 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHy-Embodied-0.5-VLA: From Vision-Language-Action Models to a Real-World Robot Learning Stack
Jun 12, 2026In this report, we present Hy-Embodied-0.5-VLA, abbreviated as HyVLA-0.5, an end-to-end system that spans the full robot learning stack: data collection, model design, continued pre-training and supervised fine-tuning, RL post-training, and real-world deployment. Each component serves a distinct role in this stack.
The Strongest Teacher Is Not Always the Best Teacher: Student-Centric Answer Selection
May 26, 2026LLM training increasingly relies on teacher-generated supervision, from synthetic responses to reasoning traces and tool-use demonstrations. Current practice often chooses the highest-performing teacher to generate student training data, implicitly treating teacher test performance as a proxy for teaching quality. We show that this assumption can fail: even when multiple teachers provide correct answers to the same question, the answer from the strongest teacher is not necessarily the best supervision for a given student. To address this gap, we propose Student-Centric Answer Sampling (SCAS), a framework that selects from verified teacher-generated answers according to their estimated student-centric learning cost. Motivated by a token-wise gradient decomposition, we derive an efficient forward-only proxy for this cost and use it to guide answer selection during training. Experiments across 30 teacher models, 6 student base models, and 8 tasks show that SCAS consistently improves student performance, suggesting that effective distillation should prioritize supervision matched to the current student rather than teacher strength alone.
VinT-6D: A Large-Scale Object-in-hand Dataset from Vision, Touch and Proprioception
Jan 06, 2025



This paper addresses the scarcity of large-scale datasets for accurate object-in-hand pose estimation, which is crucial for robotic in-hand manipulation within the ``Perception-Planning-Control" paradigm. Specifically, we introduce VinT-6D, the first extensive multi-modal dataset integrating vision, touch, and proprioception, to enhance robotic manipulation. VinT-6D comprises 2 million VinT-Sim and 0.1 million VinT-Real splits, collected via simulations in MuJoCo and Blender and a custom-designed real-world platform. This dataset is tailored for robotic hands, offering models with whole-hand tactile perception and high-quality, well-aligned data. To the best of our knowledge, the VinT-Real is the largest considering the collection difficulties in the real-world environment so that it can bridge the gap of simulation to real compared to the previous works. Built upon VinT-6D, we present a benchmark method that shows significant improvements in performance by fusing multi-modal information. The project is available at https://VinT-6D.github.io/.
Relieving Universal Label Noise for Unsupervised Visible-Infrared Person Re-Identification by Inferring from Neighbors
Dec 16, 2024Unsupervised visible-infrared person re-identification (USL-VI-ReID) is of great research and practical significance yet remains challenging due to the absence of annotations. Existing approaches aim to learn modality-invariant representations in an unsupervised setting. However, these methods often encounter label noise within and across modalities due to suboptimal clustering results and considerable modality discrepancies, which impedes effective training. To address these challenges, we propose a straightforward yet effective solution for USL-VI-ReID by mitigating universal label noise using neighbor information. Specifically, we introduce the Neighbor-guided Universal Label Calibration (N-ULC) module, which replaces explicit hard pseudo labels in both homogeneous and heterogeneous spaces with soft labels derived from neighboring samples to reduce label noise. Additionally, we present the Neighbor-guided Dynamic Weighting (N-DW) module to enhance training stability by minimizing the influence of unreliable samples. Extensive experiments on the RegDB and SYSU-MM01 datasets demonstrate that our method outperforms existing USL-VI-ReID approaches, despite its simplicity. The source code is available at: https://github.com/tengxiao14/Neighbor-guided-USL-VI-ReID.
Lifelike Agility and Play on Quadrupedal Robots using Reinforcement Learning and Generative Pre-trained Models
Aug 29, 2023Summarizing knowledge from animals and human beings inspires robotic innovations. In this work, we propose a framework for driving legged robots act like real animals with lifelike agility and strategy in complex environments. Inspired by large pre-trained models witnessed with impressive performance in language and image understanding, we introduce the power of advanced deep generative models to produce motor control signals stimulating legged robots to act like real animals. Unlike conventional controllers and end-to-end RL methods that are task-specific, we propose to pre-train generative models over animal motion datasets to preserve expressive knowledge of animal behavior. The pre-trained model holds sufficient primitive-level knowledge yet is environment-agnostic. It is then reused for a successive stage of learning to align with the environments by traversing a number of challenging obstacles that are rarely considered in previous approaches, including creeping through narrow spaces, jumping over hurdles, freerunning over scattered blocks, etc. Finally, a task-specific controller is trained to solve complex downstream tasks by reusing the knowledge from previous stages. Enriching the knowledge regarding each stage does not affect the usage of other levels of knowledge. This flexible framework offers the possibility of continual knowledge accumulation at different levels. We successfully apply the trained multi-level controllers to the MAX robot, a quadrupedal robot developed in-house, to mimic animals, traverse complex obstacles, and play in a designed challenging multi-agent Chase Tag Game, where lifelike agility and strategy emerge on the robots. The present research pushes the frontier of robot control with new insights on reusing multi-level pre-trained knowledge and solving highly complex downstream tasks in the real world.
