 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAE-based Phoneme Alignment Using Gradient Annealing and SSL Acoustic Features
Jul 03, 2024



This paper presents an accurate phoneme alignment model that aims for speech analysis and video content creation. We propose a variational autoencoder (VAE)-based alignment model in which a probable path is searched using encoded acoustic and linguistic embeddings in an unsupervised manner. Our proposed model is based on one TTS alignment (OTA) and extended to obtain phoneme boundaries. Specifically, we incorporate a VAE architecture to maintain consistency between the embedding and input, apply gradient annealing to avoid local optimum during training, and introduce a self-supervised learning (SSL)-based acoustic-feature input and state-level linguistic unit to utilize rich and detailed information. Experimental results show that the proposed model generated phoneme boundaries closer to annotated ones compared with the conventional OTA model, the CTC-based segmentation model, and the widely-used tool MFA.
An Attribute Interpolation Method in Speech Synthesis by Model Merging
Jun 30, 2024With the development of speech synthesis, recent research has focused on challenging tasks, such as speaker generation and emotion intensity control. Attribute interpolation is a common approach to these tasks. However, most previous methods for attribute interpolation require specific modules or training methods. We propose an attribute interpolation method in speech synthesis by model merging. Model merging is a method that creates new parameters by only averaging the parameters of base models. The merged model can generate an output with an intermediate feature of the base models. This method is easily applicable without specific modules or training methods, as it uses only existing trained base models. We merged two text-to-speech models to achieve attribute interpolation and evaluated its performance on speaker generation and emotion intensity control tasks. As a result, our proposed method achieved smooth attribute interpolation while keeping the linguistic content in both tasks.
Frame-Wise Breath Detection with Self-Training: An Exploration of Enhancing Breath Naturalness in Text-to-Speech
Feb 01, 2024Developing Text-to-Speech (TTS) systems that can synthesize natural breath is essential for human-like voice agents but requires extensive manual annotation of breath positions in training data. To this end, we propose a self-training method for training a breath detection model that can automatically detect breath positions in speech. Our method trains the model using a large speech corpus and involves: 1) annotation of limited breath sounds utilizing a rule-based approach, and 2) iterative augmentation of these annotations through pseudo-labeling based on the model's predictions. Our detection model employs Conformer blocks with down-/up-sampling layers, enabling accurate frame-wise breath detection. We investigate its effectiveness in multi-speaker TTS using text transcripts with detected breath marks. The results indicate that using our proposed model for breath detection and breath mark insertion synthesizes breath-contained speech more naturally than a baseline model.
Duration-aware pause insertion using pre-trained language model for multi-speaker text-to-speech
Feb 27, 2023



Pause insertion, also known as phrase break prediction and phrasing, is an essential part of TTS systems because proper pauses with natural duration significantly enhance the rhythm and intelligibility of synthetic speech. However, conventional phrasing models ignore various speakers' different styles of inserting silent pauses, which can degrade the performance of the model trained on a multi-speaker speech corpus. To this end, we propose more powerful pause insertion frameworks based on a pre-trained language model. Our approach uses bidirectional encoder representations from transformers (BERT) pre-trained on a large-scale text corpus, injecting speaker embedding to capture various speaker characteristics. We also leverage duration-aware pause insertion for more natural multi-speaker TTS. We develop and evaluate two types of models. The first improves conventional phrasing models on the position prediction of respiratory pauses (RPs), i.e., silent pauses at word transitions without punctuation. It performs speaker-conditioned RP prediction considering contextual information and is used to demonstrate the effect of speaker information on the prediction. The second model is further designed for phoneme-based TTS models and performs duration-aware pause insertion, predicting both RPs and punctuation-indicated pauses (PIPs) that are categorized by duration. The evaluation results show that our models improve the precision and recall of pause insertion and the rhythm of synthetic speech.
