 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISA: Group-wise Visual Token Selection and Aggregation via Graph Summarization for Efficient MLLMs Inference
Aug 25, 2025In this study, we introduce a novel method called group-wise \textbf{VI}sual token \textbf{S}election and \textbf{A}ggregation (VISA) to address the issue of inefficient inference stemming from excessive visual tokens in multimoal large language models (MLLMs). Compared with previous token pruning approaches, our method can preserve more visual information while compressing visual tokens. We first propose a graph-based visual token aggregation (VTA) module. VTA treats each visual token as a node, forming a graph based on semantic similarity among visual tokens. It then aggregates information from removed tokens into kept tokens based on this graph, producing a more compact visual token representation. Additionally, we introduce a group-wise token selection strategy (GTS) to divide visual tokens into kept and removed ones, guided by text tokens from the final layers of each group. This strategy progressively aggregates visual information, enhancing the stability of the visual information extraction process. We conduct comprehensive experiments on LLaVA-1.5, LLaVA-NeXT, and Video-LLaVA across various benchmarks to validate the efficacy of VISA. Our method consistently outperforms previous methods, achieving a superior trade-off between model performance and inference speed. The code is available at https://github.com/mobiushy/VISA.
Multimodal Label Relevance Ranking via Reinforcement Learning
Jul 18, 2024Conventional multi-label recognition methods often focus on label confidence, frequently overlooking the pivotal role of partial order relations consistent with human preference. To resolve these issues, we introduce a novel method for multimodal label relevance ranking, named Label Relevance Ranking with Proximal Policy Optimization (LR\textsuperscript{2}PPO), which effectively discerns partial order relations among labels. LR\textsuperscript{2}PPO first utilizes partial order pairs in the target domain to train a reward model, which aims to capture human preference intrinsic to the specific scenario. Furthermore, we meticulously design state representation and a policy loss tailored for ranking tasks, enabling LR\textsuperscript{2}PPO to boost the performance of label relevance ranking model and largely reduce the requirement of partial order annotation for transferring to new scenes. To assist in the evaluation of our approach and similar methods, we further propose a novel benchmark dataset, LRMovieNet, featuring multimodal labels and their corresponding partial order data. Extensive experiments demonstrate that our LR\textsuperscript{2}PPO algorithm achieves state-of-the-art performance, proving its effectiveness in addressing the multimodal label relevance ranking problem. Codes and the proposed LRMovieNet dataset are publicly available at \url{https://github.com/ChazzyGordon/LR2PPO}.
AdaFocus: Towards End-to-end Weakly Supervised Learning for Long-Video Action Understanding
Nov 28, 2023



Developing end-to-end models for long-video action understanding tasks presents significant computational and memory challenges. Existing works generally build models on long-video features extracted by off-the-shelf action recognition models, which are trained on short-video datasets in different domains, making the extracted features suffer domain discrepancy. To avoid this, action recognition models can be end-to-end trained on clips, which are trimmed from long videos and labeled using action interval annotations. Such fully supervised annotations are expensive to collect. Thus, a weakly supervised method is needed for long-video action understanding at scale. Under the weak supervision setting, action labels are provided for the whole video without precise start and end times of the action clip. To this end, we propose an AdaFocus framework. AdaFocus estimates the spike-actionness and temporal positions of actions, enabling it to adaptively focus on action clips that facilitate better training without the need for precise annotations. Experiments on three long-video datasets show its effectiveness. Remarkably, on two of datasets, models trained with AdaFocus under weak supervision outperform those trained under full supervision. Furthermore, we form a weakly supervised feature extraction pipeline with our AdaFocus, which enables significant improvements on three long-video action understanding tasks.
Unified and Dynamic Graph for Temporal Character Grouping in Long Videos
Aug 29, 2023



