 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Duration-aware pause insertion using pre-trained language model for multi-speaker text-to-speech
Feb 27, 2023

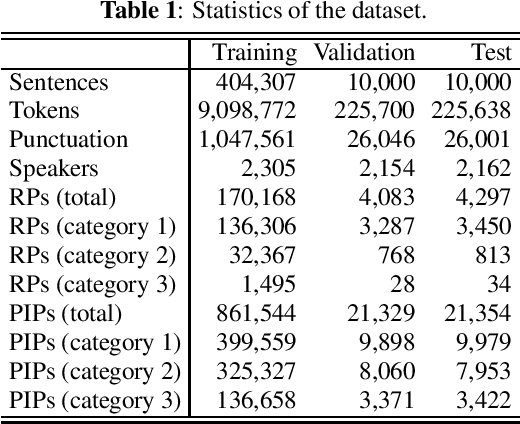
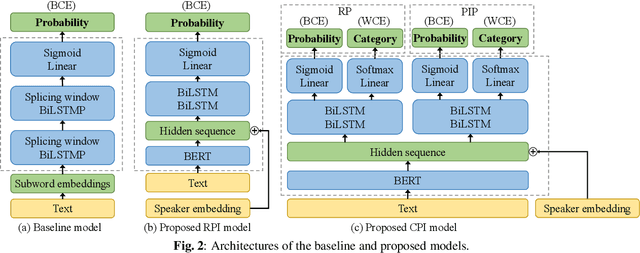
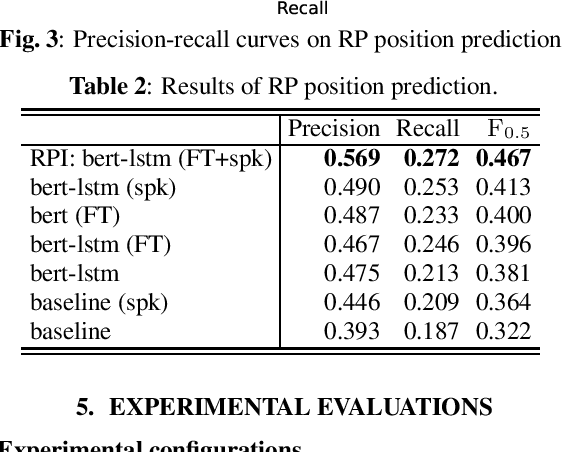
Pause insertion, also known as phrase break prediction and phrasing, is an essential part of TTS systems because proper pauses with natural duration significantly enhance the rhythm and intelligibility of synthetic speech. However, conventional phrasing models ignore various speakers' different styles of inserting silent pauses, which can degrade the performance of the model trained on a multi-speaker speech corpus. To this end, we propose more powerful pause insertion frameworks based on a pre-trained language model. Our approach uses bidirectional encoder representations from transformers (BERT) pre-trained on a large-scale text corpus, injecting speaker embedding to capture various speaker characteristics. We also leverage duration-aware pause insertion for more natural multi-speaker TTS. We develop and evaluate two types of models. The first improves conventional phrasing models on the position prediction of respiratory pauses (RPs), i.e., silent pauses at word transitions without punctuation. It performs speaker-conditioned RP prediction considering contextual information and is used to demonstrate the effect of speaker information on the prediction. The second model is further designed for phoneme-based TTS models and performs duration-aware pause insertion, predicting both RPs and punctuation-indicated pauses (PIPs) that are categorized by duration. The evaluation results show that our models improve the precision and recall of pause insertion and the rhythm of synthetic speech.
