 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTGFormer: Towards Temporal Graph Transformer with Auto-Correlation Mechanism
May 24, 2026The growing interest in Temporal Graph Neural Networks (TGNNs) stems from their ability to model complex dynamics and deliver superior performance. However, TGNNs encounter fundamental challenges in capturing long-term dependencies and identifying periodic patterns. To address these limitations, we propose TGFormer, a novel Transformer architecture specifically designed for temporal graphs. Our model redefines temporal graph learning by establishing a trajectory framework that aligns with time series analysis principles. This approach allows TGFormer to derive node representations through systematic analysis of historical interactions, enabling granular examination of node relationships across sequential timestamps. Building upon stochastic process theory, we develop an auto-correlation mechanism that systematically uncovers periodic dependencies in node interactions. This innovation empowers TGFormer to perform dependency discovery and representation aggregation at sub-interaction levels, demonstrating superior efficiency and accuracy compared to conventional attention mechanisms. Experimental validation across six public benchmarks confirms the effectiveness of our approach, with TGFormer at most achieving 9.35\% precision improvement compared to state-of-the-art approaches.
ST-TGExplainer: Disentangling Stability and Transition Patterns for Temporal GNN Interpretability
May 19, 2026Temporal graph neural networks (TGNNs) have gained significant traction for solving real-world temporal graph tasks. However, their interpretability remains limited, as most TGNNs fail to identify which historical interactions most influence a given prediction. Despite promising progress on interpretable TGNNs, existing methods predominantly focus on previously seen historical interactions, which we term stability patterns, while overlooking newly emerging first-time interactions, which we term transition patterns. Both types of patterns are essential for faithful temporal explanations. To address this limitation, we propose ST-TGExplainer, a self-explainable TGNN that disentangles Stability and Transition patterns in temporal graphs for a more faithful Temporal GNN Explainer. Guided by a disentangled information bottleneck objective, ST-TGExplainer learns a compact explanatory subgraph that remains predictive of the event label while explicitly suppressing label-conditioned redundancy between stability and transition patterns. Extensive experiments demonstrate that ST-TGExplainer achieves strong predictive performance and yields more faithful explanations. Code is available at https://github.com/hjchen-hdu/ST-TGExplainer.
One-Step Graph-Structured Neural Flows for Irregular Multivariate Time Series Classification
May 11, 2026Neural Flows efficiently model irregular multivariate time series by directly learning ODE solution trajectories with neural networks, bypassing step-by-step numerical solvers. Despite their efficiency, many existing approaches treat variables independently, leaving inter-variable interactions underexplored. Moreover, their one-step mapping makes interaction modeling inherently challenging, as it removes the iterative refinement of interactions during learning. To address this challenge, we propose one-step Graph-Structured Neural Flows (GSNF), which introduce two auxiliary-trajectory self-supervision strategies to strengthen interaction learning: (i) interaction-aware trajectory generation via re-initialization, which induces trajectory divergence to expose graph-induced interactions, with a theoretically derived lower bound on divergence; and (ii) reverse-time trajectory generation, which enforces forward-backward consistency to regularize graph learning, enabled by flow invertibility. Experiments on five real-world datasets show that GSNF achieves state-of-the-art classification performance with highly competitive training time and memory usage.
Can LLMs Fool Graph Learning? Exploring Universal Adversarial Attacks on Text-Attributed Graphs
Mar 22, 2026Text-attributed graphs (TAGs) enhance graph learning by integrating rich textual semantics and topological context for each node. While boosting expressiveness, they also expose new vulnerabilities in graph learning through text-based adversarial surfaces. Recent advances leverage diverse backbones, such as graph neural networks (GNNs) and pre-trained language models (PLMs), to capture both structural and textual information in TAGs. This diversity raises a key question: How can we design universal adversarial attacks that generalize across architectures to assess the security of TAG models? The challenge arises from the stark contrast in how different backbones-GNNs and PLMs-perceive and encode graph patterns, coupled with the fact that many PLMs are only accessible via APIs, limiting attacks to black-box settings. To address this, we propose BadGraph, a novel attack framework that deeply elicits large language models (LLMs) understanding of general graph knowledge to jointly perturb both node topology and textual semantics. Specifically, we design a target influencer retrieval module that leverages graph priors to construct cross-modally aligned attack shortcuts, thereby enabling efficient LLM-based perturbation reasoning. Experiments show that BadGraph achieves universal and effective attacks across GNN- and LLM-based reasoners, with up to a 76.3% performance drop, while theoretical and empirical analyses confirm its stealthy yet interpretable nature.
