 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuriosity in hindsight
Nov 18, 2022



Consider the exploration in sparse-reward or reward-free environments, such as Montezuma's Revenge. The curiosity-driven paradigm dictates an intuitive technique: At each step, the agent is rewarded for how much the realized outcome differs from their predicted outcome. However, using predictive error as intrinsic motivation is prone to fail in stochastic environments, as the agent may become hopelessly drawn to high-entropy areas of the state-action space, such as a noisy TV. Therefore it is important to distinguish between aspects of world dynamics that are inherently predictable and aspects that are inherently unpredictable: The former should constitute a source of intrinsic reward, whereas the latter should not. In this work, we study a natural solution derived from structural causal models of the world: Our key idea is to learn representations of the future that capture precisely the unpredictable aspects of each outcome -- not any more, not any less -- which we use as additional input for predictions, such that intrinsic rewards do vanish in the limit. First, we propose incorporating such hindsight representations into the agent's model to disentangle "noise" from "novelty", yielding Curiosity in Hindsight: a simple and scalable generalization of curiosity that is robust to all types of stochasticity. Second, we implement this framework as a drop-in modification of any prediction-based exploration bonus, and instantiate it for the recently introduced BYOL-Explore algorithm as a prime example, resulting in the noise-robust "BYOL-Hindsight". Third, we illustrate its behavior under various stochasticities in a grid world, and find improvements over BYOL-Explore in hard-exploration Atari games with sticky actions. Importantly, we show SOTA results in exploring Montezuma with sticky actions, while preserving performance in the non-sticky setting.
Self-conditioned Embedding Diffusion for Text Generation
Nov 08, 2022Can continuous diffusion models bring the same performance breakthrough on natural language they did for image generation? To circumvent the discrete nature of text data, we can simply project tokens in a continuous space of embeddings, as is standard in language modeling. We propose Self-conditioned Embedding Diffusion, a continuous diffusion mechanism that operates on token embeddings and allows to learn flexible and scalable diffusion models for both conditional and unconditional text generation. Through qualitative and quantitative evaluation, we show that our text diffusion models generate samples comparable with those produced by standard autoregressive language models - while being in theory more efficient on accelerator hardware at inference time. Our work paves the way for scaling up diffusion models for text, similarly to autoregressive models, and for improving performance with recent refinements to continuous diffusion.
BYOL-Explore: Exploration by Bootstrapped Prediction
Jun 16, 2022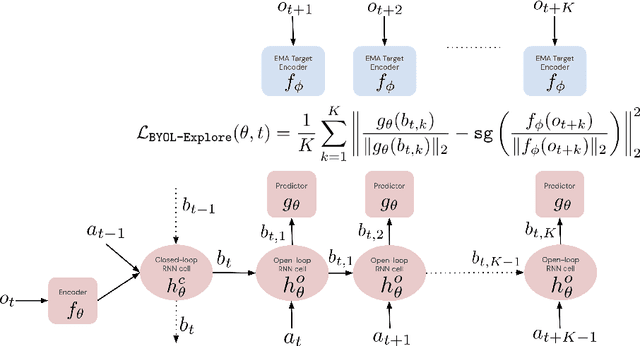
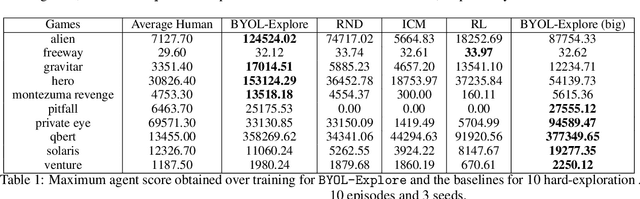

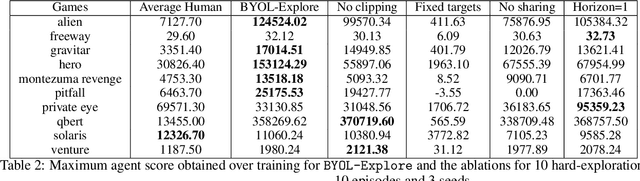
We present BYOL-Explore, a conceptually simple yet general approach for curiosity-driven exploration in visually-complex environments. BYOL-Explore learns a world representation, the world dynamics, and an exploration policy all-together by optimizing a single prediction loss in the latent space with no additional auxiliary objective. We show that BYOL-Explore is effective in DM-HARD-8, a challenging partially-observable continuous-action hard-exploration benchmark with visually-rich 3-D environments. On this benchmark, we solve the majority of the tasks purely through augmenting the extrinsic reward with BYOL-Explore s intrinsic reward, whereas prior work could only get off the ground with human demonstrations. As further evidence of the generality of BYOL-Explore, we show that it achieves superhuman performance on the ten hardest exploration games in Atari while having a much simpler design than other competitive agents.
