 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Segment Anything Meets Point Tracking
Jul 03, 2023
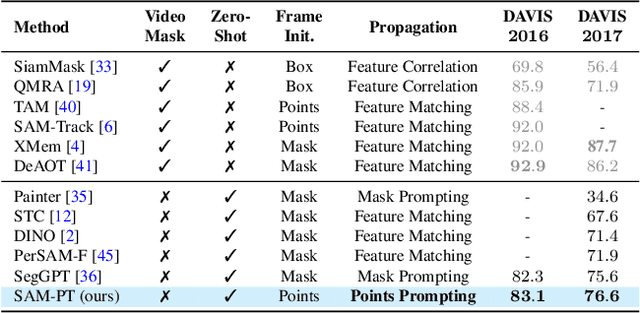
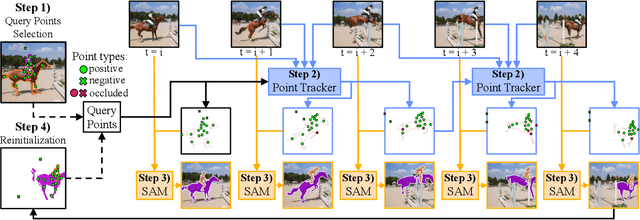
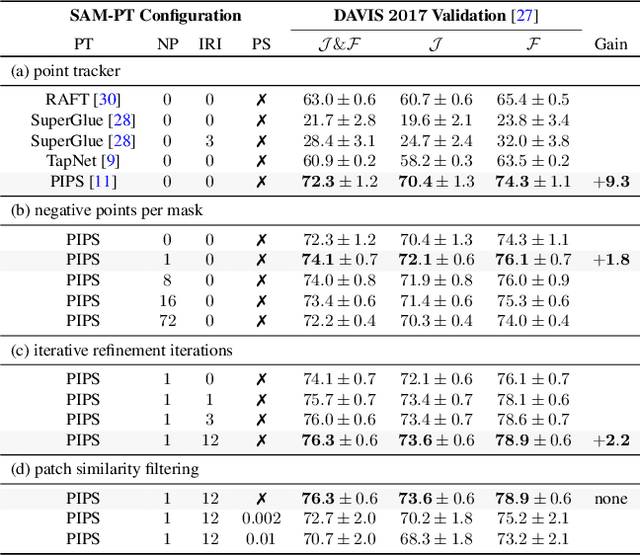
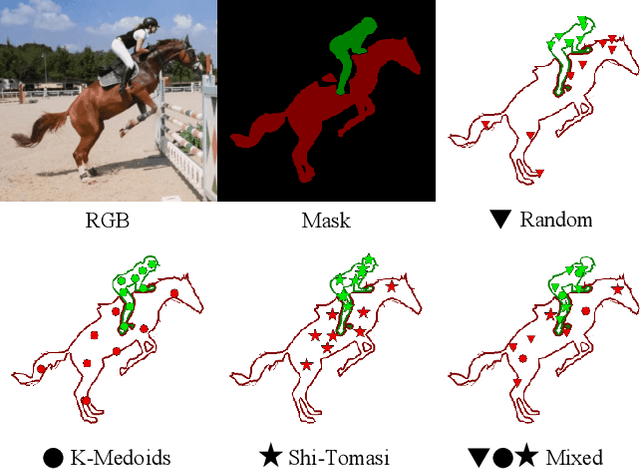
The Segment Anything Model (SAM) has established itself as a powerful zero-shot image segmentation model, employing interactive prompts such as points to generate masks. This paper presents SAM-PT, a method extending SAM's capability to tracking and segmenting anything in dynamic videos. SAM-PT leverages robust and sparse point selection and propagation techniques for mask generation, demonstrating that a SAM-based segmentation tracker can yield strong zero-shot performance across popular video object segmentation benchmarks, including DAVIS, YouTube-VOS, and MOSE. Compared to traditional object-centric mask propagation strategies, we uniquely use point propagation to exploit local structure information that is agnostic to object semantics. We highlight the merits of point-based tracking through direct evaluation on the zero-shot open-world Unidentified Video Objects (UVO) benchmark. To further enhance our approach, we utilize K-Medoids clustering for point initialization and track both positive and negative points to clearly distinguish the target object. We also employ multiple mask decoding passes for mask refinement and devise a point re-initialization strategy to improve tracking accuracy. Our code integrates different point trackers and video segmentation benchmarks and will be released at https://github.com/SysCV/sam-pt.
