 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Broaden Your Views for Self-Supervised Video Learning
Mar 30, 2021
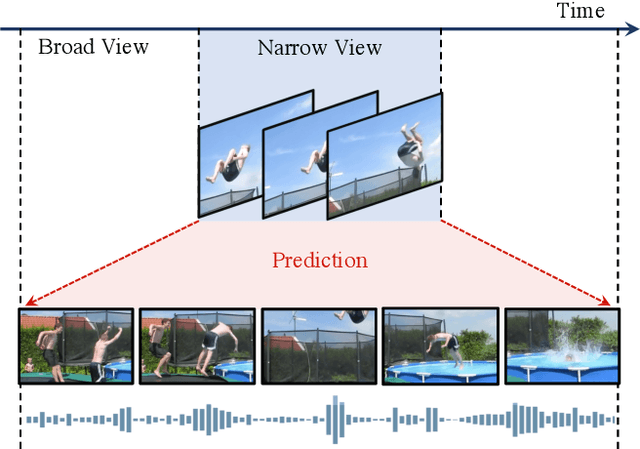
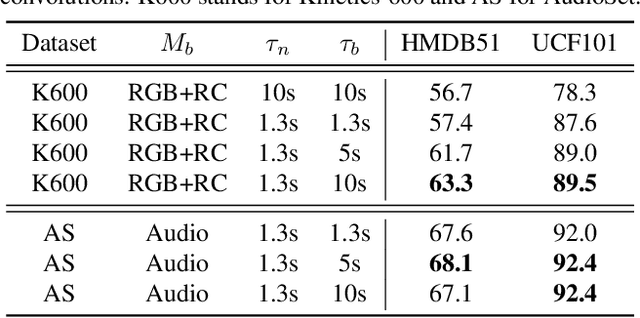
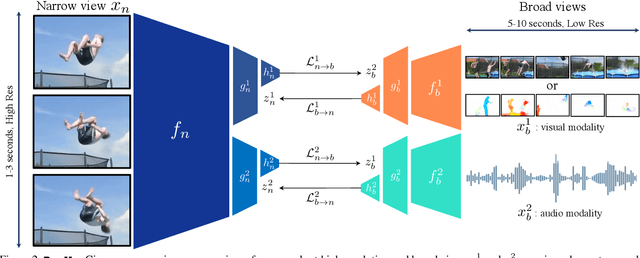
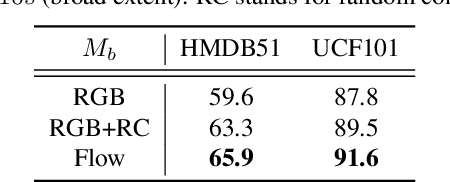
Most successful self-supervised learning methods are trained to align the representations of two independent views from the data. State-of-the-art methods in video are inspired by image techniques, where these two views are similarly extracted by cropping and augmenting the resulting crop. However, these methods miss a crucial element in the video domain: time. We introduce BraVe, a self-supervised learning framework for video. In BraVe, one of the views has access to a narrow temporal window of the video while the other view has a broad access to the video content. Our models learn to generalise from the narrow view to the general content of the video. Furthermore, BraVe processes the views with different backbones, enabling the use of alternative augmentations or modalities into the broad view such as optical flow, randomly convolved RGB frames, audio or their combinations. We demonstrate that BraVe achieves state-of-the-art results in self-supervised representation learning on standard video and audio classification benchmarks including UCF101, HMDB51, Kinetics, ESC-50 and AudioSet.
Design of a vision based range bearing and heading system for robot swarms
Mar 14, 2021An essential problem of swarm robotics is how members of the swarm knows the positions of other robots. The main aim of this research is to develop a cost-effective and simple vision-based system to detect the range, bearing, and heading of the robots inside a swarm using a multi-purpose passive landmark. A small Zumo robot equipped with Raspberry Pi, PiCamera is utilized for the implementation of the algorithm, and different kinds of multipurpose passive landmarks with nonsymmetrical patterns, which give reliable information about the range, bearing and heading in a single unit, are designed. By comparing the recorded features obtained from image analysis of the landmark through systematical experimentation and the actual measurements, correlations are obtained, and algorithms converting those features into range, bearing and heading are designed. The reliability and accuracy of algorithms are tested and errors are found within an acceptable range.