Blind Multimodal Quality Assessment: A Brief Survey and A Case Study of Low-light Images
Mar 18, 2023
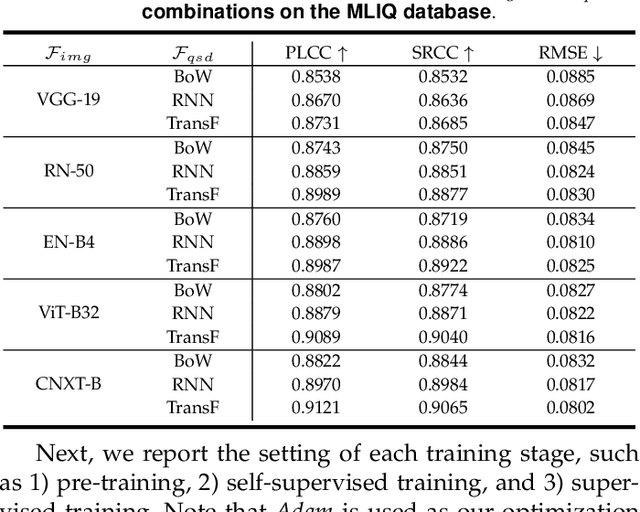
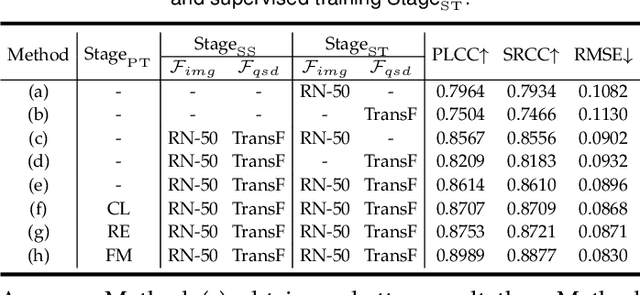
Blind image quality assessment (BIQA) aims at automatically and accurately forecasting objective scores for visual signals, which has been widely used to monitor product and service quality in low-light applications, covering smartphone photography, video surveillance, autonomous driving, etc. Recent developments in this field are dominated by unimodal solutions inconsistent with human subjective rating patterns, where human visual perception is simultaneously reflected by multiple sensory information (e.g., sight and hearing). In this article, we present a unique blind multimodal quality assessment (BMQA) of low-light images from subjective evaluation to objective score. To investigate the multimodal mechanism, we first establish a multimodal low-light image quality (MLIQ) database with authentic low-light distortions, containing image and audio modality pairs. Further, we specially design the key modules of BMQA, considering multimodal quality representation, latent feature alignment and fusion, and hybrid self-supervised and supervised learning. Extensive experiments show that our BMQA yields state-of-the-art accuracy on the proposed MLIQ benchmark database. In particular, we also build an independent single-image modality Dark-4K database, which is used to verify its applicability and generalization performance in mainstream unimodal applications. Qualitative and quantitative results on Dark-4K show that BMQA achieves superior performance to existing BIQA approaches as long as a pre-trained quality semantic description model is provided. The proposed framework and two databases as well as the collected BIQA methods and evaluation metrics are made publicly available.
Tag2Text: Guiding Vision-Language Model via Image Tagging
Mar 10, 2023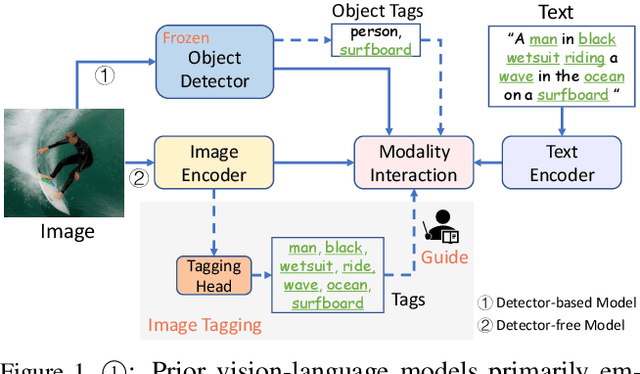
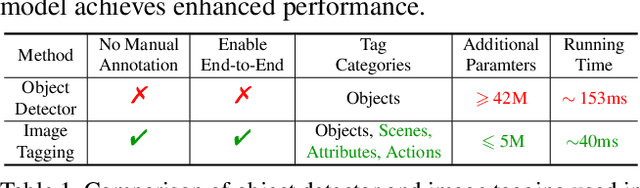

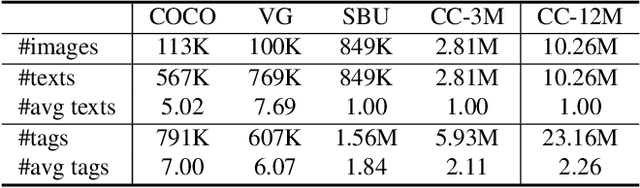
This paper presents Tag2Text, a vision language pre-training (VLP) framework, which introduces image tagging into vision-language models to guide the learning of visual-linguistic features. In contrast to prior works which utilize object tags either manually labeled or automatically detected with a limited detector, our approach utilizes tags parsed from its paired text to learn an image tagger and meanwhile provides guidance to vision-language models. Given that, Tag2Text can utilize large-scale annotation-free image tags in accordance with image-text pairs, and provides more diverse tag categories beyond objects. As a result, Tag2Text achieves a superior image tag recognition ability by exploiting fine-grained text information. Moreover, by leveraging tagging guidance, Tag2Text effectively enhances the performance of vision-language models on both generation-based and alignment-based tasks. Across a wide range of downstream benchmarks, Tag2Text achieves state-of-the-art or competitive results with similar model sizes and data scales, demonstrating the efficacy of the proposed tagging guidance.