RefSAM: Efficiently Adapting Segmenting Anything Model for Referring Video Object Segmentation
Jul 03, 2023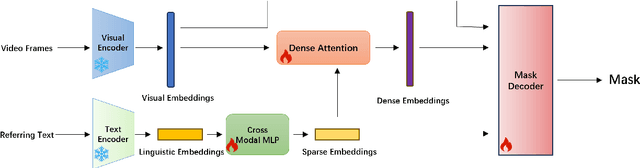

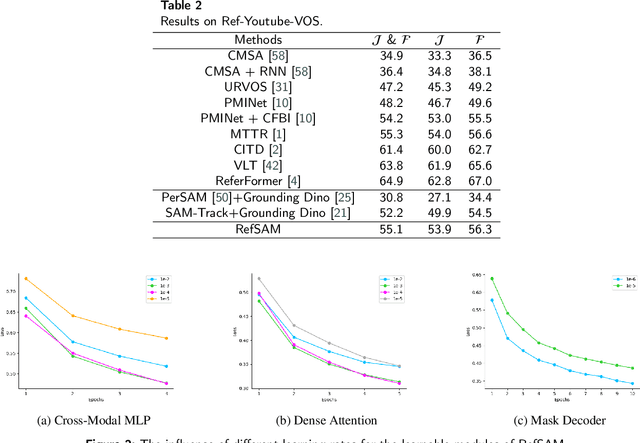

The Segment Anything Model (SAM) has gained significant attention for its impressive performance in image segmentation. However, it lacks proficiency in referring video object segmentation (RVOS) due to the need for precise user-interactive prompts and limited understanding of different modalities, such as language and vision. This paper presents the RefSAM model, which for the first time explores the potential of SAM for RVOS by incorporating multi-view information from diverse modalities and successive frames at different timestamps. Our proposed approach adapts the original SAM model to enhance cross-modality learning by employing a lightweight Cross-Modal MLP that projects the text embedding of the referring expression into sparse and dense embeddings, serving as user-interactive prompts. Subsequently, a parameter-efficient tuning strategy is employed to effectively align and fuse the language and vision features. Through comprehensive ablation studies, we demonstrate the practical and effective design choices of our strategy. Extensive experiments conducted on Ref-Youtu-VOS and Ref-DAVIS17 datasets validate the superiority and effectiveness of our RefSAM model over existing methods. The code and models will be made publicly at \href{https://github.com/LancasterLi/RefSAM}{github.com/LancasterLi/RefSAM}.
MindDial: Belief Dynamics Tracking with Theory-of-Mind Modeling for Situated Neural Dialogue Generation
Jul 03, 2023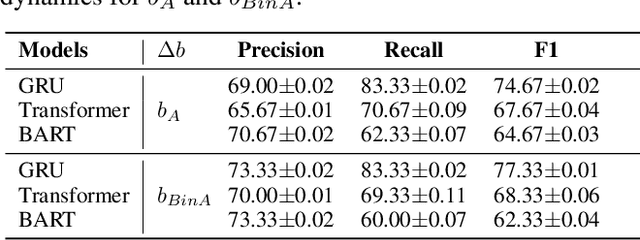
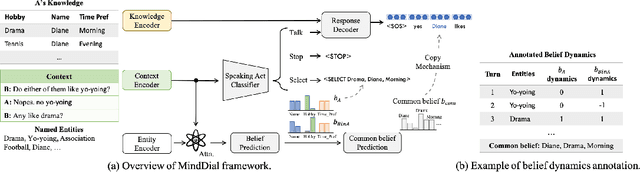
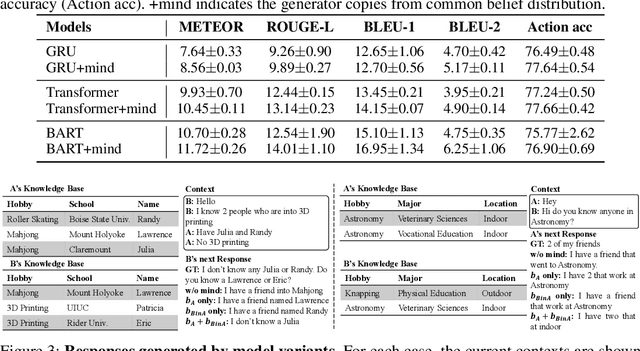
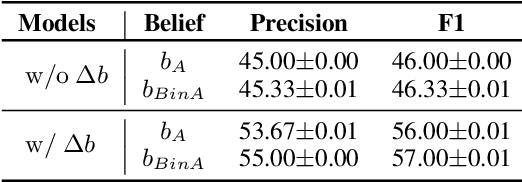
Humans talk in free-form while negotiating the expressed meanings or common ground. Despite the impressive conversational abilities of the large generative language models, they do not consider the individual differences in contextual understanding in a shared situated environment. In this work, we propose MindDial, a novel conversational framework that can generate situated free-form responses to negotiate common ground. We design an explicit mind module that can track three-level beliefs -- the speaker's belief, the speaker's prediction of the listener's belief, and the common belief