 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dynamic Association Learning of Self-Attention and Convolution in Image Restoration
Nov 09, 2023
CNNs and Self attention have achieved great success in multimedia applications for dynamic association learning of self-attention and convolution in image restoration. However, CNNs have at least two shortcomings: 1) limited receptive field; 2) static weight of sliding window at inference, unable to cope with the content diversity.In view of the advantages and disadvantages of CNNs and Self attention, this paper proposes an association learning method to utilize the advantages and suppress their shortcomings, so as to achieve high-quality and efficient inpainting. We regard rain distribution reflects the degradation location and degree, in addition to the rain distribution prediction. Thus, we propose to refine background textures with the predicted degradation prior in an association learning manner. As a result, we accomplish image deraining by associating rain streak removal and background recovery, where an image deraining network and a background recovery network are designed for two subtasks. The key part of association learning is a novel multi-input attention module. It generates the degradation prior and produces the degradation mask according to the predicted rainy distribution. Benefited from the global correlation calculation of SA, MAM can extract the informative complementary components from the rainy input with the degradation mask, and then help accurate texture restoration. Meanwhile, SA tends to aggregate feature maps with self-attention importance, but convolution diversifies them to focus on the local textures. A hybrid fusion network involves one residual Transformer branch and one encoder-decoder branch. The former takes a few learnable tokens as input and stacks multi-head attention and feed-forward networks to encode global features of the image. The latter, conversely, leverages the multi-scale encoder-decoder to represent contexture knowledge.
Optimized View and Geometry Distillation from Multi-view Diffuser
Dec 17, 2023Generating multi-view images from a single input view using image-conditioned diffusion models is a recent advancement and has shown considerable potential. However, issues such as the lack of consistency in synthesized views and over-smoothing in extracted geometry persist. Previous methods integrate multi-view consistency modules or impose additional supervisory to enhance view consistency while compromising on the flexibility of camera positioning and limiting the versatility of view synthesis. In this study, we consider the radiance field optimized during geometry extraction as a more rigid consistency prior, compared to volume and ray aggregation used in previous works. We further identify and rectify a critical bias in the traditional radiance field optimization process through score distillation from a multi-view diffuser. We introduce an Unbiased Score Distillation (USD) that utilizes unconditioned noises from a 2D diffusion model, greatly refining the radiance field fidelity. we leverage the rendered views from the optimized radiance field as the basis and develop a two-step specialization process of a 2D diffusion model, which is adept at conducting object-specific denoising and generating high-quality multi-view images. Finally, we recover faithful geometry and texture directly from the refined multi-view images. Empirical evaluations demonstrate that our optimized geometry and view distillation technique generates comparable results to the state-of-the-art models trained on extensive datasets, all while maintaining freedom in camera positioning. Please see our project page at https://youjiazhang.github.io/USD/.
3DAxiesPrompts: Unleashing the 3D Spatial Task Capabilities of GPT-4V
Dec 15, 2023
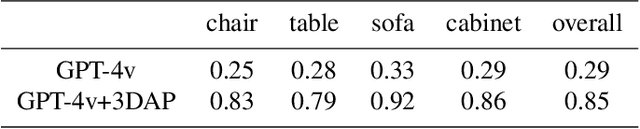
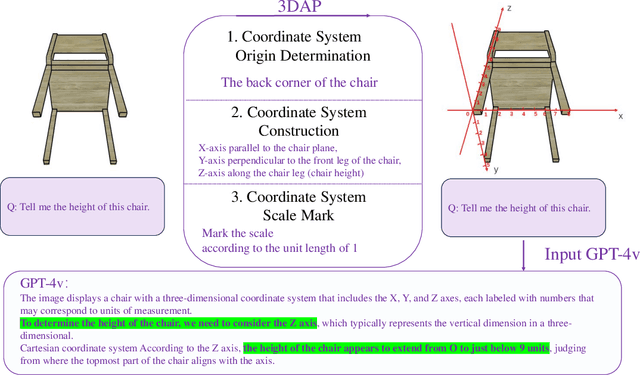

In this work, we present a new visual prompting method called 3DAxiesPrompts (3DAP) to unleash the capabilities of GPT-4V in performing 3D spatial tasks. Our investigation reveals that while GPT-4V exhibits proficiency in discerning the position and interrelations of 2D entities through current visual prompting techniques, its abilities in handling 3D spatial tasks have yet to be explored. In our approach, we create a 3D coordinate system tailored to 3D imagery, complete with annotated scale information. By presenting images infused with the 3DAP visual prompt as inputs, we empower GPT-4V to ascertain the spatial positioning information of the given 3D target image with a high degree of precision. Through experiments, We identified three tasks that could be stably completed using the 3DAP method, namely, 2D to 3D Point Reconstruction, 2D to 3D point matching, and 3D Object Detection. We perform experiments on our proposed dataset 3DAP-Data, the results from these experiments validate the efficacy of 3DAP-enhanced GPT-4V inputs, marking a significant stride in 3D spatial task execution.