Accurate Real-time Polyp Detection in Videos from Concatenation of Latent Features Extracted from Consecutive Frames
Mar 10, 2023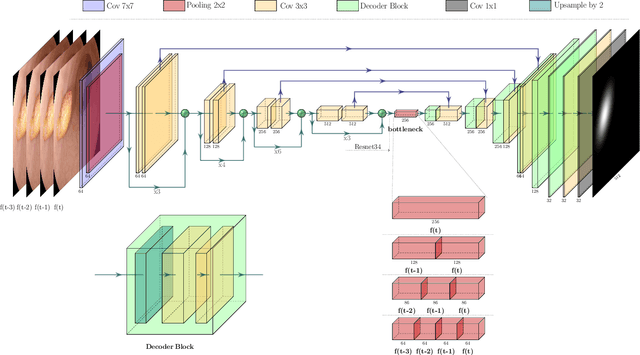
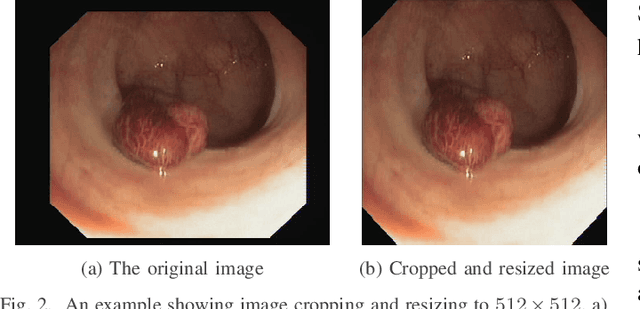
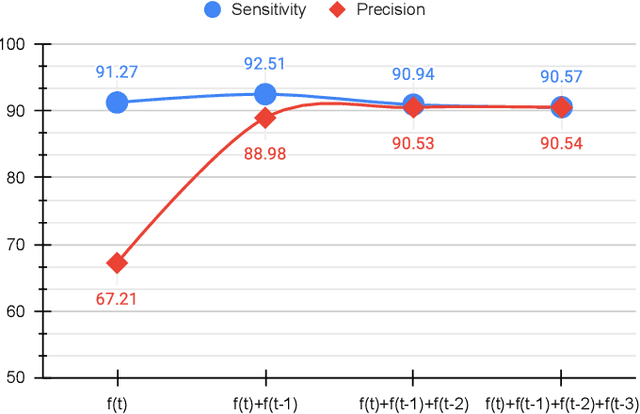

An efficient deep learning model that can be implemented in real-time for polyp detection is crucial to reducing polyp miss-rate during screening procedures. Convolutional neural networks (CNNs) are vulnerable to small changes in the input image. A CNN-based model may miss the same polyp appearing in a series of consecutive frames and produce unsubtle detection output due to changes in camera pose, lighting condition, light reflection, etc. In this study, we attempt to tackle this problem by integrating temporal information among neighboring frames. We propose an efficient feature concatenation method for a CNN-based encoder-decoder model without adding complexity to the model. The proposed method incorporates extracted feature maps of previous frames to detect polyps in the current frame. The experimental results demonstrate that the proposed method of feature concatenation improves the overall performance of automatic polyp detection in videos. The following results are obtained on a public video dataset: sensitivity 90.94\%, precision 90.53\%, and specificity 92.46%
