 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-Constrained UAV-Based Weed Detection for Site-Specific Management on Edge Devices
Apr 25, 2026Weeds compete with crops for light, water, and nutrients, reducing yield and crop quality. Efficient weed detection is essential for site-specific weed management (SSWM). Although deep learning models have been deployed on UAV-based edge systems, a systematic understanding of how different model architectures perform under real-world resource constraints is still lacking. To address this gap, this study proposes a deployment-oriented framework for real-time UAV-based weed detection on resource-constrained edge platforms. The framework integrates UAV data acquisition, model development, and on-device inference, with a focus on balancing detection accuracy and computational efficiency. A diverse set of state-of-the-art object detection models is evaluated, including convolution-based YOLO models (v8-v12) and transformer-based RT-DETR models (v1-v2). Experiments on three edge devices (Jetson Orin Nano, Jetson AGX Xavier, and Jetson AGX Orin) demonstrate clear trade-offs between accuracy and inference latency across models and hardware configurations. Results show that high-capacity models achieve up to 86.9% mAP50 but suffer from high latency, limiting real-time deployment. In contrast, lightweight models achieve 66%-71% mAP50 with significantly lower latency, enabling real-time performance. Among all models, RT-DETRv2-R50-M achieves competitive accuracy (79% mAP50) with improved efficiency, while YOLOv10n provides the fastest inference speed. YOLOv11s and RT-DETRv2-R50-M offer the best balance between accuracy and speed, making them strong candidates for real-time UAV deployment.
Interpretable and Sparse Linear Attention with Decoupled Membership-Subspace Modeling via MCR2 Objective
Jan 20, 2026Maximal Coding Rate Reduction (MCR2)-driven white-box transformer, grounded in structured representation learning, unifies interpretability and efficiency, providing a reliable white-box solution for visual modeling. However, in existing designs, tight coupling between "membership matrix" and "subspace matrix U" in MCR2 causes redundant coding under incorrect token projection. To this end, we decouple the functional relationship between the "membership matrix" and "subspaces U" in the MCR2 objective and derive an interpretable sparse linear attention operator from unrolled gradient descent of the optimized objective. Specifically, we propose to directly learn the membership matrix from inputs and subsequently derive sparse subspaces from the fullspace S. Consequently, gradient unrolling of the optimized MCR2 objective yields an interpretable sparse linear attention operator: Decoupled Membership-Subspace Attention (DMSA). Experimental results on visual tasks show that simply replacing the attention module in Token Statistics Transformer (ToST) with DMSA (we refer to as DMST) not only achieves a faster coding reduction rate but also outperforms ToST by 1.08%-1.45% in top-1 accuracy on the ImageNet-1K dataset. Compared with vanilla Transformer architectures, DMST exhibits significantly higher computational efficiency and interpretability.
A one-step generation model with a Single-Layer Transformer: Layer number re-distillation of FreeFlow
Jan 14, 2026Currently, Flow matching methods aim to compress the iterative generation process of diffusion models into a few or even a single step, with MeanFlow and FreeFlow being representative achievements of one-step generation based on Ordinary Differential Equations (ODEs). We observe that the 28-layer Transformer architecture of FreeFlow can be characterized as an Euler discretization scheme for an ODE along the depth axis, where the layer index serves as the discrete time step. Therefore, we distill the number of layers of the FreeFlow model, following the same derivation logic as FreeFlow, and propose SLT (Single-Layer Transformer), which uses a single shared DiT block to approximate the depth-wise feature evolution of the 28-layer teacher. During training, it matches the teacher's intermediate features at several depth patches, fuses those patch-level representations, and simultaneously aligns the teacher's final velocity prediction. Through distillation training, we compress the 28 independent Transformer Blocks of the teacher model DiT-XL/2 into a single Transformer Block, reducing the parameter count from 675M to 4.3M. Furthermore, leveraging its minimal parameters and rapid sampling speed, SLT can screen more candidate points in the noise space within the same timeframe, thereby selecting higher-quality initial points for the teacher model FreeFlow and ultimately enhancing the quality of generated images. Experimental results demonstrate that within a time budget comparable to two random samplings of the teacher model, our method performs over 100 noise screenings and produces a high-quality sample through the teacher model using the selected points. Quality fluctuations caused by low-quality initial noise under a limited number of FreeFlow sampling calls are effectively avoided, substantially improving the stability and average generation quality of one-step generation.
MFI-ResNet: Efficient ResNet Architecture Optimization via MeanFlow Compression and Selective Incubation
Nov 16, 2025ResNet has achieved tremendous success in computer vision through its residual connection mechanism. ResNet can be viewed as a discretized form of ordinary differential equations (ODEs). From this perspective, the multiple residual blocks within a single ResNet stage essentially perform multi-step discrete iterations of the feature transformation for that stage. The recently proposed flow matching model, MeanFlow, enables one-step generative modeling by learning the mean velocity field to transform distributions. Inspired by this, we propose MeanFlow-Incubated ResNet (MFI-ResNet), which employs a compression-expansion strategy to jointly improve parameter efficiency and discriminative performance. In the compression phase, we simplify the multi-layer structure within each ResNet stage to one or two MeanFlow modules to construct a lightweight meta model. In the expansion phase, we apply a selective incubation strategy to the first three stages, expanding them to match the residual block configuration of the baseline ResNet model, while keeping the last stage in MeanFlow form, and fine-tune the incubated model. Experimental results show that on CIFAR-10 and CIFAR-100 datasets, MFI-ResNet achieves remarkable parameter efficiency, reducing parameters by 46.28% and 45.59% compared to ResNet-50, while still improving accuracy by 0.23% and 0.17%, respectively. This demonstrates that generative flow-fields can effectively characterize the feature transformation process in ResNet, providing a new perspective for understanding the relationship between generative modeling and discriminative learning.
Signal Adversarial Examples Generation for Signal Detection Network via White-Box Attack
Oct 02, 2024