based on the gap between the first two. Then the speaking act classification head will decide to continue to talk, end this turn, or take task-related action. We augment a common ground alignment dataset MutualFriend with belief dynamics annotation, of which the goal is to find a single mutual friend based on the free chat between two agents. Experiments show that our model with mental state modeling can resemble human responses when aligning common ground meanwhile mimic the natural human conversation flow. The ablation study further validates the third-level common belief can aggregate information of the first and second-order beliefs and align common ground more efficiently.
ContriMix: Unsupervised disentanglement of content and attribute for domain generalization in microscopy image analysis
Jul 03, 2023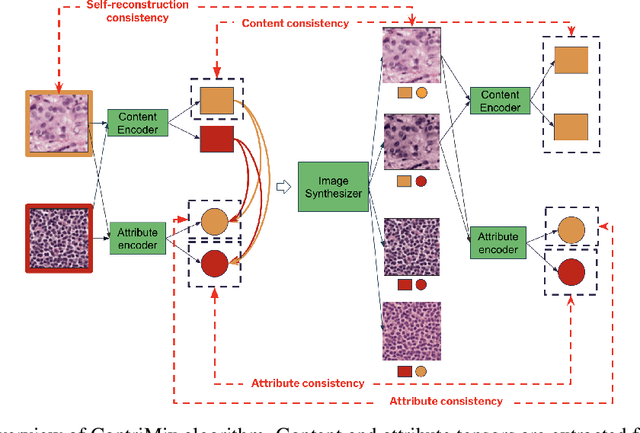

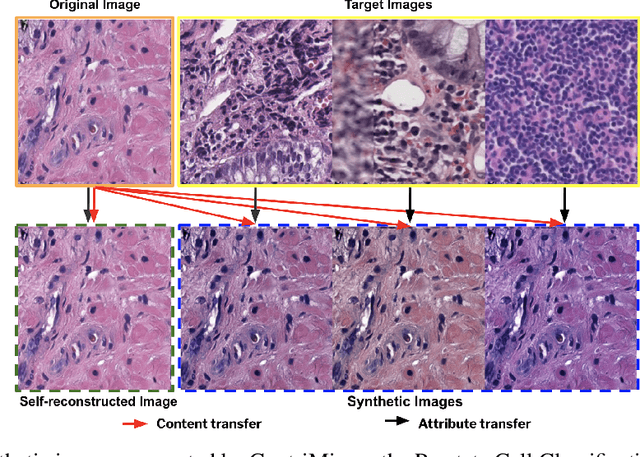
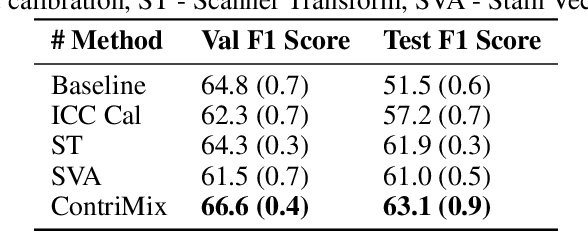
Domain generalization is critical for real-world applications of machine learning models to microscopy images, including histopathology and fluorescence imaging. Artifacts in histopathology arise through a complex combination of factors relating to tissue collection and laboratory processing, as well as factors intrinsic to patient samples. In fluorescence imaging, these artifacts stem from variations across experimental batches. The complexity and subtlety of these artifacts make the enumeration of data domains intractable. Therefore, augmentation-based methods of domain generalization that require domain identifiers and manual fine-tuning are inadequate in this setting. To overcome this challenge, we introduce ContriMix, a domain generalization technique that learns to generate synthetic images by disentangling and permuting the biological content ("content") and technical variations ("attributes") in microscopy images. ContriMix does not rely on domain identifiers or handcrafted augmentations and makes no assumptions about the input characteristics of images. We assess the performance of ContriMix on two pathology datasets (Camelyon17-WILDS and a prostate cell classification dataset) and one fluorescence microscopy dataset (RxRx1-WILDS). ContriMix outperforms current state-of-the-art methods in all datasets, motivating its usage for microscopy image analysis in real-world settings where domain information is hard to come by.