Crowd Sourcing Image Segmentation with iaSTAPLE
Feb 21, 2017
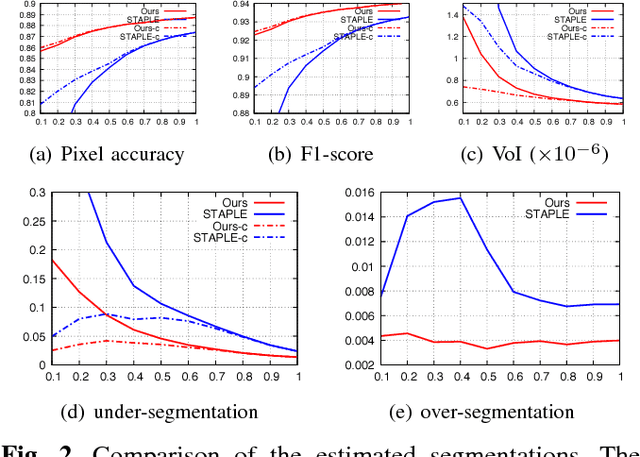

We propose a novel label fusion technique as well as a crowdsourcing protocol to efficiently obtain accurate epithelial cell segmentations from non-expert crowd workers. Our label fusion technique simultaneously estimates the true segmentation, the performance levels of individual crowd workers, and an image segmentation model in the form of a pairwise Markov random field. We term our approach image-aware STAPLE (iaSTAPLE) since our image segmentation model seamlessly integrates into the well-known and widely used STAPLE approach. In an evaluation on a light microscopy dataset containing more than 5000 membrane labeled epithelial cells of a fly wing, we show that iaSTAPLE outperforms STAPLE in terms of segmentation accuracy as well as in terms of the accuracy of estimated crowd worker performance levels, and is able to correctly segment 99% of all cells when compared to expert segmentations. These results show that iaSTAPLE is a highly useful tool for crowd sourcing image segmentation.
DAF-NET: a saliency based weakly supervised method of dual attention fusion for fine-grained image classification
Jan 04, 2020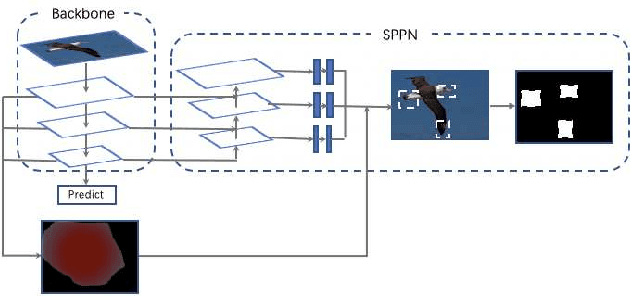
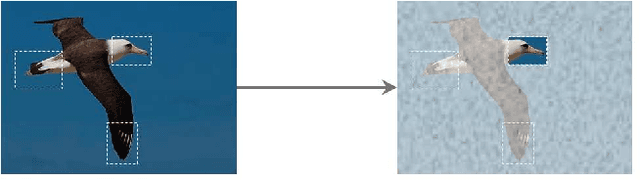
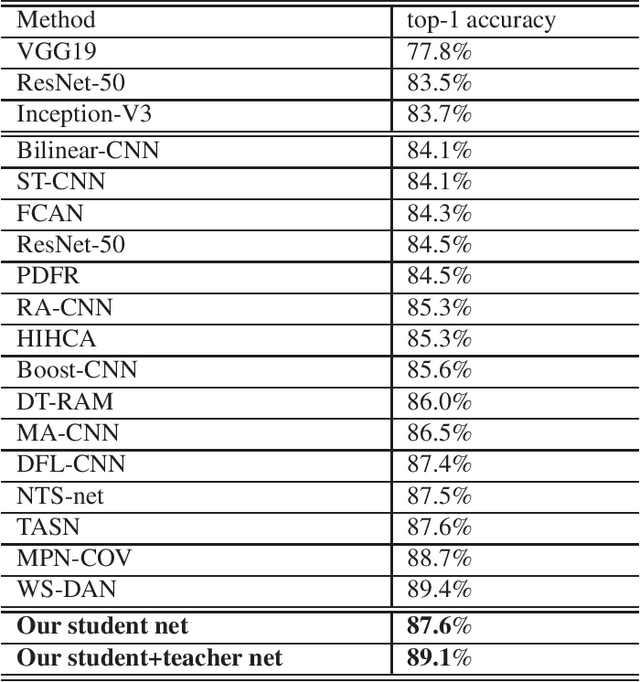
Fine-grained image classification is a challenging problem, since the difficulty of finding discriminative features. To handle this circumstance, basically, there are two ways to go. One is use attention based method to focus on informative areas, while the other one aims to find high order between features. Further, for attention based method there are two directions, activation based and detection based, which are proved effective by scholars. However ,rare work focus on fusing two types of attention with high order feature. In this paper, we propose a novel DAF method which fuse two