 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Taxonomy of Architecture Options for Foundation Model-based Agents: Analysis and Decision Model
Aug 06, 2024


The rapid advancement of AI technology has led to widespread applications of agent systems across various domains. However, the need for detailed architecture design poses significant challenges in designing and operating these systems. This paper introduces a taxonomy focused on the architectures of foundation-model-based agents, addressing critical aspects such as functional capabilities and non-functional qualities. We also discuss the operations involved in both design-time and run-time phases, providing a comprehensive view of architectural design and operational characteristics. By unifying and detailing these classifications, our taxonomy aims to improve the design of foundation-model-based agents. Additionally, the paper establishes a decision model that guides critical design and runtime decisions, offering a structured approach to enhance the development of foundation-model-based agents. Our contributions include providing a structured architecture design option and guiding the development process of foundation-model-based agents, thereby addressing current fragmentation in the field.
Agent Design Pattern Catalogue: A Collection of Architectural Patterns for Foundation Model based Agents
May 16, 2024



Foundation model-enabled generative artificial intelligence facilitates the development and implementation of agents, which can leverage distinguished reasoning and language processing capabilities to takes a proactive, autonomous role to pursue users' goals. Nevertheless, there is a lack of systematic knowledge to guide practitioners in designing the agents considering challenges of goal-seeking (including generating instrumental goals and plans), such as hallucinations inherent in foundation models, explainability of reasoning process, complex accountability, etc. To address this issue, we have performed a systematic literature review to understand the state-of-the-art foundation model-based agents and the broader ecosystem. In this paper, we present a pattern catalogue consisting of 16 architectural patterns with analyses of the context, forces, and trade-offs as the outcomes from the previous literature review. The proposed catalogue can provide holistic guidance for the effective use of patterns, and support the architecture design of foundation model-based agents by facilitating goal-seeking and plan generation.
Building the Future of Responsible AI: A Reference Architecture for Designing Large Language Model based Agents
Nov 28, 2023


Large language models (LLMs) have been widely recognised as transformative artificial generative intelligence (AGI) technologies due to their capabilities to understand and generate content, including plans with reasoning capabilities. Foundation model based agents derive their autonomy from the capabilities of foundation models, which enable them to autonomously break down a given goal into a set of manageable tasks and orchestrate task execution to meet the goal. Despite the huge efforts put into building foundation model based autonomous agents, the architecture design of the agents has not yet been systematically explored. Also, while there are significant benefits of using autonomous agents for planning and execution, there are serious considerations regarding responsible AI related software quality attributes, such as security and accountability. Therefore, this paper presents a pattern-oriented reference architecture that serves as architecture design guidance and enables responsible-AI-by-design when designing foundation model based autonomous agents. We evaluate the completeness and utility of the proposed reference architecture by mapping it to the architecture of two real-world agents.