Broaden Your Views for Self-Supervised Video Learning
Mar 30, 2021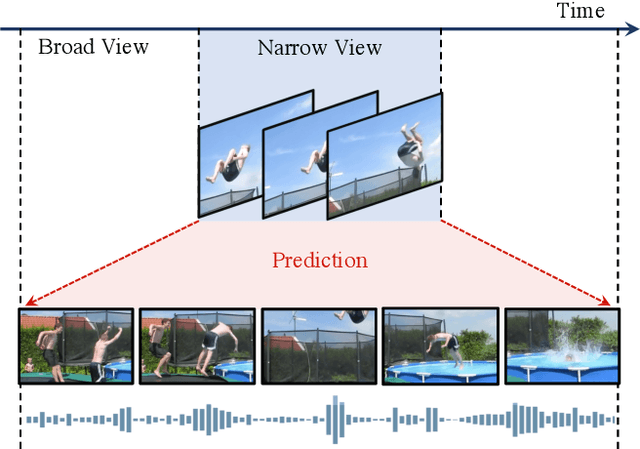
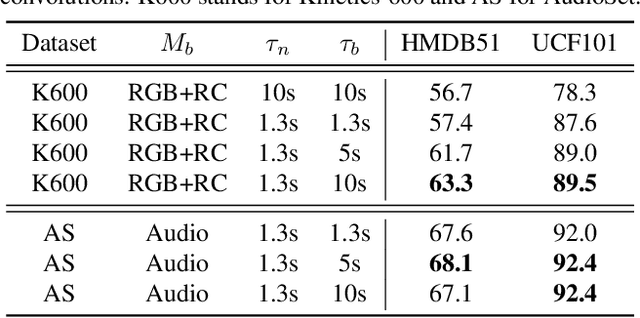
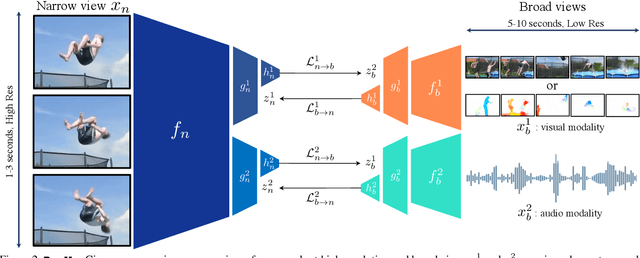
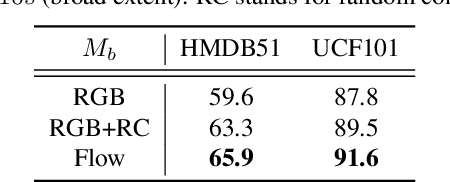
Most successful self-supervised learning methods are trained to align the representations of two independent views from the data. State-of-the-art methods in video are inspired by image techniques, where these two views are similarly extracted by cropping and augmenting the resulting crop. However, these methods miss a crucial element in the video domain: time. We introduce BraVe, a self-supervised learning framework for video. In BraVe, one of the views has access to a narrow temporal window of the video while the other view has a broad access to the video content. Our models learn to generalise from the narrow view to the general content of the video. Furthermore, BraVe processes the views with different backbones, enabling the use of alternative augmentations or modalities into the broad view such as optical flow, randomly convolved RGB frames, audio or their combinations. We demonstrate that BraVe achieves state-of-the-art results in self-supervised representation learning on standard video and audio classification benchmarks including UCF101, HMDB51, Kinetics, ESC-50 and AudioSet.
