 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ALR-GAN: Adaptive Layout Refinement for Text-to-Image Synthesis
Apr 13, 2023
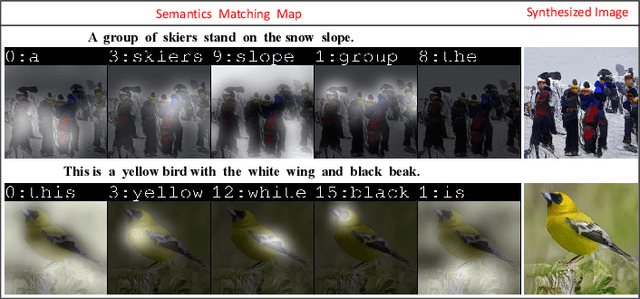
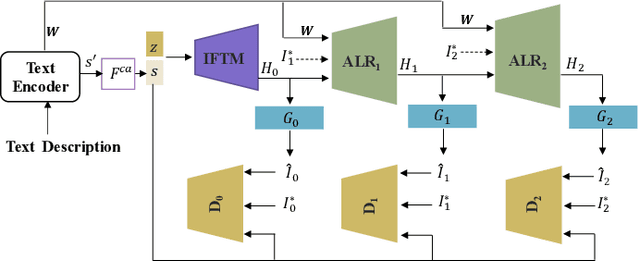
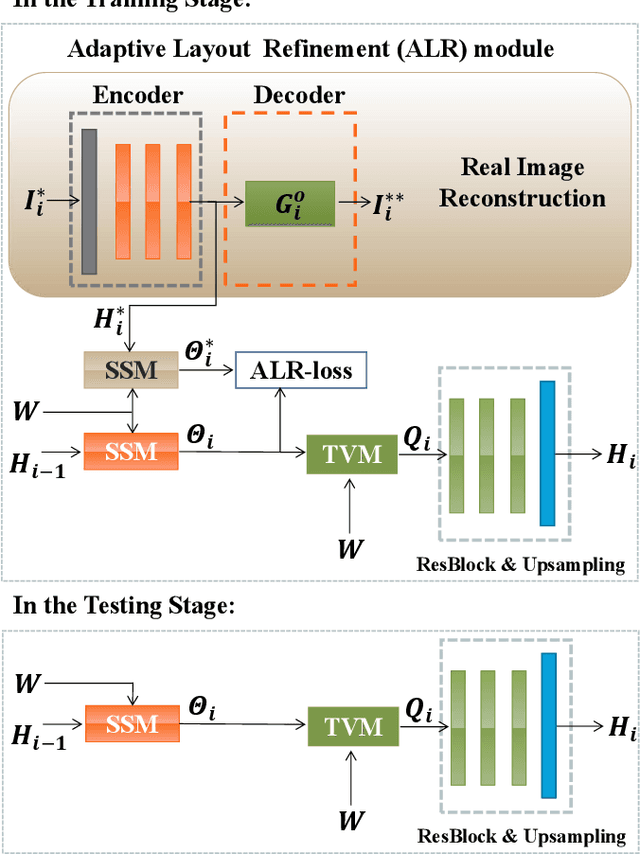

We propose a novel Text-to-Image Generation Network, Adaptive Layout Refinement Generative Adversarial Network (ALR-GAN), to adaptively refine the layout of synthesized images without any auxiliary information. The ALR-GAN includes an Adaptive Layout Refinement (ALR) module and a Layout Visual Refinement (LVR) loss. The ALR module aligns the layout structure (which refers to locations of objects and background) of a synthesized image with that of its corresponding real image. In ALR module, we proposed an Adaptive Layout Refinement (ALR) loss to balance the matching of hard and easy features, for more efficient layout structure matching. Based on the refined layout structure, the LVR loss further refines the visual representation within the layout area. Experimental results on two widely-used datasets show that ALR-GAN performs competitively at the Text-to-Image generation task.