Towards Automated and Marker-less Parkinson Disease Assessment: Predicting UPDRS Scores using Sit-stand videos
Apr 10, 2021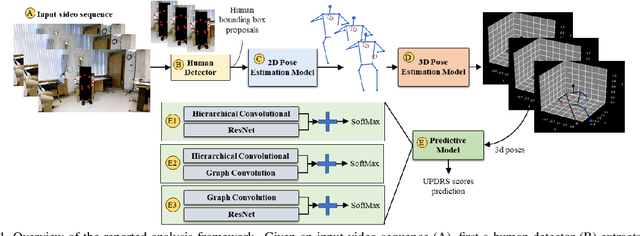
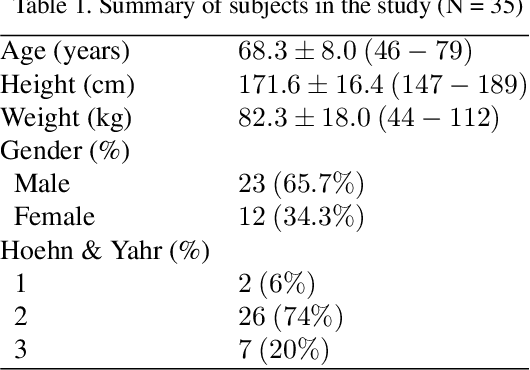
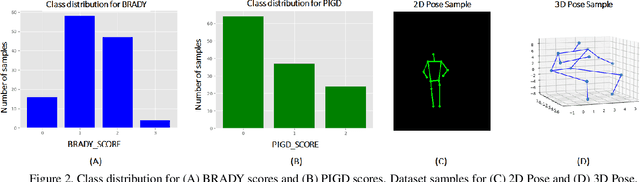
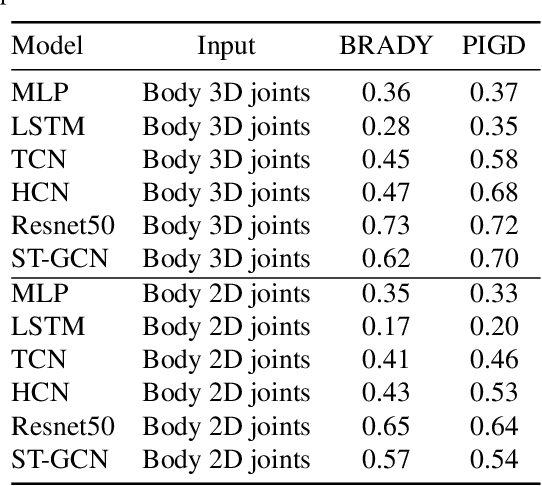
This paper presents a novel deep learning enabled, video based analysis framework for assessing the Unified Parkinsons Disease Rating Scale (UPDRS) that can be used in the clinic or at home. We report results from comparing the performance of the framework to that of trained clinicians on a population of 32 Parkinsons disease (PD) patients. In-person clinical assessments by trained neurologists are used as the ground truth for training our framework and for comparing the performance. We find that the standard sit-to-stand activity can be used to evaluate the UPDRS sub-scores of bradykinesia (BRADY) and posture instability and gait disorders (PIGD). For BRADY we find F1-scores of 0.75 using our framework compared to 0.50 for the video based rater clinicians, while for PIGD we find 0.78 for the framework and 0.45 for the video based rater clinicians. We believe our proposed framework has potential to provide clinically acceptable end points of PD in greater granularity without imposing burdens on patients and clinicians, which empowers a variety of use cases such as passive tracking of PD progression in spaces such as nursing homes, in-home self-assessment, and enhanced tele-medicine.
DeepActsNet: Spatial and Motion features from Face, Hands, and Body Combined with Convolutional and Graph Networks for Improved Action Recognition
Sep 21, 2020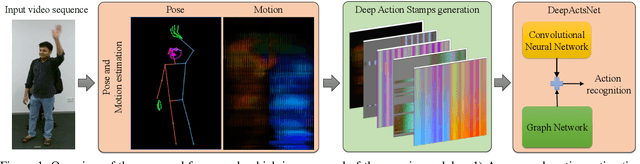
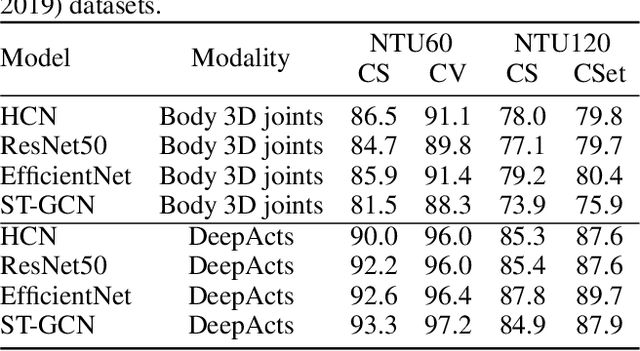

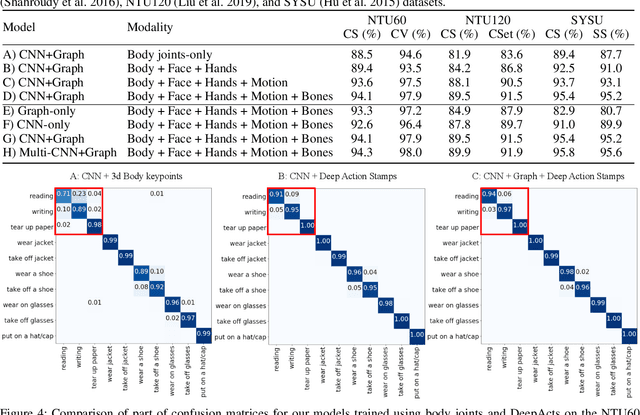
Existing action recognition methods mainly focus on joint and bone information in human body skeleton data due to its robustness to complex backgrounds and dynamic characteristics of the environments. In this paper, we combine body skeleton data with spatial and motion information from face and two hands, and present Deep Action Stamps (DeepActs), a novel data representation to encode actions from