GoAgent: Group-of-Agents Communication Topology Generation for LLM-based Multi-Agent Systems
Mar 20, 2026Large language model (LLM)-based multi-agent systems (MAS) have demonstrated exceptional capabilities in solving complex tasks, yet their effectiveness depends heavily on the underlying communication topology that coordinates agent interactions. Within these systems, successful problem-solving often necessitates task-specific group structures to divide and conquer subtasks. However, most existing approaches generate communication topologies in a node-centric manner, leaving group structures to emerge implicitly from local connectivity decisions rather than modeling them explicitly, often leading to suboptimal coordination and unnecessary communication overhead. To address this limitation, we propose GoAgent (Group-of-Agents), a communication topology generation method that explicitly treats collaborative groups as the atomic units of MAS construction. Specifically, GoAgent first enumerates task-relevant candidate groups through an LLM and then autoregressively selects and connects these groups as atomic units to construct the final communication graph, jointly capturing intra-group cohesion and inter-group coordination. To mitigate communication redundancy and noise propagation inherent in expanding topologies, we further introduce a conditional information bottleneck (CIB) objective that compresses inter-group communication, preserving task-relevant signals while filtering out redundant historical noise. Extensive experiments on six benchmarks demonstrate the state-of-the-art performance of GoAgent with 93.84% average accuracy while reducing token consumption by about 17%.
Towards OOD Generalization in Dynamic Graphs via Causal Invariant Learning
Mar 02, 2026Although dynamic graph neural networks (DyGNNs) have demonstrated promising capabilities, most existing methods ignore out-of-distribution (OOD) shifts that commonly exist in dynamic graphs. Dynamic graph OOD generalization is non-trivial due to the following challenges: 1) Identifying invariant and variant patterns amid complex graph evolution, 2) Capturing the intrinsic evolution rationale from these patterns, and 3) Ensuring model generalization across diverse OOD shifts despite limited data distribution observations. Although several attempts have been made to tackle these challenges, none has successfully addressed all three simultaneously, and they face various limitations in complex OOD scenarios. To solve these issues, we propose a Dynamic graph Causal Invariant Learning (DyCIL) model for OOD generalization via exploiting invariant spatio-temporal patterns from a causal view. Specifically, we first develop a dynamic causal subgraph generator to identify causal dynamic subgraphs explicitly. Next, we design a causal-aware spatio-temporal attention module to extract the intrinsic evolution rationale behind invariant patterns. Finally, we further introduce an adaptive environment generator to capture the underlying dynamics of distributional shifts. Extensive experiments on both real-world and synthetic dynamic graph datasets demonstrate the superiority of our model over state-of-the-art baselines in handling OOD shifts.
HGMP:Heterogeneous Graph Multi-Task Prompt Learning
Jul 10, 2025



The pre-training and fine-tuning methods have gained widespread attention in the field of heterogeneous graph neural networks due to their ability to leverage large amounts of unlabeled data during the pre-training phase, allowing the model to learn rich structural features. However, these methods face the issue of a mismatch between the pre-trained model and downstream tasks, leading to suboptimal performance in certain application scenarios. Prompt learning methods have emerged as a new direction in heterogeneous graph tasks, as they allow flexible adaptation of task representations to address target inconsistency. Building on this idea, this paper proposes a novel multi-task prompt framework for the heterogeneous graph domain, named HGMP. First, to bridge the gap between the pre-trained model and downstream tasks, we reformulate all downstream tasks into a unified graph-level task format. Next, we address the limitations of existing graph prompt learning methods, which struggle to integrate contrastive pre-training strategies in the heterogeneous graph domain. We design a graph-level contrastive pre-training strategy to better leverage heterogeneous information and enhance performance in multi-task scenarios. Finally, we introduce heterogeneous feature prompts, which enhance model performance by refining the representation of input graph features. Experimental results on public datasets show that our proposed method adapts well to various tasks and significantly outperforms baseline methods.