Weakly-Supervised Temporal Action Localization with Bidirectional Semantic Consistency Constraint
Apr 25, 2023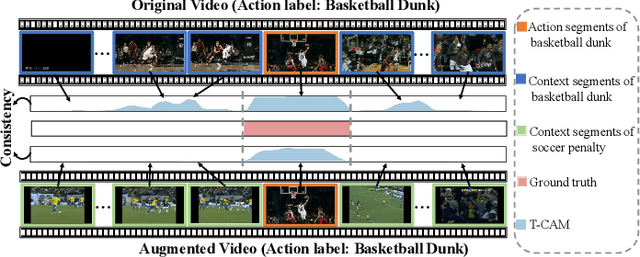
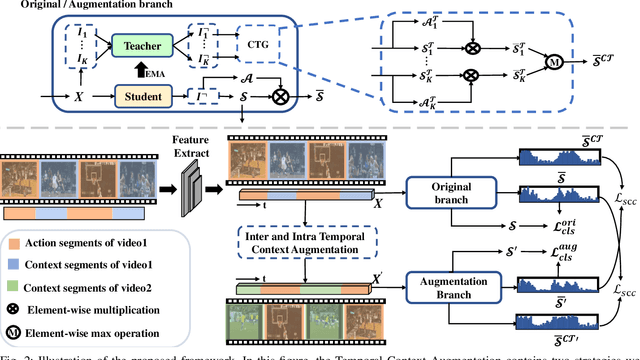
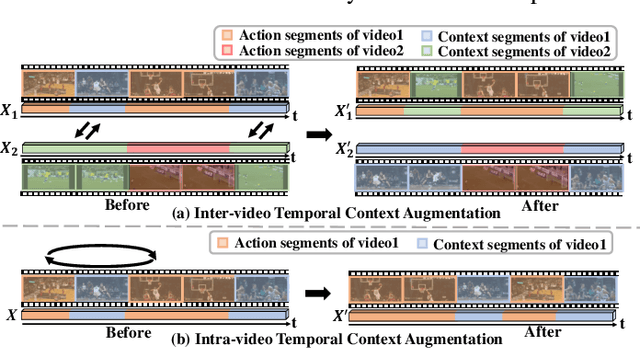
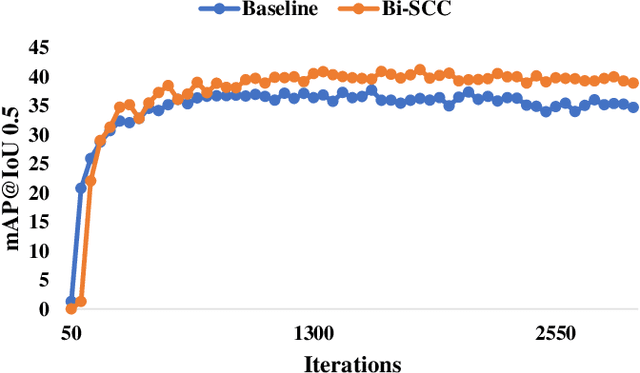
Weakly Supervised Temporal Action Localization (WTAL) aims to classify and localize temporal boundaries of actions for the video, given only video-level category labels in the training datasets. Due to the lack of boundary information during training, existing approaches formulate WTAL as a classificationproblem, i.e., generating the temporal class activation map (T-CAM) for localization. However, with only classification loss, the model would be sub-optimized, i.e., the action-related scenes are enough to distinguish different class labels. Regarding other actions in the action-related scene ( i.e., the scene same as positive actions) as co-scene actions, this sub-optimized model would misclassify the co-scene actions as positive actions. To address this misclassification, we propose a simple yet efficient method, named bidirectional semantic consistency constraint (Bi-SCC), to discriminate the positive actions from co-scene actions. The proposed Bi-SCC firstly adopts a temporal context augmentation to generate an augmented video that breaks the correlation between positive actions and their co-scene actions in the inter-video; Then, a semantic consistency constraint (SCC) is used to enforce the predictions of the original video and augmented video to be consistent, hence suppressing the co-scene actions. However, we find that this augmented video would destroy the original temporal context. Simply applying the consistency constraint would affect the completeness of localized positive actions. Hence, we boost the SCC in a bidirectional way to suppress co-scene actions while ensuring the integrity of positive actions, by cross-supervising the original and augmented videos. Finally, our proposed Bi-SCC can be applied to current WTAL approaches, and improve their performance. Experimental results show that our approach outperforms the state-of-the-art methods on THUMOS14 and ActivityNet.