types of attention and use them to as PAF(part attention filter) in deep bilinear transformation module to mine the relationship between separate parts of an object. Briefly, our network constructed by a student net who attempt to output two attention maps and a teacher net uses these two maps as empirical information to refine the result. The experiment result shows that only student net could get 87.6% accuracy in CUB dataset while cooperating with teacher net could achieve 89.1% accuracy.
Combined Depth Space based Architecture Search For Person Re-identification
Apr 09, 2021
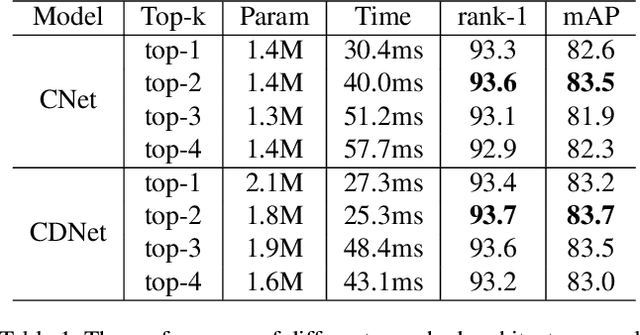
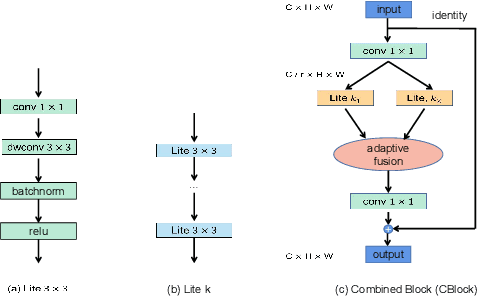
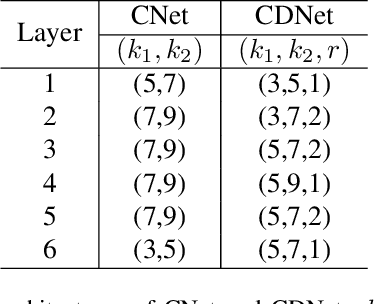
Most works on person re-identification (ReID) take advantage of large backbone networks such as ResNet, which are designed for image classification instead of ReID, for feature extraction. However, these backbones may not be computationally efficient or the most suitable architectures for ReID. In this work, we aim to design a lightweight and suitable network for ReID. We propose a novel search space called Combined Depth Space (CDS), based on which we search for an efficient network architecture, which we call CDNet, via a differentiable architecture search algorithm. Through the use of the combined basic building blocks in CDS, CDNet tends to focus on combined pattern information that is typically found in images of pedestrians. We then propose a low-cost search strategy named the Top-k Sample Search strategy to make full use of the search space and avoid trapping in local optimal result. Furthermore, an effective Fine-grained Balance Neck (FBLNeck), which is removable at the inference time, is presented to balance the effects of triplet loss and softmax loss during the training process. Extensive experiments show that our CDNet (~1.8M parameters) has comparable performance with state-of-the-art lightweight networks.
