 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SSHFD: Single Shot Human Fall Detection with Occluded Joints Resilience
Apr 03, 2020
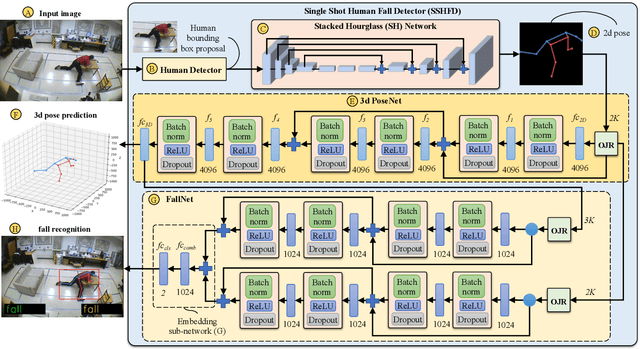
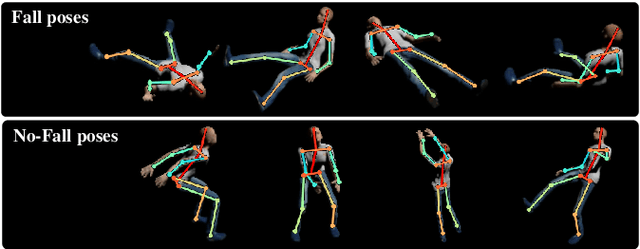
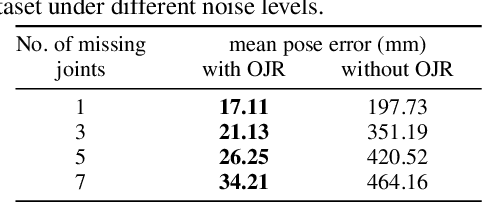

Falling can have fatal consequences for elderly people especially if the fallen person is unable to call for help due to loss of consciousness or any injury. Automatic fall detection systems can assist through prompt fall alarms and by minimizing the fear of falling when living independently at home. Existing vision-based fall detection systems lack generalization to unseen environments due to challenges such as variations in physical appearances, different camera viewpoints, occlusions, and background clutter. In this paper, we explore ways to overcome the above challenges and present Single Shot Human Fall Detector (SSHFD), a deep learning based framework for automatic fall detection from a single image. This is achieved through two key innovations. First, we present a human pose based fall representation which is invariant to appearance characteristics. Second, we present neural network models for 3d pose estimation and fall recognition which are resilient to missing joints due to occluded body parts. Experiments on public fall datasets show that our framework successfully transfers knowledge of 3d pose estimation and fall recognition learnt purely from synthetic data to unseen real-world data, showcasing its generalization capability for accurate fall detection in real-world scenarios.
HF-UNet: Learning Hierarchically Inter-Task Relevance in Multi-Task U-Net for Accurate Prostate Segmentation
May 23, 2020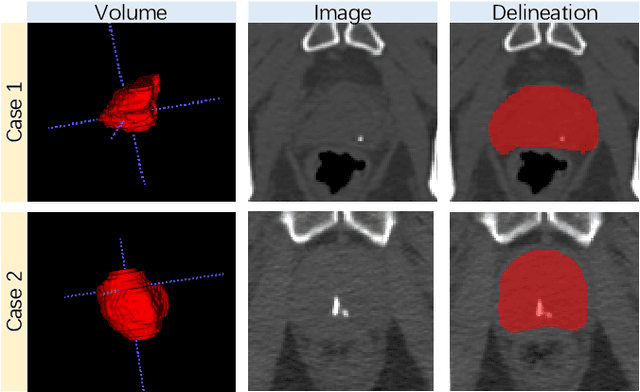
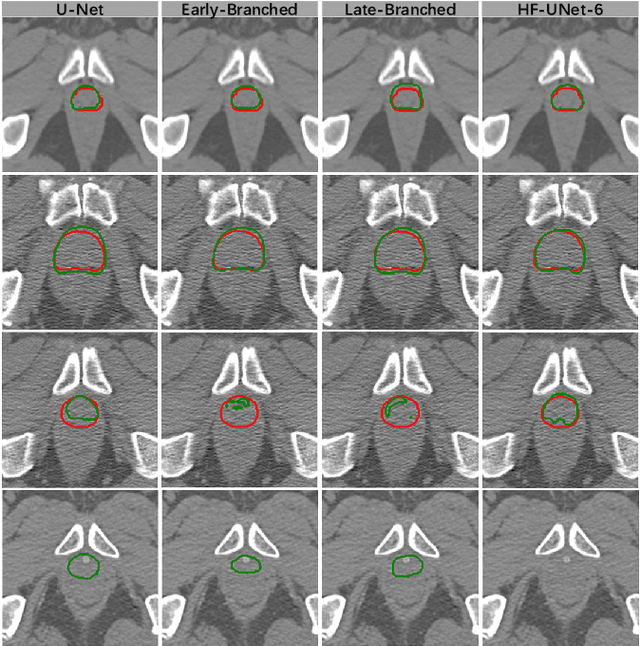
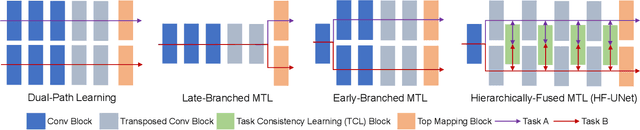
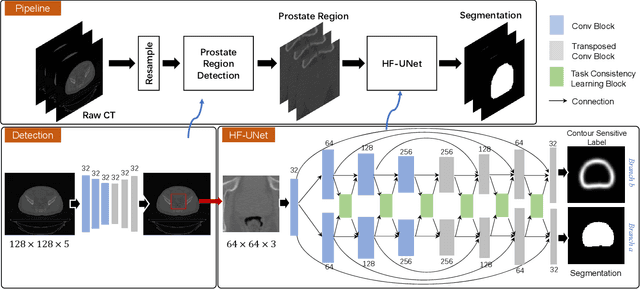
