 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperiment-as-Code Labs: A Declarative Stack for AI-Driven Scientific Discovery
May 06, 2026To unleash the full potential of AI for Science, we must untether the agents from a purely digital environment. The agent's ability to control and explore in real-world labs is essential because the physical lab remains foundational to scientific discovery. While some tasks can be performed on a computer (e.g., data analysis, running simulated experiments), Eureka moments could occur at any time while operating lab instruments (e.g., when a scientist notices unexpected clues, intuition may prompt a real-time course change). Although autonomous labs are on the rise, which expose programmable APIs to control scientific instruments via software, bridging the gap between increasingly powerful AI agents and automated lab equipment requires innovation that draws insights from computer systems. We propose a new paradigm called ``Experiment-as-Code (EaC) Labs,'' where a core concept is to encode experiments as declarative configurations that can be compiled down to device-level APIs. AI agents come up with hypotheses and experiments, written as an ensemble of declarative configurations. The systems layer performs program analysis, safety checks, resource assignment, and job orchestration. Finally, programmatic experimentation occurs via actuating the device APIs. This is a general stack that is science-, lab-, and instrument-independent, representing a novel synthesis across the physical, systems, and intelligence layers to unleash the next breakthrough in AI for Science.
Ambig-IaC: Multi-level Disambiguation for Interactive Cloud Infrastructure-as-Code Synthesis
Apr 01, 2026The scale and complexity of modern cloud infrastructure have made Infrastructure-as-Code (IaC) essential for managing deployments. While large Language models (LLMs) are increasingly being used to generate IaC configurations from natural language, user requests are often underspecified. Unlike traditional code generation, IaC configurations cannot be executed cheaply or iteratively repaired, forcing the LLMs into an almost one-shot regime. We observe that ambiguity in IaC exhibits a tractable compositional structure: configurations decompose into three hierarchical axes (resources, topology, attributes) where higher-level decisions constrain lower-level ones. We propose a training-free, disagreement-driven framework that generates diverse candidate specifications, identifies structural disagreements across these axes, ranks them by informativeness, and produces targeted clarification questions that progressively narrow the configuration space. We introduce \textsc{Ambig-IaC}, a benchmark of 300 validated IaC tasks with ambiguous prompts, and an evaluation framework based on graph edit distance and embedding similarity. Our method outperforms the strongest baseline, achieving relative improvements of +18.4\% and +25.4\% on structure and attribute evaluations, respectively.
Cloud Infrastructure Management in the Age of AI Agents
Jun 13, 2025Cloud infrastructure is the cornerstone of the modern IT industry. However, managing this infrastructure effectively requires considerable manual effort from the DevOps engineering team. We make a case for developing AI agents powered by large language models (LLMs) to automate cloud infrastructure management tasks. In a preliminary study, we investigate the potential for AI agents to use different cloud/user interfaces such as software development kits (SDK), command line interfaces (CLI), Infrastructure-as-Code (IaC) platforms, and web portals. We report takeaways on their effectiveness on different management tasks, and identify research challenges and potential solutions.
SQUiD: Synthesizing Relational Databases from Unstructured Text
May 25, 2025Relational databases are central to modern data management, yet most data exists in unstructured forms like text documents. To bridge this gap, we leverage large language models (LLMs) to automatically synthesize a relational database by generating its schema and populating its tables from raw text. We introduce SQUiD, a novel neurosymbolic framework that decomposes this task into four stages, each with specialized techniques. Our experiments show that SQUiD consistently outperforms baselines across diverse datasets.
Curie: Toward Rigorous and Automated Scientific Experimentation with AI Agents
Feb 26, 2025



Scientific experimentation, a cornerstone of human progress, demands rigor in reliability, methodical control, and interpretability to yield meaningful results. Despite the growing capabilities of large language models (LLMs) in automating different aspects of the scientific process, automating rigorous experimentation remains a significant challenge. To address this gap, we propose Curie, an AI agent framework designed to embed rigor into the experimentation process through three key components: an intra-agent rigor module to enhance reliability, an inter-agent rigor module to maintain methodical control, and an experiment knowledge module to enhance interpretability. To evaluate Curie, we design a novel experimental benchmark composed of 46 questions across four computer science domains, derived from influential research papers, and widely adopted open-source projects. Compared to the strongest baseline tested, we achieve a 3.4$\times$ improvement in correctly answering experimental questions. Curie is open-sourced at https://github.com/Just-Curieous/Curie.
Adversarial Attacks and Defense for Conversation Entailment Task
May 02, 2024As the deployment of NLP systems in critical applications grows, ensuring the robustness of large language models (LLMs) against adversarial attacks becomes increasingly important. Large language models excel in various NLP tasks but remain vulnerable to low-cost adversarial attacks. Focusing on the domain of conversation entailment, where multi-turn dialogues serve as premises to verify hypotheses, we fine-tune a transformer model to accurately discern the truthfulness of these hypotheses. Adversaries manipulate hypotheses through synonym swapping, aiming to deceive the model into making incorrect predictions. To counteract these attacks, we implemented innovative fine-tuning techniques and introduced an embedding perturbation loss method to significantly bolster the model's robustness. Our findings not only emphasize the importance of defending against adversarial attacks in NLP but also highlight the real-world implications, suggesting that enhancing model robustness is critical for reliable NLP applications.
Oobleck: Resilient Distributed Training of Large Models Using Pipeline Templates
Sep 15, 2023