Image Ordinal Classification and Understanding: Grid Dropout with Masking Label
May 08, 2018
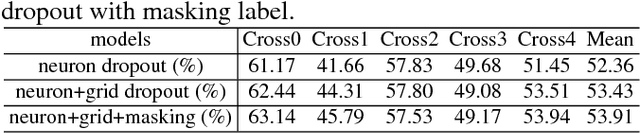

Image ordinal classification refers to predicting a discrete target value which carries ordering correlation among image categories. The limited size of labeled ordinal data renders modern deep learning approaches easy to overfit. To tackle this issue, neuron dropout and data augmentation were proposed which, however, still suffer from over-parameterization and breaking spatial structure, respectively. To address the issues, we first propose a grid dropout method that randomly dropout/blackout some areas of the raining image. Then we combine the objective of predicting the blackout patches with classification to take advantage of the spatial information. Finally we demonstrate the effectiveness of both approaches by visualizing the Class Activation Map (CAM) and discover that grid dropout is more aware of the whole facial areas and more robust than neuron dropout for small training dataset. Experiments are conducted on a challenging age estimation dataset - Adience dataset with very competitive results compared with state-of-the-art methods.
Anchor Distance for 3D Multi-Object Distance Estimation from 2D Single Shot
Feb 16, 2021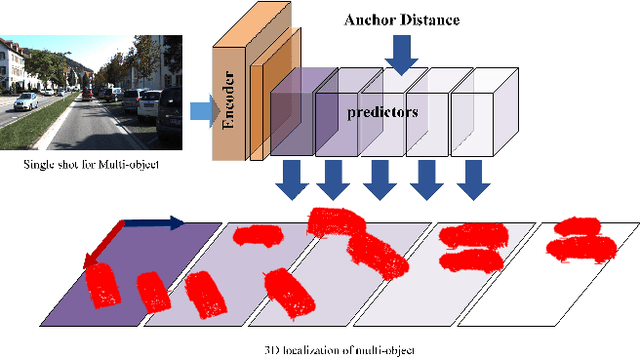
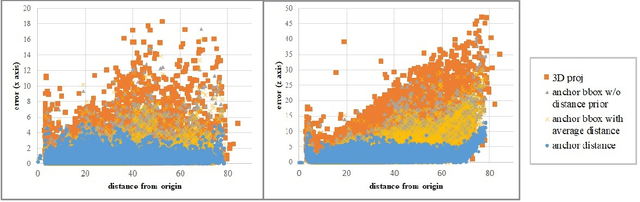
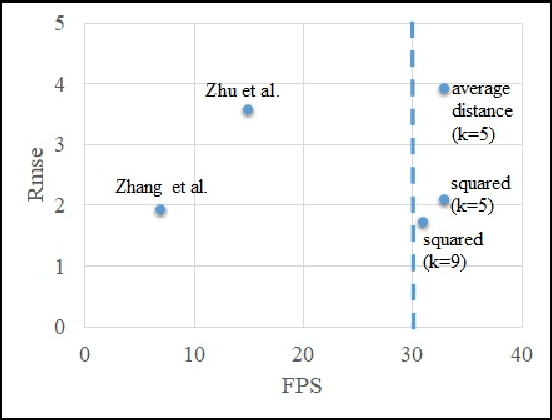
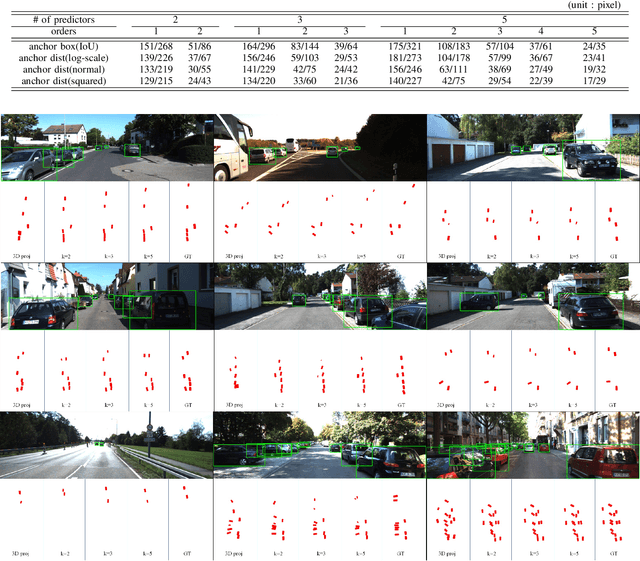
Visual perception of the objects in a 3D environment is a key to successful performance in autonomous driving and simultaneous localization and mapping (SLAM). In this paper, we present a real time approach for estimating the distances to multiple objects in a scene using only a single-shot image. Given a 2D Bounding Box (BBox) and object parameters, a 3D distance to the object can be calculated directly using 3D reprojection; however, such methods are prone to significant errors because an error from the 2D detection can be amplified in 3D. In addition, it is also challenging to apply such methods to a real-time system due to the computational burden. In the case of the traditional