With the development and application of deep learning in signal detection tasks, the vulnerability of neural networks to adversarial attacks has also become a security threat to signal detection networks. This paper defines a signal adversarial examples generation model for signal detection network from the perspective of adding perturbations to the signal. The model uses the inequality relationship of L2-norm between time domain and time-frequency domain to constrain the energy of signal perturbations. Building upon this model, we propose a method for generating signal adversarial examples utilizing gradient-based attacks and Short-Time Fourier Transform. The experimental results show that under the constraint of signal perturbation energy ratio less than 3%, our adversarial attack resulted in a 28.1% reduction in the mean Average Precision (mAP), a 24.7% reduction in recall, and a 30.4% reduction in precision of the signal detection network. Compared to random noise perturbation of equivalent intensity, our adversarial attack demonstrates a significant attack effect.
Aligned with LLM: a new multi-modal training paradigm for encoding fMRI activity in visual cortex
Jan 08, 2024Recently, there has been a surge in the popularity of pre trained large language models (LLMs) (such as GPT-4), sweeping across the entire Natural Language Processing (NLP) and Computer Vision (CV) communities. These LLMs have demonstrated advanced multi-modal understanding capabilities and showcased strong performance across various benchmarks. The LLM has started to embody traits of artificial general intelligence, which holds vital guidance for enhancing brain-like characteristics within visual encoding models. Hence, This paper proposes a new multi-modal training paradigm, aligning with LLM, for encoding fMRI activity in visual cortex. Based on this paradigm, we trained an encoding model in fMRI data named the LLM-Visual Encoding Model (LLM-VEM). Specifically, we utilize LLM (miniGPT4) to generate descriptive text for all stimulus images, forming a high-quality textual description set. Moreover, we use the pre-trained text encoder (CLIP) to process these detailed descriptions, obtaining the text embedding features. Next, we use the contrast loss function to minimize the distance between the image embedding features and the text embedding features to complete the alignment operation of the stimulus image and text information. With the assistance of the pre-trained LLM, this alignment process facilitates better learning of the visual encoding model, resulting in higher precision. The final experimental results indicate that our training paradigm has significantly aided in enhancing the performance of the visual encoding model.
A Multimodal Visual Encoding Model Aided by Introducing Verbal Semantic Information
Aug 29, 2023



Biological research has revealed that the verbal semantic information in the brain cortex, as an additional source, participates in nonverbal semantic tasks, such as visual encoding. However, previous visual encoding models did not incorporate verbal semantic information, contradicting this biological finding. This paper proposes a multimodal visual information encoding network model based on stimulus images and associated textual information in response to this issue. Our visual information encoding network model takes stimulus images as input and leverages textual information generated by a text-image generation model as verbal semantic information. This approach injects new information into the visual encoding model. Subsequently, a Transformer network aligns image and text feature information, creating a multimodal feature space. A convolutional network then maps from this multimodal feature space to voxel space, constructing the multimodal visual information encoding network model. Experimental results demonstrate that the proposed multimodal visual information encoding network model outperforms previous models under the exact training cost. In voxel prediction of the left hemisphere of subject 1's brain, the performance improves by approximately 15.87%, while in the right hemisphere, the performance improves by about 4.6%. The multimodal visual encoding network model exhibits superior encoding performance. Additionally, ablation experiments indicate that our proposed model better simulates the brain's visual information processing.
Dynamic ensemble selection based on Deep Neural Network Uncertainty Estimation for Adversarial Robustness
Aug 01, 2023