Structured State Space Decoder for Speech Recognition and Synthesis
Oct 31, 2022Automatic speech recognition (ASR) systems developed in recent years have shown promising results with self-attention models (e.g., Transformer and Conformer), which are replacing conventional recurrent neural networks. Meanwhile, a structured state space model (S4) has been recently proposed, producing promising results for various long-sequence modeling tasks, including raw speech classification. The S4 model can be trained in parallel, same as the Transformer model. In this study, we applied S4 as a decoder for ASR and text-to-speech (TTS) tasks by comparing it with the Transformer decoder. For the ASR task, our experimental results demonstrate that the proposed model achieves a competitive word error rate (WER) of 1.88%/4.25% on LibriSpeech test-clean/test-other set and a character error rate (CER) of 3.80%/2.63%/2.98% on the CSJ eval1/eval2/eval3 set. Furthermore, the proposed model is more robust than the standard Transformer model, particularly for long-form speech on both the datasets. For the TTS task, the proposed method outperforms the Transformer baseline.
UTMOS: UTokyo-SaruLab System for VoiceMOS Challenge 2022
Apr 05, 2022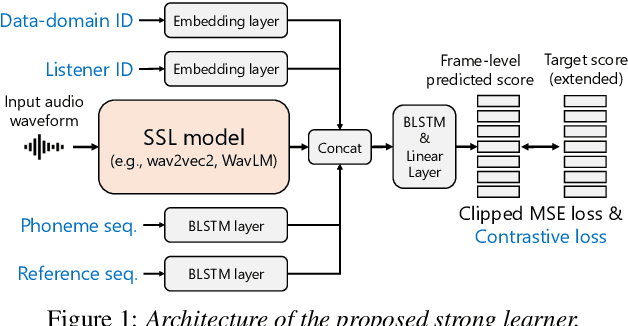
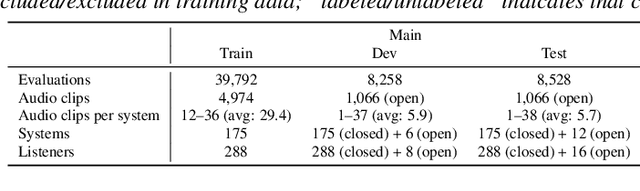
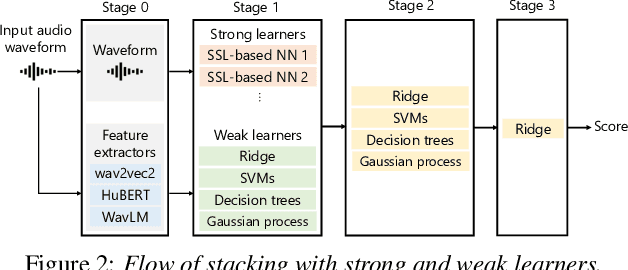
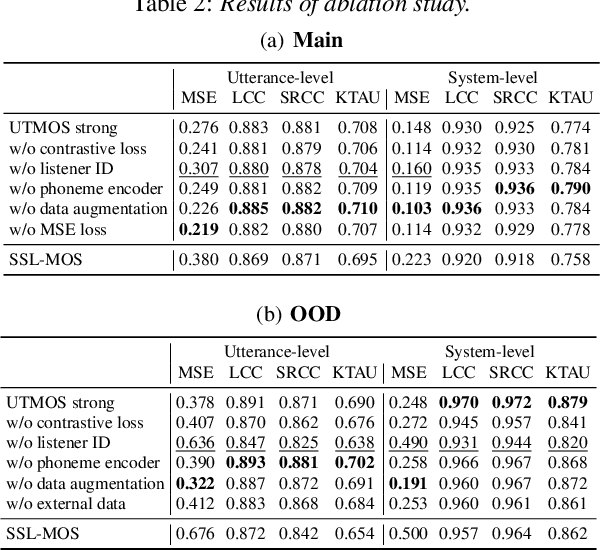
We present the UTokyo-SaruLab mean opinion score (MOS) prediction system submitted to VoiceMOS Challenge 2022. The challenge is to predict the MOS values of speech samples collected from previous Blizzard Challenges and Voice Conversion Challenges for two tracks: a main track for in-domain prediction and an out-of-domain (OOD) track for which there is less labeled data from different listening tests. Our system is based on ensemble learning of strong and weak learners. Strong learners incorporate several improvements to the previous fine-tuning models of self-supervised learning (SSL) models, while weak learners use basic machine-learning methods to predict scores from SSL features. In the Challenge, our system had the highest score on several metrics for both the main and OOD tracks. In addition, we conducted ablation studies to investigate the effectiveness of our proposed methods.