Towards preserving word order importance through Forced Invalidation
Apr 11, 2023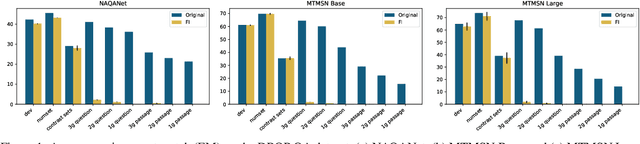
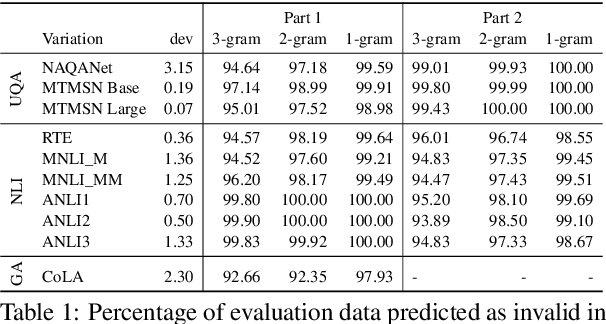
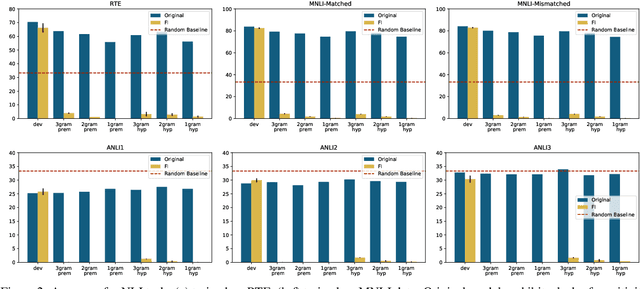
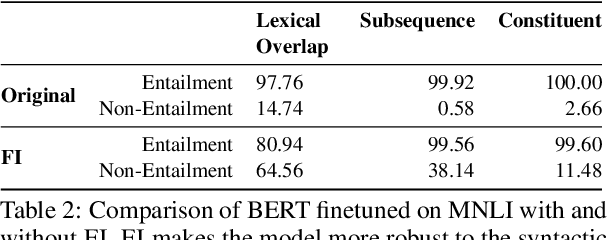
Large pre-trained language models such as BERT have been widely used as a framework for natural language understanding (NLU) tasks. However, recent findings have revealed that pre-trained language models are insensitive to word order. The performance on NLU tasks remains unchanged even after randomly permuting the word of a sentence, where crucial syntactic information is destroyed. To help preserve the importance of word order, we propose a simple approach called Forced Invalidation (FI): forcing the model to identify permuted sequences as invalid samples. We perform an extensive evaluation of our approach on various English NLU and QA based tasks over BERT-based and attention-based models over word embeddings. Our experiments demonstrate that Forced Invalidation significantly improves the sensitivity of the models to word order.
BanditQ -- No-Regret Learning with Guaranteed Per-User Rewards in Adversarial Environments
Apr 11, 2023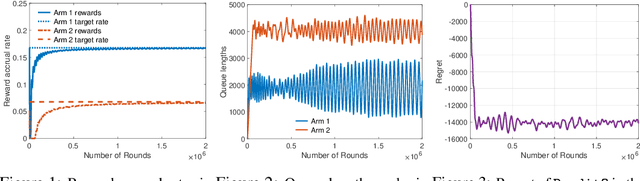
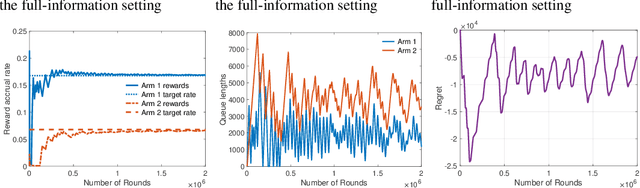
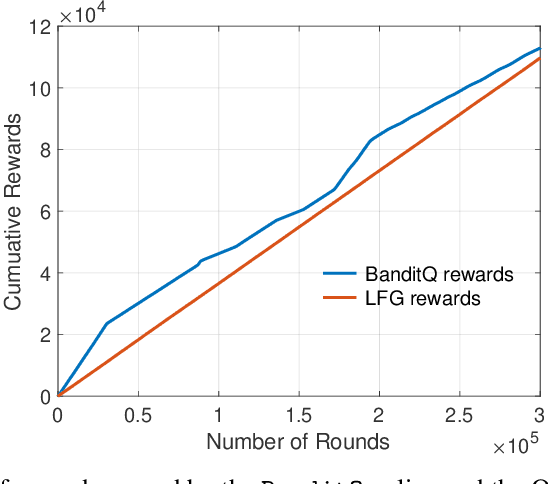
Classic online prediction algorithms, such as Hedge, are inherently unfair by design, as they try to play the most rewarding arm as many times as possible while ignoring the sub-optimal arms to achieve sublinear regret. In this paper, we consider a fair online prediction problem in the adversarial setting with hard lower bounds on the rate of accrual of rewards for all arms. By combining elementary queueing theory with online learning, we propose a new online prediction policy, called BanditQ, that achieves the target rate constraints while achieving a regret of $O(T^{3/4})$ in the full-information setting. The design and analysis of BanditQ involve a novel use of the potential function method and are of independent interest.