BYOL works even without batch statistics
Oct 20, 2020

Bootstrap Your Own Latent (BYOL) is a self-supervised learning approach for image representation. From an augmented view of an image, BYOL trains an online network to predict a target network representation of a different augmented view of the same image. Unlike contrastive methods, BYOL does not explicitly use a repulsion term built from negative pairs in its training objective. Yet, it avoids collapse to a trivial, constant representation. Thus, it has recently been hypothesized that batch normalization (BN) is critical to prevent collapse in BYOL. Indeed, BN flows gradients across batch elements, and could leak information about negative views in the batch, which could act as an implicit negative (contrastive) term. However, we experimentally show that replacing BN with a batch-independent normalization scheme (namely, a combination of group normalization and weight standardization) achieves performance comparable to vanilla BYOL ($73.9\%$ vs. $74.3\%$ top-1 accuracy under the linear evaluation protocol on ImageNet with ResNet-$50$). Our finding disproves the hypothesis that the use of batch statistics is a crucial ingredient for BYOL to learn useful representations.
Monte-Carlo Tree Search as Regularized Policy Optimization
Jul 24, 2020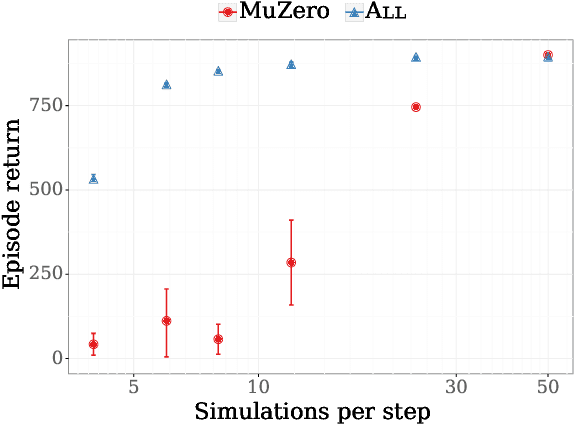
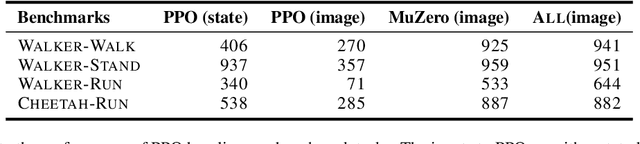
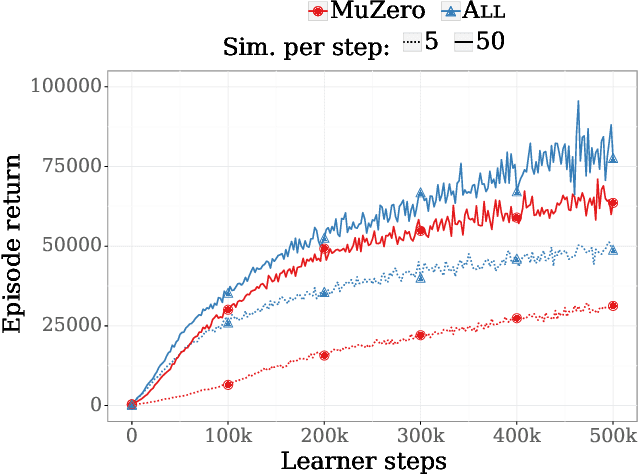
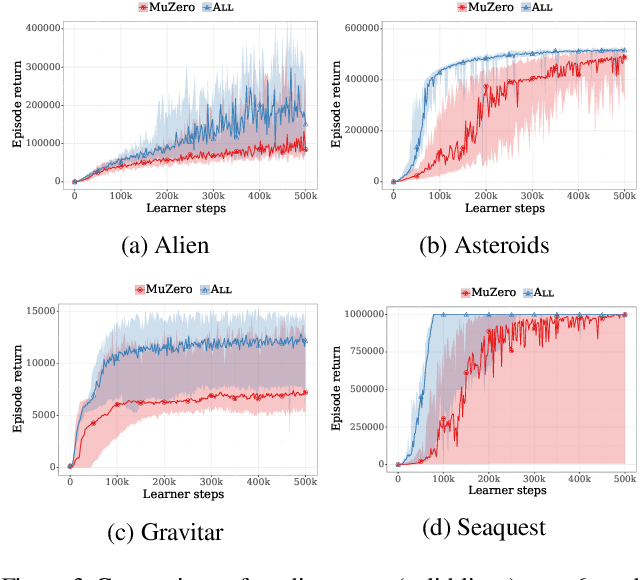
The combination of Monte-Carlo tree search (MCTS) with deep reinforcement learning has led to significant advances in artificial intelligence. However, AlphaZero, the current state-of-the-art MCTS algorithm, still relies on handcrafted heuristics that are only partially understood. In this paper, we show that AlphaZero's search heuristics, along with other common ones such as UCT, are an approximation to the solution of a specific regularized policy optimization problem. With this insight, we propose a variant of AlphaZero which uses the exact solution to this policy optimization problem, and show experimentally that it reliably outperforms the original algorithm in multiple domains.