Real-time Monocular Full-body Capture in World Space via Sequential Proxy-to-Motion Learning
Jul 03, 2023
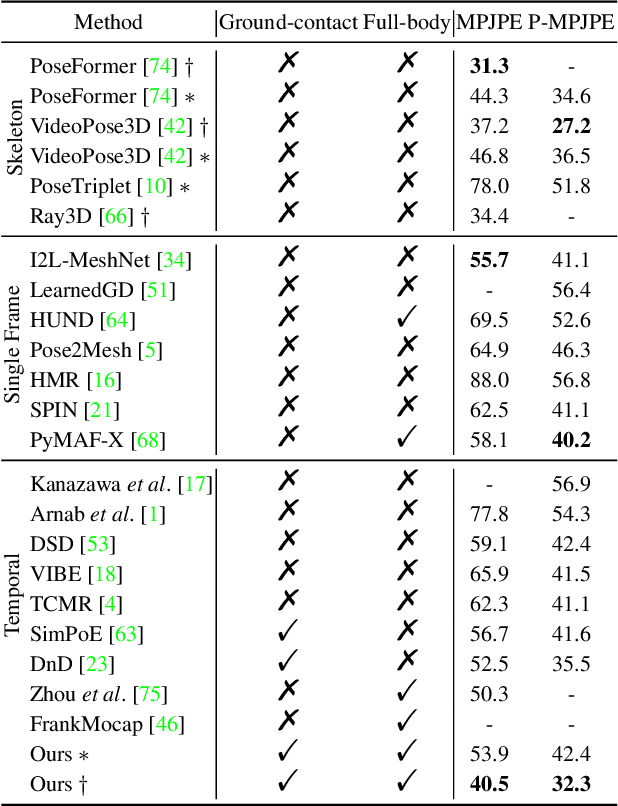
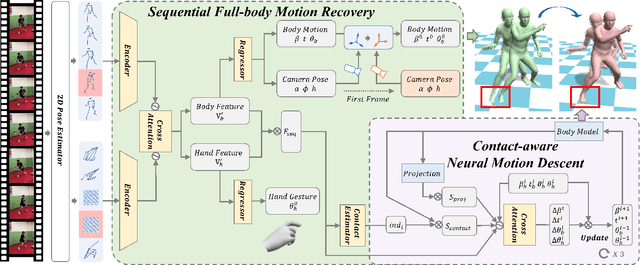
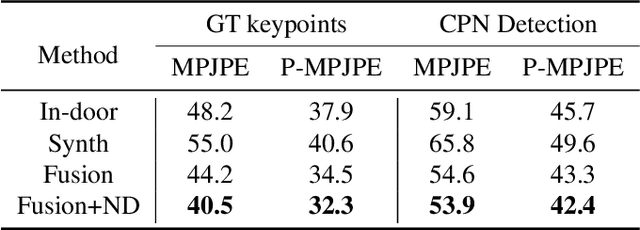
Learning-based approaches to monocular motion capture have recently shown promising results by learning to regress in a data-driven manner. However, due to the challenges in data collection and network designs, it remains challenging for existing solutions to achieve real-time full-body capture while being accurate in world space. In this work, we contribute a sequential proxy-to-motion learning scheme together with a proxy dataset of 2D skeleton sequences and 3D rotational motions in world space. Such proxy data enables us to build a learning-based network with accurate full-body supervision while also mitigating the generalization issues. For more accurate and physically plausible predictions, a contact-aware neural motion descent module is proposed in our network so that it can be aware of foot-ground contact and motion misalignment with the proxy observations. Additionally, we share the body-hand context information in our network for more compatible wrist poses recovery with the full-body model. With the proposed learning-based solution, we demonstrate the first real-time monocular full-body capture system with plausible foot-ground contact in world space. More video results can be found at our project page: https://liuyebin.com/proxycap.