Accurate segmentation of the prostate is a key step in external beam radiation therapy treatments. In this paper, we tackle the challenging task of prostate segmentation in CT images by a two-stage network with 1) the first stage to fast localize, and 2) the second stage to accurately segment the prostate. To precisely segment the prostate in the second stage, we formulate prostate segmentation into a multi-task learning framework, which includes a main task to segment the prostate, and an auxiliary task to delineate the prostate boundary. Here, the second task is applied to provide additional guidance of unclear prostate boundary in CT images. Besides, the conventional multi-task deep networks typically share most of the parameters (i.e., feature representations) across all tasks, which may limit their data fitting ability, as the specificities of different tasks are inevitably ignored. By contrast, we solve them by a hierarchically-fused U-Net structure, namely HF-UNet. The HF-UNet has two complementary branches for two tasks, with the novel proposed attention-based task consistency learning block to communicate at each level between the two decoding branches. Therefore, HF-UNet endows the ability to learn hierarchically the shared representations for different tasks, and preserve the specificities of learned representations for different tasks simultaneously. We did extensive evaluations of the proposed method on a large planning CT image dataset, including images acquired from 339 patients. The experimental results show HF-UNet outperforms the conventional multi-task network architectures and the state-of-the-art methods.
Conditional Gaussian Distribution Learning for Open Set Recognition
Apr 17, 2020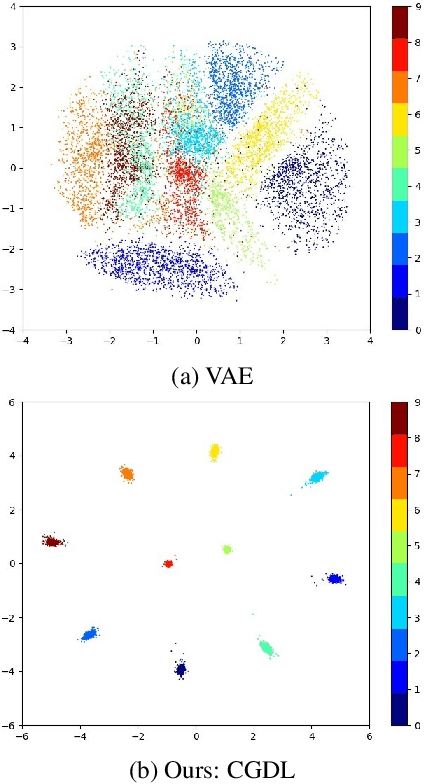
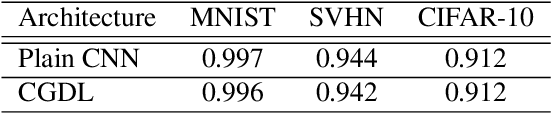
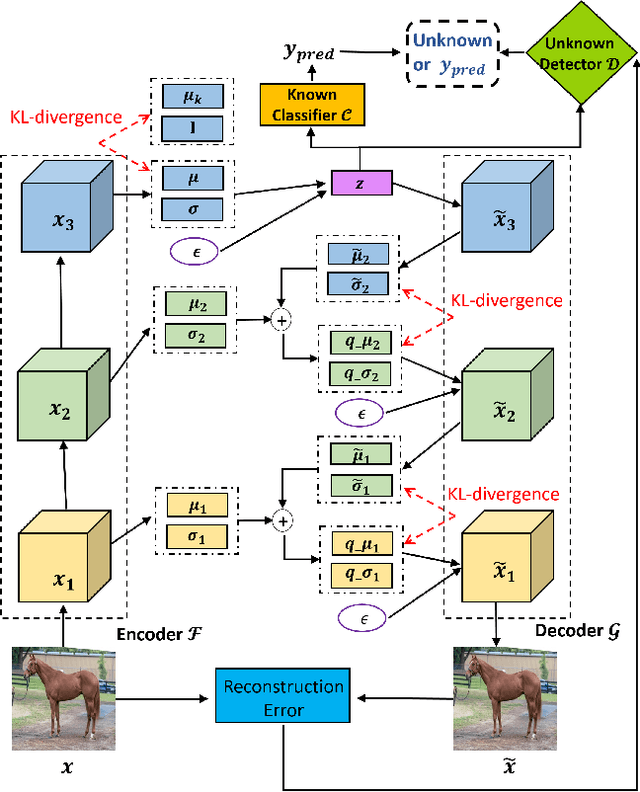

Deep neural networks have achieved state-of-the-art performance in a wide range of recognition/classification tasks. However, when applying deep learning to real-world applications, there are still multiple challenges. A typical challenge is that unknown samples may be fed into the system during the testing phase and traditional deep neural networks will wrongly recognize the unknown sample as one of the known classes. Open set recognition is a potential solution to overcome this problem, where the open