs
Feb 26, 2025Large language models (LLMs) are often deployed to perform constrained tasks, with narrow domains. For example, customer support bots can be built on top of LLMs, relying on their broad language understanding and capabilities to enhance performance. However, these LLMs are adversarially susceptible, potentially generating outputs outside the intended domain. To formalize, assess, and mitigate this risk, we introduce domain certification; a guarantee that accurately characterizes the out-of-domain behavior of language models. We then propose a simple yet effective approach, which we call VALID that provides adversarial bounds as a certificate. Finally, we evaluate our method across a diverse set of datasets, demonstrating that it yields meaningful certificates, which bound the probability of out-of-domain samples tightly with minimum penalty to refusal behavior.
* 10 pages, includes appendix Published in International Conference on Learning Representations (ICLR) 2025
Fool Me Once? Contrasting Textual and Visual Explanations in a Clinical Decision-Support Setting
Oct 16, 2024



The growing capabilities of AI models are leading to their wider use, including in safety-critical domains. Explainable AI (XAI) aims to make these models safer to use by making their inference process more transparent. However, current explainability methods are seldom evaluated in the way they are intended to be used: by real-world end users. To address this, we conducted a large-scale user study with 85 healthcare practitioners in the context of human-AI collaborative chest X-ray analysis. We evaluated three types of explanations: visual explanations (saliency maps), natural language explanations, and a combination of both modalities. We specifically examined how different explanation types influence users depending on whether the AI advice and explanations are factually correct. We find that text-based explanations lead to significant over-reliance, which is alleviated by combining them with saliency maps. We also observe that the quality of explanations, that is, how much factually correct information they entail, and how much this aligns with AI correctness, significantly impacts the usefulness of the different explanation types.
Benchmarking Predictive Coding Networks -- Made Simple
Jul 01, 2024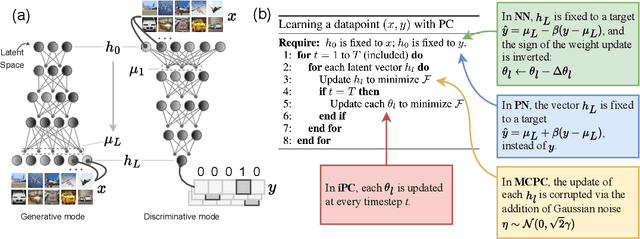
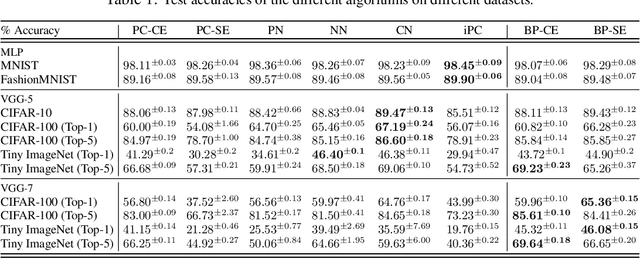

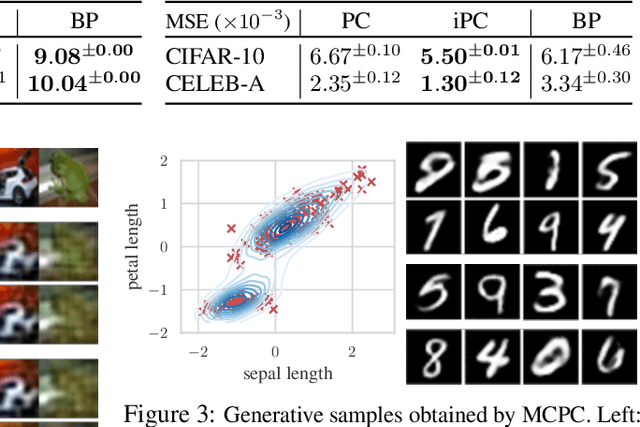
In this work, we tackle the problems of efficiency and scalability for predictive coding networks in machine learning. To do so, we first propose a library called PCX, whose focus lies on performance and simplicity, and provides a user-friendly, deep-learning oriented interface. Second, we use PCX to implement a large set of benchmarks for the community to use for their experiments. As most works propose their own tasks and architectures, do not compare one against each other, and focus on small-scale tasks, a simple and fast open-source library adopted by the whole community would address all of these concerns. Third, we perform extensive benchmarks using multiple algorithms, setting new state-of-the-art results in multiple tasks and datasets, as well as highlighting limitations inherent to PC that should be addressed. Thanks to the efficiency of PCX, we are able to analyze larger architectures than commonly used, providing baselines to galvanize community efforts towards one of the main open problems in the field: scalability. The code for PCX is available at \textit{https://github.com/liukidar/pcax}.
Towards Certification of Uncertainty Calibration under Adversarial Attacks
May 22, 2024