Learning Noise-Resistant Image Representation by Aligning Clean and Noisy Domains
Jul 03, 2023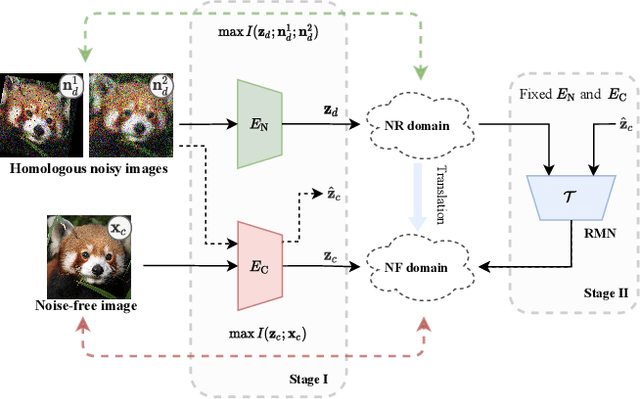
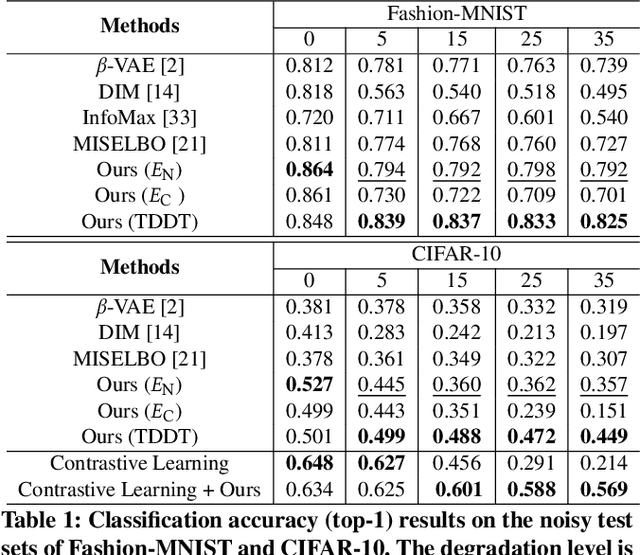
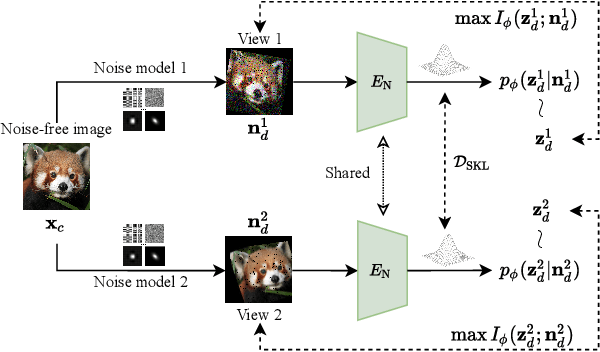

Recent supervised and unsupervised image representation learning algorithms have achieved quantum leaps. However, these techniques do not account for representation resilience against noise in their design paradigms. Consequently, these effective methods suffer failure when confronted with noise outside the training distribution, such as complicated real-world noise that is usually opaque to model training. To address this issue, dual domains are optimized to separately model a canonical space for noisy representations, namely the Noise-Robust (NR) domain, and a twinned canonical clean space, namely the Noise-Free (NF) domain, by maximizing the interaction information between the representations. Given the dual canonical domains, we design a target-guided implicit neural mapping function to accurately translate the NR representations to the NF domain, yielding noise-resistant representations by eliminating noise regencies. The proposed method is a scalable module that can be readily integrated into existing learning systems to improve their robustness against noise. Comprehensive trials of various tasks using both synthetic and real-world noisy data demonstrate that the proposed Target-Guided Dual-Domain Translation (TDDT) method is able to achieve remarkable performance and robustness in the face of complex noisy images.
