 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Right Losses for the Right Gains: Improving the Semantic Consistency of Deep Text-to-Image Generation with Distribution-Sensitive Losses
Dec 18, 2023
One of the major challenges in training deep neural networks for text-to-image generation is the significant linguistic discrepancy between ground-truth captions of each image in most popular datasets. The large difference in the choice of words in such captions results in synthesizing images that are semantically dissimilar to each other and to their ground-truth counterparts. Moreover, existing models either fail to generate the fine-grained details of the image or require a huge number of parameters that renders them inefficient for text-to-image synthesis. To fill this gap in the literature, we propose using the contrastive learning approach with a novel combination of two loss functions: fake-to-fake loss to increase the semantic consistency between generated images of the same caption, and fake-to-real loss to reduce the gap between the distributions of real images and fake ones. We test this approach on two baseline models: SSAGAN and AttnGAN (with style blocks to enhance the fine-grained details of the images.) Results show that our approach improves the qualitative results on AttnGAN with style blocks on the CUB dataset. Additionally, on the challenging COCO dataset, our approach achieves competitive results against the state-of-the-art Lafite model, outperforms the FID score of SSAGAN model by 44.
Aligned with LLM: a new multi-modal training paradigm for encoding fMRI activity in visual cortex
Jan 08, 2024Recently, there has been a surge in the popularity of pre trained large language models (LLMs) (such as GPT-4), sweeping across the entire Natural Language Processing (NLP) and Computer Vision (CV) communities. These LLMs have demonstrated advanced multi-modal understanding capabilities and showcased strong performance across various benchmarks. The LLM has started to embody traits of artificial general intelligence, which holds vital guidance for enhancing brain-like characteristics within visual encoding models. Hence, This paper proposes a new multi-modal training paradigm, aligning with LLM, for encoding fMRI activity in visual cortex. Based on this paradigm, we trained an encoding model in fMRI data named the LLM-Visual Encoding Model (LLM-VEM). Specifically, we utilize LLM (miniGPT4) to generate descriptive text for all stimulus images, forming a high-quality textual description set. Moreover, we use the pre-trained text encoder (CLIP) to process these detailed descriptions, obtaining the text embedding features. Next, we use the contrast loss function to minimize the distance between the image embedding features and the text embedding features to complete the alignment operation of the stimulus image and text information. With the assistance of the pre-trained LLM, this alignment process facilitates better learning of the visual encoding model, resulting in higher precision. The final experimental results indicate that our training paradigm has significantly aided in enhancing the performance of the visual encoding model.
A Compact and Semantic Latent Space for Disentangled and Controllable Image Editing
Dec 13, 2023Recent advances in the field of generative models and in particular generative adversarial networks (GANs) have lead to substantial progress for controlled image editing, especially compared with the pre-deep learning era. Despite their powerful ability to apply realistic modifications to an image, these methods often lack properties like disentanglement (the capacity to edit attributes independently). In this paper, we propose an auto-encoder which re-organizes the latent space of StyleGAN, so that each attribute which we wish to edit corresponds to an axis of the new latent space, and furthermore that the latent axes are decorrelated, encouraging disentanglement. We work in a compressed version of the latent space, using Principal Component Analysis, meaning that the parameter complexity of our autoencoder is reduced, leading to short training times ($\sim$ 45 mins). Qualitative and quantitative results demonstrate the editing capabilities of our approach, with greater disentanglement than competing methods, while maintaining fidelity to the original image with respect to identity. Our autoencoder architecture simple and straightforward, facilitating implementation.
Customize-It-3D: High-Quality 3D Creation from A Single Image Using Subject-Specific Knowledge Prior
Dec 15, 2023In this paper, we present a novel two-stage approach that fully utilizes the information provided by the reference image to establish a customized knowledge prior for image-to-3D generation. While previous approaches primarily rely on a general diffusion prior, which struggles to yield consistent results with the reference image, we propose a subject-specific and multi-modal diffusion model. This model not only aids NeRF optimization by considering the shading mode for improved geometry but also enhances texture from the coarse results to achieve superior refinement. Both aspects contribute to faithfully aligning the 3D content with the subject. Extensive experiments showcase the superiority of our method, Customize-It-3D, outperforming previous works by a substantial margin. It produces faithful 360-degree reconstructions with impressive visual quality, making it well-suited for various applications, including text-to-3D creation.