Relational Context Learning for Human-Object Interaction Detection
Apr 11, 2023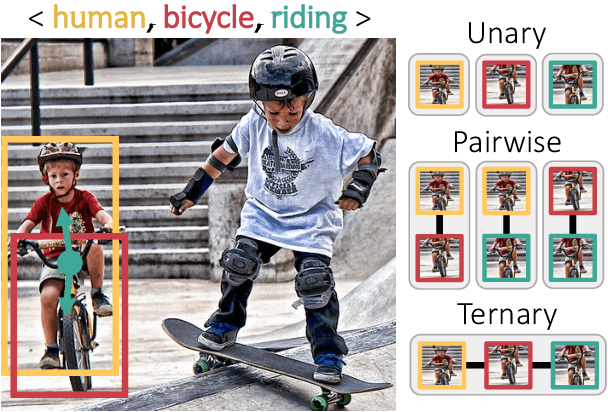
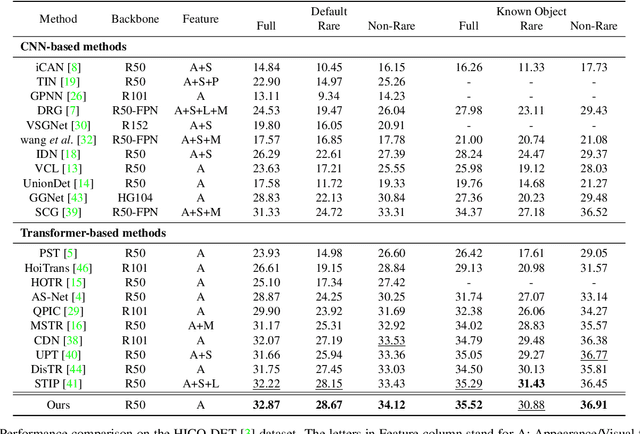
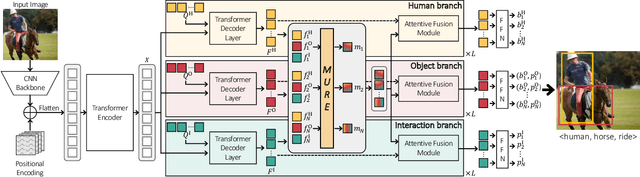
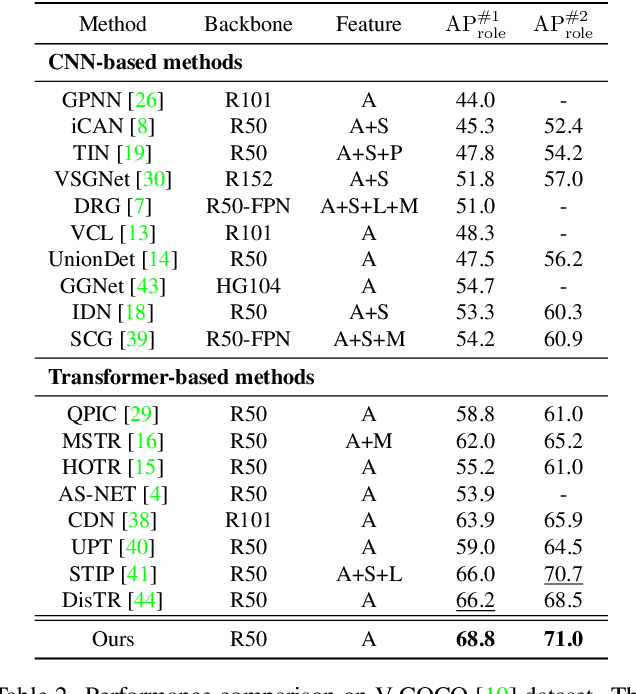
Recent state-of-the-art methods for HOI detection typically build on transformer architectures with two decoder branches, one for human-object pair detection and the other for interaction classification. Such disentangled transformers, however, may suffer from insufficient context exchange between the branches and lead to a lack of context information for relational reasoning, which is critical in discovering HOI instances. In this work, we propose the multiplex relation network (MUREN) that performs rich context exchange between three decoder branches using unary, pairwise, and ternary relations of human, object, and interaction tokens. The proposed method learns comprehensive relational contexts for discovering HOI instances, achieving state-of-the-art performance on two standard benchmarks for HOI detection, HICO-DET and V-COCO.
