 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCI-Net: A Robust Multi-Domain Context Integration Network for Point Cloud Registration
Dec 29, 2025Robust and discriminative feature learning is critical for high-quality point cloud registration. However, existing deep learning-based methods typically rely on Euclidean neighborhood-based strategies for feature extraction, which struggle to effectively capture the implicit semantics and structural consistency in point clouds. To address these issues, we propose a multi-domain context integration network (MCI-Net) that improves feature representation and registration performance by aggregating contextual cues from diverse domains. Specifically, we propose a graph neighborhood aggregation module, which constructs a global graph to capture the overall structural relationships within point clouds. We then propose a progressive context interaction module to enhance feature discriminability by performing intra-domain feature decoupling and inter-domain context interaction. Finally, we design a dynamic inlier selection method that optimizes inlier weights using residual information from multiple iterations of pose estimation, thereby improving the accuracy and robustness of registration. Extensive experiments on indoor RGB-D and outdoor LiDAR datasets show that the proposed MCI-Net significantly outperforms existing state-of-the-art methods, achieving the highest registration recall of 96.4\% on 3DMatch. Source code is available at http://www.linshuyuan.com.
Blind Image Quality Assessment: A Brief Survey
Dec 27, 2023Blind Image Quality Assessment (BIQA) is essential for automatically evaluating the perceptual quality of visual signals without access to the references. In this survey, we provide a comprehensive analysis and discussion of recent developments in the field of BIQA. We have covered various aspects, including hand-crafted BIQAs that focus on distortion-specific and general-purpose methods, as well as deep-learned BIQAs that employ supervised and unsupervised learning techniques. Additionally, we have explored multimodal quality assessment methods that consider interactions between visual and audio modalities, as well as visual and text modalities. Finally, we have offered insights into representative BIQA databases, including both synthetic and authentic distortions. We believe this survey provides valuable understandings into the latest developments and emerging trends for the visual quality community.
Prompt Engineering-assisted Malware Dynamic Analysis Using GPT-4
Dec 13, 2023



Dynamic analysis methods effectively identify shelled, wrapped, or obfuscated malware, thereby preventing them from invading computers. As a significant representation of dynamic malware behavior, the API (Application Programming Interface) sequence, comprised of consecutive API calls, has progressively become the dominant feature of dynamic analysis methods. Though there have been numerous deep learning models for malware detection based on API sequences, the quality of API call representations produced by those models is limited. These models cannot generate representations for unknown API calls, which weakens both the detection performance and the generalization. Further, the concept drift phenomenon of API calls is prominent. To tackle these issues, we introduce a prompt engineering-assisted malware dynamic analysis using GPT-4. In this method, GPT-4 is employed to create explanatory text for each API call within the API sequence. Afterward, the pre-trained language model BERT is used to obtain the representation of the text, from which we derive the representation of the API sequence. Theoretically, this proposed method is capable of generating representations for all API calls, excluding the necessity for dataset training during the generation process. Utilizing the representation, a CNN-based detection model is designed to extract the feature. We adopt five benchmark datasets to validate the performance of the proposed model. The experimental results reveal that the proposed detection algorithm performs better than the state-of-the-art method (TextCNN). Specifically, in cross-database experiments and few-shot learning experiments, the proposed model achieves excellent detection performance and almost a 100% recall rate for malware, verifying its superior generalization performance. The code is available at: github.com/yan-scnu/Prompted_Dynamic_Detection.
