 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
AlphaStar Unplugged: Large-Scale Offline Reinforcement Learning
Aug 07, 2023



StarCraft II is one of the most challenging simulated reinforcement learning environments; it is partially observable, stochastic, multi-agent, and mastering StarCraft II requires strategic planning over long time horizons with real-time low-level execution. It also has an active professional competitive scene. StarCraft II is uniquely suited for advancing offline RL algorithms, both because of its challenging nature and because Blizzard has released a massive dataset of millions of StarCraft II games played by human players. This paper leverages that and establishes a benchmark, called AlphaStar Unplugged, introducing unprecedented challenges for offline reinforcement learning. We define a dataset (a subset of Blizzard's release), tools standardizing an API for machine learning methods, and an evaluation protocol. We also present baseline agents, including behavior cloning, offline variants of actor-critic and MuZero. We improve the state of the art of agents using only offline data, and we achieve 90% win rate against previously published AlphaStar behavior cloning agent.
Vector Quantized Models for Planning
Jun 10, 2021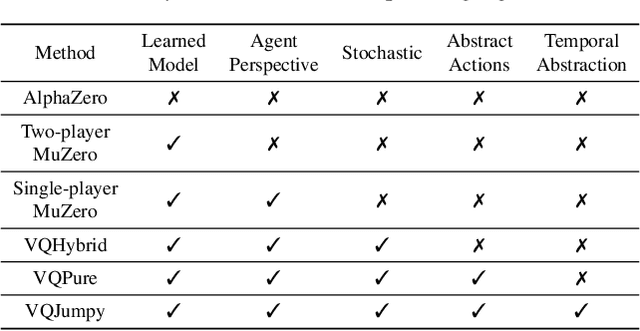
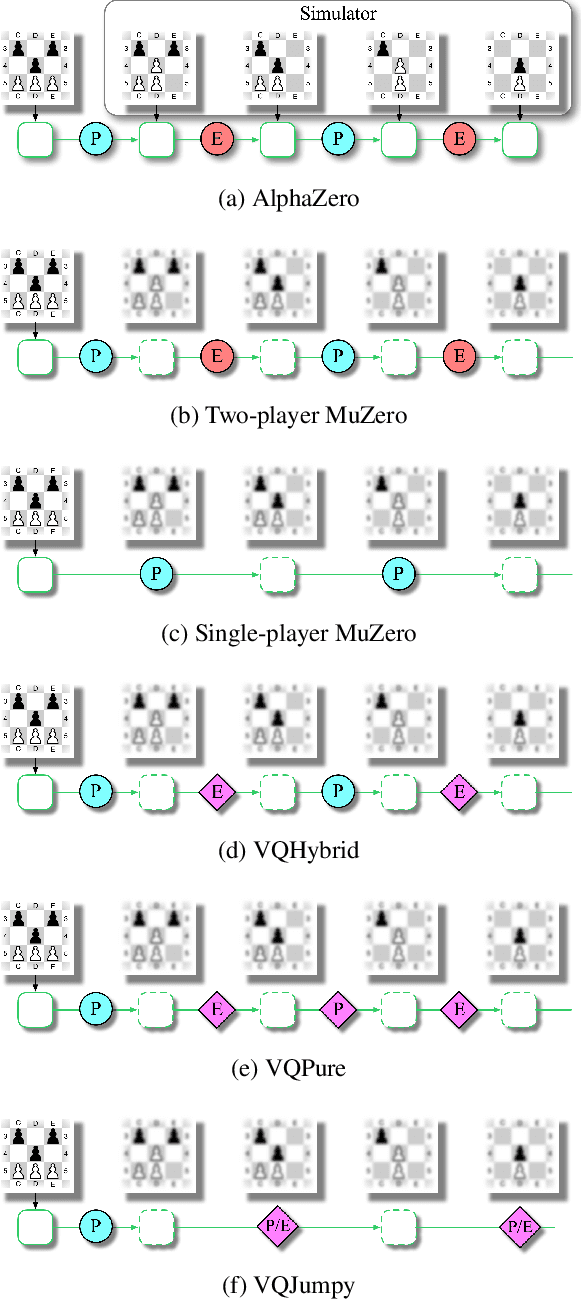
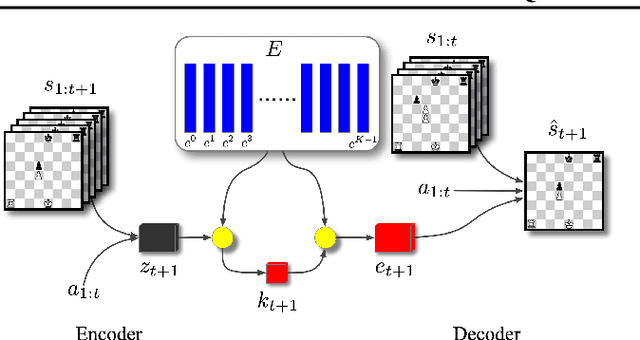