set classifier should have the ability to reject unknown samples as well as maintain high classification accuracy on known classes. The variational auto-encoder (VAE) is a popular model to detect unknowns, but it cannot provide discriminative representations for known classification. In this paper, we propose a novel method, Conditional Gaussian Distribution Learning (CGDL), for open set recognition. In addition to detecting unknown samples, this method can also classify known samples by forcing different latent features to approximate different Gaussian models. Meanwhile, to avoid information hidden in the input vanishing in the middle layers, we also adopt the probabilistic ladder architecture to extract high-level abstract features. Experiments on several standard image datasets reveal that the proposed method significantly outperforms the baseline method and achieves new state-of-the-art results.
Learning to Discover Novel Visual Categories via Deep Transfer Clustering
Aug 26, 2019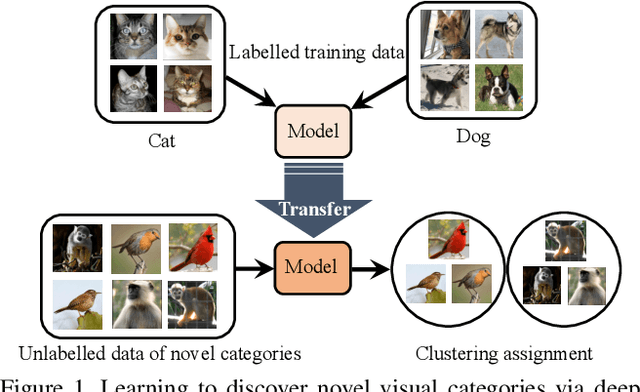
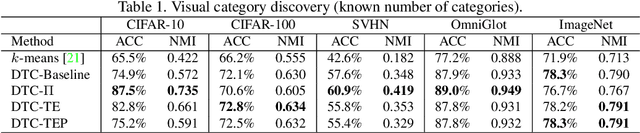

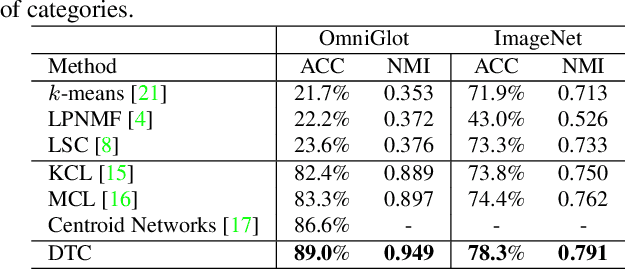
We consider the problem of discovering novel object categories in an image collection. While these images are unlabelled, we also assume prior knowledge of related but different image classes. We use such prior knowledge to reduce the ambiguity of clustering, and improve the quality of the newly discovered classes. Our contributions are twofold. The first contribution is to extend Deep Embedded Clustering to a transfer learning setting; we also improve the algorithm by introducing a representation bottleneck, temporal ensembling, and consistency. The second contribution is a method to estimate the number of classes in the unlabelled data. This also transfers knowledge from the known classes, using them as probes to diagnose different choices for the number of classes in the unlabelled subset. We thoroughly evaluate our method, substantially outperforming state-of-the-art techniques in a large number of benchmarks, including ImageNet, OmniGlot, CIFAR-100, CIFAR-10, and SVHN.