CVSformer: Cross-View Synthesis Transformer for Semantic Scene Completion
Jul 16, 2023Semantic scene completion (SSC) requires an accurate understanding of the geometric and semantic relationships between the objects in the 3D scene for reasoning the occluded objects. The popular SSC methods voxelize the 3D objects, allowing the deep 3D convolutional network (3D CNN) to learn the object relationships from the complex scenes. However, the current networks lack the controllable kernels to model the object relationship across multiple views, where appropriate views provide the relevant information for suggesting the existence of the occluded objects. In this paper, we propose Cross-View Synthesis Transformer (CVSformer), which consists of Multi-View Feature Synthesis and Cross-View Transformer for learning cross-view object relationships. In the multi-view feature synthesis, we use a set of 3D convolutional kernels rotated differently to compute the multi-view features for each voxel. In the cross-view transformer, we employ the cross-view fusion to comprehensively learn the cross-view relationships, which form useful information for enhancing the features of individual views. We use the enhanced features to predict the geometric occupancies and semantic labels of all voxels. We evaluate CVSformer on public datasets, where CVSformer yields state-of-the-art results.
Surface Geometry Processing: An Efficient Normal-based Detail Representation
Jul 16, 2023



With the rapid development of high-resolution 3D vision applications, the traditional way of manipulating surface detail requires considerable memory and computing time. To address these problems, we introduce an efficient surface detail processing framework in 2D normal domain, which extracts new normal feature representations as the carrier of micro geometry structures that are illustrated both theoretically and empirically in this article. Compared with the existing state of the arts, we verify and demonstrate that the proposed normal-based representation has three important properties, including detail separability, detail transferability and detail idempotence. Finally, three new schemes are further designed for geometric surface detail processing applications, including geometric texture synthesis, geometry detail transfer, and 3D surface super-resolution. Theoretical analysis and experimental results on the latest benchmark dataset verify the effectiveness and versatility of our normal-based representation, which accepts 30 times of the input surface vertices but at the same time only takes 6.5% memory cost and 14.0% running time in comparison with existing competing algorithms.
* 16 pages, 22 figures
Blind Multimodal Quality Assessment: A Brief Survey and A Case Study of Low-light Images
Mar 18, 2023Blind image quality assessment (BIQA) aims at automatically and accurately forecasting objective scores for visual signals, which has been widely used to monitor product and service quality in low-light applications, covering smartphone photography, video surveillance, autonomous driving, etc. Recent developments in this field are dominated by unimodal solutions inconsistent with human subjective rating patterns, where human visual perception is simultaneously reflected by multiple sensory information (e.g., sight and hearing). In this article, we present a unique blind multimodal quality assessment (BMQA) of low-light images from subjective evaluation to objective score. To investigate the multimodal mechanism, we first establish a multimodal low-light image quality (MLIQ) database with authentic low-light distortions, containing image and audio modality pairs. Further, we specially design the key modules of BMQA, considering multimodal quality representation, latent feature alignment and fusion, and hybrid self-supervised and supervised learning. Extensive experiments show that our BMQA yields state-of-the-art accuracy on the proposed MLIQ benchmark database. In particular, we also build an independent single-image modality Dark-4K database, which is used to verify its applicability and generalization performance in mainstream unimodal applications. Qualitative and quantitative results on Dark-4K show that BMQA achieves superior performance to existing BIQA approaches as long as a pre-trained quality semantic description model is provided. The proposed framework and two databases as well as the collected BIQA methods and evaluation metrics are made publicly available.
Just Noticeable Visual Redundancy Forecasting: A Deep Multimodal-driven Approach
Mar 18, 2023



Just noticeable difference (JND) refers to the maximum visual change that human eyes cannot perceive, and it has a wide range of applications in multimedia systems. However, most existing JND approaches only focus on a single modality, and rarely consider the complementary effects of multimodal information. In this article, we investigate the JND modeling from an end-to-end homologous multimodal perspective, namely hmJND-Net. Specifically, we explore three important visually sensitive modalities, including saliency, depth, and segmentation. To better utilize homologous multimodal information, we establish an effective fusion method via summation enhancement and subtractive offset, and align homologous multimodal features based on a self-attention driven encoder-decoder paradigm. Extensive experimental results on eight different benchmark datasets validate the superiority of our hmJND-Net over eight representative methods.