DDS3D: Dense Pseudo-Labels with Dynamic Threshold for Semi-Supervised 3D Object Detection
Mar 10, 2023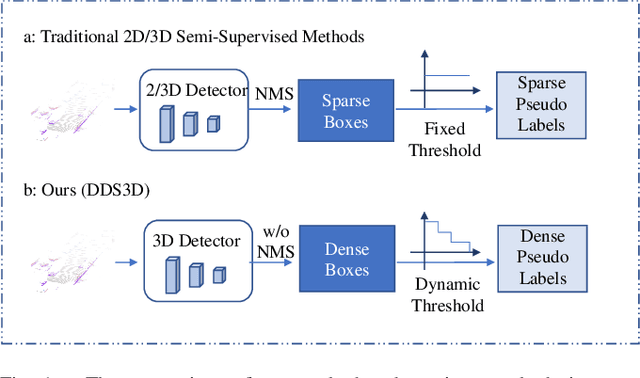
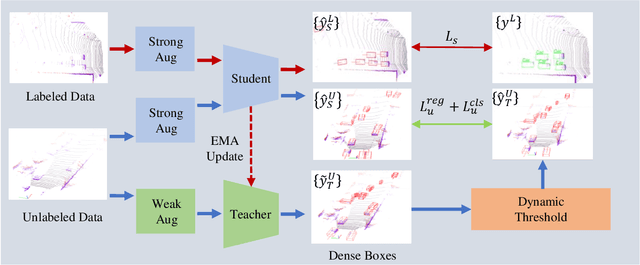
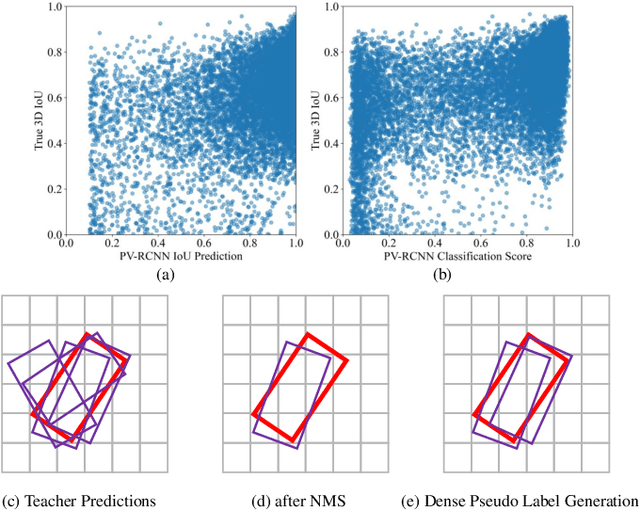
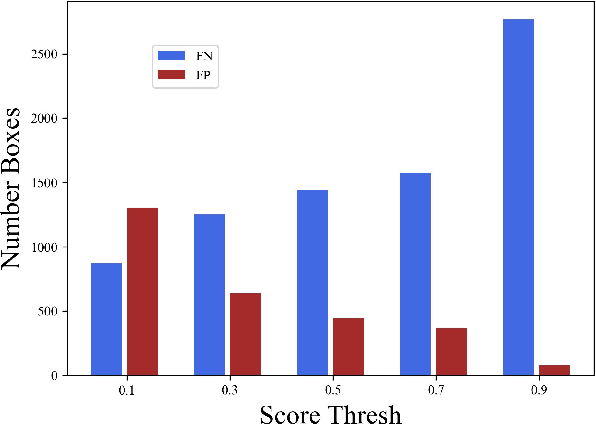
In this paper, we present a simple yet effective semi-supervised 3D object detector named DDS3D. Our main contributions have two-fold. On the one hand, different from previous works using Non-Maximal Suppression (NMS) or its variants for obtaining the sparse pseudo labels, we propose a dense pseudo-label generation strategy to get dense pseudo-labels, which can retain more potential supervision information for the student network. On the other hand, instead of traditional fixed thresholds, we propose a dynamic threshold manner to generate pseudo-labels, which can guarantee the quality and quantity of pseudo-labels during the whole training process. Benefiting from these two components, our DDS3D outperforms the state-of-the-art semi-supervised 3d object detection with mAP of 3.1% on the pedestrian and 2.1% on the cyclist under the same configuration of 1% samples. Extensive ablation studies on the KITTI dataset demonstrate the effectiveness of our DDS3D. The code and models will be made publicly available at https://github.com/hust-jy/DDS3D