MCANet: Medical Image Segmentation with Multi-Scale Cross-Axis Attention
Dec 20, 2023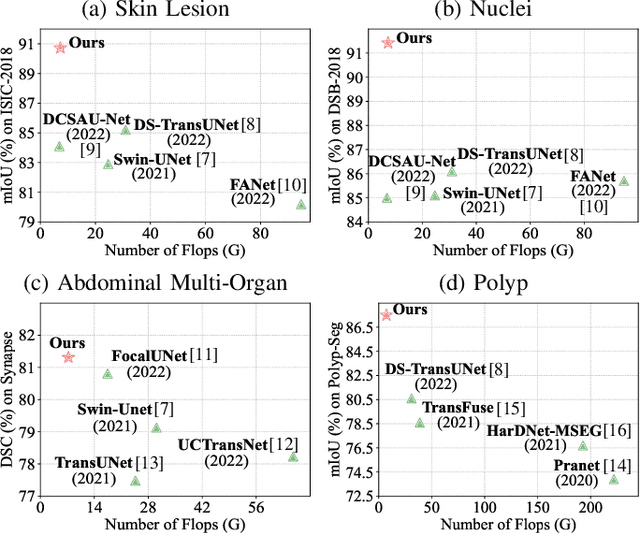
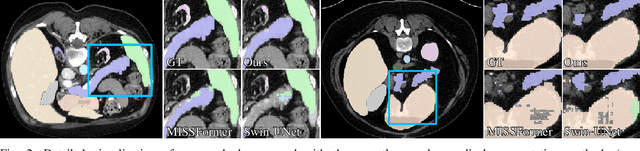
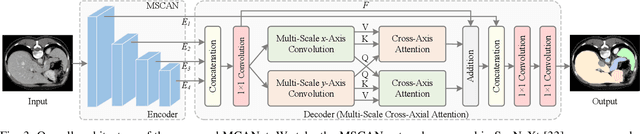
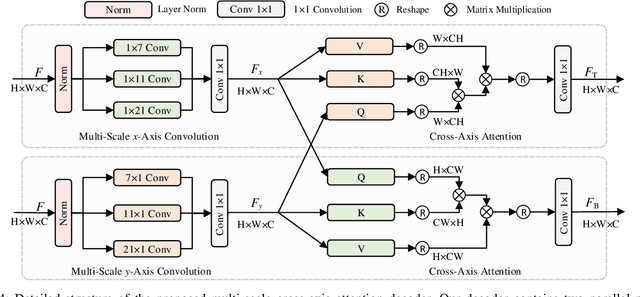
Efficiently capturing multi-scale information and building long-range dependencies among pixels are essential for medical image segmentation because of the various sizes and shapes of the lesion regions or organs. In this paper, we present Multi-scale Cross-axis Attention (MCA) to solve the above challenging issues based on the efficient axial attention. Instead of simply connecting axial attention along the horizontal and vertical directions sequentially, we propose to calculate dual cross attentions between two parallel axial attentions to capture global information better. To process the significant variations of lesion regions or organs in individual sizes and shapes, we also use multiple convolutions of strip-shape kernels with different kernel sizes in each axial attention path to improve the efficiency of the proposed MCA in encoding spatial information. We build the proposed MCA upon the MSCAN backbone, yielding our network, termed MCANet. Our MCANet with only 4M+ parameters performs even better than most previous works with heavy backbones (e.g., Swin Transformer) on four challenging tasks, including skin lesion segmentation, nuclei segmentation, abdominal multi-organ segmentation, and polyp segmentation. Code is available at https://github.com/haoshao-nku/medical_seg.
Bring Metric Functions into Diffusion Models
Jan 04, 2024We introduce a Cascaded Diffusion Model (Cas-DM) that improves a Denoising Diffusion Probabilistic Model (DDPM) by effectively incorporating additional metric functions in training. Metric functions such as the LPIPS loss have been proven highly effective in consistency models derived from the score matching. However, for the diffusion counterparts, the methodology and efficacy of adding extra metric functions remain unclear. One major challenge is the mismatch between the noise predicted by a DDPM at each step and the desired clean image that the metric function works well on. To address this problem, we propose Cas-DM, a network architecture that cascades two network modules to effectively apply metric functions to the diffusion model training. The first module, similar to a standard DDPM, learns to predict the added noise and is unaffected by the metric function. The second cascaded module learns to predict the clean image, thereby facilitating the metric function computation. Experiment results show that the proposed diffusion model backbone enables the effective use of the LPIPS loss, leading to state-of-the-art image quality (FID, sFID, IS) on various established benchmarks.