video sequences. We also present DeepActsNet, a deep learning based model with modality-specific Convolutional and Graph sub-networks for highly accurate action recognition based on Deep Action Stamps. Experiments on three challenging action recognition datasets (NTU60, NTU120, and SYSU) show that DeepActs produce considerable improvements in the recognition performance of standard convolutional and graph networks. Experiments also show that the fusion of modality-specific convolutional and structural features learnt by our DeepActsNet yields consistent improvements in action recognition accuracy over the state-of-the-art on the target datasets.
SSHFD: Single Shot Human Fall Detection with Occluded Joints Resilience
Apr 03, 2020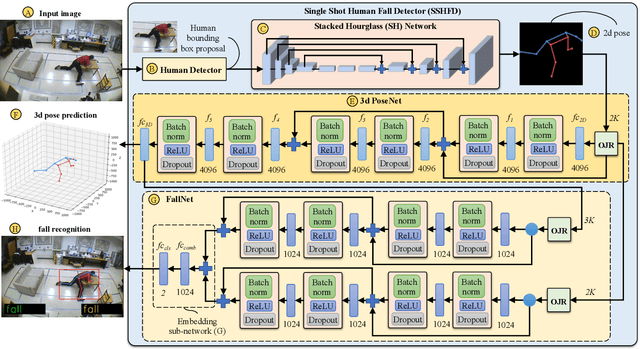
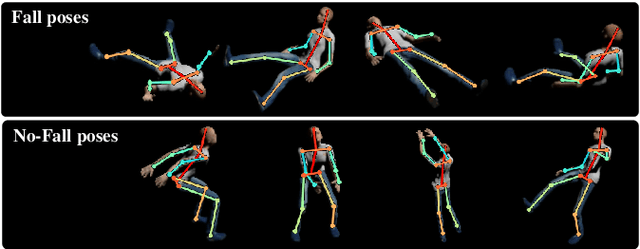
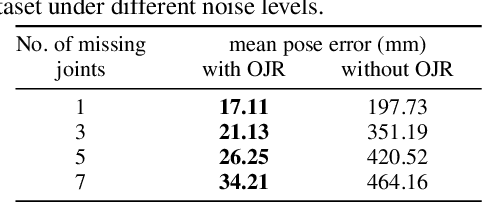

Falling can have fatal consequences for elderly people especially if the fallen person is unable to call for help due to loss of consciousness or any injury. Automatic fall detection systems can assist through prompt fall alarms and by minimizing the fear of falling when living independently at home. Existing vision-based fall detection systems lack generalization to unseen environments due to challenges such as variations in physical appearances, different camera viewpoints, occlusions, and background clutter. In this paper, we explore ways to overcome the above challenges and present Single Shot Human Fall Detector (SSHFD), a deep learning based framework for automatic fall detection from a single image. This is achieved through two key innovations. First, we present a human pose based fall representation which is invariant to appearance characteristics. Second, we present neural network models for 3d pose estimation and fall recognition which are resilient to missing joints due to occluded body parts. Experiments on public fall datasets show that our framework successfully transfers knowledge of 3d pose estimation and fall recognition learnt purely from synthetic data to unseen real-world data, showcasing its generalization capability for accurate fall detection in real-world scenarios.