Let All be Whitened: Multi-teacher Distillation for Efficient Visual Retrieval
Dec 15, 2023Visual retrieval aims to search for the most relevant visual items, e.g., images and videos, from a candidate gallery with a given query item. Accuracy and efficiency are two competing objectives in retrieval tasks. Instead of crafting a new method pursuing further improvement on accuracy, in this paper we propose a multi-teacher distillation framework Whiten-MTD, which is able to transfer knowledge from off-the-shelf pre-trained retrieval models to a lightweight student model for efficient visual retrieval. Furthermore, we discover that the similarities obtained by different retrieval models are diversified and incommensurable, which makes it challenging to jointly distill knowledge from multiple models. Therefore, we propose to whiten the output of teacher models before fusion, which enables effective multi-teacher distillation for retrieval models. Whiten-MTD is conceptually simple and practically effective. Extensive experiments on two landmark image retrieval datasets and one video retrieval dataset demonstrate the effectiveness of our proposed method, and its good balance of retrieval performance and efficiency. Our source code is released at https://github.com/Maryeon/whiten_mtd.
NM-FlowGAN: Modeling sRGB Noise with a Hybrid Approach based on Normalizing Flows and Generative Adversarial Networks
Dec 15, 2023Modeling and synthesizing real sRGB noise is crucial for various low-level vision tasks. The distribution of real sRGB noise is highly complex and affected by a multitude of factors, making its accurate modeling extremely challenging. Therefore, recent studies have proposed methods that employ data-driven generative models, such as generative adversarial networks (GAN) and Normalizing Flows. These studies achieve more accurate modeling of sRGB noise compared to traditional noise modeling methods. However, there are performance limitations due to the inherent characteristics of each generative model. To address this issue, we propose NM-FlowGAN, a hybrid approach that exploits the strengths of both GAN and Normalizing Flows. We simultaneously employ a pixel-wise noise modeling network based on Normalizing Flows, and spatial correlation modeling networks based on GAN. In our experiments, our NM-FlowGAN outperforms other baselines on the sRGB noise synthesis task. Moreover, the denoising neural network, trained with synthesized image pairs from our model, also shows superior performance compared to other baselines. Our code is available at: https://github.com/YoungJooHan/NM-FlowGAN
WeatherProof: A Paired-Dataset Approach to Semantic Segmentation in Adverse Weather
Dec 15, 2023The introduction of large, foundational models to computer vision has led to drastically improved performance on the task of semantic segmentation. However, these existing methods exhibit a large performance drop when testing on images degraded by weather conditions such as rain, fog, or snow. We introduce a general paired-training method that can be applied to all current foundational model architectures that leads to improved performance on images in adverse weather conditions. To this end, we create the WeatherProof Dataset, the first semantic segmentation dataset with accurate clear and adverse weather image pairs, which not only enables our new training paradigm, but also improves the evaluation of the performance gap between clear and degraded segmentation. We find that training on these paired clear and adverse weather frames which share an underlying scene results in improved performance on adverse weather data. With this knowledge, we propose a training pipeline which accentuates the advantages of paired-data training using consistency losses and language guidance, which leads to performance improvements by up to 18.4% as compared to standard training procedures.