multi-object detection methods, %they mostly pay attention to existing works have been developed for specific tasks such as object segmentation or 2D BBox regression. These methods introduce the concept of anchor BBox for elaborate 2D BBox estimation, and predictors are specialized and trained for specific 2D BBoxes. In order to estimate the distances to the 3D objects from a single 2D image, we introduce the notion of \textit{anchor distance} based on an object's location and propose a method that applies the anchor distance to the multi-object detector structure. We let the predictors catch the distance prior using anchor distance and train the network based on the distance. The predictors can be characterized to the objects located in a specific distance range. By propagating the distance prior using a distance anchor to the predictors, it is feasible to perform the precise distance estimation and real-time execution simultaneously. The proposed method achieves about 30 FPS speed, and shows the lowest RMSE compared to the existing methods.
Crafting a Toolchain for Image Restoration by Deep Reinforcement Learning
Apr 10, 2018
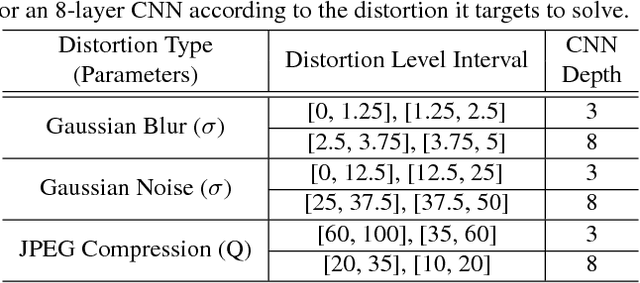
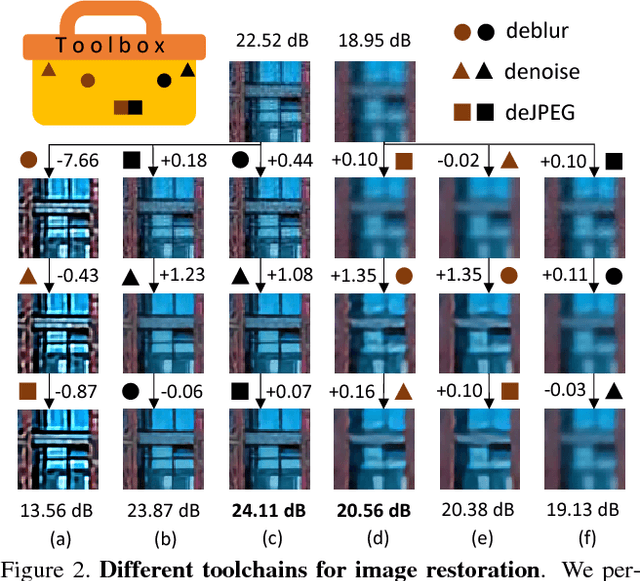

We investigate a novel approach for image restoration by reinforcement learning. Unlike existing studies that mostly train a single large network for a specialized task, we prepare a toolbox consisting of small-scale convolutional networks of different complexities and specialized in different tasks. Our method, RL-Restore, then learns a policy to select appropriate tools from the toolbox to progressively restore the quality of a corrupted image. We formulate a step-wise reward function proportional to how well the image is restored at each step to learn the action policy. We also devise a joint learning scheme to train the agent and tools for better performance in handling uncertainty. In comparison to conventional human-designed networks, RL-Restore is capable of restoring images corrupted with complex and unknown distortions in a more parameter-efficient manner using the dynamically formed toolchain.