Since neural classifiers are known to be sensitive to adversarial perturbations that alter their accuracy, \textit{certification methods} have been developed to provide provable guarantees on the insensitivity of their predictions to such perturbations. Furthermore, in safety-critical applications, the frequentist interpretation of the confidence of a classifier (also known as model calibration) can be of utmost importance. This property can be measured via the Brier score or the expected calibration error. We show that attacks can significantly harm calibration, and thus propose certified calibration as worst-case bounds on calibration under adversarial perturbations. Specifically, we produce analytic bounds for the Brier score and approximate bounds via the solution of a mixed-integer program on the expected calibration error. Finally, we propose novel calibration attacks and demonstrate how they can improve model calibration through \textit{adversarial calibration training}.
Incremental Predictive Coding: A Parallel and Fully Automatic Learning Algorithm
Nov 16, 2022



Neuroscience-inspired models, such as predictive coding, have the potential to play an important role in the future of machine intelligence. However, they are not yet used in industrial applications due to some limitations, such as the lack of efficiency. In this work, we address this by proposing incremental predictive coding (iPC), a variation of the original framework derived from the incremental expectation maximization algorithm, where every operation can be performed in parallel without external control. We show both theoretically and empirically that iPC is much faster than the original algorithm originally developed by Rao and Ballard, while maintaining performance comparable to backpropagation in image classification tasks. This work impacts several areas, has general applications in computational neuroscience and machine learning, and specific applications in scenarios where automatization and parallelization are important, such as distributed computing and implementations of deep learning models on analog and neuromorphic chips.
Explaining Chest X-ray Pathologies in Natural Language
Jul 09, 2022



Most deep learning algorithms lack explanations for their predictions, which limits their deployment in clinical practice. Approaches to improve explainability, especially in medical imaging, have often been shown to convey limited information, be overly reassuring, or lack robustness. In this work, we introduce the task of generating natural language explanations (NLEs) to justify predictions made on medical images. NLEs are human-friendly and comprehensive, and enable the training of intrinsically explainable models. To this goal, we introduce MIMIC-NLE, the first, large-scale, medical imaging dataset with NLEs. It contains over 38,000 NLEs, which explain the presence of various thoracic pathologies and chest X-ray findings. We propose a general approach to solve the task and evaluate several architectures on this dataset, including via clinician assessment.
e-ViL: A Dataset and Benchmark for Natural Language Explanations in Vision-Language Tasks
May 08, 2021


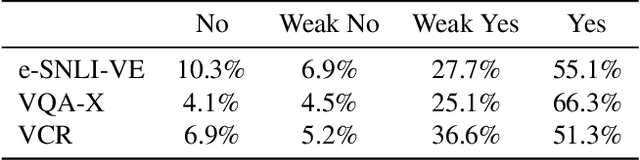
Recently, an increasing number of works have introduced models capable of generating natural language explanations (NLEs) for their predictions on vision-language (VL) tasks. Such models are appealing because they can provide human-friendly and comprehensive explanations. However, there is still a lack of unified evaluation approaches for the explanations generated by these models. Moreover, there are currently only few datasets of NLEs for VL tasks. In this work, we introduce e-ViL, a benchmark for explainable vision-language tasks that establishes a unified evaluation framework and provides the first comprehensive comparison of existing approaches that generate NLEs for VL tasks. e-ViL spans four models and three datasets. Both automatic metrics and human evaluation are used to assess model-generated explanations. We also introduce e-SNLI-VE, the largest existing VL dataset with NLEs (over 430k instances). Finally, we propose a new model that combines UNITER, which learns joint embeddings of images and text, and GPT-2, a pre-trained language model that is well-suited for text generation. It surpasses the previous state-of-the-art by a large margin across all datasets.