Improving Few-Shot Learning for Talking Face System with TTS Data Augmentation
Mar 09, 2023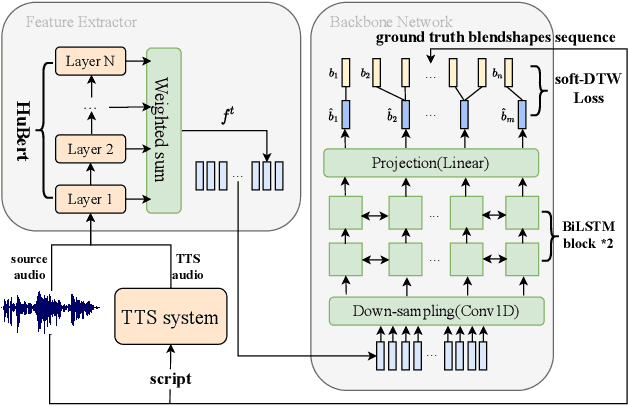
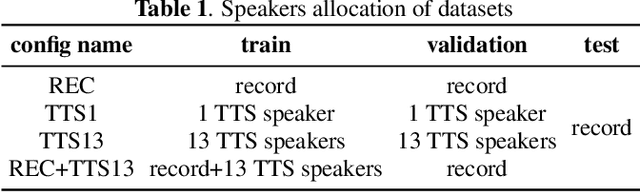
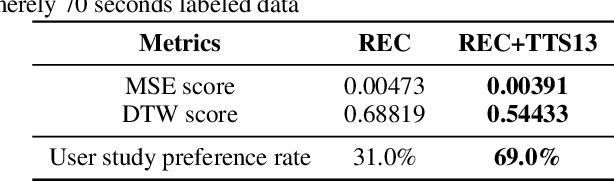
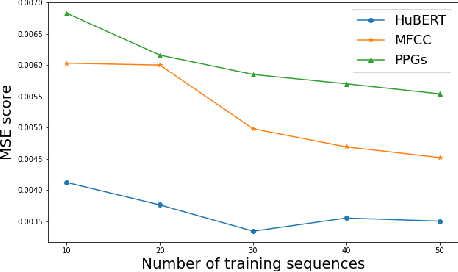
Audio-driven talking face has attracted broad interest from academia and industry recently. However, data acquisition and labeling in audio-driven talking face are labor-intensive and costly. The lack of data resource results in poor synthesis effect. To alleviate this issue, we propose to use TTS (Text-To-Speech) for data augmentation to improve few-shot ability of the talking face system. The misalignment problem brought by the TTS audio is solved with the introduction of soft-DTW, which is first adopted in the talking face task. Moreover, features extracted by HuBERT are explored to utilize underlying information of audio, and found to be superior over other features. The proposed method achieves 17%, 14%, 38% dominance on MSE score, DTW score and user study preference repectively over the baseline model, which shows the effectiveness of improving few-shot learning for talking face system with TTS augmentation.