Ensemble Knowledge Distillation for Learning Improved and Efficient Networks
Sep 19, 2019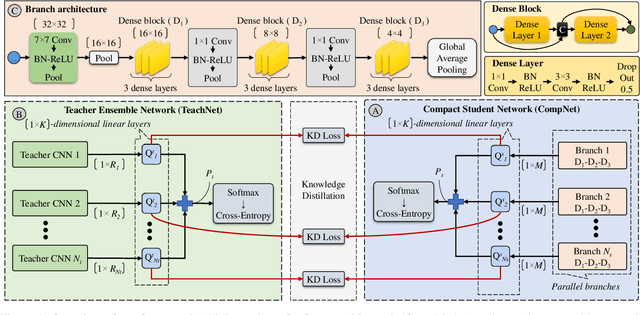
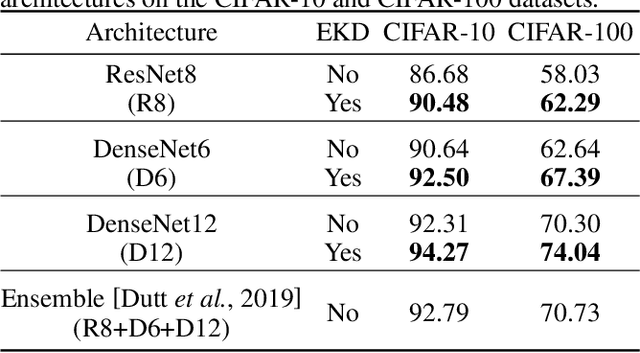
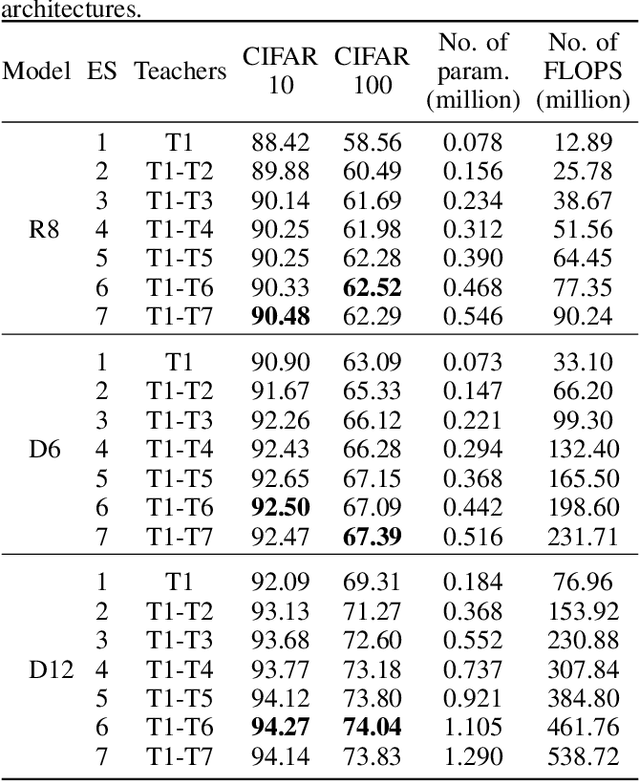
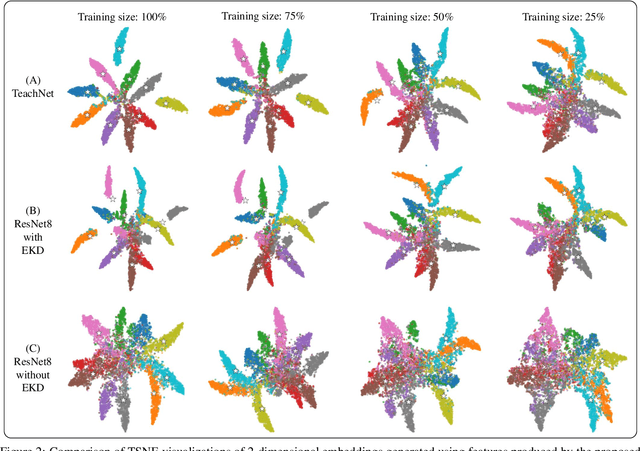
Ensemble models comprising of deep Convolutional Neural Networks (CNN) have shown significant improvements in model generalization but at the cost of large computation and memory requirements. In this paper, we present a framework for learning compact CNN models with improved classification performance and model generalization. For this, we propose a CNN architecture of a compact student model with parallel branches which are trained using ground truth labels and information from high capacity teacher networks in an ensemble learning fashion. Our framework provides two main benefits: i) Distilling knowledge from different teachers into the student network promotes heterogeneity in feature learning at different branches of the student network and enables the network to learn diverse solutions to the target problem. ii) Coupling the branches of the student network through ensembling encourages collaboration and improves the quality of the final predictions by reducing variance in the network outputs. Experiments on the well established CIFAR-10 and CIFAR-100 datasets show that our Ensemble Knowledge Distillation (EKD) improves classification accuracy and model generalization especially in situations with limited training data. Experiments also show that our EKD based compact networks outperform in terms of mean accuracy on the test datasets compared to state-of-the-art knowledge distillation based methods.