Patch-CNN: Training data-efficient deep learning for high-fidelity diffusion tensor estimation from minimal diffusion protocols
Jul 03, 2023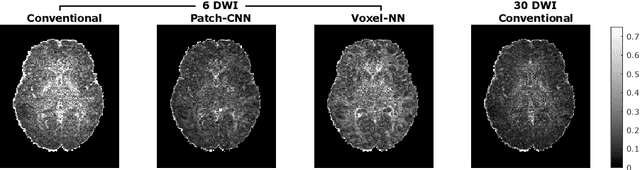
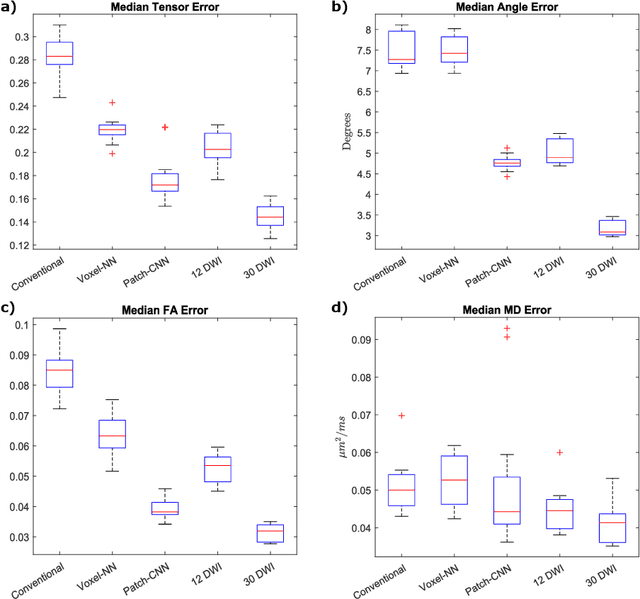
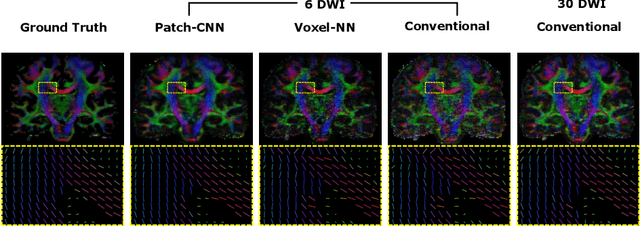
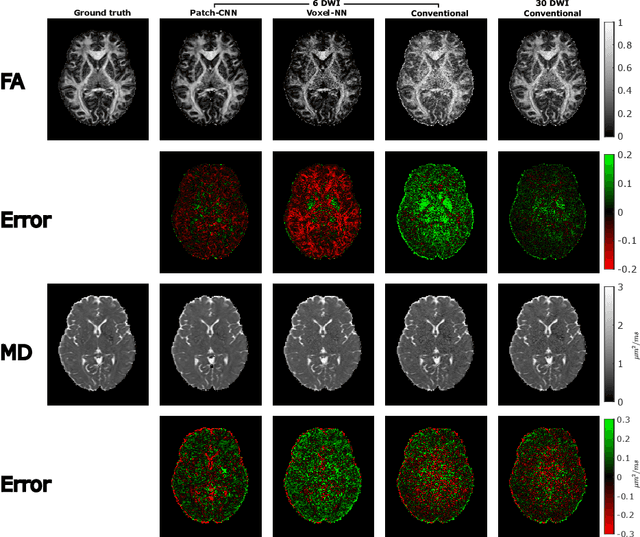
We propose a new method, Patch-CNN, for diffusion tensor (DT) estimation from only six-direction diffusion weighted images (DWI). Deep learning-based methods have been recently proposed for dMRI parameter estimation, using either voxel-wise fully-connected neural networks (FCN) or image-wise convolutional neural networks (CNN). In the acute clinical context -- where pressure of time limits the number of imaged directions to a minimum -- existing approaches either require an infeasible number of training images volumes (image-wise CNNs), or do not estimate the fibre orientations (voxel-wise FCNs) required for tractogram estimation. To overcome these limitations, we propose Patch-CNN, a neural network with a minimal (non-voxel-wise) convolutional kernel (3$\times$3$\times$3). Compared with voxel-wise FCNs, this has the advantage of allowing the network to leverage local anatomical information. Compared with image-wise CNNs, the minimal kernel vastly reduces training data demand. Evaluated against both conventional model fitting and a voxel-wise FCN, Patch-CNN, trained with a single subject is shown to improve the estimation of both scalar dMRI parameters and fibre orientation from six-direction DWIs. The improved fibre orientation estimation is shown to produce improved tractogram.