RiDDLE: Reversible and Diversified De-identification with Latent Encryptor
Mar 09, 2023
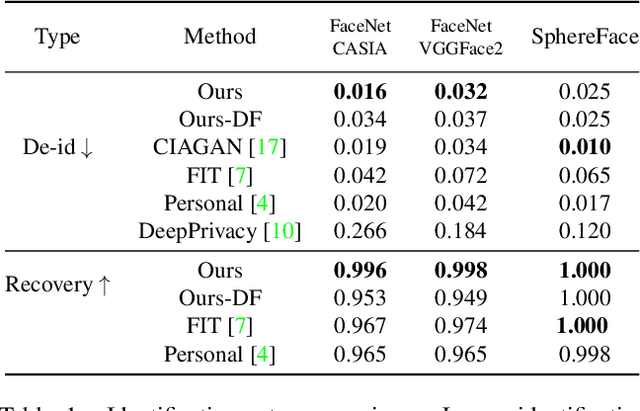
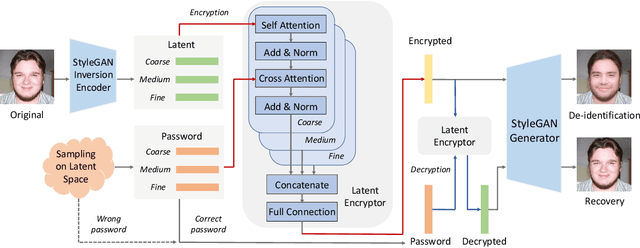
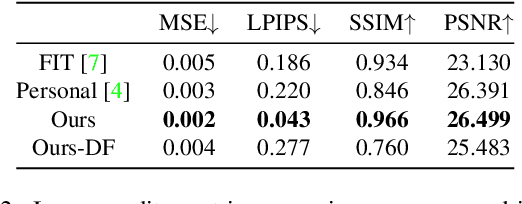
This work presents RiDDLE, short for Reversible and Diversified De-identification with Latent Encryptor, to protect the identity information of people from being misused. Built upon a pre-learned StyleGAN2 generator, RiDDLE manages to encrypt and decrypt the facial identity within the latent space. The design of RiDDLE has three appealing properties. First, the encryption process is cipher-guided and hence allows diverse anonymization using different passwords. Second, the true identity can only be decrypted with the correct password, otherwise the system will produce another de-identified face to maintain the privacy. Third, both encryption and decryption share an efficient implementation, benefiting from a carefully tailored lightweight encryptor. Comparisons with existing alternatives confirm that our approach accomplishes the de-identification task with better quality, higher diversity, and stronger reversibility. We further demonstrate the effectiveness of RiDDLE in anonymizing videos. Code and models will be made publicly available.
Fusing Visual Appearance and Geometry for Multi-modality 6DoF Object Tracking
Feb 22, 2023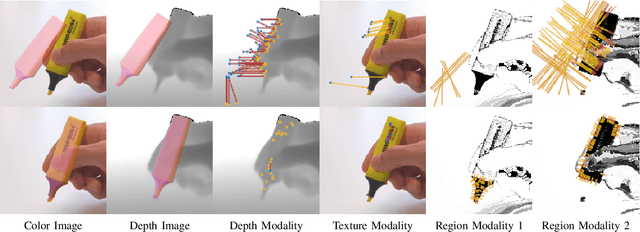
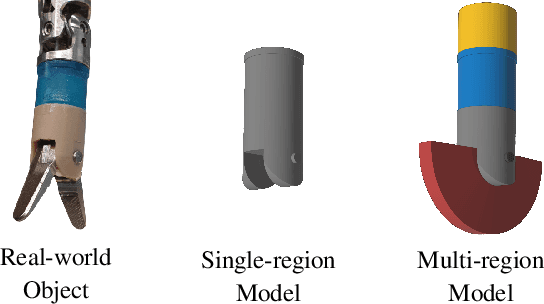
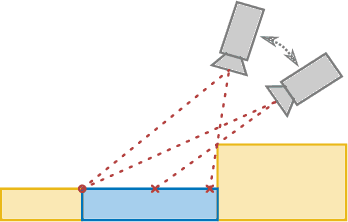
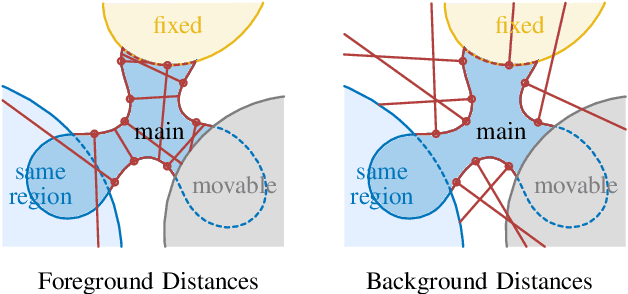
In many applications of advanced robotic manipulation, six degrees of freedom (6DoF) object pose estimates are continuously required. In this work, we develop a multi-modality tracker that fuses information from visual appearance and geometry to estimate object poses. The algorithm extends our previous method ICG, which uses geometry, to additionally consider surface appearance. In general, object surfaces contain local characteristics from text, graphics, and patterns, as well as global differences from distinct materials and colors. To incorporate this visual information, two modalities are developed. For local characteristics, keypoint features are used to minimize distances between points from keyframes and the current image. For global differences, a novel region approach is developed that considers multiple regions on the object surface. In addition, it allows the modeling of external geometries. Experiments on the YCB-Video and OPT datasets demonstrate that our approach ICG+ performs best on both datasets, outperforming both conventional and deep learning-based methods. At the same time, the algorithm is highly efficient and runs at more than 300 Hz. The source code of our tracker is publicly available.