VSFormer: Visual-Spatial Fusion Transformer for Correspondence Pruning
Dec 15, 2023Correspondence pruning aims to find correct matches (inliers) from an initial set of putative correspondences, which is a fundamental task for many applications. The process of finding is challenging, given the varying inlier ratios between scenes/image pairs due to significant visual differences. However, the performance of the existing methods is usually limited by the problem of lacking visual cues (\eg texture, illumination, structure) of scenes. In this paper, we propose a Visual-Spatial Fusion Transformer (VSFormer) to identify inliers and recover camera poses accurately. Firstly, we obtain highly abstract visual cues of a scene with the cross attention between local features of two-view images. Then, we model these visual cues and correspondences by a joint visual-spatial fusion module, simultaneously embedding visual cues into correspondences for pruning. Additionally, to mine the consistency of correspondences, we also design a novel module that combines the KNN-based graph and the transformer, effectively capturing both local and global contexts. Extensive experiments have demonstrated that the proposed VSFormer outperforms state-of-the-art methods on outdoor and indoor benchmarks.
MSE-Nets: Multi-annotated Semi-supervised Ensemble Networks for Improving Segmentation of Medical Image with Ambiguous Boundaries
Nov 17, 2023Medical image segmentation annotations exhibit variations among experts due to the ambiguous boundaries of segmented objects and backgrounds in medical images. Although using multiple annotations for each image in the fully-supervised has been extensively studied for training deep models, obtaining a large amount of multi-annotated data is challenging due to the substantial time and manpower costs required for segmentation annotations, resulting in most images lacking any annotations. To address this, we propose Multi-annotated Semi-supervised Ensemble Networks (MSE-Nets) for learning segmentation from limited multi-annotated and abundant unannotated data. Specifically, we introduce the Network Pairwise Consistency Enhancement (NPCE) module and Multi-Network Pseudo Supervised (MNPS) module to enhance MSE-Nets for the segmentation task by considering two major factors: (1) to optimize the utilization of all accessible multi-annotated data, the NPCE separates (dis)agreement annotations of multi-annotated data at the pixel level and handles agreement and disagreement annotations in different ways, (2) to mitigate the introduction of imprecise pseudo-labels, the MNPS extends the training data by leveraging consistent pseudo-labels from unannotated data. Finally, we improve confidence calibration by averaging the predictions of base networks. Experiments on the ISIC dataset show that we reduced the demand for multi-annotated data by 97.75\% and narrowed the gap with the best fully-supervised baseline to just a Jaccard index of 4\%. Furthermore, compared to other semi-supervised methods that rely only on a single annotation or a combined fusion approach, the comprehensive experimental results on ISIC and RIGA datasets demonstrate the superior performance of our proposed method in medical image segmentation with ambiguous boundaries.
Towards Better Morphed Face Images without Ghosting Artifacts
Dec 13, 2023Automatic generation of morphed face images often produces ghosting artifacts due to poorly aligned structures in the input images. Manual processing can mitigate these artifacts. However, this is not feasible for the generation of large datasets, which are required for training and evaluating robust morphing attack detectors. In this paper, we propose a method for automatic prevention of ghosting artifacts based on a pixel-wise alignment during morph generation. We evaluate our proposed method on state-of-the-art detectors and show that our morphs are harder to detect, particularly, when combined with style-transfer-based improvement of low-level image characteristics. Furthermore, we show that our approach does not impair the biometric quality, which is essential for high quality morphs.
Patient-Adaptive and Learned MRI Data Undersampling Using Neighborhood Clustering
Dec 13, 2023There has been much recent interest in adapting undersampled trajectories in MRI based on training data. In this work, we propose a novel patient-adaptive MRI sampling algorithm based on grouping scans within a training set. Scan-adaptive sampling patterns are optimized together with an image reconstruction network for the training scans. The training optimization alternates between determining the best sampling pattern for each scan (based on a greedy search or iterative coordinate descent (ICD)) and training a reconstructor across the dataset. The eventual scan-adaptive sampling patterns on the training set are used as labels to predict sampling design using nearest neighbor search at test time. The proposed algorithm is applied to the fastMRI knee multicoil dataset and demonstrates improved performance over several baselines.