 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASI-Evolve: AI Accelerates AI
Mar 31, 2026Can AI accelerate the development of AI itself? While recent agentic systems have shown strong performance on well-scoped tasks with rapid feedback, it remains unclear whether they can tackle the costly, long-horizon, and weakly supervised research loops that drive real AI progress. We present ASI-Evolve, an agentic framework for AI-for-AI research that closes this loop through a learn-design-experiment-analyze cycle. ASI-Evolve augments standard evolutionary agents with two key components: a cognition base that injects accumulated human priors into each round of exploration, and a dedicated analyzer that distills complex experimental outcomes into reusable insights for future iterations. To our knowledge, ASI-Evolve is the first unified framework to demonstrate AI-driven discovery across three central components of AI development: data, architectures, and learning algorithms. In neural architecture design, it discovered 105 SOTA linear attention architectures, with the best discovered model surpassing DeltaNet by +0.97 points, nearly 3x the gain of recent human-designed improvements. In pretraining data curation, the evolved pipeline improves average benchmark performance by +3.96 points, with gains exceeding 18 points on MMLU. In reinforcement learning algorithm design, discovered algorithms outperform GRPO by up to +12.5 points on AMC32, +11.67 points on AIME24, and +5.04 points on OlympiadBench. We further provide initial evidence that this AI-for-AI paradigm can transfer beyond the AI stack through experiments in mathematics and biomedicine. Together, these results suggest that ASI-Evolve represents a promising step toward enabling AI to accelerate AI across the foundational stages of development, offering early evidence for the feasibility of closed-loop AI research.
daVinci-LLM:Towards the Science of Pretraining
Mar 28, 2026The foundational pretraining phase determines a model's capability ceiling, as post-training struggles to overcome capability foundations established during pretraining, yet it remains critically under-explored. This stems from a structural paradox: organizations with computational resources operate under commercial pressures that inhibit transparent disclosure, while academic institutions possess research freedom but lack pretraining-scale computational resources. daVinci-LLM occupies this unexplored intersection, combining industrial-scale resources with full research freedom to advance the science of pretraining. We adopt a fully-open paradigm that treats openness as scientific methodology, releasing complete data processing pipelines, full training processes, and systematic exploration results. Recognizing that the field lacks systematic methodology for data processing, we employ the Data Darwinism framework, a principled L0-L9 taxonomy from filtering to synthesis. We train a 3B-parameter model from random initialization across 8T tokens using a two-stage adaptive curriculum that progressively shifts from foundational capabilities to reasoning-intensive enhancement. Through 200+ controlled ablations, we establish that: processing depth systematically enhances capabilities, establishing it as a critical dimension alongside volume scaling; different domains exhibit distinct saturation dynamics, necessitating adaptive strategies from proportion adjustments to format shifts; compositional balance enables targeted intensification while preventing performance collapse; how evaluation protocol choices shape our understanding of pretraining progress. By releasing the complete exploration process, we enable the community to build upon our findings and systematic methodologies to form accumulative scientific knowledge in pretraining.
Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Mar 23, 2026We present daVinci-MagiHuman, an open-source audio-video generative foundation model for human-centric generation. daVinci-MagiHuman jointly generates synchronized video and audio using a single-stream Transformer that processes text, video, and audio within a unified token sequence via self-attention only. This single-stream design avoids the complexity of multi-stream or cross-attention architectures while remaining easy to optimize with standard training and inference infrastructure. The model is particularly strong in human-centric scenarios, producing expressive facial performance, natural speech-expression coordination, realistic body motion, and precise audio-video synchronization. It supports multilingual spoken generation across Chinese (Mandarin and Cantonese), English, Japanese, Korean, German, and French. For efficient inference, we combine the single-stream backbone with model distillation, latent-space super-resolution, and a Turbo VAE decoder, enabling generation of a 5-second 256p video in 2 seconds on a single H100 GPU. In automatic evaluation, daVinci-MagiHuman achieves the highest visual quality and text alignment among leading open models, along with the lowest word error rate (14.60%) for speech intelligibility. In pairwise human evaluation, it achieves win rates of 80.0% against Ovi 1.1 and 60.9% against LTX 2.3 over 2000 comparisons. We open-source the complete model stack, including the base model, the distilled model, the super-resolution model, and the inference codebase.