SmartEdit: Exploring Complex Instruction-based Image Editing with Multimodal Large Language Models
Dec 11, 2023Current instruction-based editing methods, such as InstructPix2Pix, often fail to produce satisfactory results in complex scenarios due to their dependence on the simple CLIP text encoder in diffusion models. To rectify this, this paper introduces SmartEdit, a novel approach to instruction-based image editing that leverages Multimodal Large Language Models (MLLMs) to enhance their understanding and reasoning capabilities. However, direct integration of these elements still faces challenges in situations requiring complex reasoning. To mitigate this, we propose a Bidirectional Interaction Module that enables comprehensive bidirectional information interactions between the input image and the MLLM output. During training, we initially incorporate perception data to boost the perception and understanding capabilities of diffusion models. Subsequently, we demonstrate that a small amount of complex instruction editing data can effectively stimulate SmartEdit's editing capabilities for more complex instructions. We further construct a new evaluation dataset, Reason-Edit, specifically tailored for complex instruction-based image editing. Both quantitative and qualitative results on this evaluation dataset indicate that our SmartEdit surpasses previous methods, paving the way for the practical application of complex instruction-based image editing.
FineControlNet: Fine-level Text Control for Image Generation with Spatially Aligned Text Control Injection
Dec 14, 2023Recently introduced ControlNet has the ability to steer the text-driven image generation process with geometric input such as human 2D pose, or edge features. While ControlNet provides control over the geometric form of the instances in the generated image, it lacks the capability to dictate the visual appearance of each instance. We present FineControlNet to provide fine control over each instance's appearance while maintaining the precise pose control capability. Specifically, we develop and demonstrate FineControlNet with geometric control via human pose images and appearance control via instance-level text prompts. The spatial alignment of instance-specific text prompts and 2D poses in latent space enables the fine control capabilities of FineControlNet. We evaluate the performance of FineControlNet with rigorous comparison against state-of-the-art pose-conditioned text-to-image diffusion models. FineControlNet achieves superior performance in generating images that follow the user-provided instance-specific text prompts and poses compared with existing methods. Project webpage: https://samsunglabs.github.io/FineControlNet-project-page
Knowledge-Aware Artifact Image Synthesis with LLM-Enhanced Prompting and Multi-Source Supervision
Dec 13, 2023Ancient artifacts are an important medium for cultural preservation and restoration. However, many physical copies of artifacts are either damaged or lost, leaving a blank space in archaeological and historical studies that calls for artifact image generation techniques. Despite the significant advancements in open-domain text-to-image synthesis, existing approaches fail to capture the important domain knowledge presented in the textual description, resulting in errors in recreated images such as incorrect shapes and patterns. In this paper, we propose a novel knowledge-aware artifact image synthesis approach that brings lost historical objects accurately into their visual forms. We use a pretrained diffusion model as backbone and introduce three key techniques to enhance the text-to-image generation framework: 1) we construct prompts with explicit archaeological knowledge elicited from large language models (LLMs); 2) we incorporate additional textual guidance to correlated historical expertise in a contrastive manner; 3) we introduce further visual-semantic constraints on edge and perceptual features that enable our model to learn more intricate visual details of the artifacts. Compared to existing approaches, our proposed model produces higher-quality artifact images that align better with the implicit details and historical knowledge contained within written documents, thus achieving significant improvements across automatic metrics and in human evaluation. Our code and data are available at https://github.com/danielwusg/artifact_diffusion.
BA-SAM: Scalable Bias-Mode Attention Mask for Segment Anything Model
Jan 04, 2024In this paper, we address the challenge of image resolution variation for the Segment Anything Model (SAM). SAM, known for its zero-shot generalizability, exhibits a performance degradation when faced with datasets with varying image sizes. Previous approaches tend to resize the image to a fixed size or adopt structure modifications, hindering the preservation of SAM's rich prior knowledge. Besides, such task-specific tuning necessitates a complete retraining of the model, which is cost-expensive and unacceptable for deployment in the downstream tasks. In this paper, we reformulate this issue as a length extrapolation problem, where token sequence length varies while maintaining a consistent patch size for images of different sizes. To this end, we propose Scalable Bias-Mode Attention Mask (BA-SAM) to enhance SAM's adaptability to varying image resolutions while eliminating the need for structure modifications. Firstly, we introduce a new scaling factor to ensure consistent magnitude in the attention layer's dot product values when the token sequence length changes. Secondly, we present a bias-mode attention mask that allows each token to prioritize neighboring information, mitigating the impact of untrained distant information. Our BA-SAM demonstrates efficacy in two scenarios: zero-shot and fine-tuning. Extensive evaluation on diverse datasets, including DIS5K, DUTS, ISIC, COD10K, and COCO, reveals its ability to significantly mitigate performance degradation in the zero-shot setting and achieve state-of-the-art performance with minimal fine-tuning. Furthermore, we propose a generalized model and benchmark, showcasing BA-SAM's generalizability across all four datasets simultaneously.