On Reducing Negative Jacobian Determinant of the Deformation Predicted by Deep Registration Networks
Jun 28, 2019

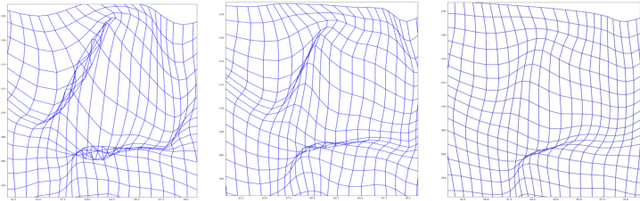
Image registration is a fundamental step in medical image analysis. Ideally, the transformation that registers one image to another should be a diffeomorphism that is both invertible and smooth. Traditional methods like geodesic shooting approach the problem via differential geometry, with theoretical guarantees that the resulting transformation will be smooth and invertible. Most previous research using unsupervised deep neural networks for registration have used a local smoothness constraint (typically, a spatial variation loss) to address the smoothness issue. These networks usually produce non-invertible transformations with ``folding'' in multiple voxel locations, indicated by a negative determinant of the Jacobian matrix of the transformation. While using a loss function that specifically penalizes the folding is a straightforward solution, this usually requires carefully tuning the regularization strength, especially when there are also other losses. In this paper we address this problem from a different angle, by investigating possible training mechanisms that will help the network avoid negative Jacobians and produce smoother deformations. We contribute two independent ideas in this direction. Both ideas greatly reduce the number of folding locations in the predicted deformation, without making changes to the hyperparameters or the architecture used in the existing baseline registration network.
Joint Wasserstein Distribution Matching
Mar 01, 2020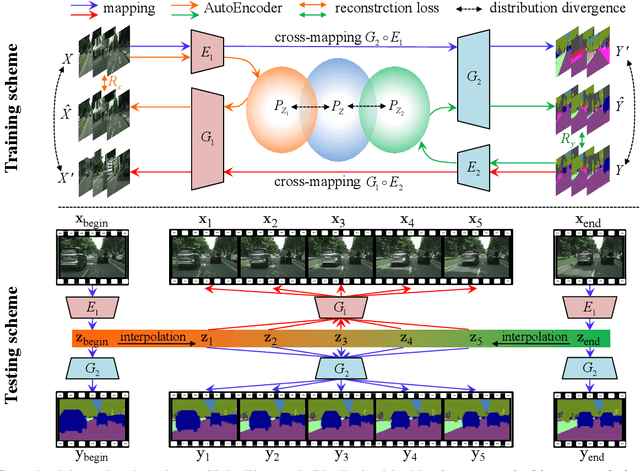
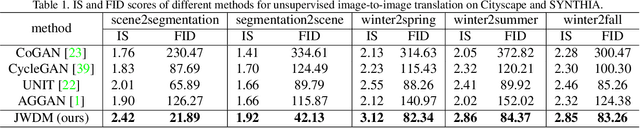
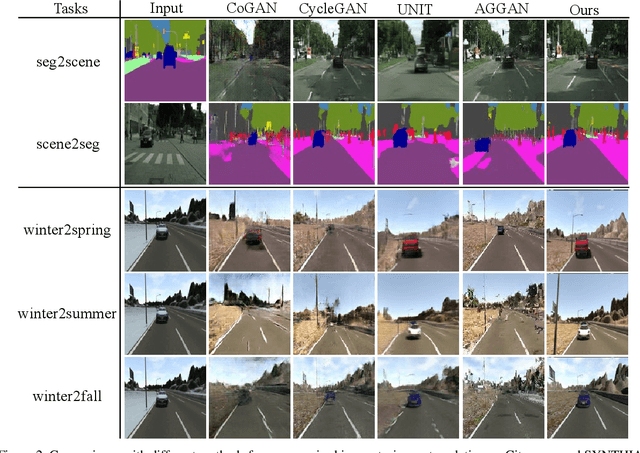

Joint distribution matching (JDM) problem, which aims to learn bidirectional mappings to match joint distributions of two domains, occurs in many machine learning and computer vision applications. This problem, however, is very difficult due to two critical challenges: (i) it is often difficult to exploit sufficient information from the joint distribution to conduct the matching; (ii) this problem is hard to formulate and optimize. In this paper, relying on optimal transport theory, we propose to address JDM problem by minimizing the Wasserstein distance of the joint distributions in two domains. However, the resultant optimization problem