SeizureNet: A Deep Convolutional Neural Network for Accurate Seizure Type Classification and Seizure Detection
Mar 08, 2019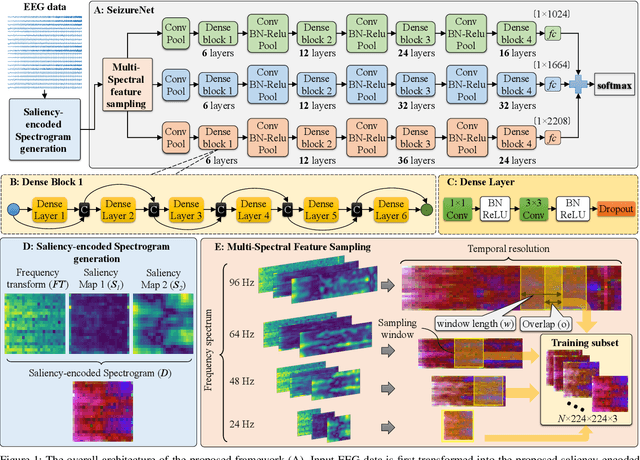

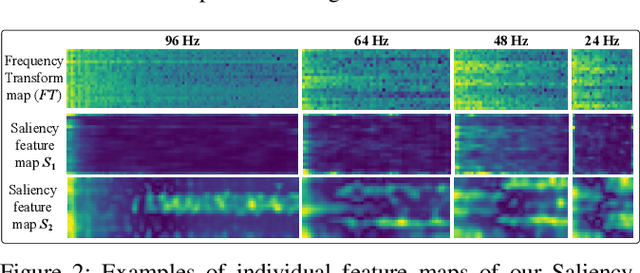
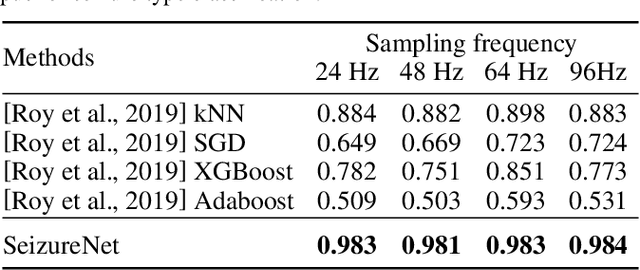
Automatic epileptic seizure analysis is important because the differentiation of neural patterns among different patients can be used to classify people with specific types of epilepsy. This could enable more efficient management of the disease. Automatic seizure type classification using clinical electroencephalograms (EEGs) is challenging due to factors such as low signal to noise ratios, signal artefacts, high variance in the seizure semiology among individual epileptic patients, and limited clinical data constraints. To overcome these challenges, in this paper, we present a deep learning based framework which uses a Convolutional Neural Network (CNN) with dense connections and learns highly robust features at different spatial and temporal resolutions of the EEG data spectrum for accurate cross-patient seizure type classification. We evaluate our framework for seizure type classification and seizure detection on the recently released TUH EEG Seizure Corpus, where our framework achieves overall weighted f 1 scores of up to 0.90 and 0.88, thereby setting new benchmarks on the dataset.