OTFS-based Robust MMSE Precoding Design in Over-the-air Computation
Jul 04, 2023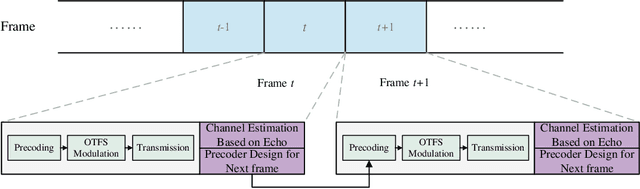
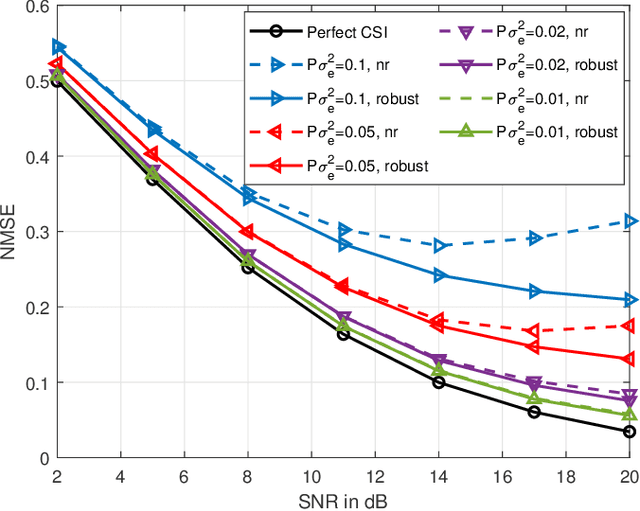
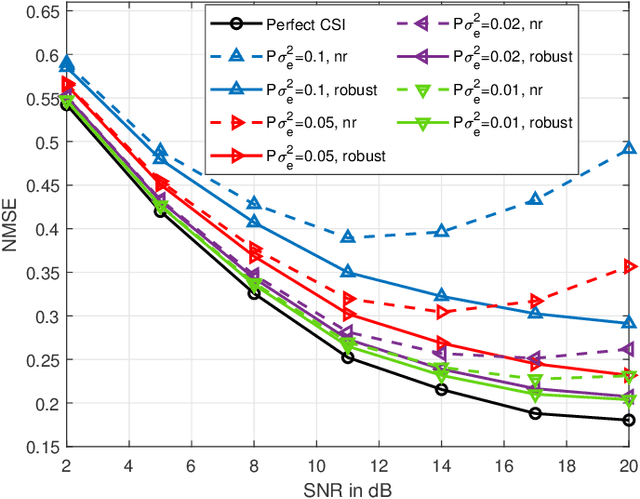
Over-the-air computation (AirComp), as a data aggregation method that can improve network efficiency by exploiting the superposition characteristics of wireless channels, has received much attention recently. Meanwhile, the orthogonal time frequency space (OTFS) modulation can provide a strong Doppler resilience and facilitates reliable transmission for high-mobility communications. Hence, in this work, we investigate an OTFS-based AirComp system in the presence of time-frequency dual-selective channels. In particular, we commence from the development of a novel transmission framework for the considered system, where the pilot signal is sent together with data and the channel estimation is implemented according to the echo from the access point to the sensor, thereby reducing the overhead of channel state information (CSI) feedback. Hereafter, based on the CSI estimated from the previous frame, a robust precoding matrix aiming at minimizing mean square error in the current frame is designed, which takes into account the estimation error from the receiver noise and the outdated CSI. The simulation results demonstrate the effectiveness of the proposed robust precoding scheme by comparing it with the non-robust precoding. The performance gain is more obvious in high signal-to-noise ratio in case of large channel estimation errors.