HeTa: Relation-wise Heterogeneous Graph Foundation Attack Model
Jun 09, 2025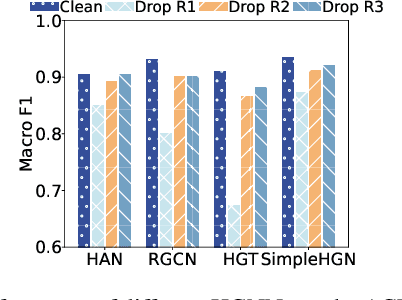



Heterogeneous Graph Neural Networks (HGNNs) are vulnerable, highlighting the need for tailored attacks to assess their robustness and ensure security. However, existing HGNN attacks often require complex retraining of parameters to generate specific perturbations for new scenarios. Recently, foundation models have opened new horizons for the generalization of graph neural networks by capturing shared semantics across various graph distributions. This leads us to ask:Can we design a foundation attack model for HGNNs that enables generalizable perturbations across different HGNNs, and quickly adapts to new heterogeneous graphs (HGs)? Empirical findings reveal that, despite significant differences in model design and parameter space, different HGNNs surprisingly share common vulnerability patterns from a relation-aware perspective. Therefore, we explore how to design foundation HGNN attack criteria by mining shared attack units. In this paper, we propose a novel relation-wise heterogeneous graph foundation attack model, HeTa. We introduce a foundation surrogate model to align heterogeneity and identify the importance of shared relation-aware attack units. Building on this, we implement a serialized relation-by-relation attack based on the identified relational weights. In this way, the perturbation can be transferred to various target HGNNs and easily fine-tuned for new HGs. Extensive experiments exhibit powerful attack performances and generalizability of our method.
A Survey on Temporal Interaction Graph Representation Learning: Progress, Challenges, and Opportunities
May 07, 2025Temporal interaction graphs (TIGs), defined by sequences of timestamped interaction events, have become ubiquitous in real-world applications due to their capability to model complex dynamic system behaviors. As a result, temporal interaction graph representation learning (TIGRL) has garnered significant attention in recent years. TIGRL aims to embed nodes in TIGs into low-dimensional representations that effectively preserve both structural and temporal information, thereby enhancing the performance of downstream tasks such as classification, prediction, and clustering within constantly evolving data environments. In this paper, we begin by introducing the foundational concepts of TIGs and emphasize the critical role of temporal dependencies. We then propose a comprehensive taxonomy of state-of-the-art TIGRL methods, systematically categorizing them based on the types of information utilized during the learning process to address the unique challenges inherent to TIGs. To facilitate further research and practical applications, we curate the source of datasets and benchmarks, providing valuable resources for empirical investigations. Finally, we examine key open challenges and explore promising research directions in TIGRL, laying the groundwork for future advancements that have the potential to shape the evolution of this field.
Data Poisoning in Deep Learning: A Survey
Mar 27, 2025



Deep learning has become a cornerstone of modern artificial intelligence, enabling transformative applications across a wide range of domains. As the core element of deep learning, the quality and security of training data critically influence model performance and reliability. However, during the training process, deep learning models face the significant threat of data poisoning, where attackers introduce maliciously manipulated training data to degrade model accuracy or lead to anomalous behavior. While existing surveys provide valuable insights into data poisoning, they generally adopt a broad perspective, encompassing both attacks and defenses, but lack a dedicated, in-depth analysis of poisoning attacks specifically in deep learning. In this survey, we bridge this gap by presenting a comprehensive and targeted review of data poisoning in deep learning. First, this survey categorizes data poisoning attacks across multiple perspectives, providing an in-depth analysis of their characteristics and underlying design princinples. Second, the discussion is extended to the emerging area of data poisoning in large language models(LLMs). Finally, we explore critical open challenges in the field and propose potential research directions to advance the field further. To support further exploration, an up-to-date repository of resources on data poisoning in deep learning is available at https://github.com/Pinlong-Zhao/Data-Poisoning.