Oobleck enables resilient distributed training of large DNN models with guaranteed fault tolerance. It takes a planning-execution co-design approach, where it first generates a set of heterogeneous pipeline templates and instantiates at least $f+1$ logically equivalent pipeline replicas to tolerate any $f$ simultaneous failures. During execution, it relies on already-replicated model states across the replicas to provide fast recovery. Oobleck provably guarantees that some combination of the initially created pipeline templates can be used to cover all available resources after $f$ or fewer simultaneous failures, thereby avoiding resource idling at all times. Evaluation on large DNN models with billions of parameters shows that Oobleck provides consistently high throughput, and it outperforms state-of-the-art fault tolerance solutions like Bamboo and Varuna by up to $13.9x$.
Chasing Low-Carbon Electricity for Practical and Sustainable DNN Training
Mar 04, 2023

Deep learning has experienced significant growth in recent years, resulting in increased energy consumption and carbon emission from the use of GPUs for training deep neural networks (DNNs). Answering the call for sustainability, conventional solutions have attempted to move training jobs to locations or time frames with lower carbon intensity. However, moving jobs to other locations may not always be feasible due to large dataset sizes or data regulations. Moreover, postponing training can negatively impact application service quality because the DNNs backing the service are not updated in a timely fashion. In this work, we present a practical solution that reduces the carbon footprint of DNN training without migrating or postponing jobs. Specifically, our solution observes real-time carbon intensity shifts during training and controls the energy consumption of GPUs, thereby reducing carbon footprint while maintaining training performance. Furthermore, in order to proactively adapt to shifting carbon intensity, we propose a lightweight machine learning algorithm that predicts the carbon intensity of the upcoming time frame. Our solution, Chase, reduces the total carbon footprint of training ResNet-50 on ImageNet by 13.6% while only increasing training time by 2.5%.
SLRNet: Semi-Supervised Semantic Segmentation Via Label Reuse for Human Decomposition Images
Feb 24, 2022



Semantic segmentation is a challenging computer vision task demanding a significant amount of pixel-level annotated data. Producing such data is a time-consuming and costly process, especially for domains with a scarcity of experts, such as medicine or forensic anthropology. While numerous semi-supervised approaches have been developed to make the most from the limited labeled data and ample amount of unlabeled data, domain-specific real-world datasets often have characteristics that both reduce the effectiveness of off-the-shelf state-of-the-art methods and also provide opportunities to create new methods that exploit these characteristics. We propose and evaluate a semi-supervised method that reuses available labels for unlabeled images of a dataset by exploiting existing similarities, while dynamically weighting the impact of these reused labels in the training process. We evaluate our method on a large dataset of human decomposition images and find that our method, while conceptually simple, outperforms state-of-the-art consistency and pseudo-labeling-based methods for the segmentation of this dataset. This paper includes graphic content of human decomposition.
Pseudo Pixel-level Labeling for Images with Evolving Content
May 20, 2021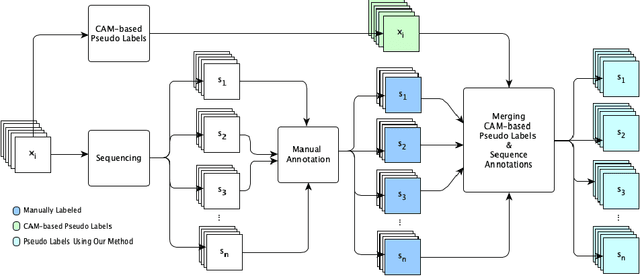
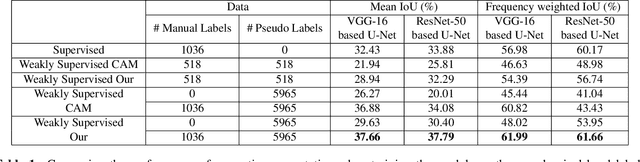

Annotating images for semantic segmentation requires intense manual labor and is a time-consuming and expensive task especially for domains with a scarcity of experts, such as Forensic Anthropology. We leverage the evolving nature of images depicting the decay process in human decomposition data to design a simple yet effective pseudo-pixel-level label generation technique to reduce the amount of effort for manual annotation of such images. We first identify sequences of images with a minimum variation that are most suitable to share the same or similar annotation using an unsupervised approach. Given one user-annotated image in each sequence, we propagate the annotation to the remaining images in the sequence by merging it with annotations produced by a state-of-the-art CAM-based pseudo label generation technique. To evaluate the quality of our pseudo-pixel-level labels, we train two semantic segmentation models with VGG and ResNet backbones on images labeled using our pseudo labeling method and those of a state-of-the-art method. The results indicate that using our pseudo-labels instead of those generated using the state-of-the-art method in the training process improves the mean-IoU and the frequency-weighted-IoU of the VGG and ResNet-based semantic segmentation models by 3.36%, 2.58%, 10.39%, and 12.91% respectively.