is still intractable. We then propose an important theorem to reduce the intractable problem into a simple optimization problem, and develop a novel method (called Joint Wasserstein Distribution Matching (JWDM)) to solve it. In the experiments, we apply our method to unsupervised image translation and cross-domain video synthesis. Both qualitative and quantitative comparisons demonstrate the superior performance of our method over several state-of-the-arts.
Monocular 3D Object Detection with Pseudo-LiDAR Point Cloud
Mar 31, 2019
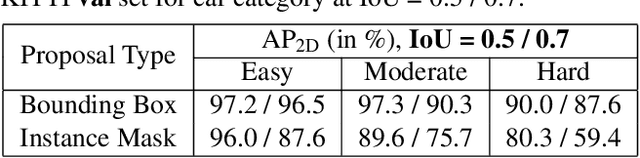
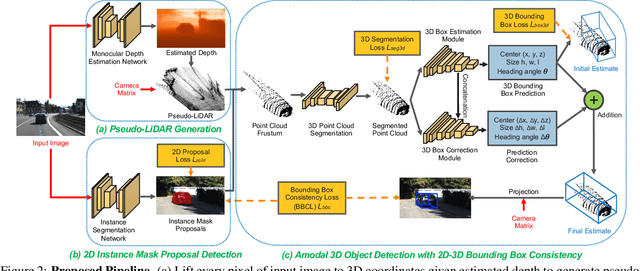

Monocular 3D scene understanding tasks, such as object size estimation, heading angle estimation and 3D localization, is challenging. Successful modern day methods for 3D scene understanding require the use of a 3D sensor such as a depth camera, a stereo camera or LiDAR. On the other hand, single image based methods have significantly worse performance, but rightly so, as there is little explicit depth information in a 2D image. In this work, we aim at bridging the performance gap between 3D sensing and 2D sensing for 3D object detection by enhancing LiDAR-based algorithms to work with single image input. Specifically, we perform monocular depth estimation and lift the input image to a point cloud representation, which we call pseudo-LiDAR point cloud. Then we can train a LiDAR-based 3D detection network with our pseudo-LiDAR end-to-end. Following the pipeline of two-stage 3D detection algorithms, we detect 2D object proposals in the input image and extract a point cloud frustum from the pseudo-LiDAR for each proposal. Then an oriented 3D bounding box is detected for each frustum. To handle the large amount of noise in the pseudo-LiDAR, we propose two innovations: (1) use a 2D-3D bounding box consistency constraint, adjusting the predicted 3D bounding box to have a high overlap with its corresponding 2D proposal after projecting onto the image; (2) use the instance mask instead of the bounding box as the representation of 2D proposals, in order to reduce the number of points not belonging to the object in the point cloud frustum. Through our evaluation on the KITTI benchmark, we achieve the top-ranked performance on both bird's eye view and 3D object detection among all monocular methods, effectively quadrupling the performance over previous state-of-the-art.