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
Jun 13, 2020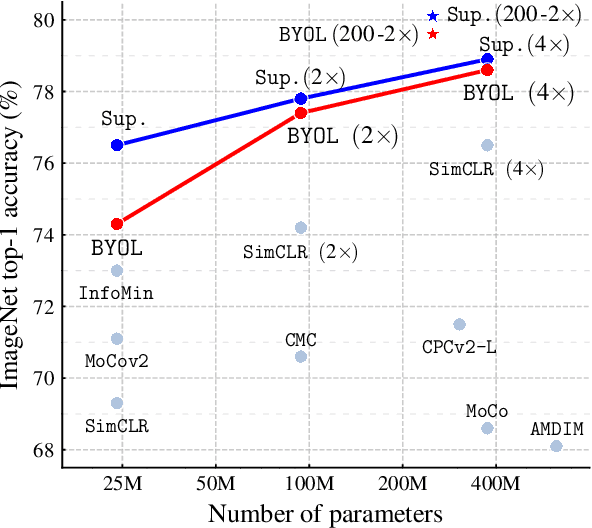

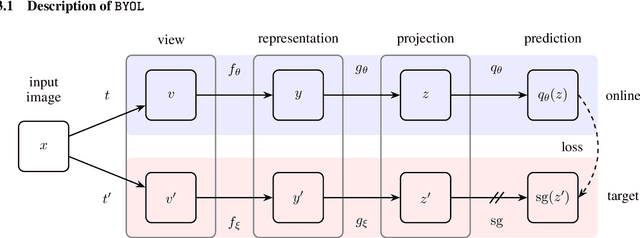
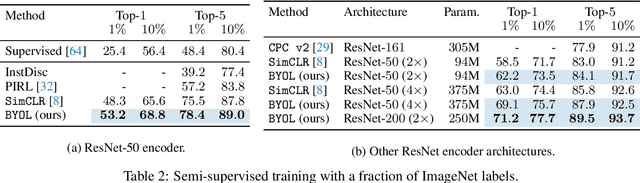
We introduce Bootstrap Your Own Latent (BYOL), a new approach to self-supervised image representation learning. BYOL relies on two neural networks, referred to as online and target networks, that interact and learn from each other. From an augmented view of an image, we train the online network to predict the target network representation of the same image under a different augmented view. At the same time, we update the target network with a slow-moving average of the online network. While state-of-the art methods intrinsically rely on negative pairs, BYOL achieves a new state of the art without them. BYOL reaches $74.3\%$ top-1 classification accuracy on ImageNet using the standard linear evaluation protocol with a ResNet-50 architecture and $79.6\%$ with a larger ResNet. We show that BYOL performs on par or better than the current state of the art on both transfer and semi-supervised benchmarks.