The deep neural network has attained significant efficiency in image recognition. However, it has vulnerable recognition robustness under extensive data uncertainty in practical applications. The uncertainty is attributed to the inevitable ambient noise and, more importantly, the possible adversarial attack. Dynamic methods can effectively improve the defense initiative in the arms race of attack and defense of adversarial examples. Different from the previous dynamic method depend on input or decision, this work explore the dynamic attributes in model level through dynamic ensemble selection technology to further protect the model from white-box attacks and improve the robustness. Specifically, in training phase the Dirichlet distribution is apply as prior of sub-models' predictive distribution, and the diversity constraint in parameter space is introduced under the lightweight sub-models to construct alternative ensembel model spaces. In test phase, the certain sub-models are dynamically selected based on their rank of uncertainty value for the final prediction to ensure the majority accurate principle in ensemble robustness and accuracy. Compared with the previous dynamic method and staic adversarial traning model, the presented approach can achieve significant robustness results without damaging accuracy by combining dynamics and diversity property.
MGTAB: A Multi-Relational Graph-Based Twitter Account Detection Benchmark
Jan 03, 2023The development of social media user stance detection and bot detection methods rely heavily on large-scale and high-quality benchmarks. However, in addition to low annotation quality, existing benchmarks generally have incomplete user relationships, suppressing graph-based account detection research. To address these issues, we propose a Multi-Relational Graph-Based Twitter Account Detection Benchmark (MGTAB), the first standardized graph-based benchmark for account detection. To our knowledge, MGTAB was built based on the largest original data in the field, with over 1.55 million users and 130 million tweets. MGTAB contains 10,199 expert-annotated users and 7 types of relationships, ensuring high-quality annotation and diversified relations. In MGTAB, we extracted the 20 user property features with the greatest information gain and user tweet features as the user features. In addition, we performed a thorough evaluation of MGTAB and other public datasets. Our experiments found that graph-based approaches are generally more effective than feature-based approaches and perform better when introducing multiple relations. By analyzing experiment results, we identify effective approaches for account detection and provide potential future research directions in this field. Our benchmark and standardized evaluation procedures are freely available at: https://github.com/GraphDetec/MGTAB.
Dynamic Stochastic Ensemble with Adversarial Robust Lottery Ticket Subnetworks
Oct 06, 2022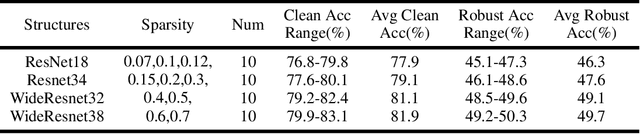

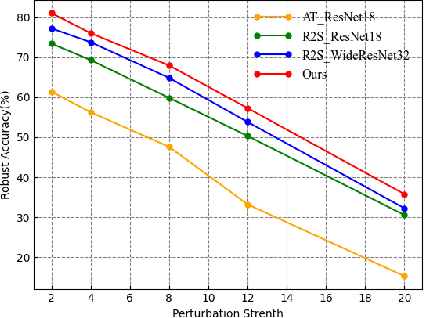

Adversarial attacks are considered the intrinsic vulnerability of CNNs. Defense strategies designed for attacks have been stuck in the adversarial attack-defense arms race, reflecting the imbalance between attack and defense. Dynamic Defense Framework (DDF) recently changed the passive safety status quo based on the stochastic ensemble model. The diversity of subnetworks, an essential concern in the DDF, can be effectively evaluated by the adversarial transferability between different networks. Inspired by the poor adversarial transferability between subnetworks of scratch tickets with various remaining ratios, we propose a method to realize the dynamic stochastic ensemble defense strategy. We discover the adversarial transferable diversity between robust lottery ticket subnetworks drawn from different basic structures and sparsity. The experimental results suggest that our method achieves better robust and clean recognition accuracy by adversarial transferable diversity, which would decrease the reliability of attacks.