Bridging the Gap between Spatial and Spectral Domains: A Survey on Graph Neural Networks
Mar 01, 2020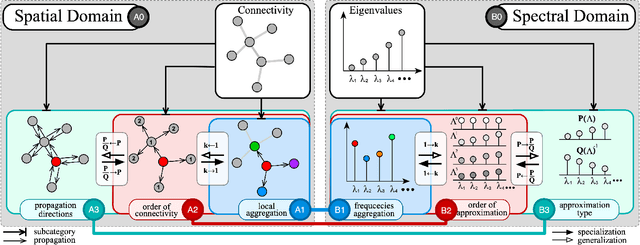
The success of deep learning has been widely recognized in many machine learning tasks during the last decades, ranging from image classification and speech recognition to natural language understanding. As an extension of deep learning, Graph neural networks (GNNs) are designed to solve the non-Euclidean problems on graph-structured data which can hardly be handled by general deep learning techniques. Existing GNNs under various mechanisms, such as random walk, PageRank, graph convolution, and heat diffusion, are designed for different types of graphs and problems, which makes it difficult to compare them directly. Previous GNN surveys focus on categorizing current models into independent groups, lacking analysis regarding their internal connection. This paper proposes a unified framework and provides a novel perspective that can widely fit existing GNNs into our framework methodologically. Specifically, we survey and categorize existing GNN models into the spatial and spectral domains, and reveal connections among subcategories in each domain. Further analysis establishes a strong link across the spatial and spectral domains.
FAMED-Net: A Fast and Accurate Multi-scale End-to-end Dehazing Network
Jun 11, 2019
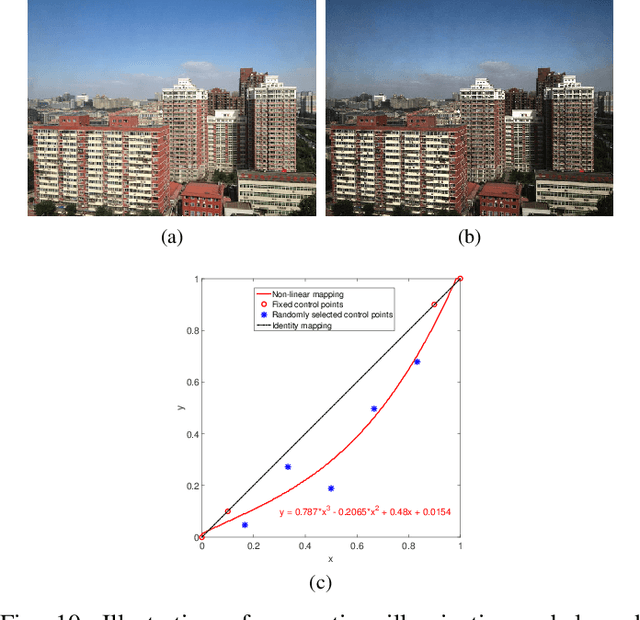

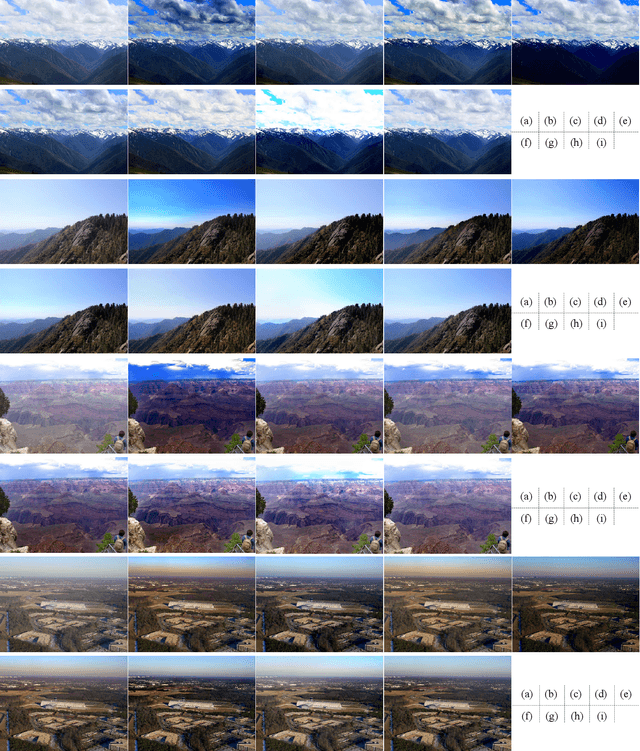
Single image dehazing is a critical image pre-processing step for subsequent high-level computer vision tasks. However, it remains challenging due to its ill-posed nature. Existing dehazing models tend to suffer from model overcomplexity and computational inefficiency or have limited representation capacity. To tackle these challenges, here we propose a fast and accurate multi-scale end-to-end dehazing network called FAMED-Net, which comprises encoders at three scales and a fusion module to efficiently and directly learn the haze-free image. Each encoder consists of cascaded and densely connected point-wise convolutional layers and pooling layers. Since no larger convolutional kernels are used and features are reused layer-by-layer, FAMED-Net is lightweight and computationally efficient. Thorough empirical studies on public synthetic datasets (including RESIDE) and real-world hazy images demonstrate the superiority of FAMED-Net over other representative state-of-the-art models with respect to model complexity, computational efficiency, restoration accuracy, and cross-set generalization. The code will be made publicly available.