Video temporal character grouping locates appearing moments of major characters within a video according to their identities. To this end, recent works have evolved from unsupervised clustering to graph-based supervised clustering. However, graph methods are built upon the premise of fixed affinity graphs, bringing many inexact connections. Besides, they extract multi-modal features with kinds of models, which are unfriendly to deployment. In this paper, we present a unified and dynamic graph (UniDG) framework for temporal character grouping. This is accomplished firstly by a unified representation network that learns representations of multiple modalities within the same space and still preserves the modality's uniqueness simultaneously. Secondly, we present a dynamic graph clustering where the neighbors of different quantities are dynamically constructed for each node via a cyclic matching strategy, leading to a more reliable affinity graph. Thirdly, a progressive association method is introduced to exploit spatial and temporal contexts among different modalities, allowing multi-modal clustering results to be well fused. As current datasets only provide pre-extracted features, we evaluate our UniDG method on a collected dataset named MTCG, which contains each character's appearing clips of face and body and speaking voice tracks. We also evaluate our key components on existing clustering and retrieval datasets to verify the generalization ability. Experimental results manifest that our method can achieve promising results and outperform several state-of-the-art approaches.
D3G: Exploring Gaussian Prior for Temporal Sentence Grounding with Glance Annotation
Aug 08, 2023



Temporal sentence grounding (TSG) aims to locate a specific moment from an untrimmed video with a given natural language query. Recently, weakly supervised methods still have a large performance gap compared to fully supervised ones, while the latter requires laborious timestamp annotations. In this study, we aim to reduce the annotation cost yet keep competitive performance for TSG task compared to fully supervised ones. To achieve this goal, we investigate a recently proposed glance-supervised temporal sentence grounding task, which requires only single frame annotation (referred to as glance annotation) for each query. Under this setup, we propose a Dynamic Gaussian prior based Grounding framework with Glance annotation (D3G), which consists of a Semantic Alignment Group Contrastive Learning module (SA-GCL) and a Dynamic Gaussian prior Adjustment module (DGA). Specifically, SA-GCL samples reliable positive moments from a 2D temporal map via jointly leveraging Gaussian prior and semantic consistency, which contributes to aligning the positive sentence-moment pairs in the joint embedding space. Moreover, to alleviate the annotation bias resulting from glance annotation and model complex queries consisting of multiple events, we propose the DGA module, which adjusts the distribution dynamically to approximate the ground truth of target moments. Extensive experiments on three challenging benchmarks verify the effectiveness of the proposed D3G. It outperforms the state-of-the-art weakly supervised methods by a large margin and narrows the performance gap compared to fully supervised methods. Code is available at https://github.com/solicucu/D3G.
Collaborative Noisy Label Cleaner: Learning Scene-aware Trailers for Multi-modal Highlight Detection in Movies
Mar 26, 2023



Movie highlights stand out of the screenplay for efficient browsing and play a crucial role on social media platforms. Based on existing efforts, this work has two observations: (1) For different annotators, labeling highlight has uncertainty, which leads to inaccurate and time-consuming annotations. (2) Besides previous supervised or unsupervised settings, some existing video corpora can be useful, e.g., trailers, but they are often noisy and incomplete to cover the full highlights. In this work, we study a more practical and promising setting, i.e., reformulating highlight detection as "learning with noisy labels". This setting does not require time-consuming manual annotations and can fully utilize existing abundant video corpora. First, based on movie trailers, we leverage scene segmentation to obtain complete shots, which are regarded as noisy labels. Then, we propose a Collaborative noisy Label Cleaner (CLC) framework to learn from noisy highlight moments. CLC consists of two modules: augmented cross-propagation (ACP) and multi-modality cleaning (MMC). The former aims to exploit the closely related audio-visual signals and fuse them to learn unified multi-modal representations. The latter aims to achieve cleaner highlight labels by observing the changes in losses among different modalities. To verify the effectiveness of CLC, we further collect a large-scale highlight dataset named MovieLights. Comprehensive experiments on MovieLights and YouTube Highlights datasets demonstrate the effectiveness of our approach. Code has been made available at: https://github.com/TencentYoutuResearch/HighlightDetection-CLC
SIOD: Single Instance Annotated Per Category Per Image for Object Detection
Mar 30, 2022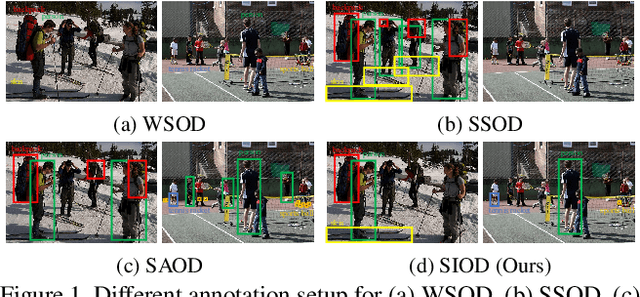