Data Darwinism Part II: DataEvolve -- AI can Autonomously Evolve Pretraining Data Curation
Mar 15, 2026Data Darwinism (Part I) established a ten-level hierarchy for data processing, showing that stronger processing can unlock greater data value. However, that work relied on manually designed strategies for a single category. Modern pretraining corpora comprise hundreds of heterogeneous categories spanning domains and content types, each demanding specialized treatment. At this scale, manual strategy design becomes prohibitive. This raises a key question: can strategies evolve in an automated way? We introduce DataEvolve, a framework that enables strategies to evolve through iterative optimization rather than manual design. For each data category, DataEvolve operates in a closed evolutionary loop: it identifies quality issues, generates candidate strategies, executes them on sampled data, evaluates results, and refines approaches across generations. The process accumulates knowledge through an experience pool of discovered issues and a strategy pool tracking performance across iterations. Applied to 8 categories spanning 672B tokens from Nemotron-CC, DataEvolve produces Darwin-CC, a 504B-token dataset with strategies evolved through 30 iterations per category. Training 3B models on 500B tokens, Darwin-CC outperforms raw data (+3.96 points) and achieves a 44.13 average score across 18 benchmarks, surpassing DCLM, Ultra-FineWeb, and FineWeb-Edu, with strong gains on knowledge-intensive tasks such as MMLU. Analysis shows evolved strategies converge on cleaning-focused approaches: targeted noise removal and format normalization with domain-aware preservation, echoing the L4 (Generative Refinement) principles from Part I. Ablation studies confirm iterative evolution is essential: optimized strategies outperform suboptimal ones by 2.93 points, establishing evolutionary strategy design as feasible and necessary for pretraining-scale data curation.
AlphaGo Moment for Model Architecture Discovery
Jul 24, 2025
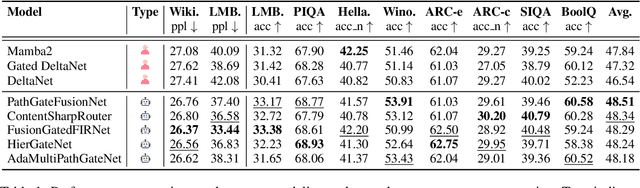
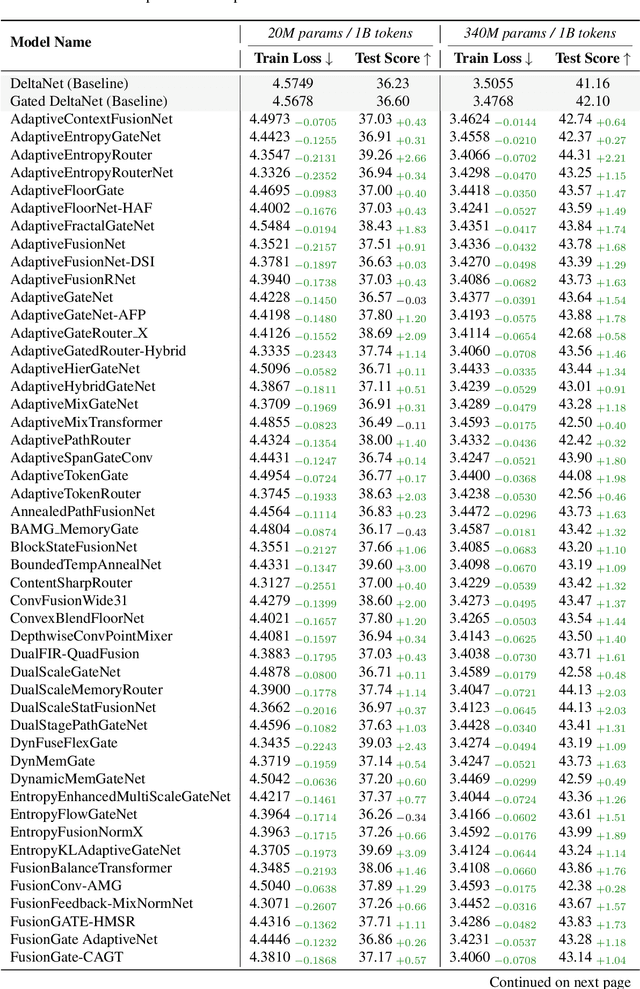

While AI systems demonstrate exponentially improving capabilities, the pace of AI research itself remains linearly bounded by human cognitive capacity, creating an increasingly severe development bottleneck. We present ASI-Arch, the first demonstration of Artificial Superintelligence for AI research (ASI4AI) in the critical domain of neural architecture discovery--a fully autonomous system that shatters this fundamental constraint by enabling AI to conduct its own architectural innovation. Moving beyond traditional Neural Architecture Search (NAS), which is fundamentally limited to exploring human-defined spaces, we introduce a paradigm shift from automated optimization to automated innovation. ASI-Arch can conduct end-to-end scientific research in the domain of architecture discovery, autonomously hypothesizing novel architectural concepts, implementing them as executable code, training and empirically validating their performance through rigorous experimentation and past experience. ASI-Arch conducted 1,773 autonomous experiments over 20,000 GPU hours, culminating in the discovery of 106 innovative, state-of-the-art (SOTA) linear attention architectures. Like AlphaGo's Move 37 that revealed unexpected strategic insights invisible to human players, our AI-discovered architectures demonstrate emergent design principles that systematically surpass human-designed baselines and illuminate previously unknown pathways for architectural innovation. Crucially, we establish the first empirical scaling law for scientific discovery itself--demonstrating that architectural breakthroughs can be scaled computationally, transforming research progress from a human-limited to a computation-scalable process. We provide comprehensive analysis of the emergent design patterns and autonomous research capabilities that enabled these breakthroughs, establishing a blueprint for self-accelerating AI systems.