Scale-aware Two-stage High Dynamic Range Imaging
Mar 12, 2023



Deep high dynamic range (HDR) imaging as an image translation issue has achieved great performance without explicit optical flow alignment. However, challenges remain over content association ambiguities especially caused by saturation and large-scale movements. To address the ghosting issue and enhance the details in saturated regions, we propose a scale-aware two-stage high dynamic range imaging framework (STHDR) to generate high-quality ghost-free HDR image. The scale-aware technique and two-stage fusion strategy can progressively and effectively improve the HDR composition performance. Specifically, our framework consists of feature alignment and two-stage fusion. In feature alignment, we propose a spatial correct module (SCM) to better exploit useful information among non-aligned features to avoid ghosting and saturation. In the first stage of feature fusion, we obtain a preliminary fusion result with little ghosting. In the second stage, we conflate the results of the first stage with aligned features to further reduce residual artifacts and thus improve the overall quality. Extensive experimental results on the typical test dataset validate the effectiveness of the proposed STHDR in terms of speed and quality.
Advanced Geometry Surface Coding for Dynamic Point Cloud Compression
Mar 11, 2021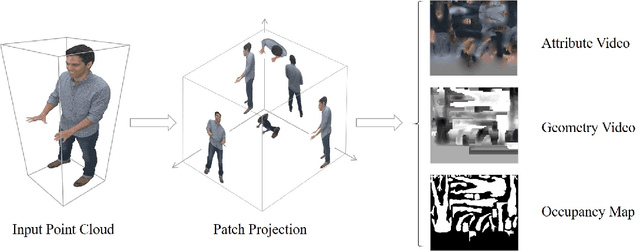
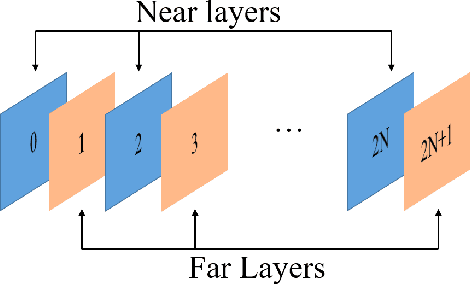
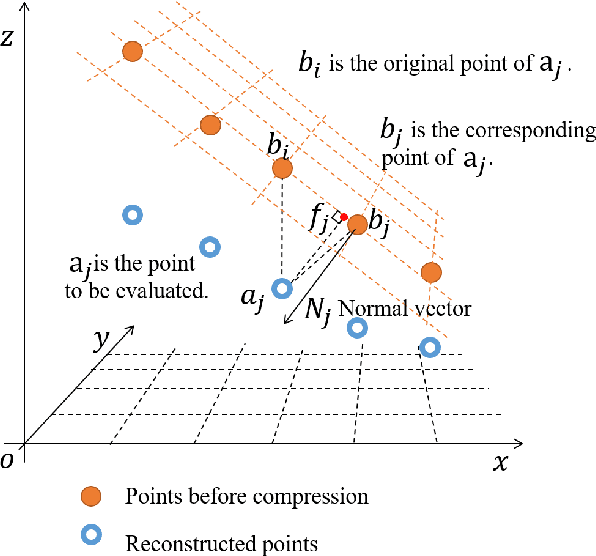
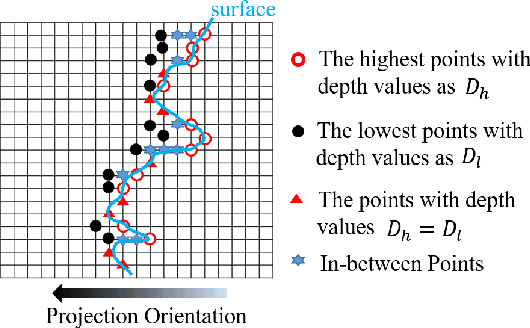
In video-based dynamic point cloud compression (V-PCC), 3D point clouds are projected onto 2D images for compressing with the existing video codecs. However, the existing video codecs are originally designed for natural visual signals, and it fails to account for the characteristics of point clouds. Thus, there are still problems in the compression of geometry information generated from the point clouds. Firstly, the distortion model in the existing rate-distortion optimization (RDO) is not consistent with the geometry quality assessment metrics. Secondly, the prediction methods in video codecs fail to account for the fact that the highest depth values of a far layer is greater than or equal to the corresponding lowest depth values of a near layer. This paper proposes an advanced geometry surface coding (AGSC) method for dynamic point clouds (DPC) compression. The proposed method consists of two modules, including an error projection model-based (EPM-based) RDO and an occupancy map-based (OM-based) merge prediction. Firstly, the EPM model is proposed to describe the relationship between the distortion model in the existing video codec and the geometry quality metric. Secondly, the EPM-based RDO method is presented to project the existing distortion model on the plane normal and is simplified to estimate the average normal vectors of coding units (CUs). Finally, we propose the OM-based merge prediction approach, in which the prediction pixels of merge modes are refined based on the occupancy map. Experiments tested on the standard point clouds show that the proposed method achieves an average 9.84\% bitrate saving for geometry compression.