Hierarchical B-frame Video Coding Using Two-Layer CANF without Motion Coding
Apr 05, 2023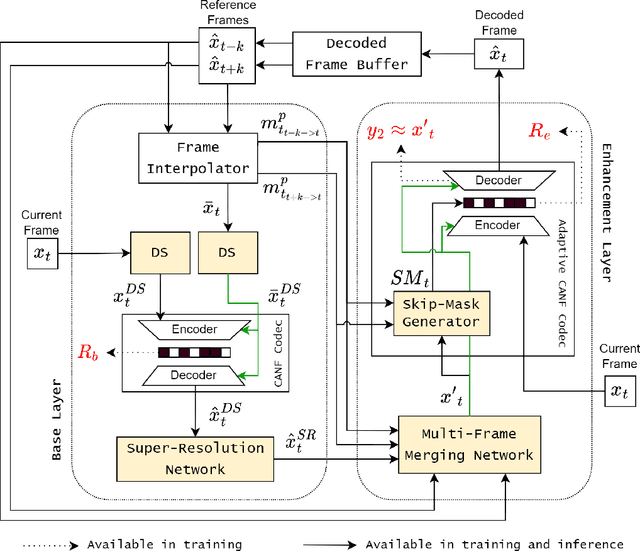
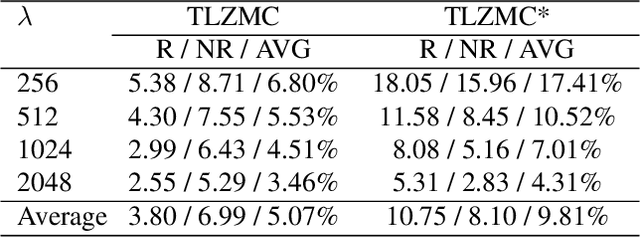
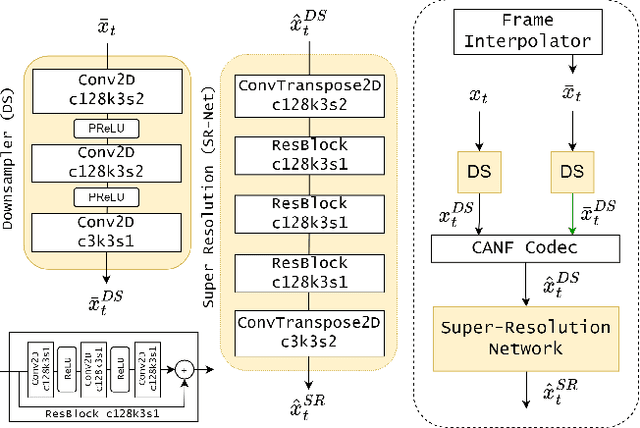
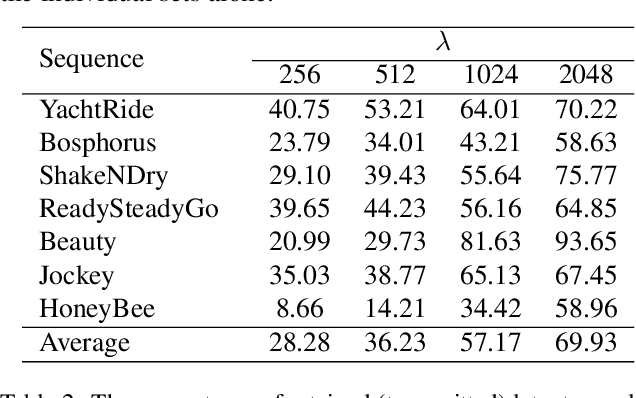
Typical video compression systems consist of two main modules: motion coding and residual coding. This general architecture is adopted by classical coding schemes (such as international standards H.265 and H.266) and deep learning-based coding schemes. We propose a novel B-frame coding architecture based on two-layer Conditional Augmented Normalization Flows (CANF). It has the striking feature of not transmitting any motion information. Our proposed idea of video compression without motion coding offers a new direction for learned video coding. Our base layer is a low-resolution image compressor that replaces the full-resolution motion compressor. The low-resolution coded image is merged with the warped high-resolution images to generate a high-quality image as a conditioning signal for the enhancement-layer image coding in full resolution. One advantage of this architecture is significantly reduced computational complexity due to eliminating the motion information compressor. In addition, we adopt a skip-mode coding technique to reduce the transmitted latent samples. The rate-distortion performance of our scheme is slightly lower than that of the state-of-the-art learned B-frame coding scheme, B-CANF, but outperforms other learned B-frame coding schemes. However, compared to B-CANF, our scheme saves 45% of multiply-accumulate operations (MACs) for encoding and 27% of MACs for decoding. The code is available at https://nycu-clab.github.io.