Embodied Task Planning with Large Language Models
Jul 04, 2023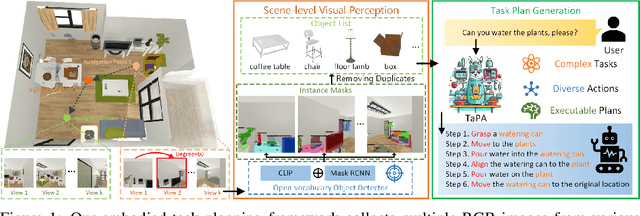

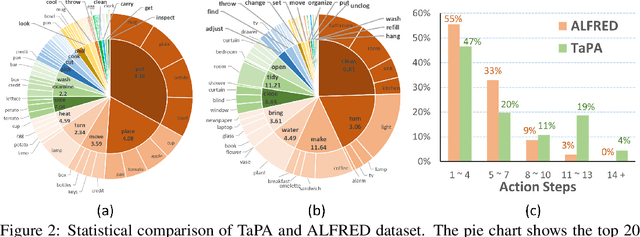
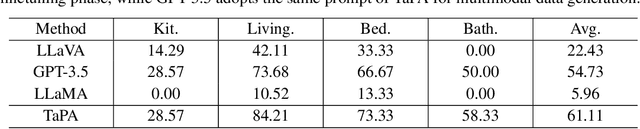
Equipping embodied agents with commonsense is important for robots to successfully complete complex human instructions in general environments. Recent large language models (LLM) can embed rich semantic knowledge for agents in plan generation of complex tasks, while they lack the information about the realistic world and usually yield infeasible action sequences. In this paper, we propose a TAsk Planing Agent (TaPA) in embodied tasks for grounded planning with physical scene constraint, where the agent generates executable plans according to the existed objects in the scene by aligning LLMs with the visual perception models. Specifically, we first construct a multimodal dataset containing triplets of indoor scenes, instructions and action plans, where we provide the designed prompts and the list of existing objects in the scene for GPT-3.5 to generate a large number of instructions and corresponding planned actions. The generated data is leveraged for grounded plan tuning of pre-trained LLMs. During inference, we discover the objects in the scene by extending open-vocabulary object detectors to multi-view RGB images collected in different achievable locations. Experimental results show that the generated plan from our TaPA framework can achieve higher success rate than LLaVA and GPT-3.5 by a sizable margin, which indicates the practicality of embodied task planning in general and complex environments.
ChildPlay: A New Benchmark for Understanding Children's Gaze Behaviour
Jul 04, 2023
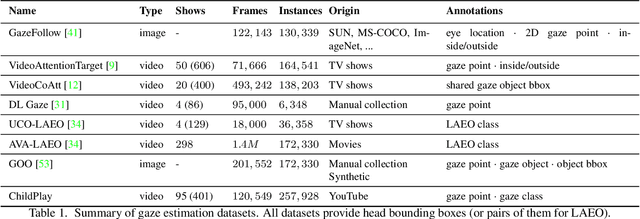


Gaze behaviors such as eye-contact or shared attention are important markers for diagnosing developmental disorders in children. While previous studies have looked at some of these elements, the analysis is usually performed on private datasets and is restricted to lab settings. Furthermore, all publicly available gaze target prediction benchmarks mostly contain instances of adults, which makes models trained on them less applicable to scenarios with young children. In this paper, we propose the first study for predicting the gaze target of children and interacting adults. To this end, we introduce the ChildPlay dataset: a curated collection of short video clips featuring children playing and interacting with adults in uncontrolled environments (e.g. kindergarten, therapy centers, preschools etc.), which we annotate with rich gaze information. We further propose a new model for gaze target prediction that is geometrically grounded by explicitly identifying the scene parts in the 3D field of view (3DFoV) of the person, leveraging recent geometry preserving depth inference methods. Our model achieves state of the art results on benchmark datasets and ChildPlay. Furthermore, results show that looking at faces prediction performance on children is much worse than on adults, and can be significantly improved by fine-tuning models using child gaze annotations. Our dataset and models will be made publicly available.