 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInject Semantic Concepts into Image Tagging for Open-Set Recognition
Oct 23, 2023



In this paper, we introduce the Recognize Anything Plus Model~(RAM++), a fundamental image recognition model with strong open-set recognition capabilities, by injecting semantic concepts into image tagging training framework. Previous approaches are either image tagging models constrained by limited semantics, or vision-language models with shallow interaction for suboptimal performance in multi-tag recognition. In contrast, RAM++ integrates image-text alignment and image-tagging within a unified fine-grained interaction framework based on image-tags-text triplets. This design enables RAM++ not only excel in identifying predefined categories, but also significantly augment the recognition ability in open-set categories. Moreover, RAM++ employs large language models~(LLMs) to generate diverse visual tag descriptions, pioneering the integration of LLM's knowledge into image tagging training. This approach empowers RAM++ to integrate visual description concepts for open-set recognition during inference. Evaluations on comprehensive image recognition benchmarks demonstrate RAM++ exceeds existing state-of-the-art (SOTA) fundamental image recognition models on most aspects. Specifically, for predefined common-used tag categories, RAM++ showcases 10.2 mAP and 15.4 mAP enhancements over CLIP on OpenImages and ImageNet. For open-set categories beyond predefined, RAM++ records improvements of 5 mAP and 6.4 mAP over CLIP and RAM respectively on OpenImages. For diverse human-object interaction phrases, RAM++ achieves 7.8 mAP and 4.7 mAP improvements on the HICO benchmark. Code, datasets and pre-trained models are available at \url{https://github.com/xinyu1205/recognize-anything}.
Recognize Anything: A Strong Image Tagging Model
Jun 09, 2023



We present the Recognize Anything Model (RAM): a strong foundation model for image tagging. RAM makes a substantial step for large models in computer vision, demonstrating the zero-shot ability to recognize any common category with high accuracy. RAM introduces a new paradigm for image tagging, leveraging large-scale image-text pairs for training instead of manual annotations. The development of RAM comprises four key steps. Firstly, annotation-free image tags are obtained at scale through automatic text semantic parsing. Subsequently, a preliminary model is trained for automatic annotation by unifying the caption and tagging tasks, supervised by the original texts and parsed tags, respectively. Thirdly, a data engine is employed to generate additional annotations and clean incorrect ones. Lastly, the model is retrained with the processed data and fine-tuned using a smaller but higher-quality dataset. We evaluate the tagging capabilities of RAM on numerous benchmarks and observe impressive zero-shot performance, significantly outperforming CLIP and BLIP. Remarkably, RAM even surpasses the fully supervised manners and exhibits competitive performance with the Google tagging API. We are releasing the RAM at \url{https://recognize-anything.github.io/} to foster the advancements of large models in computer vision.
Knowledge Distillation from Single to Multi Labels: an Empirical Study
Mar 15, 2023



Knowledge distillation (KD) has been extensively studied in single-label image classification. However, its efficacy for multi-label classification remains relatively unexplored. In this study, we firstly investigate the effectiveness of classical KD techniques, including logit-based and feature-based methods, for multi-label classification. Our findings indicate that the logit-based method is not well-suited for multi-label classification, as the teacher fails to provide inter-category similarity information or regularization effect on student model's training. Moreover, we observe that feature-based methods struggle to convey compact information of multiple labels simultaneously. Given these limitations, we propose that a suitable dark knowledge should incorporate class-wise information and be highly correlated with the final classification results. To address these issues, we introduce a novel distillation method based on Class Activation Maps (CAMs), which is both effective and straightforward to implement. Across a wide range of settings, CAMs-based distillation consistently outperforms other methods.