RefSAM: Efficiently Adapting Segmenting Anything Model for Referring Video Object Segmentation
Jul 03, 2023The Segment Anything Model (SAM) has gained significant attention for its impressive performance in image segmentation. However, it lacks proficiency in referring video object segmentation (RVOS) due to the need for precise user-interactive prompts and limited understanding of different modalities, such as language and vision. This paper presents the RefSAM model, which for the first time explores the potential of SAM for RVOS by incorporating multi-view information from diverse modalities and successive frames at different timestamps. Our proposed approach adapts the original SAM model to enhance cross-modality learning by employing a lightweight Cross-Modal MLP that projects the text embedding of the referring expression into sparse and dense embeddings, serving as user-interactive prompts. Subsequently, a parameter-efficient tuning strategy is employed to effectively align and fuse the language and vision features. Through comprehensive ablation studies, we demonstrate the practical and effective design choices of our strategy. Extensive experiments conducted on Ref-Youtu-VOS and Ref-DAVIS17 datasets validate the superiority and effectiveness of our RefSAM model over existing methods. The code and models will be made publicly at \href{https://github.com/LancasterLi/RefSAM}{github.com/LancasterLi/RefSAM}.
Multi-scale Knowledge Distillation for Unsupervised Person Re-Identification
Apr 21, 2022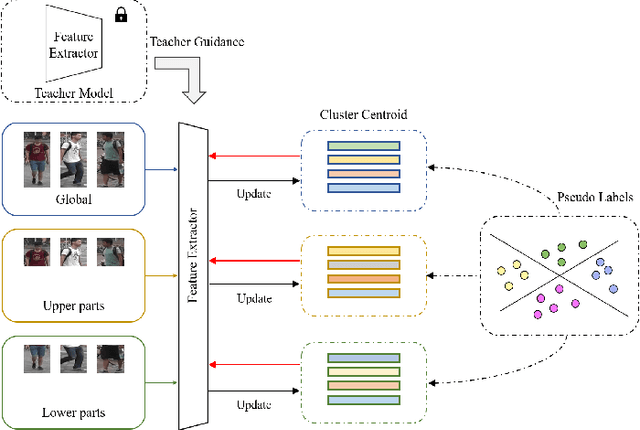
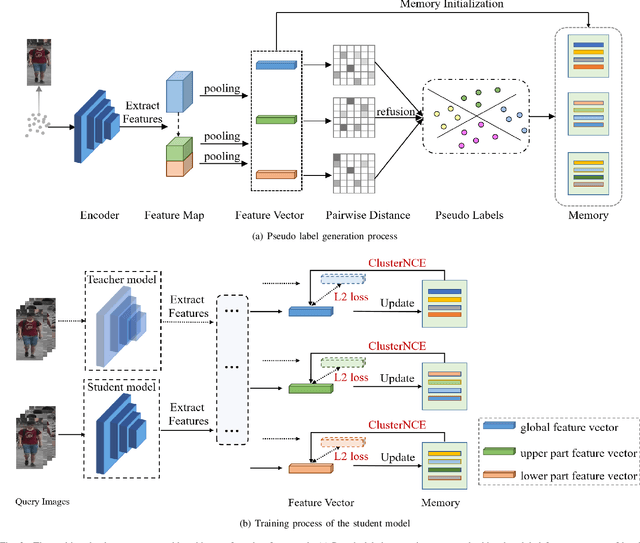
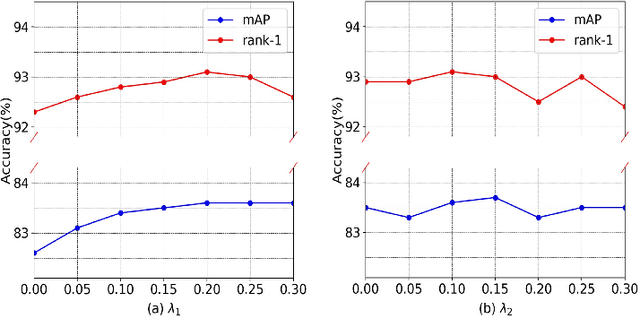
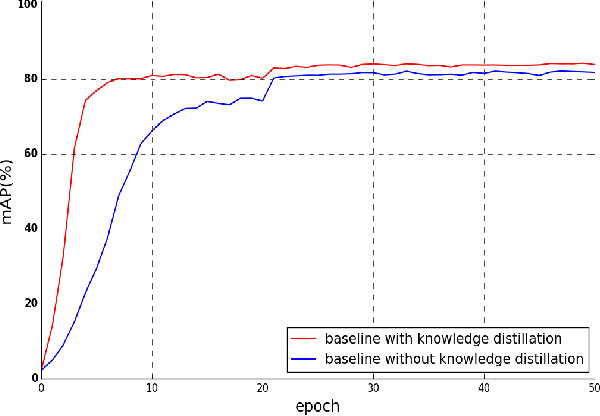
Unsupervised person re-identification is a challenging and promising task in the computer vision. Nowadays unsupervised person re-identification methods have achieved great improvements by training with pseudo labels. However, the appearance and label noise are less explicitly studied in the unsupervised manner. To relieve the effects of appearance noise the global features involved, we also take into account the features from two local views and produce multi-scale features. We explore the knowledge distillation to filter label noise, Specifically, we first train a teacher model from noisy pseudo labels in a iterative way, and then use the teacher model to guide the learning of our student model. In our setting, the student model could converge fast in the supervision of the teacher model thus reduce the interference of noisy labels as the teacher model greatly suffered. After carefully handling the noises in the feature learning, Our multi-scale knowledge distillation are proven to be very effective in the unsupervised re-identification. Extensive experiments on three popular person re-identification datasets demonstrate the superiority of our method. Especially, our approach achieves a state-of-the-art accuracy 85.7% @mAP or 94.3% @Rank-1 on the challenging Market-1501 benchmark with ResNet-50 under the fully unsupervised setting.