Object detection under imperfect data receives great attention recently. Weakly supervised object detection (WSOD) suffers from severe localization issues due to the lack of instance-level annotation, while semi-supervised object detection (SSOD) remains challenging led by the inter-image discrepancy between labeled and unlabeled data. In this study, we propose the Single Instance annotated Object Detection (SIOD), requiring only one instance annotation for each existing category in an image. Degraded from inter-task (WSOD) or inter-image (SSOD) discrepancies to the intra-image discrepancy, SIOD provides more reliable and rich prior knowledge for mining the rest of unlabeled instances and trades off the annotation cost and performance. Under the SIOD setting, we propose a simple yet effective framework, termed Dual-Mining (DMiner), which consists of a Similarity-based Pseudo Label Generating module (SPLG) and a Pixel-level Group Contrastive Learning module (PGCL). SPLG firstly mines latent instances from feature representation space to alleviate the annotation missing problem. To avoid being misled by inaccurate pseudo labels, we propose PGCL to boost the tolerance to false pseudo labels. Extensive experiments on MS COCO verify the feasibility of the SIOD setting and the superiority of the proposed method, which obtains consistent and significant improvements compared to baseline methods and achieves comparable results with fully supervised object detection (FSOD) methods with only 40% instances annotated.
Combined Depth Space based Architecture Search For Person Re-identification
Apr 09, 2021
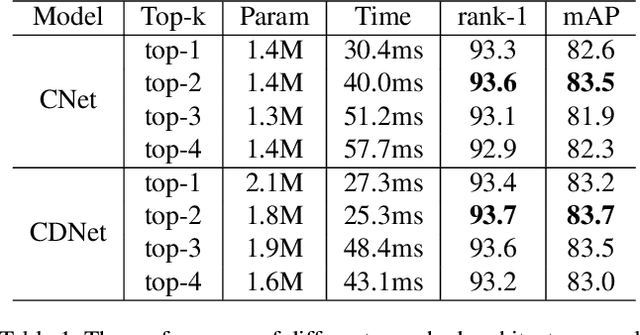
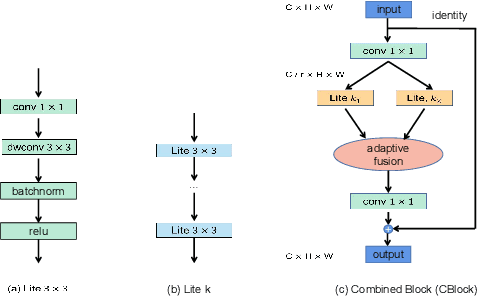
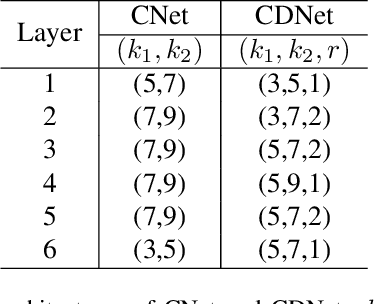
Most works on person re-identification (ReID) take advantage of large backbone networks such as ResNet, which are designed for image classification instead of ReID, for feature extraction. However, these backbones may not be computationally efficient or the most suitable architectures for ReID. In this work, we aim to design a lightweight and suitable network for ReID. We propose a novel search space called Combined Depth Space (CDS), based on which we search for an efficient network architecture, which we call CDNet, via a differentiable architecture search algorithm. Through the use of the combined basic building blocks in CDS, CDNet tends to focus on combined pattern information that is typically found in images of pedestrians. We then propose a low-cost search strategy named the Top-k Sample Search strategy to make full use of the search space and avoid trapping in local optimal result. Furthermore, an effective Fine-grained Balance Neck (FBLNeck), which is removable at the inference time, is presented to balance the effects of triplet loss and softmax loss during the training process. Extensive experiments show that our CDNet (~1.8M parameters) has comparable performance with state-of-the-art lightweight networks.