Tag2Text: Guiding Vision-Language Model via Image Tagging
Mar 10, 2023



This paper presents Tag2Text, a vision language pre-training (VLP) framework, which introduces image tagging into vision-language models to guide the learning of visual-linguistic features. In contrast to prior works which utilize object tags either manually labeled or automatically detected with a limited detector, our approach utilizes tags parsed from its paired text to learn an image tagger and meanwhile provides guidance to vision-language models. Given that, Tag2Text can utilize large-scale annotation-free image tags in accordance with image-text pairs, and provides more diverse tag categories beyond objects. As a result, Tag2Text achieves a superior image tag recognition ability by exploiting fine-grained text information. Moreover, by leveraging tagging guidance, Tag2Text effectively enhances the performance of vision-language models on both generation-based and alignment-based tasks. Across a wide range of downstream benchmarks, Tag2Text achieves state-of-the-art or competitive results with similar model sizes and data scales, demonstrating the efficacy of the proposed tagging guidance.
IDEA: Increasing Text Diversity via Online Multi-Label Recognition for Vision-Language Pre-training
Jul 12, 2022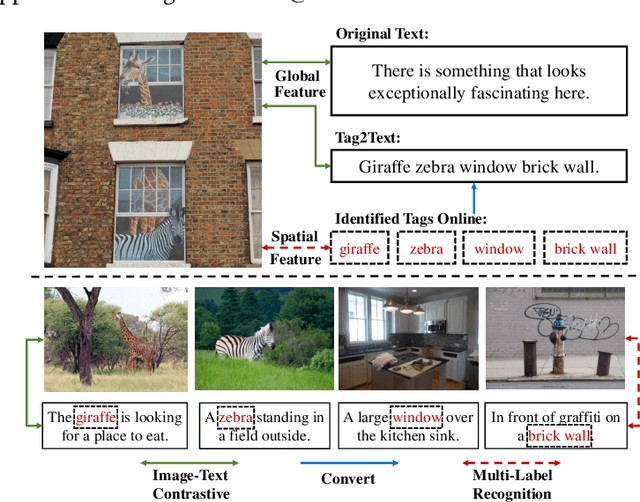
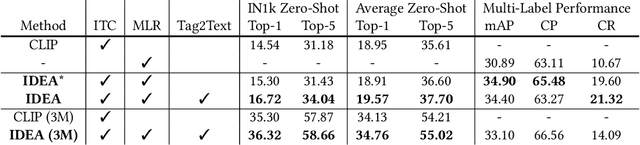
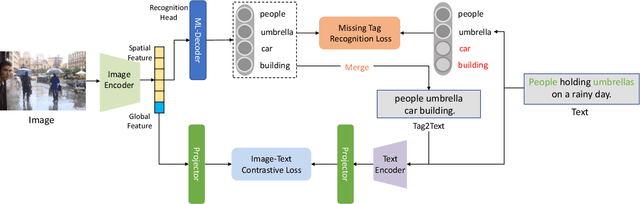
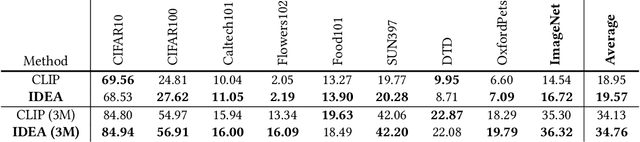
Vision-Language Pre-training (VLP) with large-scale image-text pairs has demonstrated superior performance in various fields. However, the image-text pairs co-occurrent on the Internet typically lack explicit alignment information, which is suboptimal for VLP. Existing methods proposed to adopt an off-the-shelf object detector to utilize additional image tag information. However, the object detector is time-consuming and can only identify the pre-defined object categories, limiting the model capacity. Inspired by the observation that the texts incorporate incomplete fine-grained image information, we introduce IDEA, which stands for increasing text diversity via online multi-label recognition for VLP. IDEA shows that multi-label learning with image tags extracted from the texts can be jointly optimized during VLP. Moreover, IDEA can identify valuable image tags online to provide more explicit textual supervision. Comprehensive experiments demonstrate that IDEA can significantly boost the performance on multiple downstream datasets with a small extra computational cost.