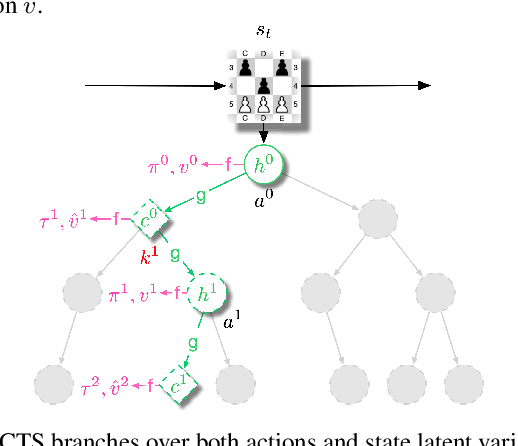
Recent developments in the field of model-based RL have proven successful in a range of environments, especially ones where planning is essential. However, such successes have been limited to deterministic fully-observed environments. We present a new approach that handles stochastic and partially-observable environments. Our key insight is to use discrete autoencoders to capture the multiple possible effects of an action in a stochastic environment. We use a stochastic variant of Monte Carlo tree search to plan over both the agent's actions and the discrete latent variables representing the environment's response. Our approach significantly outperforms an offline version of MuZero on a stochastic interpretation of chess where the opponent is considered part of the environment. We also show that our approach scales to DeepMind Lab, a first-person 3D environment with large visual observations and partial observability.
Broaden Your Views for Self-Supervised Video Learning
Mar 30, 2021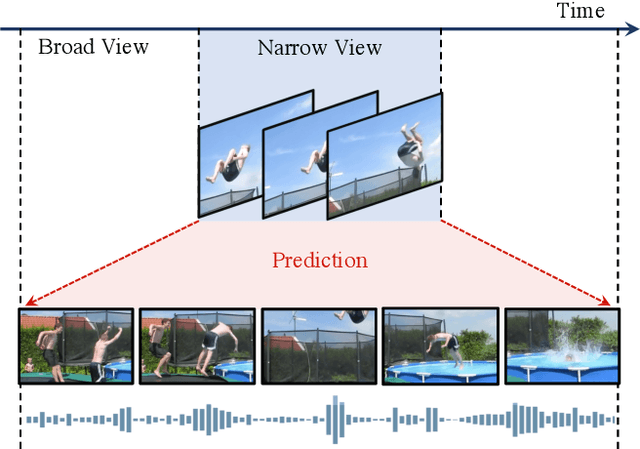
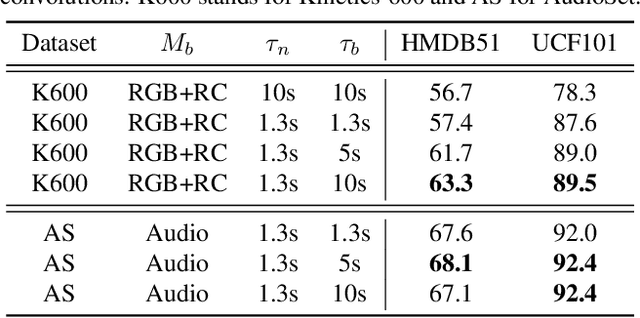
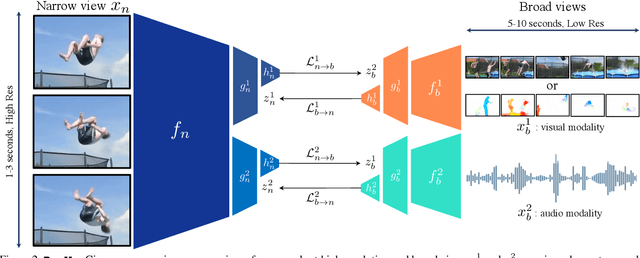
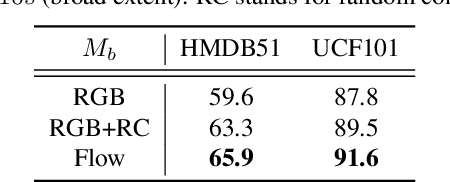
Most successful self-supervised learning methods are trained to align the representations of two independent views from the data. State-of-the-art methods in video are inspired by image techniques, where these two