Quality Classified Image Analysis with Application to Face Detection and Recognition
Jan 19, 2018
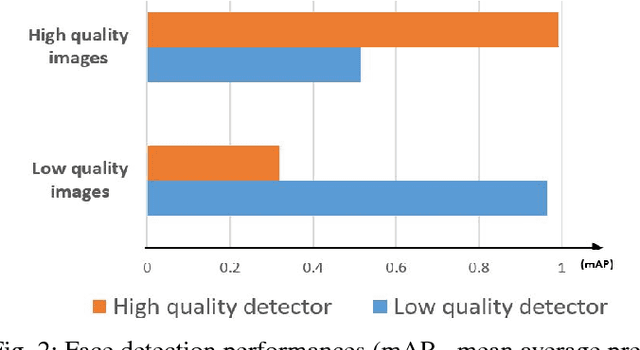
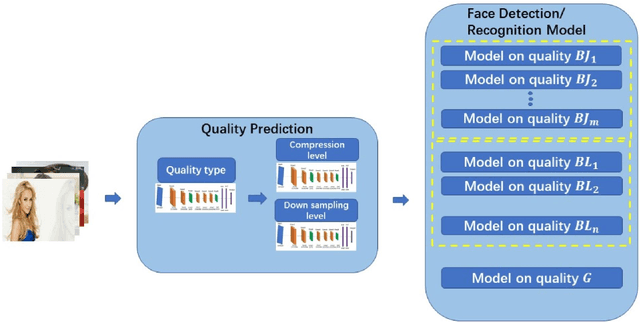
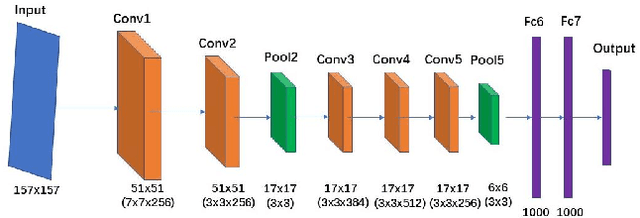
Motion blur, out of focus, insufficient spatial resolution, lossy compression and many other factors can all cause an image to have poor quality. However, image quality is a largely ignored issue in traditional pattern recognition literature. In this paper, we use face detection and recognition as case studies to show that image quality is an essential factor which will affect the performances of traditional algorithms. We demonstrated that it is not the image quality itself that is the most important, but rather the quality of the images in the training set should have similar quality as those in the testing set. To handle real-world application scenarios where images with different kinds and severities of degradation can be presented to the system, we have developed a quality classified image analysis framework to deal with images of mixed qualities adaptively. We use deep neural networks first to classify images based on their quality classes and then design a separate face detector and recognizer for images in each quality class. We will present experimental results to show that our quality classified framework can accurately classify images based on the type and severity of image degradations and can significantly boost the performances of state-of-the-art face detector and recognizer in dealing with image datasets containing mixed quality images.