Simple and Robust Loss Design for Multi-Label Learning with Missing Labels
Dec 27, 2021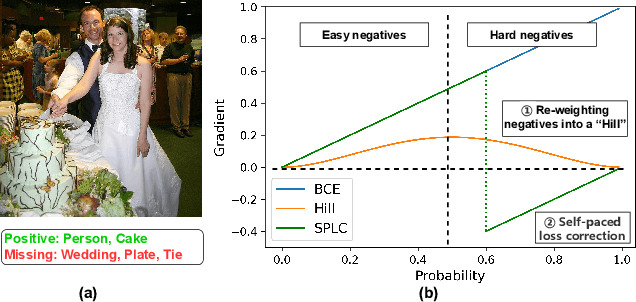
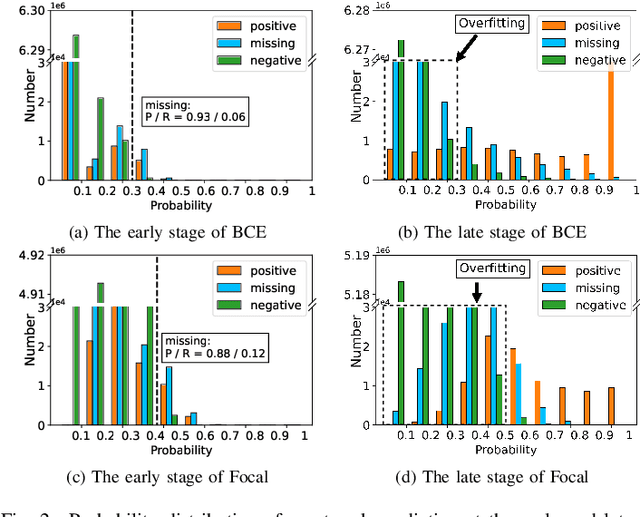
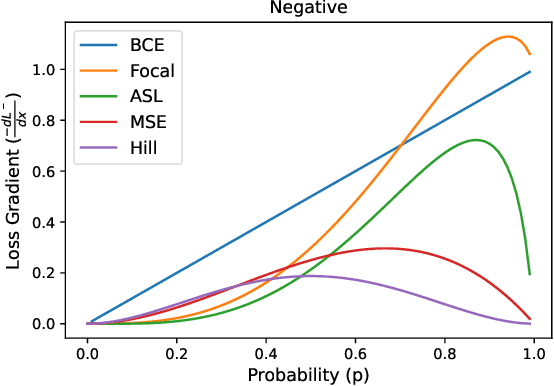
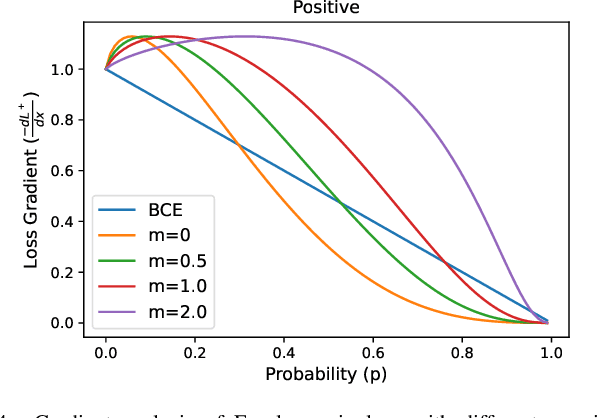
Multi-label learning in the presence of missing labels (MLML) is a challenging problem. Existing methods mainly focus on the design of network structures or training schemes, which increase the complexity of implementation. This work seeks to fulfill the potential of loss function in MLML without increasing the procedure and complexity. Toward this end, we propose two simple yet effective methods via robust loss design based on an observation that a model can identify missing labels during training with a high precision. The first is a novel robust loss for negatives, namely the Hill loss, which re-weights negatives in the shape of a hill to alleviate the effect of false negatives. The second is a self-paced loss correction (SPLC) method, which uses a loss derived from the maximum likelihood criterion under an approximate distribution of missing labels. Comprehensive experiments on a vast range of multi-label image classification datasets demonstrate that our methods can remarkably boost the performance of MLML and achieve new state-of-the-art loss functions in MLML.