Investigating and Mitigating the Side Effects of Noisy Views in Multi-view Clustering in Practical Scenarios
Mar 30, 2023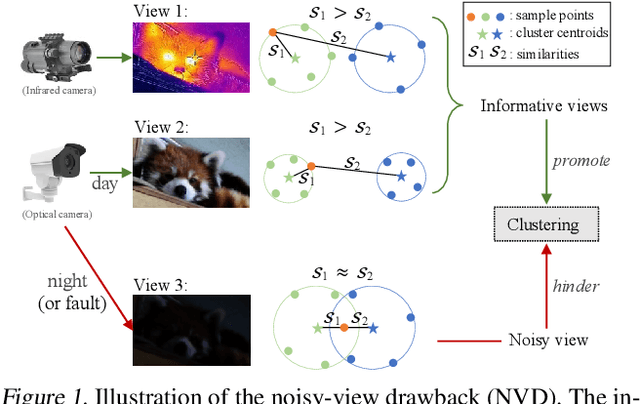
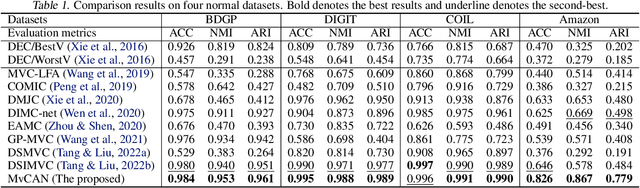
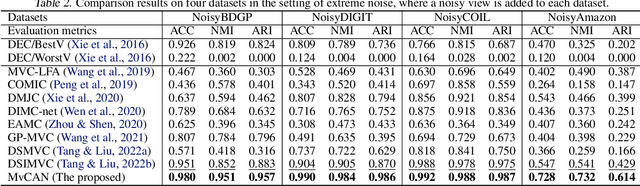
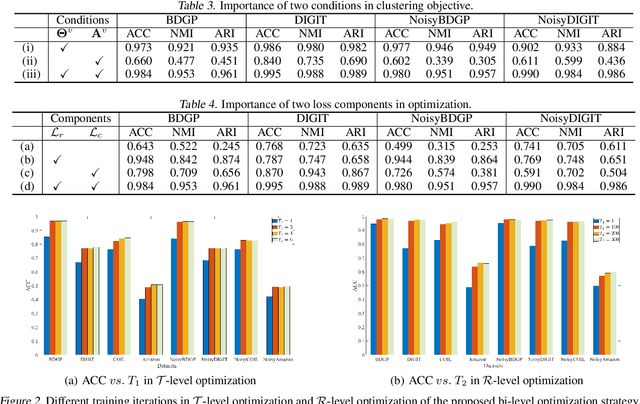
Multi-view clustering (MvC) aims at exploring the category structure among multi-view data without label supervision. Multiple views provide more information than single views and thus existing MvC methods can achieve satisfactory performance. However, their performance might seriously degenerate when the views are noisy in practical scenarios. In this paper, we first formally investigate the drawback of noisy views and then propose a theoretically grounded deep MvC method (namely MvCAN) to address this issue. Specifically, we propose a novel MvC objective that enables un-shared parameters and inconsistent clustering predictions across multiple views to reduce the side effects of noisy views. Furthermore, a non-parametric iterative process is designed to generate a robust learning target for mining multiple views' useful information. Theoretical analysis reveals that MvCAN works by achieving the multi-view consistency, complementarity, and noise robustness. Finally, experiments on public datasets demonstrate that MvCAN outperforms state-of-the-art methods and is robust against the existence of noisy views.