Multi-speaker Text-to-speech Synthesis Using Deep Gaussian Processes
Aug 07, 2020



Multi-speaker speech synthesis is a technique for modeling multiple speakers' voices with a single model. Although many approaches using deep neural networks (DNNs) have been proposed, DNNs are prone to overfitting when the amount of training data is limited. We propose a framework for multi-speaker speech synthesis using deep Gaussian processes (DGPs); a DGP is a deep architecture of Bayesian kernel regressions and thus robust to overfitting. In this framework, speaker information is fed to duration/acoustic models using speaker codes. We also examine the use of deep Gaussian process latent variable models (DGPLVMs). In this approach, the representation of each speaker is learned simultaneously with other model parameters, and therefore the similarity or dissimilarity of speakers is considered efficiently. We experimentally evaluated two situations to investigate the effectiveness of the proposed methods. In one situation, the amount of data from each speaker is balanced (speaker-balanced), and in the other, the data from certain speakers are limited (speaker-imbalanced). Subjective and objective evaluation results showed that both the DGP and DGPLVM synthesize multi-speaker speech more effective than a DNN in the speaker-balanced situation. We also found that the DGPLVM outperforms the DGP significantly in the speaker-imbalanced situation.
Utterance-level Sequential Modeling For Deep Gaussian Process Based Speech Synthesis Using Simple Recurrent Unit
Apr 22, 2020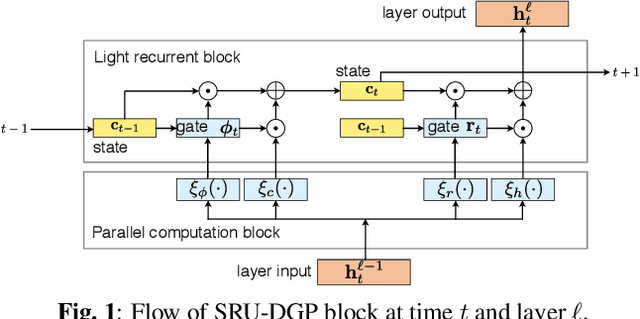
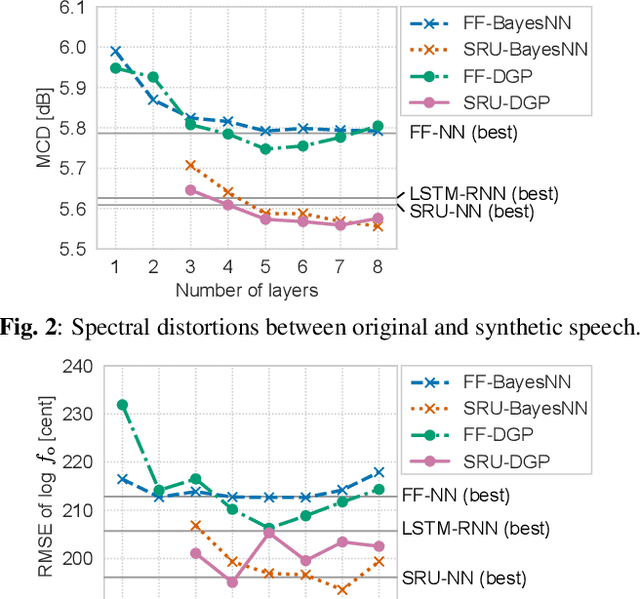
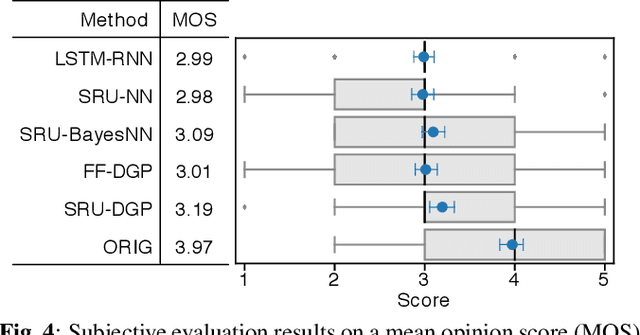
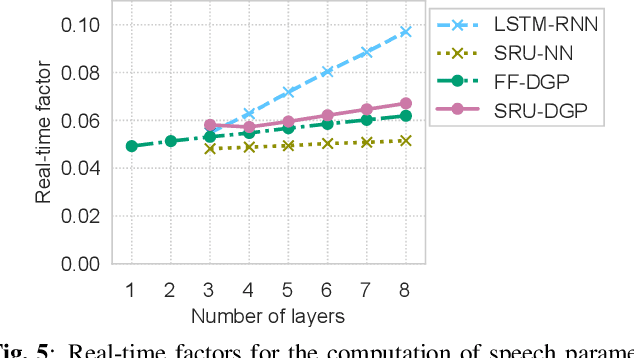
This paper presents a deep Gaussian process (DGP) model with a recurrent architecture for speech sequence modeling. DGP is a Bayesian deep model that can be trained effectively with the consideration of model complexity and is a kernel regression model that can have high expressibility. In the previous studies, it was shown that the DGP-based speech synthesis outperformed neural network-based one, in which both models used a feed-forward architecture. To improve the naturalness of synthetic speech, in this paper, we show that DGP can be applied to utterance-level modeling using recurrent architecture models. We adopt a simple recurrent unit (SRU) for the proposed model to achieve a recurrent architecture, in which we can execute fast speech parameter generation by using the high parallelization nature of SRU. The objective and subjective evaluation results show that the proposed SRU-DGP-based speech synthesis outperforms not only feed-forward DGP but also automatically tuned SRU- and long short-term memory (LSTM)-based neural networks.