views are similarly extracted by cropping and augmenting the resulting crop. However, these methods miss a crucial element in the video domain: time. We introduce BraVe, a self-supervised learning framework for video. In BraVe, one of the views has access to a narrow temporal window of the video while the other view has a broad access to the video content. Our models learn to generalise from the narrow view to the general content of the video. Furthermore, BraVe processes the views with different backbones, enabling the use of alternative augmentations or modalities into the broad view such as optical flow, randomly convolved RGB frames, audio or their combinations. We demonstrate that BraVe achieves state-of-the-art results in self-supervised representation learning on standard video and audio classification benchmarks including UCF101, HMDB51, Kinetics, ESC-50 and AudioSet.
Predicting Video with VQVAE
Mar 02, 2021
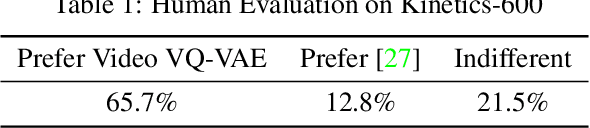


In recent years, the task of video prediction-forecasting future video given past video frames-has attracted attention in the research community. In this paper we propose a novel approach to this problem with Vector Quantized Variational AutoEncoders (VQ-VAE). With VQ-VAE we compress high-resolution videos into a hierarchical set of multi-scale discrete latent variables. Compared to pixels, this compressed latent space has dramatically