Machine Learning for Seizure Type Classification: Setting the benchmark
Feb 04, 2019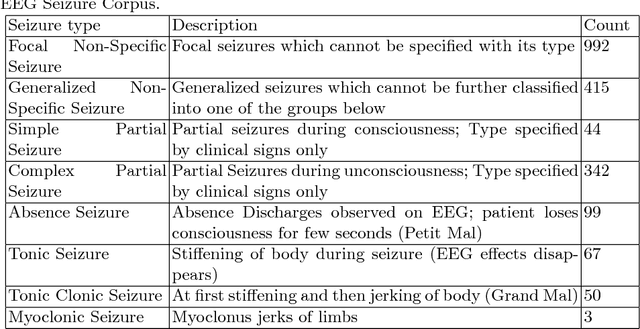
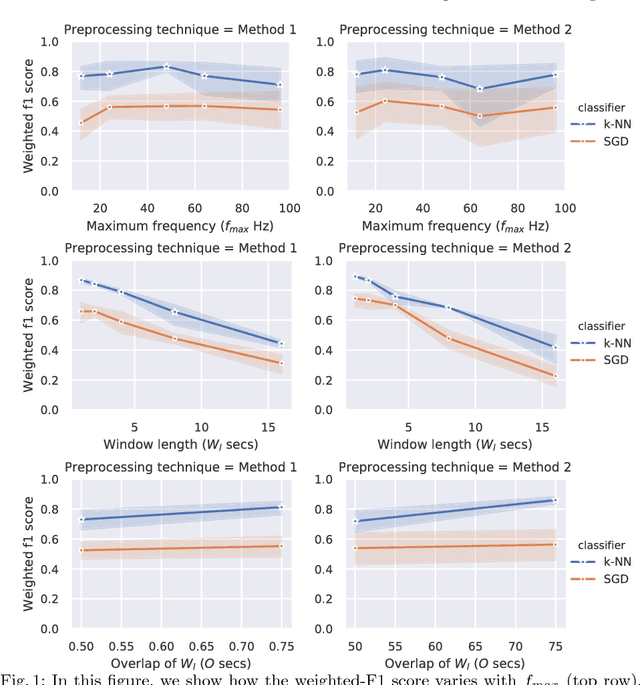
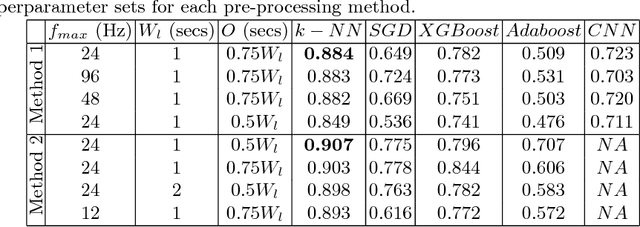
Accurate classification of seizure types plays a crucial role in the treatment and disease management of epileptic patients. Epileptic seizure type not only impacts on the choice of drugs but also on the range of activities a patient can safely engage in. With recent advances being made towards artificial intelligence enabled automatic seizure detection, the next frontier is the automatic classification of seizure types. On that note, in this paper, we undertake the first study to explore the application of machine learning algorithms for multi-class seizure type classification. We used the recently released TUH EEG Seizure Corpus and conducted a thorough search space exploration to evaluate the performance of a combination of various pre-processing techniques, machine learning algorithms, and corresponding hyperparameters on this task. We show that our algorithms can reach a weighted F1 score of up to 0.907 thereby setting the first benchmark for scalp EEG based multi-class seizure type classification.