Generative Moment Matching Network-based Random Modulation Post-filter for DNN-based Singing Voice Synthesis and Neural Double-tracking
Feb 09, 2019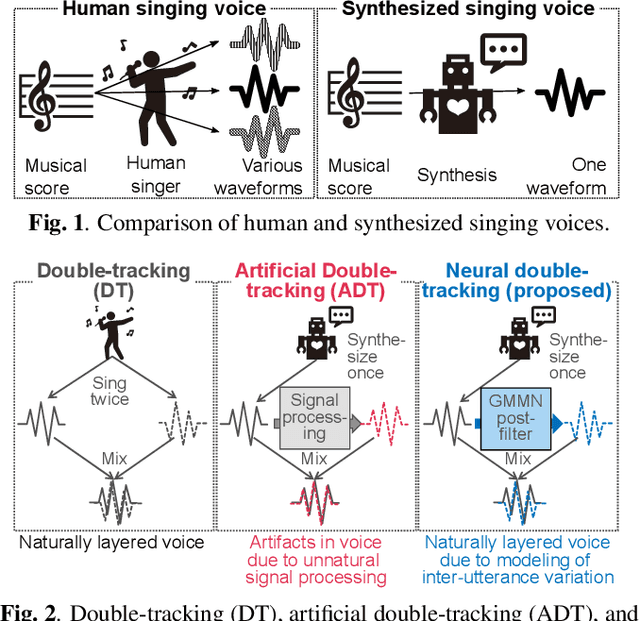
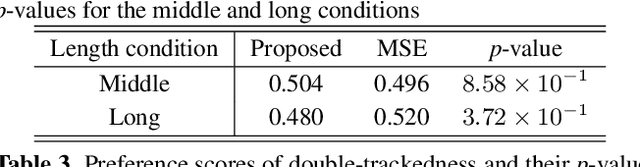
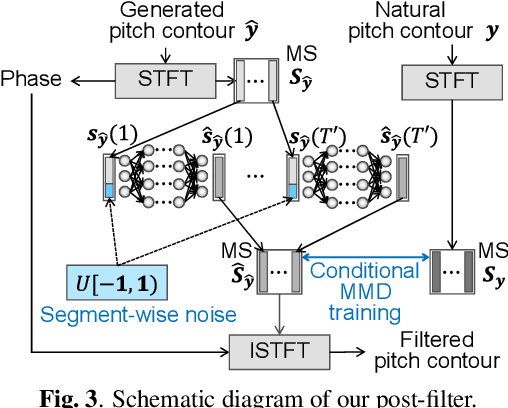
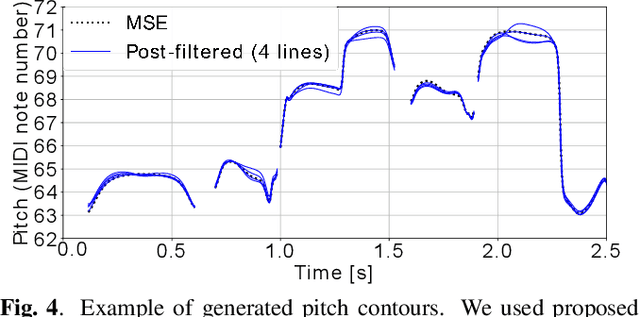
This paper proposes a generative moment matching network (GMMN)-based post-filter that provides inter-utterance pitch variation for deep neural network (DNN)-based singing voice synthesis. The natural pitch variation of a human singing voice leads to a richer musical experience and is used in double-tracking, a recording method in which two performances of the same phrase are recorded and mixed to create a richer, layered sound. However, singing voices synthesized using conventional DNN-based methods never vary because the synthesis process is deterministic and only one waveform is synthesized from one musical score. To address this problem, we use a GMMN to model the variation of the modulation spectrum of the pitch contour of natural singing voices and add a randomized inter-utterance variation to the pitch contour generated by conventional DNN-based singing voice synthesis. Experimental evaluations suggest that 1) our approach can provide perceptible inter-utterance pitch variation while preserving speech quality. We extend our approach to double-tracking, and the evaluation demonstrates that 2) GMMN-based neural double-tracking is perceptually closer to natural double-tracking than conventional signal processing-based artificial double-tracking is.