reduced dimensionality, allowing us to apply scalable autoregressive generative models to predict video. In contrast to previous work that has largely emphasized highly constrained datasets, we focus on very diverse, large-scale datasets such as Kinetics-600. We predict video at a higher resolution on unconstrained videos, 256x256, than any other previous method to our knowledge. We further validate our approach against prior work via a crowdsourced human evaluation.
Are we done with ImageNet?
Jun 12, 2020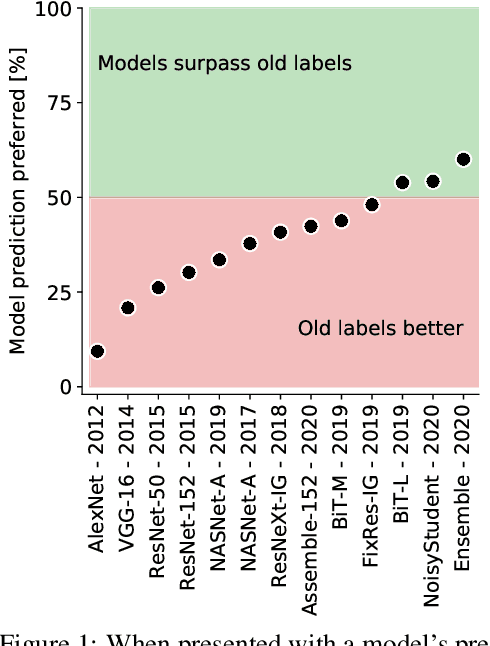
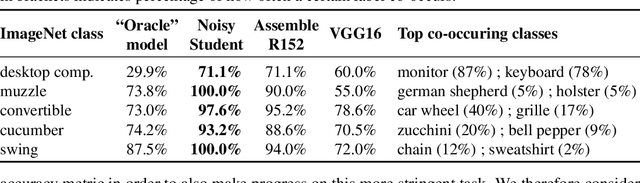
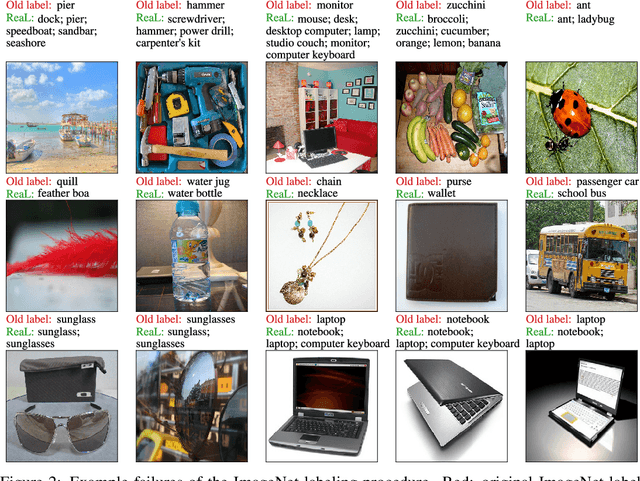
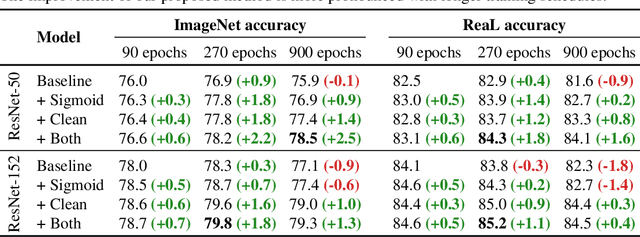
Yes, and no. We ask whether recent progress on the ImageNet classification benchmark continues to represent meaningful generalization, or whether the community has started to overfit to the idiosyncrasies of its labeling procedure. We therefore develop a significantly more robust procedure for collecting human annotations of the ImageNet validation set. Using these new labels, we reassess the accuracy of recently proposed ImageNet classifiers, and find their gains to be substantially smaller than those reported on the original labels. Furthermore, we find the original ImageNet labels to no longer be the best predictors of this independently-collected set, indicating that their usefulness in evaluating vision models may