Multiple Instance Captioning: Learning Representations from Histopathology Textbooks and Articles
Mar 08, 2021
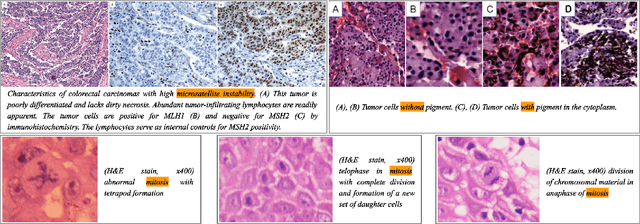
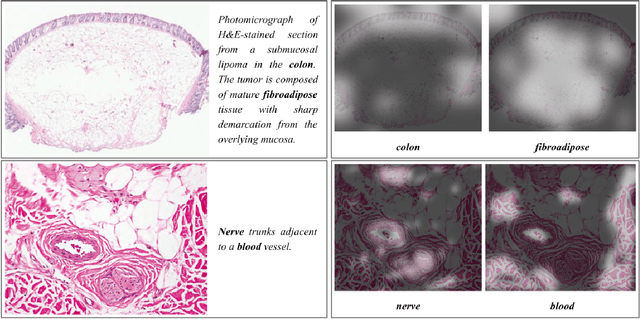
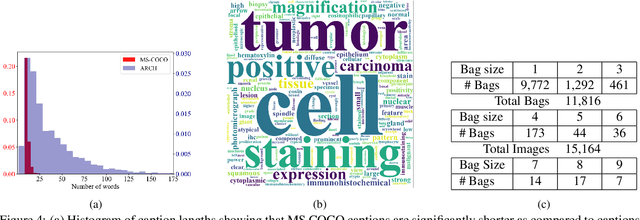
We present ARCH, a computational pathology (CP) multiple instance captioning dataset to facilitate dense supervision of CP tasks. Existing CP datasets focus on narrow tasks; ARCH on the other hand contains dense diagnostic and morphological descriptions for a range of stains, tissue types and pathologies. Using intrinsic dimensionality estimation, we show that ARCH is the only CP dataset to (ARCH-)rival its computer vision analog MS-COCO Captions. We conjecture that an encoder pre-trained on dense image captions learns transferable representations for most CP tasks. We support the conjecture with evidence that ARCH representation transfers to a variety of pathology sub-tasks better than ImageNet features or representations obtained via self-supervised or multi-task learning on pathology images alone. We release our best model and invite other researchers to test it on their CP tasks.
FoodAI: Food Image Recognition via Deep Learning for Smart Food Logging
Sep 26, 2019



An important aspect of health monitoring is effective logging of food consumption. This can help management of diet-related diseases like obesity, diabetes, and even cardiovascular diseases. Moreover, food logging can help fitness enthusiasts, and people who wanting to achieve a target weight. However, food-logging is cumbersome, and requires not only taking additional effort to note down the food item consumed regularly, but also sufficient knowledge of the food item consumed (which is difficult due to the availability of a wide variety of cuisines). With increasing reliance on smart devices, we exploit the convenience offered through the use of smart phones and propose a smart-food logging system: FoodAI, which offers state-of-the-art deep-learning based image recognition capabilities. FoodAI has been developed in Singapore and is particularly focused on food items commonly consumed in Singapore. FoodAI models were trained on a corpus of 400,000 food images from 756 different classes. In this paper we present extensive analysis and insights into the development of this system. FoodAI has been deployed as an API service and is one of the components powering Healthy 365, a mobile app developed by Singapore's Heath Promotion Board. We have over 100 registered organizations (universities, companies, start-ups) subscribing to this service and actively receive several API requests a day. FoodAI has made food logging convenient, aiding smart consumption and a healthy lifestyle.