Sampling-based speech parameter generation using moment-matching networks
Apr 12, 2017
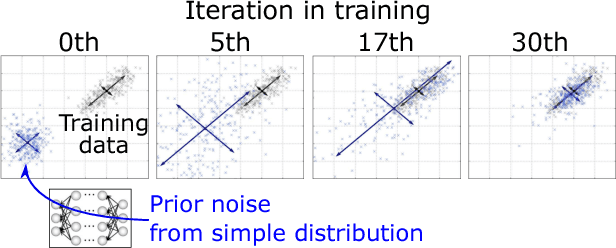
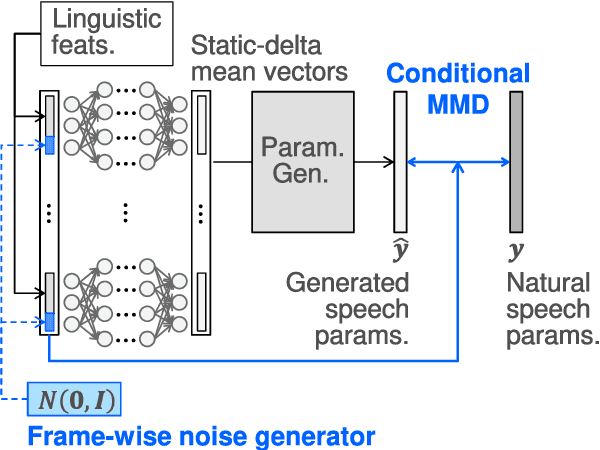
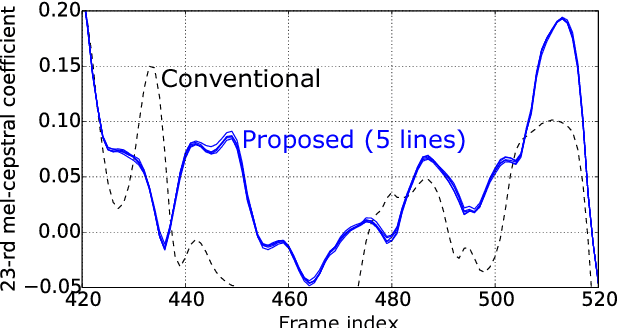
This paper presents sampling-based speech parameter generation using moment-matching networks for Deep Neural Network (DNN)-based speech synthesis. Although people never produce exactly the same speech even if we try to express the same linguistic and para-linguistic information, typical statistical speech synthesis produces completely the same speech, i.e., there is no inter-utterance variation in synthetic speech. To give synthetic speech natural inter-utterance variation, this paper builds DNN acoustic models that make it possible to randomly sample speech parameters. The DNNs are trained so that they make the moments of generated speech parameters close to those of natural speech parameters. Since the variation of speech parameters is compressed into a low-dimensional simple prior noise vector, our algorithm has lower computation cost than direct sampling of speech parameters. As the first step towards generating synthetic speech that has natural inter-utterance variation, this paper investigates whether or not the proposed sampling-based generation deteriorates synthetic speech quality. In evaluation, we compare speech quality of conventional maximum likelihood-based generation and proposed sampling-based generation. The result demonstrates the proposed generation causes no degradation in speech quality.