be nearing an end. Nevertheless, we find our annotation procedure to have largely remedied the errors in the original labels, reinforcing ImageNet as a powerful benchmark for future research in visual recognition.
Low Bit-Rate Speech Coding with VQ-VAE and a WaveNet Decoder
Oct 14, 2019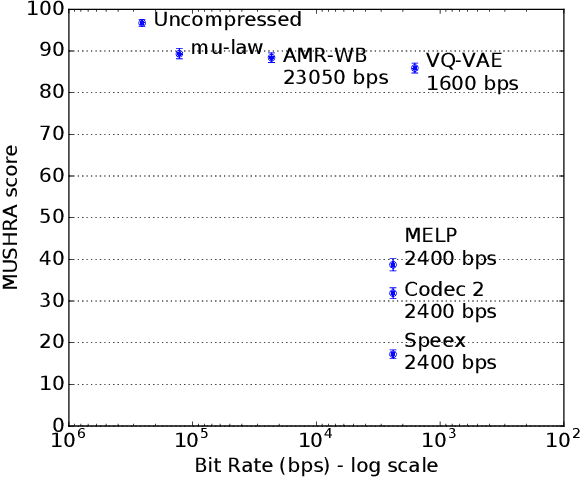
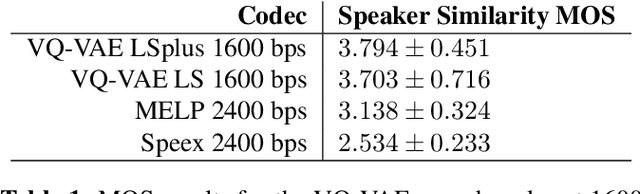
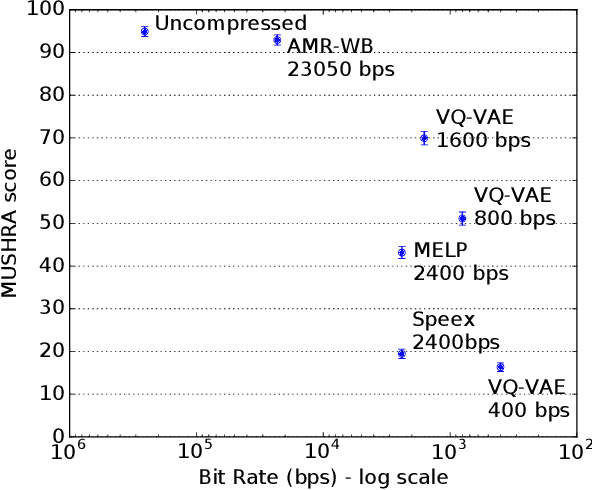
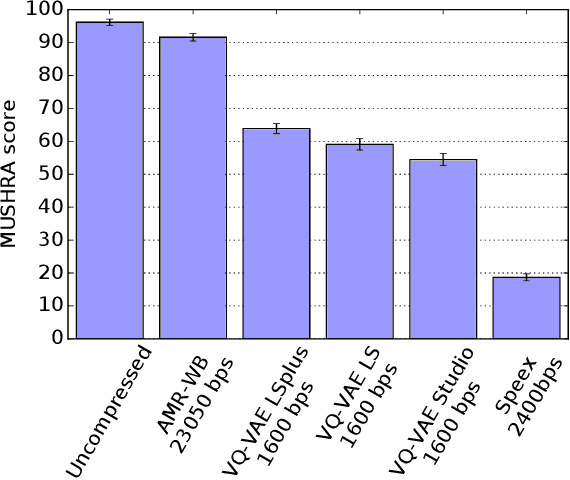
In order to efficiently transmit and store speech signals, speech codecs create a minimally redundant representation of the input signal which is then decoded at the receiver with the best possible perceptual quality. In this work we demonstrate that a neural network architecture based on VQ-VAE with a WaveNet decoder can be used to perform very low bit-rate speech coding with high reconstruction quality. A prosody-transparent and speaker-independent model trained on the LibriSpeech corpus coding audio at 1.6 kbps exhibits perceptual quality which is around halfway between the MELP codec at 2.4 kbps and AMR-WB codec at 23.05 kbps. In addition, when training on high-quality recorded speech with the test speaker included in the training set, a model coding speech at 1.6 kbps produces output of similar perceptual quality to that generated by AMR-WB at 23.05 kbps.
* ICASSP 2019
Unsupervised speech representation learning using WaveNet autoencoders