Federated Self-Supervised Contrastive Learning via Ensemble Similarity Distillation
Sep 29, 2021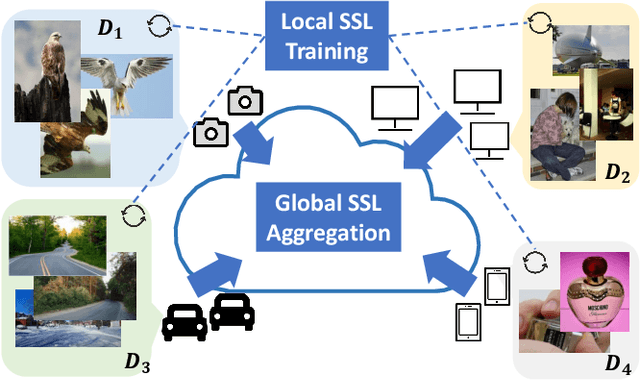
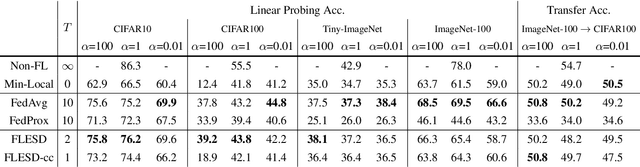
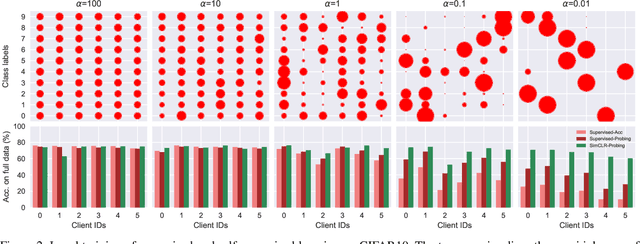
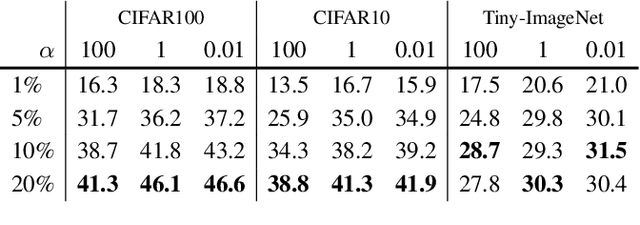
This paper investigates the feasibility of learning good representation space with unlabeled client data in the federated scenario. Existing works trivially inherit the supervised federated learning methods, which does not apply to the model heterogeneity and has the potential risk of privacy exposure. To tackle the problems above, we first identify that self-supervised contrastive local training is more robust against the non-i.i.d.-ness than the traditional supervised learning paradigm. Then we propose a novel federated self-supervised contrastive learning framework FLESD that supports architecture-agnostic local training and communication-efficient global aggregation. At each round of communication, the server first gathers a fraction of the clients' inferred similarity matrices on a public dataset. Then FLESD ensembles the similarity matrices and trains the global model via similarity distillation. We verify the effectiveness of our proposed framework by a series of empirical experiments and show that FLESD has three main advantages over the existing methods: it handles the model heterogeneity, is less prone to privacy leak, and is more communication-efficient. We will release the code of this paper in the future.