Densely Supervised Grasp Detector (DSGD)
Oct 01, 2018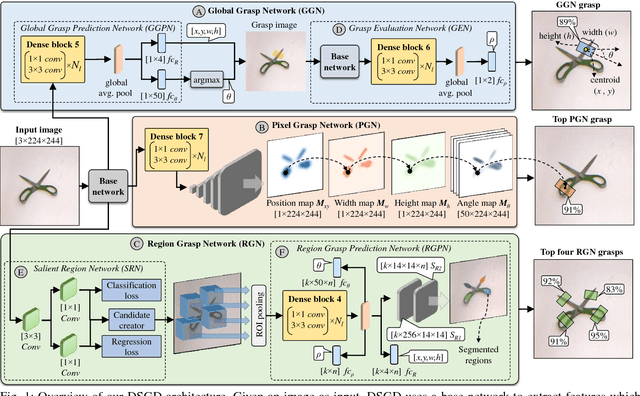
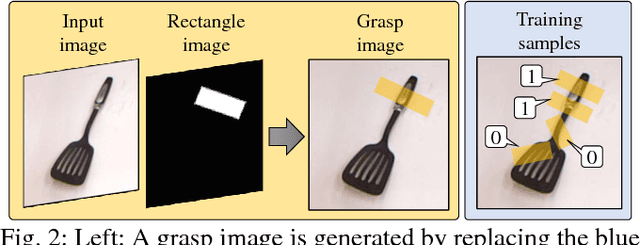
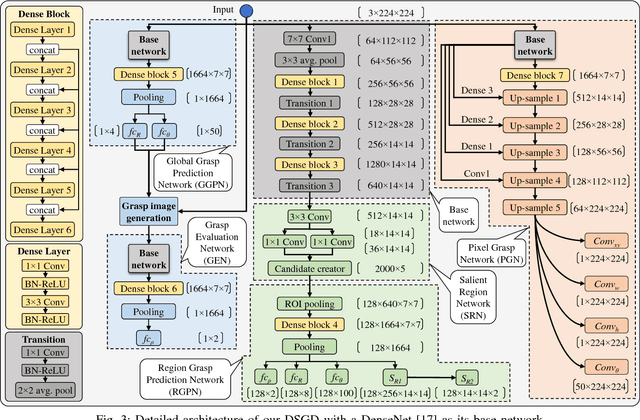

This paper presents Densely Supervised Grasp Detector (DSGD), a deep learning framework which combines CNN structures with layer-wise feature fusion and produces grasps and their confidence scores at different levels of the image hierarchy (i.e., global-, region-, and pixel-levels). Specifically, at the global-level, DSGD uses the entire image information to predict a grasp and its confidence score. At the region-level, DSGD uses a region proposal network to identify salient regions in the image and predicts a grasp for each salient region. At the pixel-level, DSGD uses a fully convolutional network and predicts a grasp and its confidence at every pixel. The grasp with the highest confidence score is selected as the output of DSGD. This selection from hierarchically generated grasp candidates overcomes limitations of the individual models. DSGD outperforms state-of-the-art methods on the Cornell grasp dataset in terms of grasp accuracy. Evaluation on a multi-object dataset and real-world robotic grasping experiments show that DSGD produces highly stable grasps on a set of unseen objects in new environments. It achieves 96% grasp detection accuracy and 90% robotic grasping success rate with real-time inference speed.