Medical Intervention Duration Estimation Using Language-enhanced Transformer Encoder with Medical Prompts
Mar 30, 2023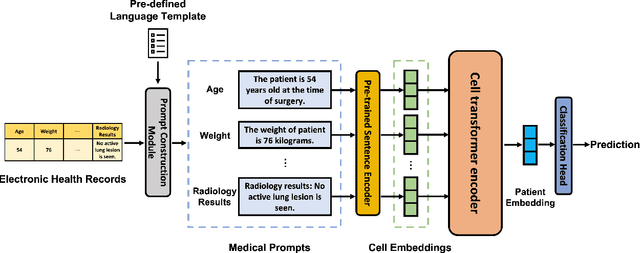

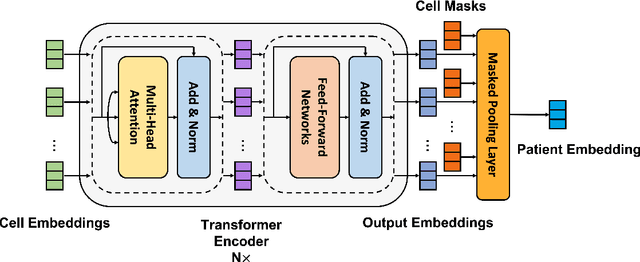

In recent years, estimating the duration of medical intervention based on electronic health records (EHRs) has gained significant attention in the filed of clinical decision support. However, current models largely focus on structured data, leaving out information from the unstructured clinical free-text data. To address this, we present a novel language-enhanced transformer-based framework, which projects all relevant clinical data modalities (continuous, categorical, binary, and free-text features) into a harmonized language latent space using a pre-trained sentence encoder with the help of medical prompts. The proposed method enables the integration of information from different modalities within the cell transformer encoder and leads to more accurate duration estimation for medical intervention. Our experimental results on both US-based (length of stay in ICU estimation) and Asian (surgical duration prediction) medical datasets demonstrate the effectiveness of our proposed framework, which outperforms tailored baseline approaches and exhibits robustness to data corruption in EHRs.
Detecting Everything in the Open World: Towards Universal Object Detection
Mar 27, 2023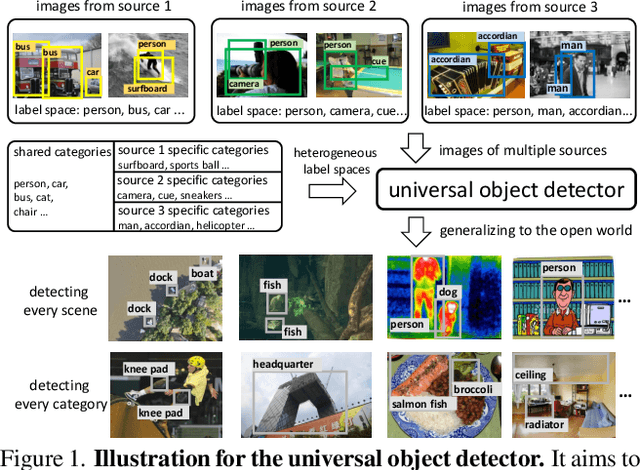
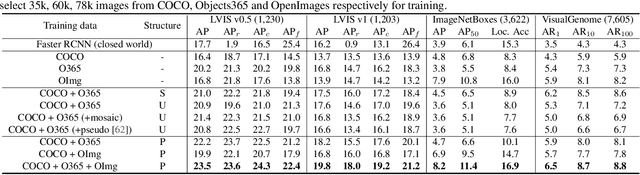
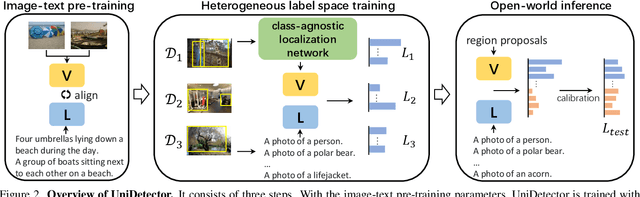
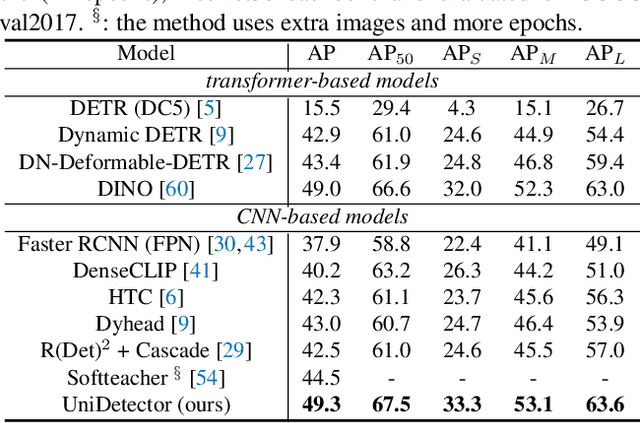
In this paper, we formally address universal object detection, which aims to detect every scene and predict every category. The dependence on human annotations, the limited visual information, and the novel categories in the open world severely restrict the universality of traditional detectors. We propose UniDetector, a universal object detector that has the ability to recognize enormous categories in the open world. The critical points for the universality of UniDetector are: 1) it leverages images of multiple sources and heterogeneous label spaces for training through the alignment of image and text spaces, which guarantees sufficient information for universal representations. 2) it generalizes to the open world easily while keeping the balance between seen and unseen classes, thanks to abundant information from both vision and language modalities. 