Jan 25, 2019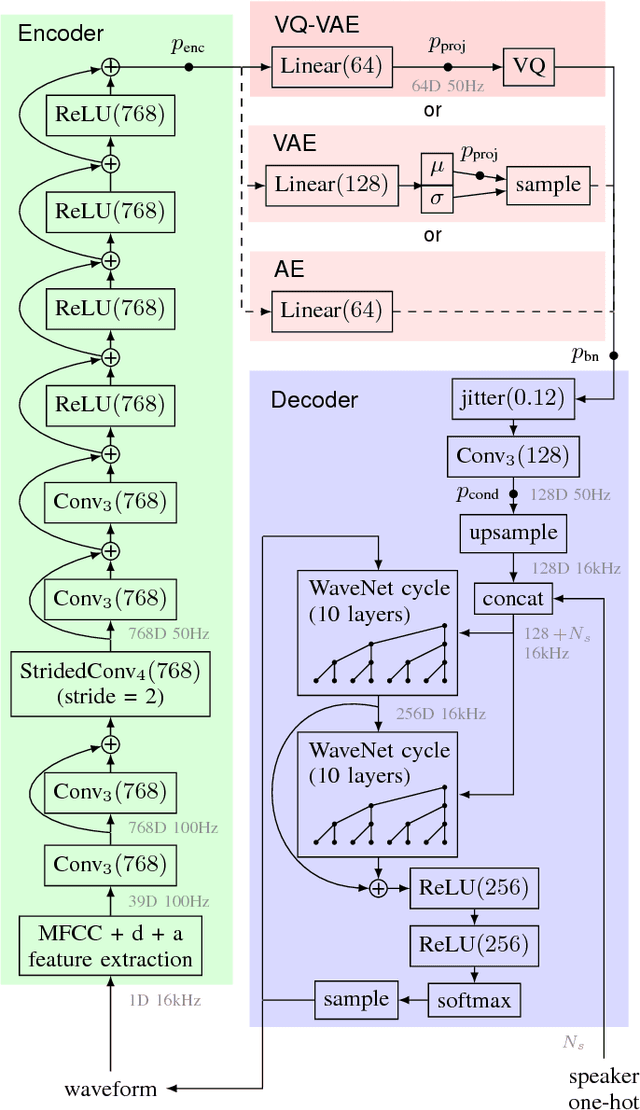
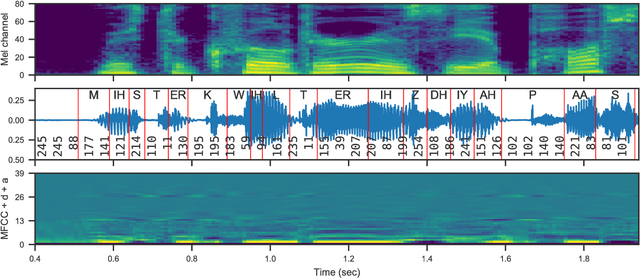
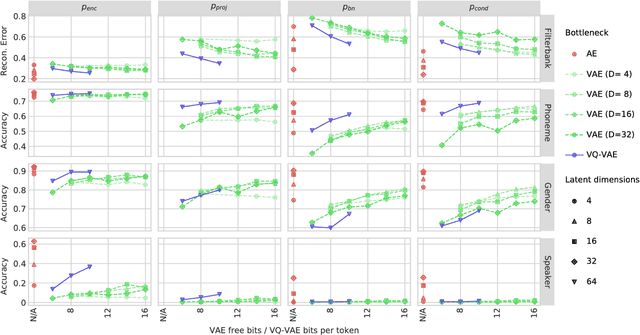
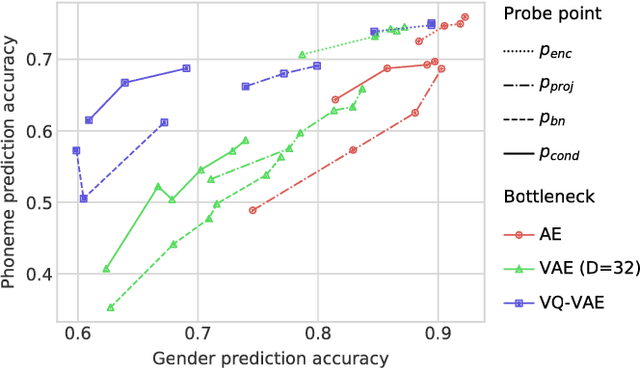
We consider the task of unsupervised extraction of meaningful latent representations of speech by applying autoencoding neural networks to speech waveforms. The goal is to learn a representation able to capture high level semantic content from the signal, e.g. phoneme identities, while being invariant to confounding low level details in the signal such as the underlying pitch contour or background noise. The behavior of autoencoder models depends on the kind of constraint that is applied to the latent representation. We compare three variants: a simple dimensionality reduction bottleneck, a Gaussian Variational Autoencoder (VAE), and a discrete Vector Quantized VAE (VQ-VAE). We analyze the quality of learned representations in terms of speaker independence, the ability to predict phonetic content, and the ability to accurately reconstruct individual spectrogram frames. Moreover, for discrete encodings extracted using the VQ-VAE, we measure the ease of mapping them to phonemes. We introduce a regularization scheme that forces the representations to focus on the phonetic content of the utterance and report performance comparable with the top entries in the ZeroSpeech 2017 unsupervised acoustic unit discovery task.