Bootstrap Latent-Predictive Representations for Multitask Reinforcement Learning
Apr 30, 2020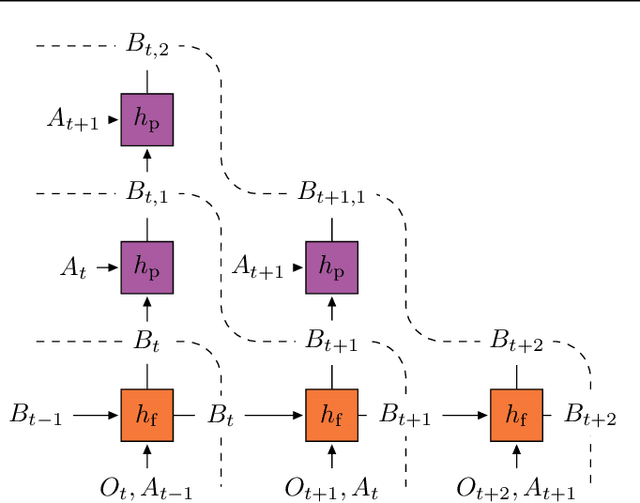
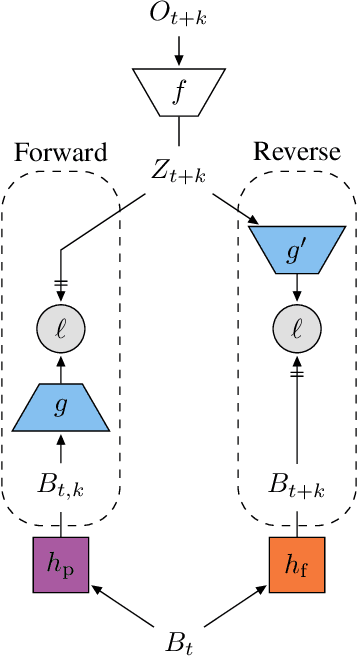

Learning a good representation is an essential component for deep reinforcement learning (RL). Representation learning is especially important in multitask and partially observable settings where building a representation of the unknown environment is crucial to solve the tasks. Here we introduce Prediction of Bootstrap Latents (PBL), a simple and flexible self-supervised representation learning algorithm for multitask deep RL. PBL builds on multistep predictive representations of future observations, and focuses on capturing structured information about environment dynamics. Specifically, PBL trains its representation by predicting latent embeddings of future observations. These latent embeddings are themselves trained to be predictive of the aforementioned representations. These predictions form a bootstrapping effect, allowing the agent to learn more about the key aspects of the environment dynamics. In addition, by defining prediction tasks completely in latent space, PBL provides the flexibility of using multimodal observations involving pixel images, language instructions, rewards and more. We show in our experiments that PBL delivers across-the-board improved performance over state of the art deep RL agents in the DMLab-30 and Atari-57 multitask setting.
World Discovery Models
Mar 01, 2019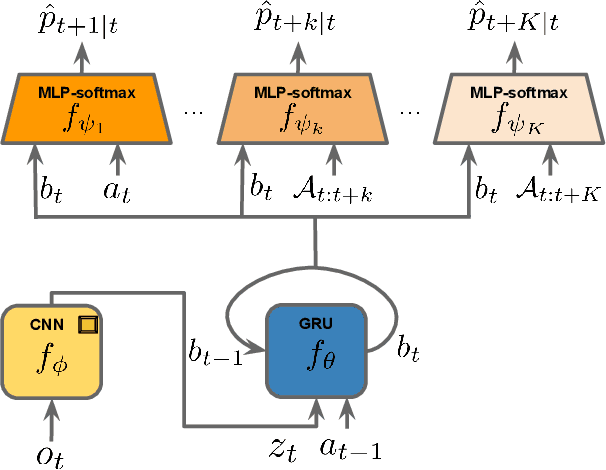
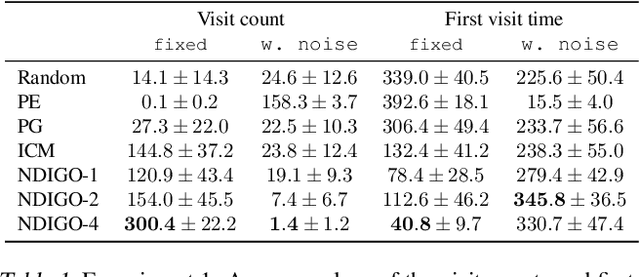

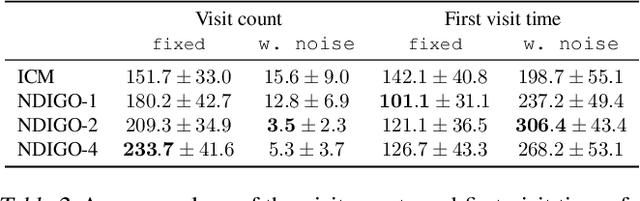
As humans we are driven by a strong desire for seeking novelty in our world. Also upon observing a novel pattern we are capable of refining our understanding of the world based on the new information---humans can discover their world. The outstanding ability of the human mind for discovery has led to many breakthroughs in science, art and technology. Here we investigate the possibility of building an agent capable of discovering its world using the modern AI technology. In particular we introduce NDIGO, Neural Differential Information Gain Optimisation, a self-supervised discovery model that aims at seeking new information to construct a global view of its world from partial and noisy observations. Our experiments on some controlled 2-D navigation tasks show that NDIGO outperforms state-of-the-art information-seeking methods in terms of the quality of the learned representation. The improvement in performance is particularly significant in the presence of white or structured noise where other information-seeking methods follow the noise instead of discovering their world.