3) it further promotes the generalization ability to novel categories through our proposed decoupling training manner and probability calibration. These contributions allow UniDetector to detect over 7k categories, the largest measurable category size so far, with only about 500 classes participating in training. Our UniDetector behaves the strong zero-shot generalization ability on large-vocabulary datasets like LVIS, ImageNetBoxes, and VisualGenome - it surpasses the traditional supervised baselines by more than 4\% on average without seeing any corresponding images. On 13 public detection datasets with various scenes, UniDetector also achieves state-of-the-art performance with only a 3\% amount of training data.
DeID-GPT: Zero-shot Medical Text De-Identification by GPT-4
Mar 20, 2023

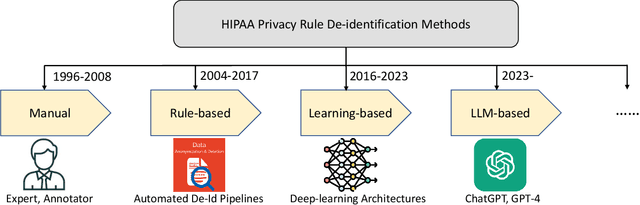
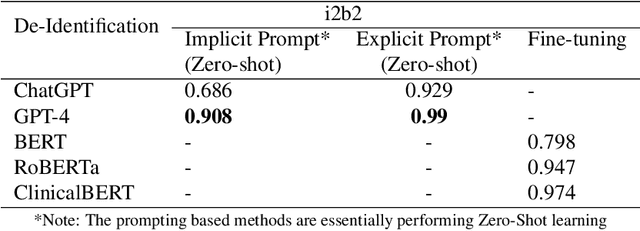
The digitization of healthcare has facilitated the sharing and re-using of medical data but has also raised concerns about confidentiality and privacy. HIPAA (Health Insurance Portability and Accountability Act) mandates removing re-identifying information before the dissemination of medical records. Thus, effective and efficient solutions for de-identifying medical data, especially those in free-text forms, are highly needed. While various computer-assisted de-identification methods, including both rule-based and learning-based, have been developed and used in prior practice, such solutions still lack generalizability or need to be fine-tuned according to different scenarios, significantly imposing restrictions in wider use. The advancement of large language models (LLM), such as ChatGPT and GPT-4, have shown great potential in processing text data in the medical domain with zero-shot in-context learning, especially in the task of privacy protection, as these models can identify confidential information by their powerful named entity recognition (NER) capability. In this work, we developed a novel GPT4-enabled de-identification framework ("DeID-GPT") to automatically identify and remove the identifying information. Compared to existing commonly used medical text data de-identification methods, our developed DeID-GPT showed the highest accuracy and remarkable reliability in masking private information from the unstructured medical text while preserving the original structure and meaning of the text. This study is one of the earliest to utilize ChatGPT and GPT-4 for medical text data processing and de-identification, which provides insights for further research and solution development on the use of LLMs such as ChatGPT/GPT-4 in healthcare. Codes and benchmarking data information are available at https://github.com/yhydhx/ChatGPT-API.