Envisioning the Next-Gen Document Reader
Feb 15, 2023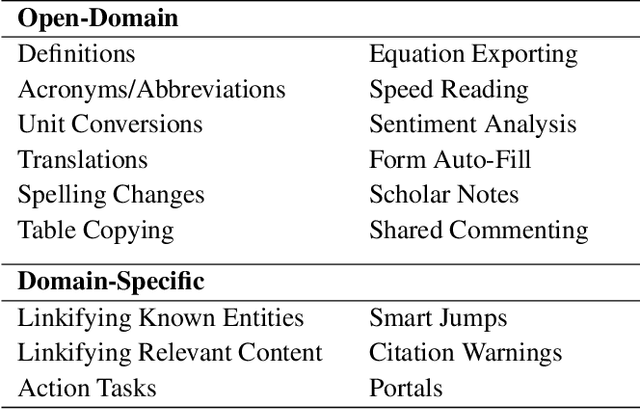
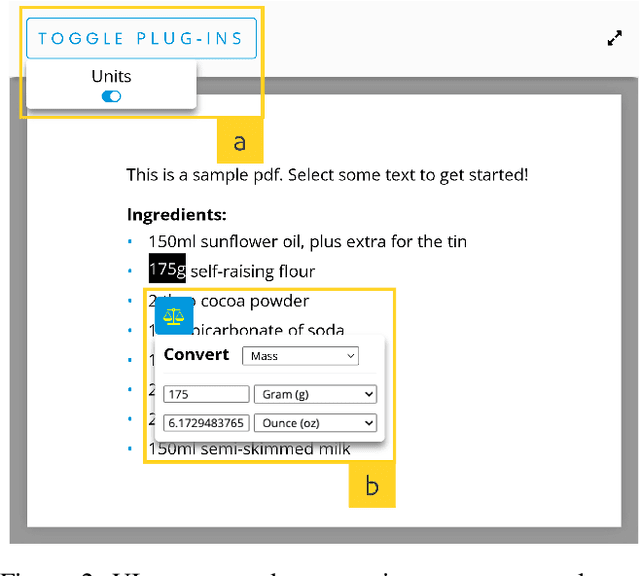

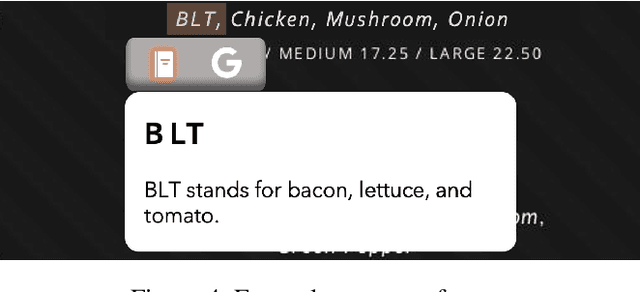
People read digital documents on a daily basis to share, exchange, and understand information in electronic settings. However, current document readers create a static, isolated reading experience, which does not support users' goals of gaining more knowledge and performing additional tasks through document interaction. In this work, we present our vision for the next-gen document reader that strives to enhance user understanding and create a more connected, trustworthy information experience. We describe 18 NLP-powered features to add to existing document readers and propose a novel plug-in marketplace that allows users to further customize their reading experience, as demonstrated through 3 exploratory UI prototypes available at https://github.com/catherinesyeh/nextgen-prototypes
TRUSformer: Improving Prostate Cancer Detection from Micro-Ultrasound Using Attention and Self-Supervision
Mar 03, 2023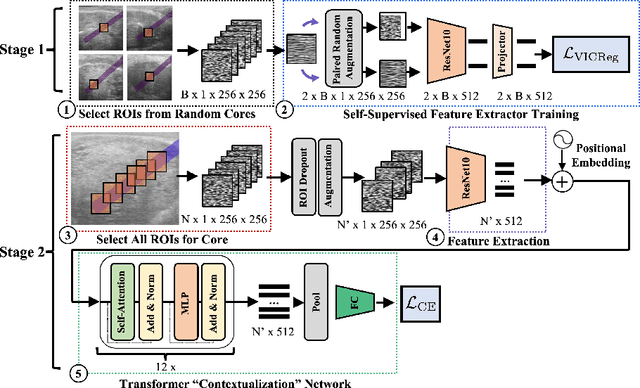
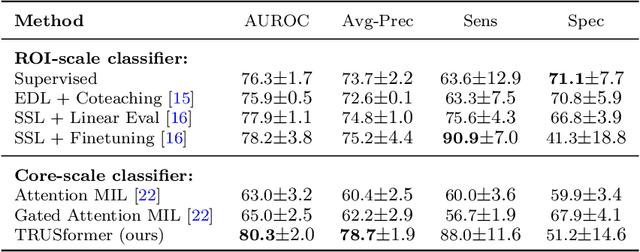
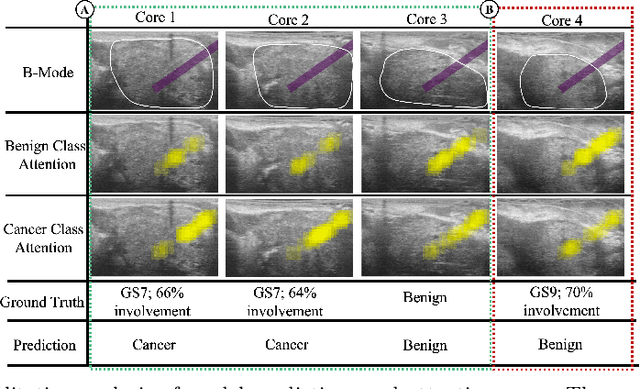

A large body of previous machine learning methods for ultrasound-based prostate cancer detection classify small regions of interest (ROIs) of ultrasound signals that lie within a larger needle trace corresponding to a prostate tissue biopsy (called biopsy core). These ROI-scale models suffer from weak labeling as histopathology results available for biopsy cores only approximate the distribution of cancer in the ROIs. ROI-scale models do not take advantage of contextual information that are normally considered by pathologists, i.e. they do not consider information about surrounding tissue and larger-scale trends when identifying cancer. We aim to improve cancer detection by taking a multi-scale, i.e. ROI-scale and biopsy core-scale, approach. Methods: Our multi-scale approach combines (i) an "ROI-scale" model trained using self-supervised learning to extract features from small ROIs and (ii) a "core-scale" transformer model that processes a collection of extracted features from multiple ROIs in the needle trace region to predict the tissue type of the corresponding core. Attention maps, as a byproduct, allow us to localize cancer at the ROI scale. We analyze this method using a dataset of micro-ultrasound acquired from 578 patients who underwent prostate biopsy, and compare our model to baseline models and other large-scale studies in the literature. Results and Conclusions: Our model shows consistent and substantial performance improvements compared to ROI-scale-only models. It achieves 80.3% AUROC, a statistically significant improvement over ROI-scale classification. We also compare our method to large studies on prostate cancer detection, using other imaging modalities. Our code is publicly available at www.github.com/med-i-lab/TRUSFormer