On the Efficacy of Small Self-Supervised Contrastive Models without Distillation Signals
Jul 30, 2021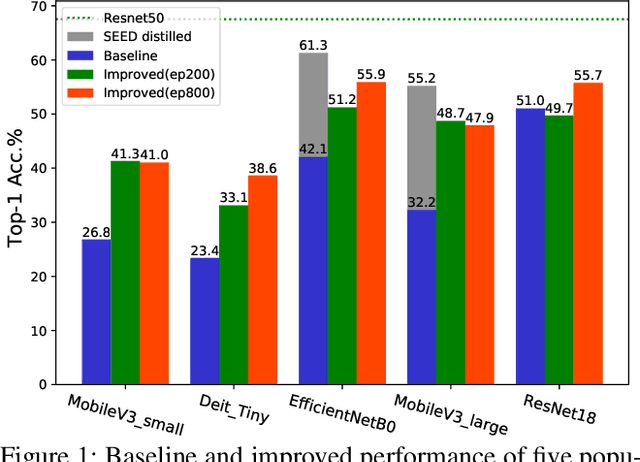
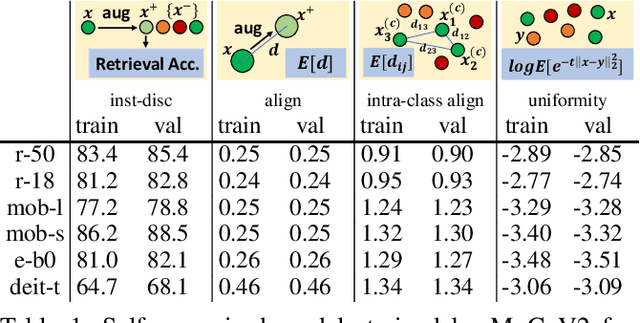

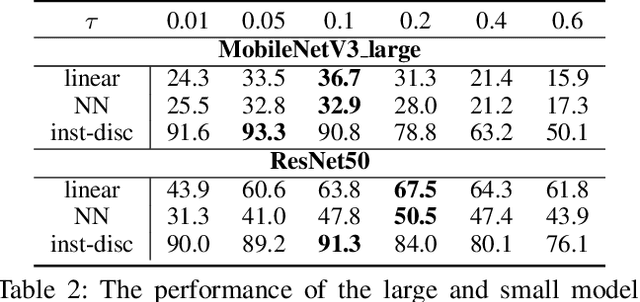
It is a consensus that small models perform quite poorly under the paradigm of self-supervised contrastive learning. Existing methods usually adopt a large off-the-shelf model to transfer knowledge to the small one via knowledge distillation. Despite their effectiveness, distillation-based methods may not be suitable for some resource-restricted scenarios due to the huge computational expenses of deploying a large model. In this paper, we study the issue of training self-supervised small models without distillation signals. We first evaluate the representation spaces of the small models and make two non-negligible observations: (i) small models can complete the pretext task without overfitting despite its limited capacity; (ii) small models universally suffer the problem of over-clustering. Then we verify multiple assumptions that are considered to alleviate the over-clustering phenomenon. Finally, we combine the validated techniques and improve the baseline of five small architectures with considerable margins, which indicates that training small self-supervised contrastive models is feasible even without distillation signals.
Prime-Aware Adaptive Distillation
Aug 04, 2020
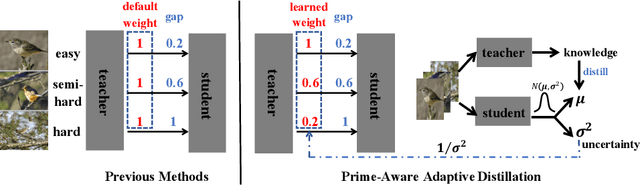
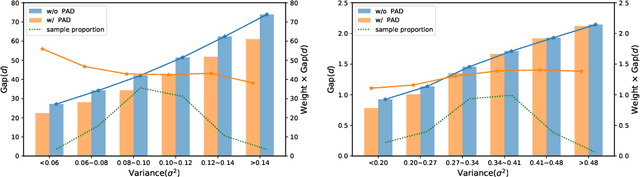

Knowledge distillation(KD) aims to improve the performance of a student network by mimicing the knowledge from a powerful teacher network. Existing methods focus on studying what knowledge should be transferred and treat all samples equally during training. This paper introduces the adaptive sample weighting to KD. We discover that previous effective hard mining methods are not appropriate for distillation. Furthermore, we propose Prime-Aware Adaptive Distillation (PAD) by the incorporation of uncertainty learning. PAD perceives the prime samples in distillation and then emphasizes their effect adaptively. PAD is fundamentally different from and would refine existing methods with the innovative view of unequal training. For this reason, PAD is versatile and has been applied in various tasks including classification, metric learning, and object detection. With ten teacher-student combinations on six datasets, PAD promotes the performance of existing distillation methods and outperforms recent state-of-the-art methods.