MUTATT: Visual-Textual Mutual Guidance for Referring Expression Comprehension
Mar 18, 2020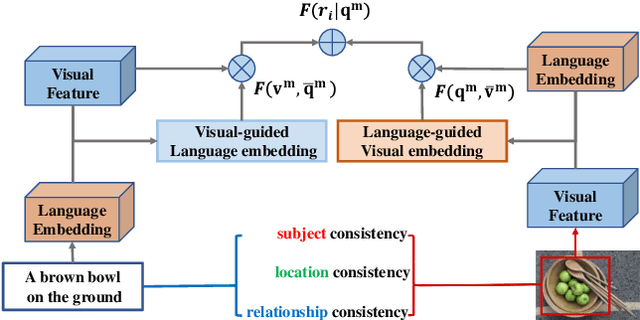
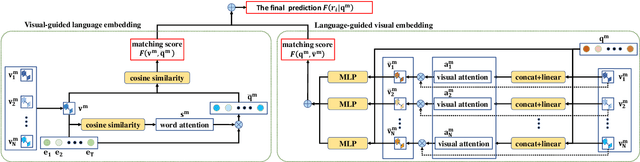
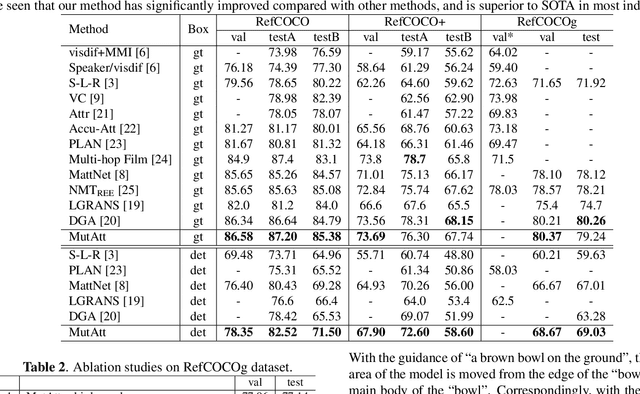
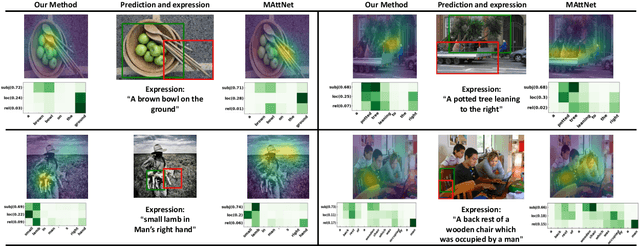
Referring expression comprehension (REC) aims to localize a text-related region in a given image by a referring expression in natural language. Existing methods focus on how to build convincing visual and language representations independently, which may significantly isolate visual and language information. In this paper, we argue that for REC the referring expression and the target region are semantically correlated and subject, location and relationship consistency exist between vision and language.On top of this, we propose a novel approach called MutAtt to construct mutual guidance between vision and language, which treat vision and language equally thus yield compact information matching. Specifically, for each module of subject, location and relationship, MutAtt builds two kinds of attention-based mutual guidance strategies. One strategy is to generate vision-guided language embedding for the sake of matching relevant visual feature. The other reversely generates language-guided visual feature to match relevant language embedding. This mutual guidance strategy can effectively guarantees the vision-language consistency in three modules. Experiments on three popular REC datasets demonstrate that the proposed approach outperforms the current state-of-the-art methods.