Preventing Posterior Collapse with delta-VAEs
Jan 10, 2019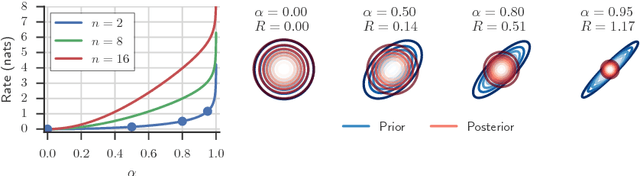
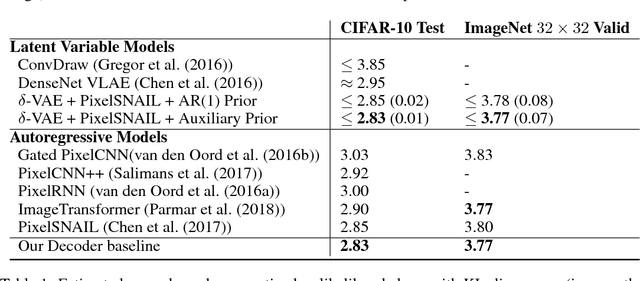
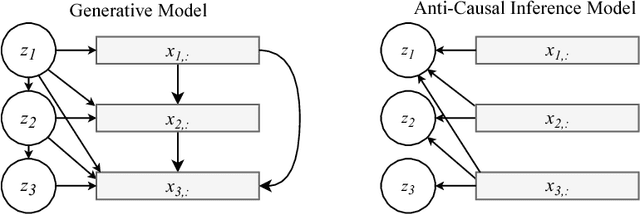

Due to the phenomenon of "posterior collapse," current latent variable generative models pose a challenging design choice that either weakens the capacity of the decoder or requires augmenting the objective so it does not only maximize the likelihood of the data. In this paper, we propose an alternative that utilizes the most powerful generative models as decoders, whilst optimising the variational lower bound all while ensuring that the latent variables preserve and encode useful information. Our proposed $\delta$-VAEs achieve this by constraining the variational family for the posterior to have a minimum distance to the prior. For sequential latent variable models, our approach resembles the classic representation learning approach of slow feature analysis. We demonstrate the efficacy of our approach at modeling text on LM1B and modeling images: learning representations, improving sample quality, and achieving state of the art log-likelihood on CIFAR-10 and ImageNet $32\times 32$.
Sample Efficient Adaptive Text-to-Speech
Sep 27, 2018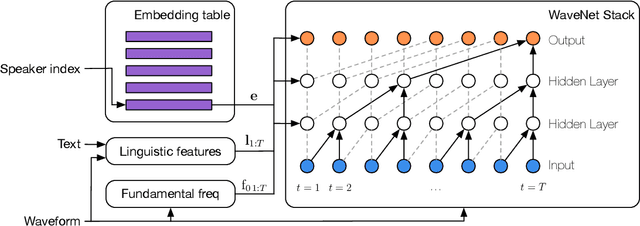
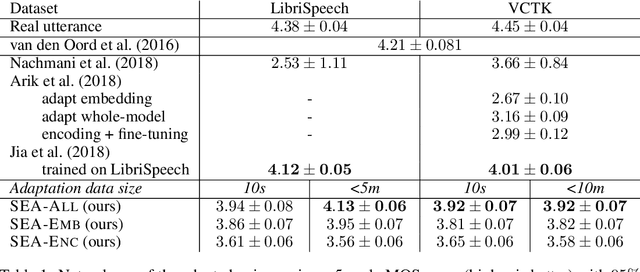
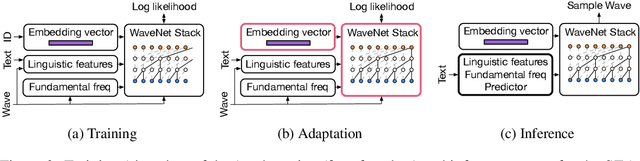
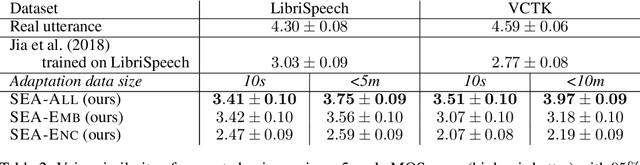
We present a meta-learning approach for adaptive text-to-speech (TTS) with few data. During training, we learn a multi-speaker model using a shared conditional WaveNet core and independent learned embeddings for each speaker. The aim of training is not to produce a neural network with fixed weights, which is then deployed as a TTS system. Instead, the aim is to produce a network that requires few data at deployment time to rapidly adapt to new speakers. We introduce and benchmark three strategies: (i) learning the speaker embedding while keeping the WaveNet core fixed, (ii) fine-tuning the entire architecture with stochastic gradient descent, and (iii) predicting the speaker embedding with a trained neural network encoder. The experiments show that these approaches are successful at adapting the multi-speaker neural network to new speakers, obtaining state-of-the-art results in both sample naturalness and voice similarity with merely a few minutes of audio data from new speakers.