Coupled Longitudinal and Lateral Control of a Vehicle using Deep Learning
Oct 22, 2018
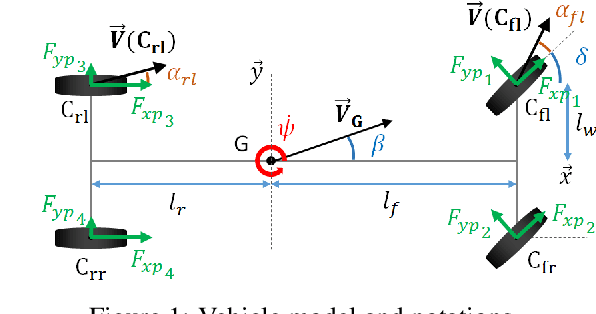
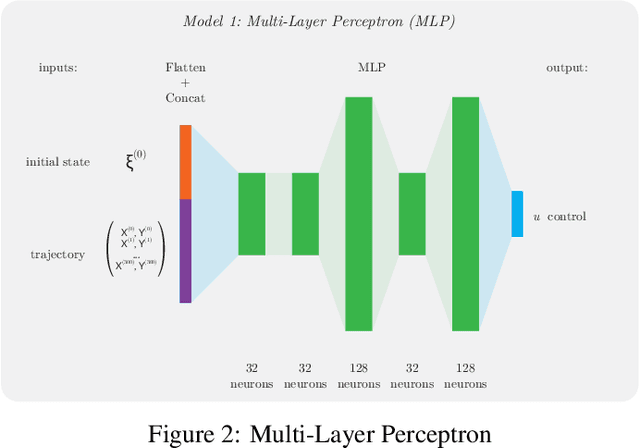
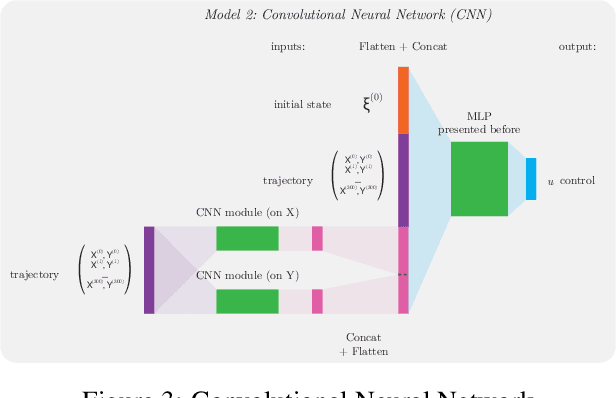
This paper explores the capability of deep neural networks to capture key characteristics of vehicle dynamics, and their ability to perform coupled longitudinal and lateral control of a vehicle. To this extent, two different artificial neural networks are trained to compute vehicle controls corresponding to a reference trajectory, using a dataset based on high-fidelity simulations of vehicle dynamics. In this study, control inputs are chosen as the steering angle of the front wheels, and the applied torque on each wheel. The performance of both models, namely a Multi-Layer Perceptron (MLP) and a Convolutional Neural Network (CNN), is evaluated based on their ability to drive the vehicle on a challenging test track, shifting between long straight lines and tight curves. A comparison to conventional decoupled controllers on the same track is also provided.