Generative AI Act II: Test Time Scaling Drives Cognition Engineering
Apr 21, 2025



The first generation of Large Language Models - what might be called "Act I" of generative AI (2020-2023) - achieved remarkable success through massive parameter and data scaling, yet exhibited fundamental limitations such as knowledge latency, shallow reasoning, and constrained cognitive processes. During this era, prompt engineering emerged as our primary interface with AI, enabling dialogue-level communication through natural language. We now witness the emergence of "Act II" (2024-present), where models are transitioning from knowledge-retrieval systems (in latent space) to thought-construction engines through test-time scaling techniques. This new paradigm establishes a mind-level connection with AI through language-based thoughts. In this paper, we clarify the conceptual foundations of cognition engineering and explain why this moment is critical for its development. We systematically break down these advanced approaches through comprehensive tutorials and optimized implementations, democratizing access to cognition engineering and enabling every practitioner to participate in AI's second act. We provide a regularly updated collection of papers on test-time scaling in the GitHub Repository: https://github.com/GAIR-NLP/cognition-engineering
Reproducibility Companion Paper:In-processing User Constrained Dominant Sets for User-Oriented Fairness in Recommender Systems
Mar 29, 2025In this paper, we reproduce experimental results presented in our earlier work titled "In-processing User Constrained Dominant Sets for User-Oriented Fairness in Recommender Systems" that was presented in the proceeding of the 31st ACM International Conference on Multimedia.This work aims to verify the effectiveness of our previously proposed method and provide guidance for reproducibility. We present detailed descriptions of our preprocessed datasets, the structure of our source code, configuration file settings, experimental environment, and the reproduced experimental results.
DIVE: Diversified Iterative Self-Improvement
Jan 01, 2025Recent advances in large language models (LLMs) have demonstrated the effectiveness of Iterative Self-Improvement (ISI) techniques. However, continuous training on self-generated data leads to reduced output diversity, a limitation particularly critical in reasoning tasks where diverse solution paths are essential. We present DIVE (Diversified Iterative Self-Improvement), a novel framework that addresses this challenge through two key components: Sample Pool Expansion for broader solution exploration, and Data Selection for balancing diversity and quality in preference pairs. Experiments on MATH and GSM8k datasets show that DIVE achieves a 10% to 45% relative increase in output diversity metrics while maintaining performance quality compared to vanilla ISI. Our ablation studies confirm both components' significance in achieving these improvements. Code is available at https://github.com/qinyiwei/DIVE.
O1 Replication Journey -- Part 2: Surpassing O1-preview through Simple Distillation, Big Progress or Bitter Lesson?
Nov 25, 2024This paper presents a critical examination of current approaches to replicating OpenAI's O1 model capabilities, with particular focus on the widespread but often undisclosed use of knowledge distillation techniques. While our previous work explored the fundamental technical path to O1 replication, this study reveals how simple distillation from O1's API, combined with supervised fine-tuning, can achieve superior performance on complex mathematical reasoning tasks. Through extensive experiments, we show that a base model fine-tuned on simply tens of thousands of samples O1-distilled long-thought chains outperforms O1-preview on the American Invitational Mathematics Examination (AIME) with minimal technical complexity. Moreover, our investigation extends beyond mathematical reasoning to explore the generalization capabilities of O1-distilled models across diverse tasks: hallucination, safety and open-domain QA. Notably, despite training only on mathematical problem-solving data, our models demonstrated strong generalization to open-ended QA tasks and became significantly less susceptible to sycophancy after fine-tuning. We deliberately make this finding public to promote transparency in AI research and to challenge the current trend of obscured technical claims in the field. Our work includes: (1) A detailed technical exposition of the distillation process and its effectiveness, (2) A comprehensive benchmark framework for evaluating and categorizing O1 replication attempts based on their technical transparency and reproducibility, (3) A critical discussion of the limitations and potential risks of over-relying on distillation approaches, our analysis culminates in a crucial bitter lesson: while the pursuit of more capable AI systems is important, the development of researchers grounded in first-principles thinking is paramount.
SAFETY-J: Evaluating Safety with Critique
Jul 25, 2024The deployment of Large Language Models (LLMs) in content generation raises significant safety concerns, particularly regarding the transparency and interpretability of content evaluations. Current methods, primarily focused on binary safety classifications, lack mechanisms for detailed critique, limiting their utility for model improvement and user trust. To address these limitations, we introduce SAFETY-J, a bilingual generative safety evaluator for English and Chinese with critique-based judgment. SAFETY-J utilizes a robust training dataset that includes diverse dialogues and augmented query-response pairs to assess safety across various scenarios comprehensively. We establish an automated meta-evaluation benchmark that objectively assesses the quality of critiques with minimal human intervention, facilitating scalable and continuous improvement. Additionally, SAFETY-J employs an iterative preference learning technique to dynamically refine safety assessments based on meta-evaluations and critiques. Our evaluations demonstrate that SAFETY-J provides more nuanced and accurate safety evaluations, thereby enhancing both critique quality and predictive reliability in complex content scenarios. To facilitate further research and application, we open-source SAFETY-J's training protocols, datasets, and code at \url{https://github.com/GAIR-NLP/Safety-J}.